


Fünfzehn Monate nach der Veröffentlichung von DALL·E veröffentlichte OpenAI in diesem Frühjahr die Fortsetzung DALL·E 2, die mit ihren atemberaubenderen Effekten und ihrer reichhaltigen Spielbarkeit schnell für Schlagzeilen in großen KI-Communitys sorgte. In den letzten Jahren hat Deep Learning mit dem Aufkommen von Generative Adversarial Networks (GAN), Variational Autoencoders (VAE) und Diffusionsmodellen zusammen mit GPT-3 und BERT der Welt seine leistungsstarken Fähigkeiten zur Bilderzeugung unter Beweis gestellt Nach NLP-Modellen durchbrechen Menschen nach und nach die Informationsgrenzen zwischen Text und Bildern.
In DALL·E 2 geben Sie einfach einen einfachen Text (Eingabeaufforderung) ein und es können mehrere hochauflösende Bilder mit 1024 x 1024 Pixeln generiert werden. Diese Bilder können sogar unkonventionelle Semantiken zum Ausdruck bringen, um fantasievolle visuelle Effekte in surrealistischer Form zu erzeugen, wie zum Beispiel „Ein Astronaut reitet auf einem Pferd im fotorealistischen Stil“ in Abbildung 1.
 Abbildung 1. DALL·E-Beispiel der 2. Generation
Abbildung 1. DALL·E-Beispiel der 2. Generation
Dieser Artikel bietet eine ausführliche Erklärung, wie neue Paradigmen wie DALL·E durch Text viele erstaunliche Bilder erzeugen können Einführung in grundlegende Technologien und eignet sich auch für Einsteiger in die Generierung von Feldlesern.
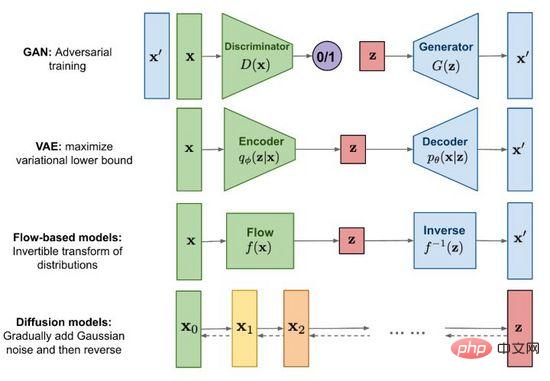
Abbildung 2. Mainstream-Bilderzeugungsmethoden
Seit der Geburt von Generative Adversarial Networks (GAN) im Jahr 2014 ist die Bilderzeugungsforschung zu einem wichtigen Grenzthema im Deep Learning und sogar im gesamten Bereich geworden Künstliche Intelligenz hat in diesem Stadium der Entwicklung der Technologie einen Punkt erreicht, an dem Fälschungen mit echten verwechselt werden können. Zu den Mainstream-Methoden gehören neben dem bekannten Generative Adversarial Network (GAN) auch Variational Autoencoder (VAE) und flussbasierte Modelle (Flow-based models) sowie Diffusionsmodelle (Diffusion models), die in letzter Zeit große Aufmerksamkeit erregt haben . Mithilfe von Abbildung 2 untersuchen wir die Merkmale und Unterschiede der einzelnen Methoden.
GANs vollständiger Name ist G enerative A dversarial N etworks, aus dem Namen lässt sich das nicht schwer ablesen " ist einer von seine Erfolge Essenz. Die Idee der Konfrontation ist von der Spieltheorie inspiriert. Trainieren Sie beim Trainieren eines Diskriminators (Diskriminator), ob es sich bei der Eingabe um ein echtes Bild oder ein generiertes Bild handelt Minimax-Spiel und stärker werden, wie Formel (1). Wenn aus zufälligem Rauschen ein zum „Täuschen“ ausreichendes Bild erzeugt wird, glauben wir, dass die Datenverteilung des realen Bildes gut angepasst ist und durch Abtasten eine große Anzahl realistischer Bilder erzeugt werden kann.
