


Übersetzer |. Bugatti
Rezensent |. Derzeit gibt es keine Standardpraktiken für die Erstellung und Verwaltung von Anwendungen für maschinelles Lernen (ML). Projekte für maschinelles Lernen sind schlecht organisiert, nicht wiederholbar und scheitern auf lange Sicht tendenziell. Daher benötigen wir einen Prozess, der uns dabei hilft, Qualität, Nachhaltigkeit, Robustheit und Kostenmanagement während des gesamten Lebenszyklus des maschinellen Lernens aufrechtzuerhalten. Abbildung 1: Lebenszyklusprozess der maschinellen Lernentwicklung Lernen von Produktqualität.
CRISP-ML (Q) besteht aus sechs separaten Phasen:
1. Datenvorbereitung 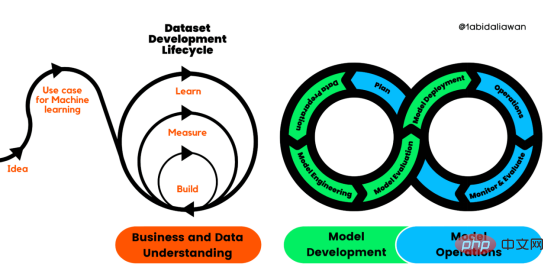
Abbildung 2. Qualitätssicherung in jeder Phase
Qualitätssicherungsmethoden werden in jeder Phase des Frameworks eingeführt. Dieser Ansatz hat Anforderungen und Einschränkungen, wie z. B. Leistungsmetriken, Datenqualitätsanforderungen und Robustheit. Es trägt dazu bei, Risiken zu reduzieren, die den Erfolg von Anwendungen für maschinelles Lernen beeinträchtigen. Dies kann durch kontinuierliche Überwachung und Wartung des gesamten Systems erreicht werden.
Zum Beispiel: In E-Commerce-Unternehmen führen Daten- und Konzeptabweichungen zu einer Modellverschlechterung. Wenn wir keine Systeme zur Überwachung dieser Änderungen einsetzen, wird das Unternehmen Verluste erleiden, d. h. Kunden verlieren.
Geschäfts- und Datenverständnis
Zu Beginn des Entwicklungsprozesses müssen wir den Projektumfang, die Erfolgskriterien und die Machbarkeit der ML-Anwendung bestimmen. Danach begannen wir mit der Datenerfassung und Qualitätsüberprüfung. Der Prozess ist langwierig und herausfordernd.
Umfang:Was wir durch den Einsatz eines maschinellen Lernprozesses erreichen wollen. Geht es darum, Kunden zu binden oder die Betriebskosten durch Automatisierung zu senken? 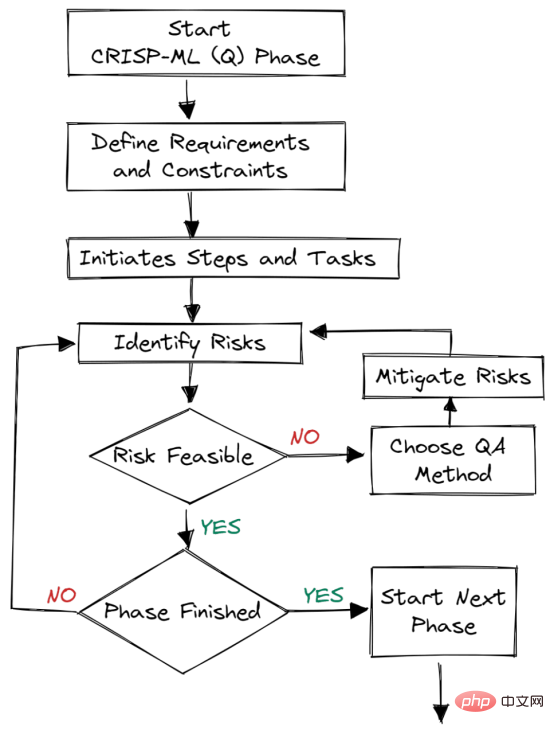
Erfolgskriterien:
Wir müssen klare und messbare geschäftliche, maschinelle Lern- (statistische Indikatoren) und wirtschaftliche (KPI) Erfolgsindikatoren definieren.Machbarkeit:
Wir müssen Datenverfügbarkeit, Eignung für maschinelle Lernanwendungen, rechtliche Einschränkungen, Robustheit, Skalierbarkeit, Interpretierbarkeit und Ressourcenanforderungen sicherstellen.Datenerfassung:
Ermöglichen Sie die Reproduzierbarkeit, indem Sie Daten sammeln, diese versionieren und einen konstanten Fluss realer und generierter Daten sicherstellen.Überprüfung der Datenqualität:
Stellen Sie die Qualität sicher, indem Sie Datenbeschreibungen, Anforderungen und Validierungen pflegen.Um Qualität und Reproduzierbarkeit sicherzustellen, müssen wir die statistischen Eigenschaften der Daten und den Datengenerierungsprozess aufzeichnen.
DatenvorbereitungDer zweite Schritt ist sehr einfach. Wir bereiten die Daten für die Modellierungsphase vor. Dazu gehören Datenauswahl, Datenbereinigung, Feature-Engineering, Datenverbesserung und -normalisierung.
