


DeepRec (PAI-TF) ist die einheitliche Open-Source-Empfehlungs-Engine der Alibaba Group (https://github.com/alibaba/DeepRec). Sie wird hauptsächlich für das Training und die Vorhersage spärlicher Modelle verwendet und kann Hunderte von Milliarden Funktionen und unterstützen Billionen von Proben. Ultragroß angelegtes, spärliches Training hat offensichtliche Vorteile in Bezug auf Trainingsleistung und -wirkung. Derzeit unterstützt DeepRec die Taobao-Suche, Empfehlung, Werbung und andere Szenarien und wird häufig in Taobao, Tmall, Alimama, Amap und anderen Unternehmen eingesetzt .
Intel arbeitet seit 2019 eng mit dem Alibaba PAI-Team zusammen, um die Technologie der künstlichen Intelligenz (KI) von Intel auf DeepRec anzuwenden und dabei auf Operatoren, Untergraphen, Laufzeit, Framework-Ebenen und -Modelle usw. abzuzielen. Optimieren Sie auf allen Ebenen, um volles Potenzial auszuschöpfen Die Software- und Hardwarevorteile von Intel helfen Alibaba dabei, die Leistung des internen und externen KI-Geschäfts zu beschleunigen.
Aktuelle Mainstream-Open-Source-Engines weisen immer noch gewisse Einschränkungen bei der Unterstützung extrem großer, spärlicher Trainingsszenarien auf. Beispielsweise unterstützen sie kein Online-Training, Funktionen können nicht dynamisch geladen werden und Die Iteration der Online-Bereitstellung ist unpraktisch usw. Insbesondere das Problem, dass die Leistung die Geschäftsanforderungen nur schwer erfüllen kann, ist besonders offensichtlich. Um die oben genannten Probleme zu lösen, wurde DeepRec umfassend angepasst und für spärliche Modellszenarien basierend auf TensorFlow1.15 optimiert. Die Hauptmaßnahmen umfassen die folgenden drei Kategorien:
Modelleffekt: Hauptsächlich durch Hinzufügen der EmbeddingVariable (EV ) Dynamische elastische Feature-Funktion und Verbesserung des Adagrad-Optimierers, um eine Optimierung zu erreichen. Die EV-Funktion löst Probleme wie Schwierigkeiten bei der Schätzung der nativen Variablengröße und Feature-Konflikte und bietet eine Fülle erweiterter Features wie Feature-Zulassungs- und Eliminierungsstrategien. Gleichzeitig werden Hot- und Cold-Feature-Dimensionen automatisch basierend auf der Häufigkeit konfiguriert Merkmalsvorkommen, Hinzufügen der Ausdruckskraft von Hochfrequenzmerkmalen lindert Überanpassungen und kann die Wirkung von Modellen mit geringer Dichte deutlich verbessern. Untergraphen, Operatoren, Laufzeit usw. Eine umfassende Leistungsoptimierung, einschließlich verteilter Strategieoptimierung, automatischer Pipeline SmartStage, automatischer Diagrammfusion, Diagrammoptimierung wie Einbettung und Aufmerksamkeit, allgemeine Optimierung von Sparse-Operatoren und Speicherverwaltungsoptimierung, reduziert die Speichernutzung erheblich Beschleunigt die End-to-End-Trainings- und Inferenzleistung erheblich;
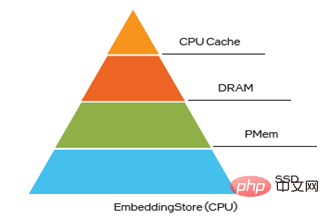
Bereitstellung und Bereitstellung: DeepRec unterstützt den inkrementellen Modellexport und -laden und ermöglicht so Online-Training und Aktualisierungen von ultragroßen Modellen auf 10-TB-Ebene und erfüllt damit die höchsten Anforderungen Geschäftsanforderungen für Aktualität; Ausrichtung auf Sparsamkeit Die Funktionen im Modell verfügen über Hot- und Cold-Skew-Eigenschaften (Hybridspeicher mit bis zu vier Ebenen, nämlich HBM+DRAM+PMem+SSD). Verbessern Sie die Leistung großer Modelle und senken Sie gleichzeitig die Kosten.