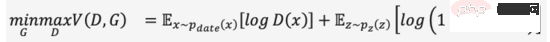
GAN ist die am weitesten verbreitete Technologie in generativen Modellen und glänzt in vielen Datensyntheseszenarien wie Bildern, Videos, Sprache und NLP. Neben der direkten Generierung von Inhalten aus zufälligem Rauschen können wir auch Bedingungen (z. B. Klassifizierungsbezeichnungen) als Eingaben für den Generator und den Diskriminator hinzufügen, sodass die generierten Ergebnisse den Attributen der bedingten Eingabe entsprechen und der generierte Inhalt gesteuert werden kann. Obwohl GAN hervorragende Effekte hat, ist seine Trainingsstabilität aufgrund der Existenz eines Spielmechanismus schlecht und anfällig für einen Moduskollaps. Wie man dafür sorgt, dass das Modell den Spielgleichgewichtspunkt reibungslos erreicht, ist auch ein heißes Forschungsthema bei GAN.
Variational Autoencoder (Variational Autoencoder) ist eine Variante des Autoencoders. Der traditionelle Autoencoder ist darauf ausgelegt, ein neuronales Netzwerk auf unbeaufsichtigte Weise zu trainieren, um die ursprüngliche Eingabe in eine Zwischendarstellung zu komprimieren und wiederherzustellen Es gibt zwei Prozesse, bei denen der erste die ursprüngliche hochdimensionale Eingabe über den Encoder (Encoder) in eine niedrigdimensionale verborgene Schicht umwandelt und der zweite die Daten aus der Codierung über den Decoder (Decoder) rekonstruiert. Es ist nicht schwer zu erkennen, dass das Ziel des Autoencoders darin besteht, eine Identitätsfunktion zu lernen. Wir können Kreuzentropie (Kreuzentropie) oder mittleren quadratischen Fehler (mittlerer quadratischer Fehler) verwenden, um einen Rekonstruktionsverlust zu konstruieren, um die Differenz zwischen den zu quantifizieren Eingang und Ausgang. Wie in Abbildung 3 dargestellt, erhalten wir während des obigen Prozesses eine niedrigdimensionale Hidden-Layer-Kodierung, die die potenziellen Attribute der Originaldaten erfasst und zur Datenkomprimierung und Merkmalsdarstellung verwendet werden kann.
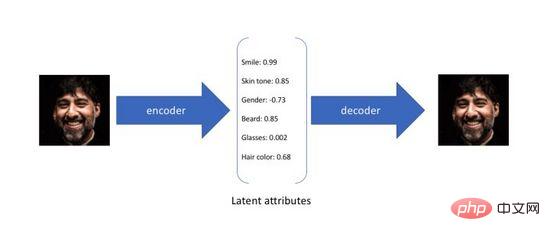
Abbildung 3. Latente Attributcodierung des Autoencoders
Da sich der Autoencoder nur auf die Rekonstruktionsfähigkeit der Codierung der verborgenen Schicht konzentriert, ist seine räumliche Verteilung der verborgenen Schicht im kontinuierlichen Raum der verborgenen Schicht häufig unregelmäßig und ungleichmäßig. Zufälliges Abtasten oder Interpolieren von a Eine Reihe von Codes führt oft zu bedeutungslosen und nicht interpretierbaren Ergebnissen. Um einen regelmäßigen verborgenen Schichtraum zu konstruieren, damit wir verschiedene potenzielle Attribute zufällig abtasten und reibungslos interpolieren und schließlich über den Decoder aussagekräftige Bilder erzeugen können, haben Forscher 2014 den Variations-Autoencoder vorgeschlagen.
Der Variations-Autoencoder ordnet die Eingabe nicht mehr einer festen Codierung im Raum der verborgenen Schicht zu, sondern wandelt sie in eine Wahrscheinlichkeitsverteilungsschätzung des Raums der verborgenen Schicht um. Zur Vereinfachung des Ausdrucks gehen wir davon aus, dass die vorherige Verteilung eine Standard-Gauß-Verteilung ist. In ähnlicher Weise trainieren wir ein probabilistisches Decodermodell, um die räumliche Verteilung der verborgenen Schicht auf die reale Datenverteilung abzubilden. Wenn wir eine Eingabe erhalten, schätzen wir die Parameter der Verteilung (den Mittelwert und die Kovarianz des multivariaten Gaußschen Modells) durch die Posterior-Verteilung und nehmen eine Stichprobe aus dieser Verteilung. Wir können Reparametrisierungstechniken verwenden, um die Stichprobe differenzierbar zu machen (als Zufallsvariable). , und schließlich wird die Verteilung über den Wahrscheinlichkeitsdecoder ausgegeben, wie in Abbildung 4 dargestellt. Um das erzeugte Bild so realistisch wie möglich zu gestalten, müssen wir nach der Posterior-Verteilung auflösen, mit dem Ziel, die Log-Likelihood des realen Bildes zu maximieren.
