



Wir haben vor vielen Jahren erwähnt, dass das Training von KI-Workloads mit ausreichend Daten und der Verwendung von Faltungs-Neuronalen Netzen allmählich zum Mainstream wird, und große HPC-Zentren (High Performance Computing) auf der ganzen Welt tun dies bereits seit vielen Jahren. Überlassen Sie diese Last der GPU von NVIDIA. Für Aufgaben wie Simulation und Modellierung ist die GPU-Leistung ganz hervorragend. Im Wesentlichen handelt es sich bei HPC-Simulation/-Modellierung und KI-Training tatsächlich um eine Art harmonische Konvergenz, und GPUs sind als massiv parallele Prozessoren besonders gut für diese Art von Arbeit geeignet.
Aber seit 2012 brach offiziell die KI-Revolution aus und Bilderkennungssoftware verbesserte erstmals die Genauigkeit auf ein Niveau, das über dem des Menschen liegt. Daher sind wir sehr gespannt, wie lange die Gemeinsamkeit der effizienten Verarbeitung von HPC und KI auf ähnlichen GPUs anhalten kann. Daher haben wir im Sommer 2019 versucht, durch Verfeinerung und Iteration des Modells mit der mathematischen Einheit mit gemischter Genauigkeit die gleichen Ergebnisse wie die FP64-Berechnungen im Linpack-Benchmark zu erzielen. Bevor NVIDIA im folgenden Jahr die GA100-GPU „Ampere“ auf den Markt brachte, versuchten wir noch einmal, die Verarbeitungsleistung von HPC und KI zu testen. Zu diesem Zeitpunkt hatte Nvidia die A100-GPU „Ampere“ noch nicht auf den Markt gebracht, sodass der Grafikkartenriese noch nicht offiziell dazu geneigt war, KI-Modelle auf Tensorkernen mit gemischter Präzision zu trainieren. Die Antwort ist jetzt natürlich klar: HPC-Workloads auf FP64-Vektoreinheiten erfordern einige architektonische Anpassungen, um die GPU-Leistung zu nutzen. Es besteht kein Zweifel, dass sie ein bisschen ein „Bürger zweiter Klasse“ sind. Aber damals war noch alles möglich.
Mit der Einführung von Nvidias „Hopper“ GH100-GPU Anfang dieses Jahres gibt es eine größere Lücke bei den generationsübergreifenden Leistungsverbesserungen zwischen KI und HPC. Darüber hinaus sagte Huang Jensen, Mitbegründer und CET von NVIDIA, auf der jüngsten GTC-2022-Herbstkonferenz, dass auch die KI-Arbeitslast selbst divergent geworden sei, was NVIDIA dazu zwingt, mit der Erforschung des CPU-Geschäfts zu beginnen – oder genauer gesagt, es sollte so sein sogenannter GPU-orientierter optimierter erweiterter Speichercontroller.
Wir werden dieses Problem später ausführlich besprechen.
Lassen Sie uns mit dem klarsten Urteil beginnen. Wenn Nvidia möchte, dass seine GPU über eine stärkere FP64-Leistung verfügt, um 64-Bit-Gleitkomma-HPC-Anwendungen wie Wettermodellierung, Berechnungen der Fluiddynamik, Finite-Elemente-Analyse, Quantenchromodynamik und andere hochintensive mathematische Simulationen zu unterstützen, dann sollte der Beschleuniger die Designidee sein so: Erstellen Sie ein Produkt, das keine Tensorkerne oder FP32-CUDA-Kerne hat (hauptsächlich als Grafik-Shader in der CUDA-Architektur verwendet).
Aber ich befürchte, dass nur ein paar hundert Kunden bereit sind, ein solches Produkt zu kaufen, sodass der Preis für einen einzelnen Chip Zehntausende oder sogar Hunderttausende Dollar betragen kann. Nur so können die Design- und Herstellungskosten gesenkt werden abgedeckt werden. Um ein größeres und profitableres Geschäft aufzubauen, muss Nvidia eine allgemeinere Architektur entwerfen, deren Vektormathematikfunktionen einfach stärker sind als die von CPUs.
Seit NVIDIA vor 15 Jahren beschlossen hat, sich ernsthaft mit der Entwicklung von Produkten für HPC-Anwendungen zu befassen, konzentriert sich das Unternehmen auf HPC-Szenarien, die FP32-Gleitkomma-Matheoperationen verwenden – einschließlich Daten mit einfacher Genauigkeit, die in der seismischen Verarbeitung, Signalverarbeitung und Genomik verwendet werden -Typ-Workloads und Verarbeitungsaufgaben und verbessern Sie schrittweise die FP64-Fähigkeiten der GPU.