1. Wir beginnen mit der Funktionsauswahl, der Datenauswahl und dem Umgang mit unausgeglichenen Klassen durch Überabtastung oder Unterabtastung.2. Konzentrieren Sie sich dann auf die Reduzierung von Rauschen und den Umgang mit fehlenden Werten. Zur Qualitätssicherung werden wir Dateneinheitstests hinzufügen, um fehlerhafte Werte zu reduzieren.
3. Je nach Modell führen wir Feature Engineering und Datenerweiterung wie One-Hot-Encoding und Clustering durch.4. Daten normalisieren und erweitern. Dadurch wird das Risiko verzerrter Merkmale verringert.
Um die Reproduzierbarkeit sicherzustellen, haben wir Datenmodellierungs-, Transformations- und Feature-Engineering-Pipelines erstellt. ModellentwicklungDie Einschränkungen und Anforderungen der Geschäfts- und Datenverständnisphase bestimmen die Modellierungsphase. Wir müssen die Geschäftsprobleme verstehen und wissen, wie wir Modelle für maschinelles Lernen entwickeln, um sie zu lösen. Wir werden uns auf die Modellauswahl, -optimierung und -schulung konzentrieren, um Modellleistungsmetriken, Robustheit, Skalierbarkeit, Interpretierbarkeit sowie die Optimierung von Speicher- und Rechenressourcen sicherzustellen. 1. Forschung zu Modellarchitektur und ähnlichen Geschäftsproblemen. 2. Definieren Sie Modellleistungsindikatoren. 3. Modellauswahl. 4. Fachwissen durch Einbindung von Experten verstehen. 5. Modeltraining. 6. Modellkomprimierung und -integration. Um Qualität und Reproduzierbarkeit sicherzustellen, speichern und versionieren wir Modellmetadaten, wie z. B. Modellarchitektur, Trainings- und Validierungsdaten, Hyperparameter und Umgebungsbeschreibungen. Abschließend werden wir ML-Experimente verfolgen und ML-Pipelines erstellen, um wiederholbare Trainingsprozesse zu erstellen. ModellbewertungIn dieser Phase testen wir das Modell und stellen sicher, dass es für den Einsatz bereit ist.Jeder Schritt der Beurteilungsphase wird zur Qualitätssicherung protokolliert.
Die Modellbereitstellung ist die Phase, in der wir Modelle für maschinelles Lernen in bestehende Systeme integrieren. Das Modell kann auf Servern, Browsern, Software und Edge-Geräten bereitgestellt werden. Vorhersagen aus dem Modell sind in BI-Dashboards, APIs, Webanwendungen und Plug-ins verfügbar.
Modellbereitstellungsprozess:
Modelle in Produktionsumgebungen erfordern eine kontinuierliche Überwachung und Wartung. Wir überwachen die Aktualität des Modells, die Hardwareleistung und die Softwareleistung.
Kontinuierliche Überwachung ist der erste Teil des Prozesses; wenn die Leistung unter einen Schwellenwert fällt, wird automatisch entschieden, das Modell anhand neuer Daten neu zu trainieren. Darüber hinaus beschränkt sich der Wartungsteil nicht nur auf die Umschulung des Modells. Es erfordert Entscheidungsmechanismen, die Erfassung neuer Daten, die Aktualisierung von Software und Hardware sowie die Verbesserung von ML-Prozessen auf der Grundlage von Geschäftsanwendungsfällen.
Kurz gesagt handelt es sich um die kontinuierliche Integration, Schulung und Bereitstellung von ML-Modellen.
Das Training und die Validierung von Modellen ist ein kleiner Teil von ML-Anwendungen. Um eine erste Idee in die Realität umzusetzen, sind mehrere Prozesse erforderlich. In diesem Artikel stellen wir CRISP-ML(Q) vor und wie es sich auf Risikobewertung und Qualitätssicherung konzentriert.
Wir definieren zunächst die Geschäftsziele, sammeln und bereinigen Daten, erstellen das Modell, verifizieren das Modell mit Testdatensätzen und stellen es dann in der Produktionsumgebung bereit.
Die Schlüsselkomponenten dieses Frameworks sind die kontinuierliche Überwachung und Wartung. Wir überwachen Daten sowie Software- und Hardware-Metriken, um zu entscheiden, ob das Modell neu trainiert oder das System aktualisiert werden soll.
Wenn Sie neu im Bereich maschineller Lernvorgänge sind und mehr erfahren möchten, lesen Sie den kostenlosen MLOps-Kurs, der von DataTalks.Club geprüft wurde. In allen sechs Phasen sammeln Sie praktische Erfahrungen und verstehen die praktische Umsetzung von CRISP-ML.
Originaltitel: Making Sense of CRISP-ML(Q): The Machine Learning Lifecycle Process, Autor: Abid Ali Awan
Das obige ist der detaillierte Inhalt vonInterpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen Lernens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 Einführung in das von vscode verwendete Framework
Einführung in das von vscode verwendete Framework
 Was bedeutet WLAN deaktiviert?
Was bedeutet WLAN deaktiviert?
 Linux-Systemzeit
Linux-Systemzeit
 So lösen Sie die Ausnahme „IllegalArgument'.
So lösen Sie die Ausnahme „IllegalArgument'.
 Welches OA-System ist besser?
Welches OA-System ist besser?
 Eine vollständige Liste häufig verwendeter öffentlicher DNS
Eine vollständige Liste häufig verwendeter öffentlicher DNS
 Verwendung der Switch-Anweisung
Verwendung der Switch-Anweisung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