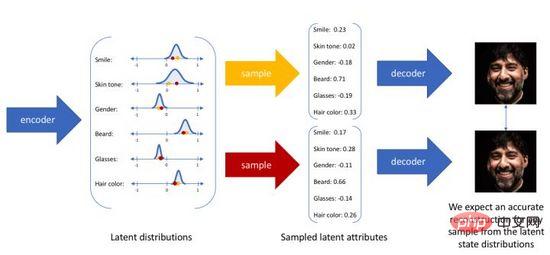
Abbildung 4. Sampling-Generierungsprozess des Variations-Autoencoders
Leider enthält die reale Posterior-Verteilung das Integral über den kontinuierlichen Raum gemäß dem Bayes'schen Modell und kann nicht direkt gelöst werden. Um die oben genannten Probleme zu lösen, verwendet der Variations-Autoencoder die Variationsinferenzmethode, führt einen lernbaren Wahrscheinlichkeitsencoder ein, um die reale Posterior-Verteilung anzunähern, verwendet die KL-Divergenz, um die Differenz zwischen den beiden Verteilungen zu messen, und löst dieses Problem anhand der wahren Posterior-Verteilung bedeutet, wie der Abstand zwischen den beiden Verteilungen verringert werden kann.
Wir lassen den Zwischenableitungsprozess weg und erweitern die obige Formel, um Formel (2) zu erhalten,
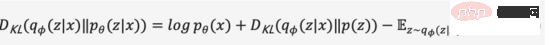
Da die KL-Divergenz nicht negativ ist, können wir unser Maximierungsziel in Formel (3) umwandeln,
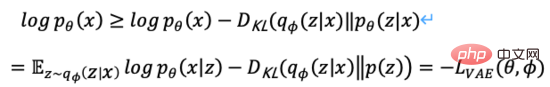
Zusammenfassend definieren wir den probabilistischen Encoder und den probabilistischen Decoder als Verlustfunktion des Modells, und seine negative Form wird als Evidenzuntergrenze (Evidence Lower Bound) bezeichnet. Die Maximierung der Evidenzuntergrenze entspricht der Maximierung des Ziels. Der obige Variationsprozess ist die Kernidee von VAE und seinen verschiedenen Varianten. Durch Variationsargumentation wird das Problem in eine Evidenzuntergrenze umgewandelt, die die Generierung realer Daten maximiert.
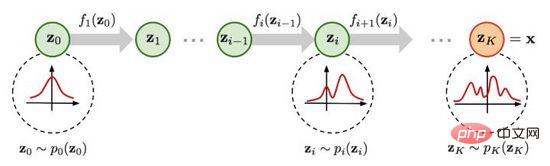
Abbildung 5. Flussbasierter Generierungsprozess
Wie in Abbildung 5 gezeigt, wird davon ausgegangen, dass die ursprüngliche Datenverteilung durch eine Reihe reversibler Transformationsfunktionen von der bekannten Datenverteilung transformiert werden kann Verteilung erhalten wird, d. h. Durch die Determinanten- und Variablenänderungsregeln der Jacob-Matrix können wir die Wahrscheinlichkeitsdichtefunktion realer Daten (Formel (4)) direkt schätzen und die berechenbare Log-Likelihood maximieren.
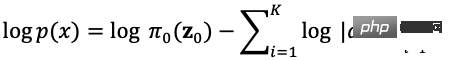
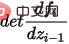 ist die Jacobs-Determinante der Transformationsfunktion. Sie ist also nicht nur reversibel, sondern erfordert auch, dass ihre Jacobs-Determinante leicht berechnet werden kann. Flussbasierte Generierungsmodelle wie Glow verwenden eine reversible 1x1-Faltung für eine genaue Dichteschätzung und erzielen gute Ergebnisse bei der Gesichtsgenerierung.
ist die Jacobs-Determinante der Transformationsfunktion. Sie ist also nicht nur reversibel, sondern erfordert auch, dass ihre Jacobs-Determinante leicht berechnet werden kann. Flussbasierte Generierungsmodelle wie Glow verwenden eine reversible 1x1-Faltung für eine genaue Dichteschätzung und erzielen gute Ergebnisse bei der Gesichtsgenerierung.