Intel-Technologie hilft DeepRec, eine hohe Leistung zu erzielen. Die enge Zusammenarbeit zwischen Intel und dem Alibaba PAI-Team hat eine wichtige Rolle bei der Erreichung der oben genannten drei einzigartigen Vorteile gespielt. Auch die drei Hauptvorteile von DeepRec spiegeln den großen Wert der Intel-Technologie voll und ganz wider :
Im Hinblick auf dieLeistungsoptimierung arbeitet Intels Team für ultragroße Cloud-Software eng mit Alibaba zusammen, um die CPU-Plattform von Operatoren, Untergraphen, Frameworks, Laufzeit und anderen Ebenen zu optimieren, um Intel® Xeon voll auszunutzen ® Verschiedene neue Funktionen skalierbarer Prozessoren können die Vorteile der Hardware voll ausnutzen.
Um die Benutzerfreundlichkeit von DeepRec auf der CPU-Plattform zu verbessern, wurde modelzoo auch so entwickelt, dass es die meisten Mainstream-Empfehlungsmodelle unterstützt, und wird dies auch tun Die einzigartigen EV-Funktionen von DeepRec werden auf diese Modelle angewendet und ermöglichen ein sofort einsatzbereites Benutzererlebnis.
Gleichzeitig stellt das Intel Optane Innovation Center-Team als Reaktion auf die besonderen Anforderungen des ultragroßen, spärlichen Trainingsmodells EV für Speicher- und KV-Suchvorgänge die Speicherverwaltung bereit und unterstützt und kooperiert mit der Speicherlösung Die mehrstufige Hybridspeicherlösung von DeepRec erfüllt die Anforderungen an großen Speicher und niedrige Kosten. Das Team der Programmable Solutions Division
implementiert die KV-Suchfunktion für die Einbettung, was gleichzeitig die Einbettungsabfragefähigkeit erheblich verbessert können mehr CPU-Ressourcen freigegeben werden. In Kombination mit den unterschiedlichen Hardwareeigenschaften von CPU, PMem und FPGA können aus Systemsicht die Software- und Hardwarevorteile von Intel für unterschiedliche Anforderungen vollständig genutzt werden, was die Implementierung von DeepRec im KI-Geschäft von Alibaba beschleunigen und bessere Lösungen für die gesamte Sparte bieten kann Szenario-Geschäftsökosystem. Hervorragende Lösung. Intel® DL Boost sorgt für eine entscheidende Leistungsbeschleunigung für DeepRec und ModelloptimierungVier Ebenen. Seit der Einführung der skalierbaren Intel® Deep-Learning-Trainings- und Inferenzfunktionen und die Einführung von DL Boost_VNNI im Intel® der zweiten Generation. Nach dem Strong® Scalable-Prozessor hat Intel einen Befehlssatz eingeführt, der den Datentyp BFloat16 (BF16) unterstützt, um die Deep-Learning-Trainings- und Inferenzleistung weiter zu verbessern. Mit der kontinuierlichen Innovation und Weiterentwicklung der Hardwaretechnologie wird Intel in der nächsten Generation der skalierbaren Xeon®-Prozessoren eine neue KI-Verarbeitungstechnologie einführen, um die Fähigkeiten von VNNI und BF16 vom eindimensionalen Vektor zur zweidimensionalen Matrix weiter zu verbessern. Die oben genannten Hardware-Befehlssatztechnologien wurden bei der Optimierung von DeepRec angewendet, sodass unterschiedliche Hardwarefunktionen für unterschiedliche Rechenanforderungen verwendet werden können. Außerdem wurde bestätigt, dass Intel® AVX-512 und BF16 sehr gut für Training und Inferenzbeschleunigung in spärlichen Umgebungen geeignet sind Szenarien. Abbildung 1 Entwicklungsdiagramm der KI-Fähigkeit der Intel Plattformtiefe Lernleistungsbeschleunigungsbibliothek oneDNN (oneAPI Deep Neural Network Library) und ändern Sie den ursprünglichen Thread-Pool von oneDNN und vereinheitlichen Sie ihn im Eigen-Thread-Pool von DeepRec, wodurch die Kosten für den Thread-Pool-Wechsel gesenkt und das durch den Wettbewerb zwischen verschiedenen Thread-Pools verursachte Problem der Leistungseinbuße vermieden wird. oneDNN hat die Leistungsoptimierung für eine große Anzahl gängiger Betreiber implementiert, darunter MatMul, BiasAdd, LeakyReLU und andere gängige Betreiber in spärlichen Szenarien, die eine starke Leistungsunterstützung für Such- und Werbemodelle bieten können, und die Betreiber in oneDNN unterstützen auch den Datentyp BF16. In Verbindung mit dem skalierbaren Intel® Xeon® Prozessor der dritten Generation, der mit dem BF16-Befehlssatz ausgestattet ist, kann die Modelltrainings- und Inferenzleistung erheblich verbessert werden.