Der im Juli 2012 eingeführte K10-Beschleuniger ist mit zwei „Kepler“ GK104-GPUs ausgestattet, bei denen es sich um genau die gleichen GPUs handelt, die auch in Gaming-Grafikkarten verwendet werden. Es verfügt über 1536 FP32-CUDA-Kerne und verwendet keine dedizierten FP64-Kerne. Die FP64-Unterstützung erfolgt rein in der Software, sodass es keinen nennenswerten Leistungsgewinn gibt: Die beiden GK104-GPUs erreichten 4,58 Teraflops bei FP32-Aufgaben und 190 Gigaflops bei FP64, ein Verhältnis von 24 zu 1. Der K20X, der Ende 2012 auf der SC12 Supercomputing Conference vorgestellt wurde, nutzt die GK110-GPU mit einer FP32-Leistung von 3,95 Teraflops und einer FP64-Leistung von 1,31 Teraflops, ein Verhältnis, das auf 3 zu 1 erhöht wurde. Zu diesem Zeitpunkt ist das Produkt erstmals für HPC-Anwendungen und Benutzer verfügbar, die KI-Modelle im akademischen/Hyperscale-Computing-Bereich trainieren. Die K80-GPU-Beschleunigerkarte verwendet zwei GK110B-GPUs. Dies liegt daran, dass NVIDIA der damals höchsten „Maxwell“-GPU keine FP64-Unterstützung hinzugefügt hat, sodass GK110 B damals die beliebteste und kostengünstigste Option war. Die FP32-Leistung des K80 beträgt 8,74 Teraflops und die FP64-Leistung 2,91 Teraflops, was immer noch einem Verhältnis von 3 zu 1 entspricht.
Bei der „Pascal“ GP100-GPU hat sich die Kluft zwischen HPC und AI mit der Einführung des FP16-Mischpräzisionsindikators weiter vergrößert, aber das Verhältnis von Vektor-FP32 zu Vektor-FP64 hat sich weiter auf 2 zu 1 umgewandelt, und nach dem „ Volta“ GV100 „ Es wurde in neueren GPUs wie dem Ampere“ GA100 und dem „Hopper“ GH100 beibehalten. In der Volta-Architektur führte NVIDIA zum ersten Mal die Tensor-Core-Matrix-Mathematikeinheit mit fester Matrix-Lei ein, die die Gleitkomma- (und Ganzzahl-)Rechnungsfunktionen erheblich verbesserte und weiterhin Vektoreinheiten in der Architektur beibehielt.
Diese Tensorkerne werden zur Verarbeitung immer größerer Matrizen verwendet, aber die spezifische Betriebsgenauigkeit wird immer geringer, sodass diese Art von Ausrüstung einen extrem übertriebenen KI-Lastdurchsatz erreicht hat. Dies ist natürlich untrennbar mit der unscharfen statistischen Natur des maschinellen Lernens selbst verbunden und hinterlässt auch eine große Lücke zu der hochpräzisen Mathematik, die für die meisten HPC-Algorithmen erforderlich ist. Die folgende Abbildung zeigt die logarithmische Darstellung des Leistungsunterschieds zwischen KI und HPC. Ich glaube, Sie können den Trendunterschied zwischen den beiden bereits erkennen:
? gehen? 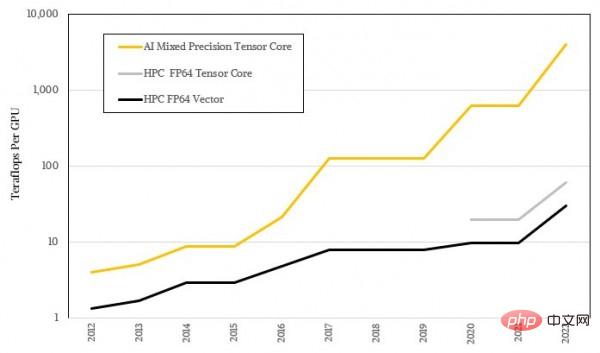
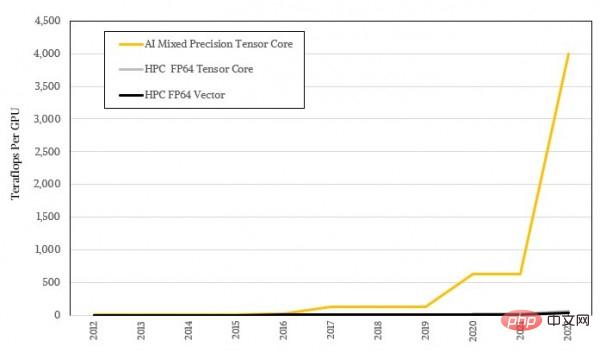 Es ist ersichtlich, dass die GPU-Architektur von NVIDIA hauptsächlich auf eine höhere KI-Leistung bei gleichzeitig akzeptabler HPC-Leistung abzielt. Der zweigleisige Ansatz leitet Kunden dazu an, ihre Hardware alle drei Jahre zu aktualisieren. Aus reiner FP64-Leistungsperspektive stieg der FP64-Durchsatz von Nvidia-GPUs in den zehn Jahren von 2012 bis 2022 um das 22,9-fache, von 1,3 Teraflops beim K20X auf 30 Teraflops beim H100. Wenn die Tensor-Kernmatrixeinheit mit dem iterativen Löser verwendet werden kann, kann die Steigerung das 45,8-fache erreichen. Wenn Sie jedoch ein KI-Trainingsbenutzer sind, der nur groß angelegte