Abbildung 6. Diffusions- und Rückwärtsprozesse des Diffusionsmodells
Das Diffusionsmodell definiert zwei Prozesse, Vorwärts- und Rückwärtsprozesse, die aus realen Daten verteilt werden. Während der Abtastung wird Gaußsches Rauschen erzeugt wird schrittweise zu den Abtastwerten hinzugefügt, um eine Rauschabtastsequenz zu erzeugen. Der Rauschadditionsprozess kann durch den Varianzparameter gesteuert werden. Er kann dann ungefähr einer Gaußschen Verteilung entsprechen. Der Diffusionsprozess ist ein voreingestellter steuerbarer Prozess. Der Rauschadditionsprozess kann als Gleichung (5) mit einer bedingten Verteilung ausgedrückt werden bei jeder Schrittgröße
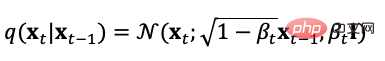
In ähnlicher Weise können wir den Diffusionsprozess auch umkehren, anhand des Gaußschen Rauschens abtasten und ein Modell lernen, um die tatsächliche bedingte Wahrscheinlichkeitsverteilung abzuschätzen. Daher kann der umgekehrte Prozess als Gleichung (7) definiert werden. ,
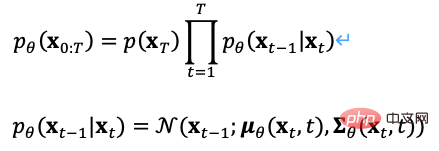
Es gibt viele Möglichkeiten für die Optimierungsziele des Diffusionsmodells. Da es beispielsweise direkt aus dem Vorwärtsprozess berechnet werden kann, können wir Stichproben aus der vorhergesagten Verteilung hinzufügen Klassifizierung und Textbeschriftungen als bedingte Eingaben, wodurch der Rekonstruktionsverlust mit minimalem mittleren quadratischen Fehler optimiert wird.
Im Entrauschungs-Diffusionswahrscheinlichkeitsmodell DDPM erstellte der Autor eine vereinfachte Version des Verlusts des Rauschvorhersagemodells (Gleichung (8)) durch Neuparametrisierungstechnologie und gab die verrauschten Daten mit der Schrittgröße ein 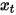 Trainieren Sie das Modell zur Vorhersage von Rauschen
Trainieren Sie das Modell zur Vorhersage von Rauschen 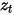 . Während des Inferenzprozesses wird der Gaußsche Verteilungsmittelwert von
. Während des Inferenzprozesses wird der Gaußsche Verteilungsmittelwert von
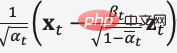
verwendet, um die entrauschten Daten vorherzusagen 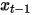 , um eine Entrauschung von Gesichtsbildern zu erreichen. 3. Multimodales Repräsentationslernen. 3.1 NLP auf Transformer. und bei der Artikelgenerierung verwendet werden, wurden bei nachgelagerten Aufgaben wie Codegenerierung, maschineller Übersetzung, Fragen und Antworten usw. große Durchbrüche erzielt. Beide verwenden Transformer als Hauptrahmen des Algorithmus, und die Implementierungsdetails unterscheiden sich geringfügig (Abbildung 7).
, um eine Entrauschung von Gesichtsbildern zu erreichen. 3. Multimodales Repräsentationslernen. 3.1 NLP auf Transformer. und bei der Artikelgenerierung verwendet werden, wurden bei nachgelagerten Aufgaben wie Codegenerierung, maschineller Übersetzung, Fragen und Antworten usw. große Durchbrüche erzielt. Beide verwenden Transformer als Hauptrahmen des Algorithmus, und die Implementierungsdetails unterscheiden sich geringfügig (Abbildung 7).