Obwohl oneDNN verwendet werden kann, um die Leistung rechenintensiver Operatoren erheblich zu verbessern, gibt es im Empfehlungsmodell für Suchmaschinenwerbung eine große Anzahl spärlicher Operatoren, wie z. B. Select, DynamicStitch, Transpose, Tile, SparseSegmentMean usw. Die meisten nativen Implementierungen dieser Operatoren bieten einen gewissen Raum für die Optimierung des Speicherzugriffs, und gezielte Lösungen können verwendet werden, um eine zusätzliche Optimierung zu erreichen. Diese Optimierung ruft AVX-512-Anweisungen auf und kann durch Hinzufügen von „--copt=-march=skylake-avx512“ zum Kompilierungsbefehl aktiviert werden. Im Folgenden sind zwei der Optimierungsfälle aufgeführt. Fall 2: Ebenso können Sie die Entpack- und Shuffle-Anweisungen von Intel® AVX-512 verwenden, um den Transponierungsoperator zu optimieren, d. h. die Matrix durch klein zu transponieren Blöcke, wie im rechten Bild von Abbildung 2 gezeigt, der letzte Warp. Der obige Test zeigt, dass die Leistungsverbesserung ebenfalls sehr signifikant ist.
Subgraph-Optimierung Die Graphoptimierung ist eine der wichtigsten effektiven Methoden zur aktuellen KI-Leistungsoptimierung. Wenn DeepRec in groß angelegten, spärlichen Szenarien angewendet wird, erfolgt in der Regel eine große Menge an Feature-Informationsverarbeitung, bei der es sich hauptsächlich um Einbettungsfunktionen handelt, und die Einbettung enthält eine große Anzahl kleiner Operatoren, um eine allgemeine Leistungsverbesserung zu erreichen DeepRec Die Funktion „fused_embedding_lookup“ wird zum Einbetten von Untergraphen hinzugefügt, wodurch eine große Anzahl redundanter Vorgänge reduziert wird. Gleichzeitig wird durch die Verwendung von Intel® AVX-512-Anweisungen zur Beschleunigung von Berechnungen die Leistung beim Einbetten von Untergraphen erheblich verbessert. Indem Sie do_fusion in der API tf.feature_column.embedding_column(..., do_fusion=True) auf True setzen, können Sie die Funktion zur Optimierung des Einbettens von Untergraphen aktivieren. Basierend auf der CPU-Plattform hat Intel in DeepRec einzigartige Empfehlungen erstellt, die mehrere Mainstream-Modelle wie WDL, DeepFM, DLRM, DIEN, DIN, DSSM, BST, MMoE, DBMTL, ESMM abdecken usw. Modellsammlung, die verschiedene gängige Szenarien wie Rückruf, Sortierung, Mehrzielsetzung usw. umfasst. Im Vergleich zu anderen Frameworks bieten diese Modelle eine hervorragende Leistung auf CPU-Plattformen, die auf Open-Source-Datensätzen basieren wie Criteo bewirbt. Die herausragendste Leistung ist zweifellos die optimierte Implementierung von Mixed Precision BF16 und Float32. Durch Hinzufügen der Funktion zum Anpassen des Datentyps der DNN-Schicht in DeepRec können wir die hohen Leistungs- und Genauigkeitsanforderungen spärlicher Szenen erfüllen. Die Möglichkeit, die Optimierung zu ermöglichen, ist in Abbildung 3 dargestellt. Der Datentyp der aktuellen Variablen ist Wird über keep_weights als Float32 beibehalten. Verhindern Sie den durch die Gradientenakkumulation verursachten Genauigkeitsabfall und konvertieren Sie die DNN-Operation mithilfe der BF16-Hardware-Recheneinheit des skalierbaren Intel® Xeon®-Prozessors. Die Leistung des DNN-Computings wird erheblich verbessert, während die Leistung durch Graph-Fusion-Cast-Operationen weiter verbessert wird. Abbildung 3 So aktivieren Sie die gemischte Präzisionsoptimierung Um den Einfluss von BF16 auf die Modellgenauigkeit AUC (Area Under Curve) und die Leistung Gsteps/ s, für das vorhandene Modellzoo Alle Modelle wenden die oben genannte Optimierungsmethode mit gemischter Präzision an. Die Auswertung des Alibaba PAI-Teams mithilfe von DeepRec auf der Alibaba Cloud-Plattform zeigt, dass [1], basierend auf dem Criteo-Datensatz, nach der Optimierung mit BF16 die Modell-WDL-Genauigkeit oder AUC FP32 erreichen kann , und die