parallele Berechnungen mit geringer Präzision benötigt, ist die Leistungsänderung von FP32 zu FP8 übertrieben. Es wurde von den ersten 3,95 Teraflops der FP32-Rechenleistung auf 4 Petaflops der FP8-Sparse-Leistung aufgerüstet Matrix, was eine Verbesserung um das 1012,7-fache darstellt. Und wenn wir es mit dem damaligen FP64-codierten KI-Algorithmus auf der K20X-GPU vergleichen (damals gängige Praxis), beträgt die Leistungsverbesserung in den letzten zehn Jahren nur ein erbärmliches Zweifaches.
Es ist ersichtlich, dass die GPU-Architektur von NVIDIA hauptsächlich auf eine höhere KI-Leistung bei gleichzeitig akzeptabler HPC-Leistung abzielt. Der zweigleisige Ansatz leitet Kunden dazu an, ihre Hardware alle drei Jahre zu aktualisieren. Aus reiner FP64-Leistungsperspektive stieg der FP64-Durchsatz von Nvidia-GPUs in den zehn Jahren von 2012 bis 2022 um das 22,9-fache, von 1,3 Teraflops beim K20X auf 30 Teraflops beim H100. Wenn die Tensor-Kernmatrixeinheit mit dem iterativen Löser verwendet werden kann, kann die Steigerung das 45,8-fache erreichen. Wenn Sie jedoch ein KI-Trainingsbenutzer sind, der nur groß angelegte parallele Berechnungen mit geringer Präzision benötigt, ist die Leistungsänderung von FP32 zu FP8 übertrieben. Es wurde von den ersten 3,95 Teraflops der FP32-Rechenleistung auf 4 Petaflops der FP8-Sparse-Leistung aufgerüstet Matrix, was eine Verbesserung um das 1012,7-fache darstellt. Und wenn wir es mit dem damaligen FP64-codierten KI-Algorithmus auf der K20X-GPU vergleichen (damals gängige Praxis), beträgt die Leistungsverbesserung in den letzten zehn Jahren nur ein erbärmliches Zweifaches.
Natürlich kann der Leistungsunterschied zwischen den beiden nicht als riesig bezeichnet werden. Huang Renxun selbst erwähnte auch, dass das aktuelle KI-Lager selbst wieder zweigeteilt sei. Ein Typ ist ein riesiges Basismodell, das vom Transformatormodell unterstützt wird und auch als großes Sprachmodell bezeichnet wird. Die Anzahl der Parameter solcher Modelle wächst rasant und auch der Bedarf an Hardware steigt. Im Vergleich zum vorherigen neuronalen Netzwerkmodell stellt das heutige Transformatormodell eine völlig andere Ära dar, wie in der folgenden Abbildung dargestellt:
Bitte verzeihen Sie, dass dieses Bild etwas verschwommen ist, aber der Punkt ist: Für die erste Gruppe ist dies nicht der Fall Bei KI-Modellen stieg der Rechenbedarf innerhalb von zwei Jahren um das Achtfache; bei KI-Modellen mit Transformatoren stieg der Rechenbedarf jedoch um das 275-fache in zwei Jahren. Wenn Gleitkommaoperationen zur Verarbeitung verwendet werden, müssen 100.000 GPUs im System vorhanden sein, um den Bedarf zu decken (dies ist kein großes Problem). Durch die Umstellung auf FP4-Präzision wird sich jedoch die Anzahl der Berechnungen verdoppeln. Wenn die GPU künftig 1,8-nm-Transistoren verwendet, wird sich die Rechenleistung um etwa das 2,5-fache erhöhen, sodass immer noch eine Lücke von etwa dem 55-fachen besteht. Wenn FP2-Operationen implementiert werden könnten (vorausgesetzt, diese Genauigkeit reicht aus, um das Problem zu lösen), könnte der Rechenaufwand halbiert werden, aber das würde den Einsatz von mindestens 250.000 GPUs erfordern. Darüber hinaus sind große Sprachtransformatormodelle oft schwer zu