BERT ist im Wesentlichen ein bidirektionaler Encoder. Er verwendet zwei Aufgaben, Mask Language Model (MLM) und Next Sentence Prediction (NSP), um die Merkmalsdarstellung von Text auf selbstüberwachte Weise zu erlernen andere Lernaufgaben. Das Wesentliche von GPT ist ein autoregressiver Decoder. Durch die Verwendung umfangreicher Daten und das kontinuierliche Stapeln von Modellen maximiert es den Wahrscheinlichkeitswert des Sprachmodells, den nächsten Text vorherzusagen. Wichtig ist, dass der Nachbestellungstext von GPT während des Trainingsprozesses maskiert wird, sodass er beim Training und Vorhersagen des Vorbestellungstextes unsichtbar ist. In BERT sind alle Texte füreinander sichtbar und nehmen an der Selbstaufmerksamkeitsberechnung teil. BERT verwendet zufällige Masken- oder Ersatzeingaben, um die Robustheit und Ausdrucksfähigkeit des Modells zu verbessern. 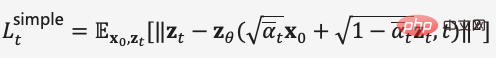
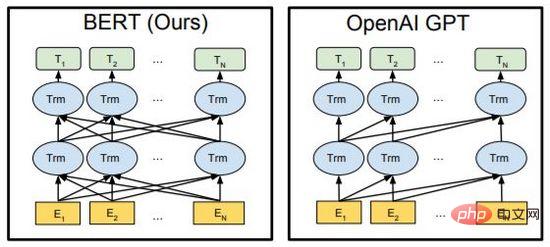
Abbildung 9. CLIP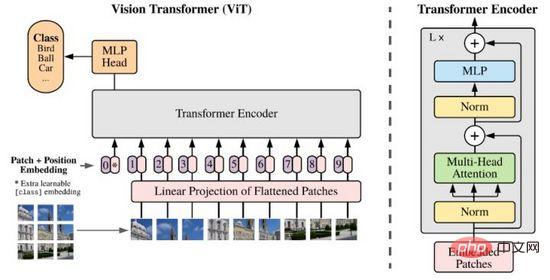
CLIP ordnet die Merkmalsdarstellungen von Text und Bildern demselben Raum zu. Obwohl es keine modalübergreifende Informationsübertragung realisiert, ist es als Methode zur Merkmalskomprimierung, Ähnlichkeitsmessung und zum Lernen modalübergreifender Darstellungen sehr effektiv. Intuitiv geben wir Bildtoken mit den ähnlichsten Merkmalen unter allen im Etikettenbereich generierten Textaufforderungen aus, d. h. eine Bildklassifizierung ist abgeschlossen (Abbildung 9(2)), insbesondere wenn die Datenverteilung von Bildern und Etiketten noch nicht erfolgt ist Der zuvor erschienene Trainingssatz verfügt immer noch über die Fähigkeit des Zero-Shot-Lernens.
Nach der Einführung in den beiden vorherigen Kapiteln haben wir die grundlegenden Technologien im Zusammenhang mit der Bildgenerierung und dem Lernen multimodaler Darstellungen systematisch überprüft. In diesem Kapitel werden die drei neuesten Methoden zur modalübergreifenden Bildgenerierung vorgestellt . Interpretation Wie sie mithilfe dieser zugrunde liegenden Techniken modelliert werden.
DALL·E wurde Anfang 2021 von OpenAI vorgeschlagen und zielt darauf ab, einen autoregressiven Decoder vom Eingabetext zum Ausgabebild zu trainieren. Aus der erfolgreichen Erfahrung mit CLIP wissen wir, dass Textmerkmale und Bildmerkmale im selben Merkmalsraum codiert werden können, sodass wir Transformer verwenden können, um die Text- und Bildmerkmale autoregressiv als einen einzelnen Datenstrom zu modellieren („Autoregressively models the text and image“) Token als einzelner Datenstrom"). Datenstrom"). Der Trainingsprozess von
DALL·E ist in zwei Phasen unterteilt: Die eine besteht darin, einen Variations-Autoencoder für die Bildkodierung und -dekodierung zu trainieren, und die andere darin, einen autoregressiven Dekoder für Text und Bilder zu trainieren, um die Token der generierten Bilder vorherzusagen in Abbildung 10 gezeigt.