Trainingsleistung des BF16-Modells wird um das 1,4-fache verbessert, was ein bemerkenswerter Effekt ist. Um die Hardwarevorteile der CPU-Plattform in Zukunft stärker zu nutzen, insbesondere um die Wirkung neuer Hardwarefunktionen zu maximieren, wird DeepRec die Optimierung aus verschiedenen Blickwinkeln, einschließlich Optimierungsoperatoren, weiter implementieren Untergraphen und das Hinzufügen von Modellen mit mehreren Zielen usw., um CPU-Lösungen mit höherer Leistung für spärliche Szenen zu erstellen. Verwenden Sie PMem, um den Einbettungsspeicher zu implementieren Für extrem große, spärliche Modelltrainings- und Vorhersage-Engines (hundert Milliarden Features, Billionen von Proben, Modell auf 10-TB-Ebene), wenn alles dynamisch zufällig ist Die Verwendung von Zugriffsspeichern (Dynamic Random Access Memory, DRAM) wird die Gesamtbetriebskosten (Total Cost of Ownership, TCO) erheblich erhöhen und gleichzeitig einen enormen Druck auf den IT-Betrieb und die Verwaltung des Unternehmens ausüben, was die Implementierung von KI erschwert Lösungen stoßen auf Herausforderungen. PMem bietet die Vorteile einer höheren Speicherdichte und Datenpersistenz, seine E/A-Leistung kommt der von DRAM nahe und seine Kosten sind günstiger. Es kann die Anforderungen von Ultra-Großunternehmen an hohe Leistung und große Kapazität vollständig erfüllen -Skaliertes, spärliches Training und Vorhersage. PMem unterstützt zwei Betriebsmodi, nämlich den Speichermodus und den App Direct-Modus. Im Speichermodus ist es identisch mit gewöhnlichem flüchtigem (nicht persistentem) Systemspeicher, jedoch zu geringeren Kosten, was eine höhere Kapazität bei gleichzeitiger Wahrung des Systembudgets ermöglicht und Terabytes an Speicher in einer einzelnen Server-Gesamtkapazität im Vergleich zum Speichermodus bereitstellt Der Direktzugriffsmodus kann die Persistenzfunktion von PMem nutzen. Im Anwendungsdirektzugriffsmodus werden PMem und der angrenzende DRAM-Speicher als byteadressierbarer Speicher erkannt. Das Betriebssystem kann PMem-Hardware als zwei verschiedene Geräte verwenden. PMem ist als Blockgerät konfiguriert Formatieren Sie es zur Verwendung in ein Dateisystem. Der andere ist der DEVDAX-Modus. PMem wird als Einzelzeichengerät gesteuert, verlässt sich auf die vom Kernel bereitgestellte KMEM-DAX-Funktion (5.1 oder höher) und behandelt PMem als flüchtig. Es verwendet nicht den Standard Speicher und ist mit dem Speicherverwaltungssystem verbunden. Da es sich um einen langsameren und größeren Speicher-NUMA-Knoten handelt, kann die Anwendung transparent darauf zugreifen. Beim Feature-Training in sehr großem Maßstab nimmt das Einbetten von Variablenspeicher mehr als 90 % des Speichers ein, und die Speicherkapazität wird zu einem seiner Engpässe. Das Speichern von EV in PMem kann diesen Engpass überwinden und mehrere Vorteile schaffen, z. B. die Verbesserung der Speicherkapazität für groß angelegtes verteiltes Training, die Unterstützung des Trainings und der Vorhersage größerer Modelle, die Reduzierung der Kommunikation zwischen mehreren Maschinen und die Verbesserung der Modelltrainingsleistung Reduzierung der Gesamtbetriebskosten. Bei der Einbettung von mehrstufigem Hybridspeicher ist PMem auch eine ausgezeichnete Wahl, um den DRAM-Engpass zu überwinden. Derzeit gibt es drei Möglichkeiten, Elektrofahrzeuge in PMem zu speichern, und wenn Mikrobenchmark, WDL-Modell und WDL-Proxy-Modell auf die folgenden drei Arten ausgeführt werden, kommt die Leistung der Speicherung von Elektrofahrzeugen im DRAM sehr nahe, was zweifellos die Gesamtbetriebskosten erhöht besser. Große Vorteile: Das Alibaba PAI-Team nutzte drei Möglichkeiten, um EV auf der speichererweiterten Alibaba Cloud-Instanz ecs.re7p.16xlarge zu speichern, um einen Vergleichstest des eigenständigen WDL-Modells in Modelzoo durchzuführen [2] Diese drei Methoden bestehen darin, EV im DRAM zu speichern, den auf der Libpmem-Bibliothek basierenden Allokator zum Speichern von EV zu verwenden und den auf der Memkind-Bibliothek basierenden Allokator zum Speichern von EV zu verwenden. Die Testergebnisse zeigen, dass das Speichern von EV in PMem unterschiedlich ist Von der Einsparung von EV bis zur Leistung von DRAM ist es sehr ähnlich. Abbildung 4: Einbetten von mehrstufigem Hybridspeicher Erzielen Sie Leistungsverbesserungen um mehrere Größenordnungen und beseitigen Sie das aktuelle Dilemma, SSD zum Speichern und Wiederherstellen sehr großer Modelle zu verwenden, was viel Zeit in Anspruch nimmt und Trainingsvorhersagen in diesem Zeitraum unterbrochen werden. FPGA beschleunigt die Einbettungssuche Groß angelegtes, spärliches Training und Vorhersage deckt eine Vielzahl von Szenarien ab, wie z. B. verteiltes Training, Einzelmaschinen- und verteilte Vorhersage sowie heterogenes Computertraining. Im Vergleich zu herkömmlichen Convolutional Neural Networks (CNN) oder Recurrent Neural Networks (RNN) weisen sie einen wesentlichen Unterschied auf, nämlich die Verarbeitung von Einbettungstabellen, und die Anforderungen an die Verarbeitung von Einbettungstabellen stehen in diesen Szenarien vor neuen Herausforderungen: Enormer Speicherkapazitätsbedarf (bis zu 10 TB oder mehr); Relativ geringe Rechendichte; Unregelmäßige Speicherzugriffsmuster. Um das Problem des Zirkulationsengpasses und der Verzögerung zu lösen, wurde bei der Optimierung ein FPGA der Intel® Agilex Abbildung 5 stellt die FPGA-Implementierungsoptimierung der Intel® Agilex® I-Serie vor Rechtlicher HinweisIntel kontrolliert oder prüft die Daten Dritter nicht. Bitte überprüfen Sie diesen Inhalt, konsultieren Sie andere Quellen und bestätigen Sie, dass die genannten Daten korrekt sind. Die beschriebenen Kostensenkungsszenarien sollen veranschaulichen, wie sich bestimmte Intel-Produkte auf zukünftige Kosten auswirken und in bestimmten Situationen und Konfigurationen Kosteneinsparungen ermöglichen können. Jede Situation ist anders. Intel übernimmt keine Garantie für Kosten oder Kostensenkungen.
Die Funktionen und Vorteile der Intel-Technologie hängen von der Systemkonfiguration ab und erfordern möglicherweise die Aktivierung aktivierter Hardware, Software oder Dienste. Die Produktleistung variiert je nach Systemkonfiguration. Kein Produkt und keine Komponente ist völlig sicher. Weitere Informationen erhalten Sie beim Originalgerätehersteller oder -händler oder unter intel.com. Intel, das Intel-Logo und andere Intel-Marken sind Marken der Intel Corporation oder ihrer Tochtergesellschaften in den Vereinigten Staaten und/oder anderen Ländern. © Copyright Intel Corporation [1] Weitere Details zum Leistungstest finden Sie unter https://github.com/alibaba/DeepRec/tree/ main/modelzoo/ WDL 
Fügen Sie in den DeepRec-Kompilierungsoptionen einfach „--config=mkl_threadpool“ hinzu, um die oneDNN-Optimierung einfach zu aktivieren.
Fall 1: Das Implementierungsprinzip des Select-Operators besteht darin, Elemente basierend auf Bedingungen auszuwählen. Zu diesem Zeitpunkt kann die Maskenlademethode von Intel® AVX-512 verwendet werden, wie im linken Bild von Abbildung 2 gezeigt. Um den durch eine große Anzahl von Beurteilungen verursachten Zeitaufwand zu reduzieren und dann die Effizienz beim Lesen und Schreiben von Daten durch Stapelauswahl zu verbessern, zeigt der abschließende Online-Test, dass die Leistung erheblich verbessert wird



I-Serie eingeführt, der CXL (Compute Express Link) unterstützt. Der Implementierungspfad ist in Abbildung 5 dargestellt :
Das obige ist der detaillierte Inhalt vonIntel hilft beim Aufbau der groß angelegten Open-Source-Trainings-/Vorhersage-Engine DeepRec für spärliche Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