erweitern und insbesondere wirtschaftlich nicht realisierbar. Daher ist diese Art von Modell ausschließlich den Riesenkonzernen vorbehalten, so wie sich Atomwaffen nur in den Händen mächtiger Länder befinden. Was das Empfehlungssystem als „digitale Wirtschaftsmaschine“ betrifft, so erfordert es nicht nur einen exponentiellen Anstieg der Berechnungsmenge, sondern auch einen Datenumfang, der die Speicherkapazität eines großen Sprachmodells oder sogar einer GPU bei weitem übersteigt. Huang Renxun erwähnte in seiner vorherigen GTC-Keynote-Rede:
"Im Vergleich zu großen Sprachmodellen ist die Datenmenge, mit der jede Recheneinheit bei der Verarbeitung des Empfehlungssystems konfrontiert wird, um eine Größenordnung größer. Offensichtlich erfordert das Empfehlungssystem nicht nur eine schnellere Speichergeschwindigkeit, sondern auch die zehnfache Speichergeschwindigkeit Obwohl große Sprachmodelle im Laufe der Zeit ein exponentielles Wachstum aufweisen und eine konstante Rechenleistung erfordern, sind Empfehlungssysteme wohl die beiden wichtigsten Arten von KI-Modelle haben heutzutage unterschiedliche Rechenanforderungen. Empfehlungssysteme können für jeden Artikel, jedes Video und jeden sozialen Beitrag skaliert werden. Jede Einbettungstabelle kann Zehner enthalten Bei der Verarbeitung von Empfehlungssystemen ist eine parallele Verarbeitung der Daten in einigen Teilen des Netzwerks erforderlich, was höhere Anforderungen an die Datenverarbeitung stellt Verschiedene Teile des Computers „Grace“ Arm-Server-CPU und eng gekoppelt mit der Hopper-GPU. Wir scherzen auch darüber, dass Grace eigentlich nur Hoppers Speichercontroller ist, wenn der benötigte Hauptspeicher sehr groß ist. Aber auf lange Sicht könnte man vielleicht einfach eine Reihe von CXL-Ports, die das NVLink-Protokoll ausführen, in die GPU der nächsten Generation von Hooper einbinden.
Der von NVIDIA hergestellte Grace-Hopper-Superchip ist also gleichbedeutend damit, einen CPU-Cluster auf „untergeordneter“ Ebene in einen riesigen GPU-Beschleunigungscluster auf „erwachsener“ Ebene zu stecken. Diese Arm-CPUs können herkömmliche C++- und Fortran-Workloads unterstützen, allerdings zu einem Preis: Die Leistung des CPU-Teils im Hybrid-Cluster beträgt nur ein Zehntel der Leistung der GPU im Cluster, aber die Kosten betragen das Drei- bis Dreifache eines herkömmlichen reinen CPU-Clusters.
Übrigens respektieren und verstehen wir alle technischen Entscheidungen von NVIDIA. Grace ist eine hervorragende CPU und Hopper ist auch eine hervorragende GPU. Die Kombination der beiden wird definitiv zu guten Ergebnissen führen. Aber was jetzt passiert, ist, dass wir auf derselben Plattform mit drei unterschiedlichen Arbeitslasten konfrontiert sind, die die Architektur jeweils in eine andere Richtung bewegen. Hochleistungsrechnen, große Sprachmodelle und Empfehlungssysteme – diese drei Brüder haben ihre eigenen Eigenschaften, und es ist unmöglich, die Architektur gleichzeitig auf kostengünstige Weise zu optimieren. 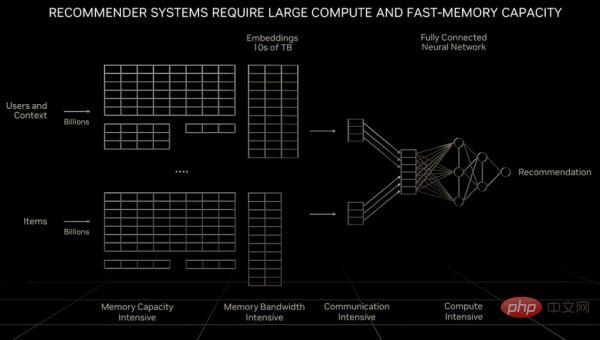
Das obige ist der detaillierte Inhalt vonDie Kunst des Systemdesigns: Wohin sollte die GPU-Architektur gehen, wenn HPC- und KI-Anwendungen zum Mainstream werden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