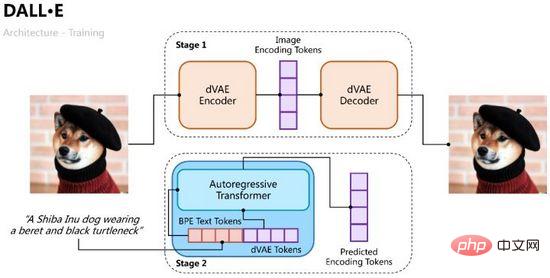
Abbildung 10. Der Trainingsprozess von DALL·E
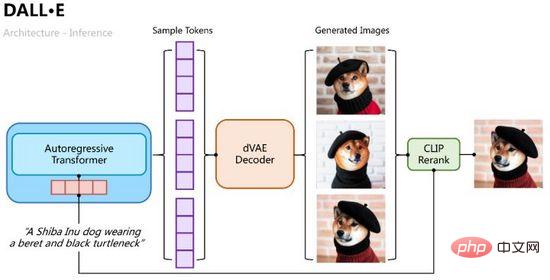
Der Argumentationsprozess ist intuitiver. Verwenden Sie den autoregressiven Transformer, um die Text-Token schrittweise in Bild-Token zu dekodieren. Während des Dekodierungsprozesses können wir mehrere Gruppen von Beispielen abtasten Durch die Klassifizierungswahrscheinlichkeit werden dann mehrere Gruppen von Beispieltoken in die Variations-Autokodierung eingegeben, um mehrere generierte Bilder zu dekodieren, und durch die CLIP-Ähnlichkeitsberechnung sortiert und ausgewählt, wie in Abbildung 11 dargestellt. Abbildung 11: Der Inferenzprozess von DALL·E Verwenden Sie das Modell der gemeinsamen Wahrscheinlichkeitsverteilung von Text und Bildern, die von vornherein vorhergesagt wurde (in der ersten Stufe auf eine gleichmäßige Verteilung initialisiert). Auf die gleiche Weise kann die Evidenzuntergrenze des Optimierungsziels ermittelt werden,
In der ersten Phase des Trainingsprozesses verwendet DALL·E einen diskreten Variations-Autoencoder (Discrete VAE), der als dVAE bezeichnet wird und eine aktualisierte Version von Vector Quantized VAE (VQ-VAE) ist. In VAE verwenden wir eine Wahrscheinlichkeitsverteilung, um den kontinuierlichen Raum der verborgenen Schicht zu beschreiben, und erhalten den Code der verborgenen Schicht durch Zufallsstichprobe. Dieser Code ist jedoch nicht so deterministisch wie diskrete Sprachzeichen. Um die „Sprache“ des verborgenen Schichtraums des Bildes zu lernen, verwendet VQ-VAE eine Reihe erlernbarer Vektorquantisierungen, um den verborgenen Schichtraum darzustellen. Dieser quantifizierte verborgene Schichtraum wird als Einbettungsraum oder Codebuch/Vokabular bezeichnet. Der Trainingsprozess und der Vorhersageprozess von VQ-VAE zielen darauf ab, den verborgenen Schichtvektor zu finden, der dem Bildkodierungsvektor am nächsten liegt, und dann die abgebildete Vektorsprache in ein Bild zu dekodieren (Abbildung 12). Die Verlustfunktion besteht aus drei Teilen, die jeweils optimiert werden Rekonstruktionsverlust, aktualisieren Sie den Einbettungsraum und den Encoder, und der Gradient wird beendet.
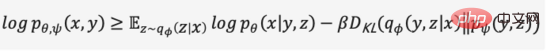
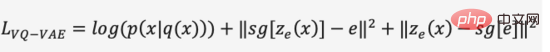
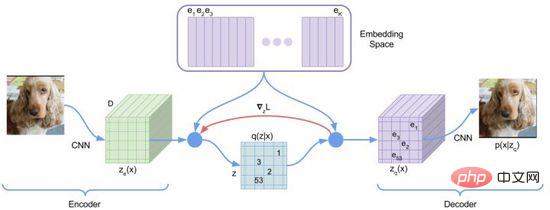
Abbildung 13. dVAE
Um die oben genannten Probleme zu optimieren, verwendete DALL·E Gumbel-Softmax, um ein neues dVAE zu erstellen (Abbildung 13), und die Ausgabe des Decoders beträgt 32*32 K=8192 Dimensionen Beim Einbetten der Raumklassifizierungswahrscheinlichkeit wird Rauschen zur Softmax-Berechnung hinzugefügt, um Zufälligkeiten einzuführen neu parametrisiert, um es differenzierbar zu machen (Formel (11)), wird während des Inferenzprozesses immer noch der nächste Nachbar verwendet.
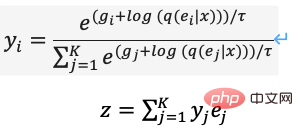
PyTorch-Implementierung kann hard=True setzen, um eine ungefähre One-Hot-Codierung auszugeben, während die Ableitbarkeit durch y_hard = y_hard - y_soft.detach() + y_soft erhalten bleibt.
Wenn die erste Trainingsphase abgeschlossen ist, können wir dVAE reparieren, um die Bildtoken des vorhergesagten Ziels für jedes Text-Bild-Paar zu generieren. Während der zweiten Trainingsphase verwendete DALL·E die BPE-Methode, um zunächst den Text in Text-Tokens mit der gleichen Dimension d=3968 wie die Bild-Tokens zu kodieren, dann die Text-Tokens und Bild-Tokens zusammenzufassen und Positionskodierung und Füllkodierung hinzuzufügen , und verwenden Sie Transformer Encoder, um eine autoregressive Vorhersage durchzuführen, wie in Abbildung 14 dargestellt. Um die Berechnungsgeschwindigkeit zu verbessern, verwendet DALL·E außerdem drei Mechanismen mit geringer Aufmerksamkeitsmaske: Zeile, Spalte und Faltung.
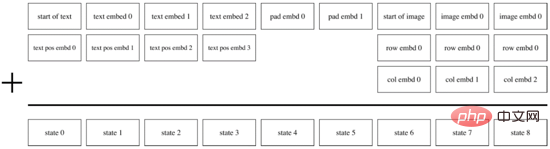
Abbildung 14. Der autoregressive Decoder von DALL·E
Basierend auf der obigen Implementierung kann DALL·E nicht nur „echte“ Bilder basierend auf der Texteingabe generieren, sondern auch Fusionserstellung, Szenenverständnis und Stiltransformation durchführen siehe Abbildung 15. Darüber hinaus kann sich die Wirkung von DALL·E in Null-Sample- und professionellen Bereichen verschlechtern und die erzeugte Bildauflösung (256*256) ist geringer.

Abbildung 15. Verschiedene Generierungsszenarien von DALL·E
Um die Qualität der Bildgenerierung weiter zu verbessern und die Interpretierbarkeit des Text-Bild-Feature-Raums zu untersuchen, kombiniert OpenAI das Diffusionsmodell und CLIP in DALL·E 2 wurde im April 2022 vorgeschlagen, was nicht nur die Generierungsgröße auf 1024*1024 erhöhte, sondern auch den Migrationsprozess des Text-Bild-Merkmalsraums durch die Interpolationsoperation des Merkmalsraums visualisierte.
Wie in Abbildung 16 dargestellt, verwendet DALL·E 2 die durch CLIP-Vergleichslernen erhaltene Texteinbettung als Modelleingabe und Vorhersageobjekte. Der spezifische Prozess besteht darin, einen vorherigen Prior zu lernen und die entsprechende Bildeinbettung aus dem Text vorherzusagen Verwenden Sie den autoregressiven Transformator und das Diffusionsmodell, um auf zwei Arten zu trainieren. Letzteres erbringt bei jedem Datensatz eine bessere Leistung und lernt dann den UnCLIP-Diffusionsmodell-Decoder, der als umgekehrter Prozess des CLIP-Bildencoders und der von Prior vorhergesagten Bildeinbettung angesehen werden kann Da Bedingungen hinzugefügt werden, um die Kontrolle zu erreichen, sind Texteinbettung und Textinhalt optionale Bedingungen. Um die Auflösung zu verbessern, fügt UnCLIP außerdem zwei Upsampling-Decoder (CNN-Netzwerke) hinzu, um umgekehrt größere Bilder zu generieren.
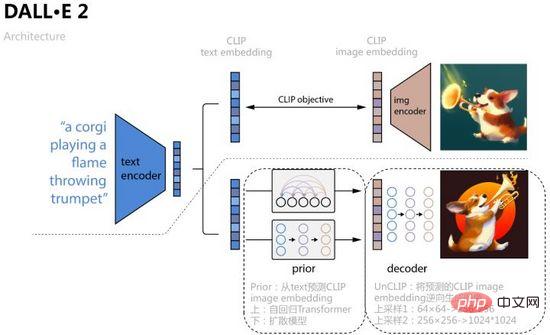
Abbildung 16. DALL·E 2
Im Diffusionsmodelltraining von Prior verwendet DALL·E 2 einen Transformer-Decoder, um den Diffusionsprozess vorherzusagen, und die Eingabesequenz besteht derzeit aus BPE-codiertem Text + Texteinbettung + Zeitschritteinbettung Verrauschte Bildeinbettung hinzugefügt, entrauschte Bildeinbettung vorhersagen, MSE verwenden, um die Verlustfunktion zu erstellen,
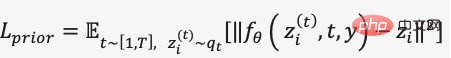
DALL·E 2 Um zu vermeiden, dass das Modell gerichtete Typgenerierungsergebnisse für bestimmte Textbeschriftungen erzeugt, wird der Funktionsreichtum reduziert, und für die Diffusion Die Vorhersagebedingungen des Modells sind eingeschränkt, um eine klassifikatorfreie Führung zu gewährleisten. Beispielsweise wird beim Diffusionsmodelltraining von Prior und UnCLIP die Drop-Wahrscheinlichkeit für Bedingungen wie das Hinzufügen von Texteinbettung festgelegt, sodass der Generierungsprozess die abhängige Bedingungseingabe nicht abschließt. Daher können wir im umgekehrten Generierungsprozess durch Bildeinbettungsabtastung verschiedene Varianten desselben Bildes generieren und dabei die Grundfunktionen beibehalten. Durch die Steuerung des Interpolationsverhältnisses können wir beispielsweise reibungslose Migrationsvisualisierungsergebnisse erzielen Dies ist in der Abbildung 17 dargestellt.

Abbildung 17. Bewahrung und Übertragung von Bildmerkmalen, die DALL·E 2 erreichen kann
DALL·E 2 hat zahlreiche Überprüfungsexperimente zur Wirksamkeit von Prior und UnCLIP durchgeführt, beispielsweise mithilfe von drei Methoden 1) Nur Textinhalt Geben Sie das UnCLIP-Generierungsmodell ein. 2) Geben Sie nur den Textinhalt und die Texteinbettung in das UnCLIP-Generierungsmodell ein. 3) Fügen Sie die von Prior vorhergesagte Bildeinbettung hinzu, und die Generierungseffekte der drei Methoden verbessern sich allmählich Überprüfen Sie die Wirksamkeit von Prior. Darüber hinaus verwendet DALL·E 2 PCA, um die Einbettungsdimension des verborgenen Schichtraums zu reduzieren. Mit der Reduzierung der Dimension werden die semantischen Merkmale des generierten Bildes allmählich schwächer. Schließlich verglich DALL·E 2 andere Methoden am MS-COCO-Datensatz und erreichte mit FID= 10,39 die beste Generierungsqualität (Abbildung 18).
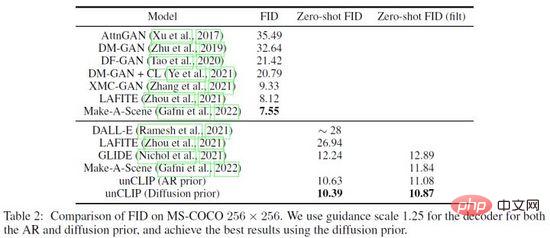
Abbildung 18. Vergleichsergebnisse von DALL·E 2 im MS-COCO-Datensatz
ERNIE-VILG ist ein bidirektionales Text-Bild-Generierungsmodell für chinesische Szenen, das Anfang 2022 von Baidu Wenxin vorgeschlagen wurde.
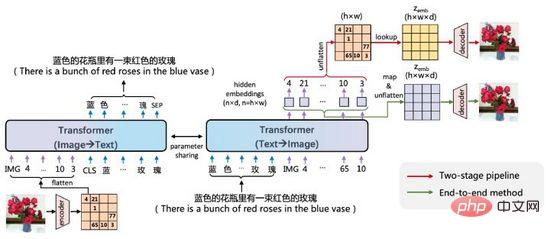
Abbildung 19. ERNIE-VILG
Die Idee von ERNIE-VILG ähnelt der von DALL·E. Es kodiert Bildmerkmale durch vorab trainierte Variations-Autoencoder und verwendet Transformer, um Text-Tokens und Bild-Tokens autoregressiv vorherzusagen . Hauptsächlich Der Unterschied besteht darin:
 Abbildung 20. ERNIE-VILG-Generierungsbeispiel
Abbildung 20. ERNIE-VILG-Generierungsbeispiel
IV Zusammenfassung
Heutzutage hat die Technologie zur Text-zu-Bild-Generierung einen hohen Schwellenwert und ihre Schulungskosten übersteigen die von einmodalen Methoden wie Gesichtserkennung, maschineller Übersetzung und Sprachsynthese bei weitem. Am Beispiel von DALL·E ist dies der Fall 250 Millionen Paare gesammelt und beschriftet. Für die Stichprobe wurden 1024 V100-GPUs verwendet, um ein Modell mit 12 Milliarden Parametern zu trainieren. Darüber hinaus gab es im Bereich der Bilderzeugung immer wieder Themen wie Rassendiskriminierung, Gewaltpornografie und sensible Privatsphäre. Ab 2020 investieren immer mehr KI-Teams in die modalübergreifende Generierungsforschung. In naher Zukunft werden wir möglicherweise nicht mehr von Fälschungen in der realen Welt und der generierten Welt zu unterscheiden sein.
Das obige ist der detaillierte Inhalt vonVon VAE zum Diffusionsmodell: Ein Artikel, der das neue Paradigma der Verwendung von Texten zur Generierung von Diagrammen erläutert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



