


In diesem Artikel werden einige Interviewfragen zum Knotenmodul mit Ihnen geteilt. Ich hoffe, dass er Ihnen hilft, die Fallstricke häufiger Modulprobleme schnell zu verstehen und das Interview erfolgreich zu bestehen.
![[Kompilieren und teilen] Einige Interviewfragen und -antworten im Zusammenhang mit Knotenmodulen (Sammlung)](https://img.php.cn/upload/article/000/000/024/641d8cf83fe1a283.jpg)
Wie aktualisiere ich eine js/json-Datei im laufenden Betrieb, ohne den Knotenprozess neu zu starten?
node.js-Cache und Hot-Update liegen eng beieinander Im Zusammenhang damit werfen wir zunächst einen kurzen Blick auf den Modulmechanismus von Node.js (das Bild unten stammt vom Master hyj1991).
Einfach ausgedrückt: Nachdem Modul A erforderlich ist, wird Modul A in den Cache gelegt und der Cache wird beim zweiten Mal abgerufen. Wenn Sie also nur die Datei ändern, wird die Datei nicht neu geladen, also müssen wir sie entfernen Zwischenspeichern, damit die Datei erneut geladen werden kann. [Empfohlene verwandte Tutorials: nodejs-Video-Tutorial, Programmierunterricht]

Einfach ausgedrückt sind die Schritte für das übergeordnete Modul A zur Einführung von Submodul B wie folgt:
require.cache hinzu (der Schlüssel ist der vollständige Pfad von Modul B)require.cache(其中 key 为模块 B 的全路径)children 数组中children
im Array vorhanden ist, ermitteln Sie, ob B im Array children des übergeordneten Moduls A vorhanden ist. Wenn es nicht vorhanden ist, fügen Sie hinzu die B-Modul-Referenz.
1.1 Bitte stellen Sie vor, was ein Modul in Node ist.
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
module.exports = Module;var module = new Module(filename, parent);
1.2 Bitte stellen Sie den Modullademechanismus von require vor
Diese Frage kann grundsätzlich das Verständnis des Interviewers für den Node-Modulmechanismus verstehen// require 其实内部调用 Module._load 方法
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
/********************************这里注意了**************************/
// 第三步:生成模块实例,存入缓存
// 这里的Module就是我们上面的1.1定义的Module
var module = new Module(filename, parent);
Module._cache[filename] = module;
/********************************这里注意了**************************/
// 第四步:加载模块
// 下面的module.load实际上是Module原型上有一个方法叫Module.prototype.load
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};// 上面(1.2部分)的第四步module.load(filename)
// 这一步,module模块相当于被包装了,包装形式如下
// 加载js模块,相当于下面的代码(加载node模块和json模块逻辑不一样)
(function (exports, require, module, __filename, __dirname) {
// 模块源码
// 假如模块代码如下
var math = require('math');
exports.area = function(radius){
return Math.PI * radius * radius
}
});// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
module.exports = {
hello: hello,
greet: greet
};// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
function hello() {
console.log('Hello, world!');
}
exports.hello = hello;
exports.greet = greet;Aber Sie können Exporten keinen Wert direkt zuweisen:
// 代码可以执行,但是模块并没有输出任何变量:
exports = {
hello: hello,
greet: greet
};Wenn Sie daran interessiert sind Oben bin ich sehr verwirrt über die Schreibweise. Keine Sorge, analysieren wir den Lademechanismus von Node:
首先,Node会把整个待加载的hello.js文件放入一个包装函数load中执行。在执行这个load()函数前,Node准备好了module变量:
var module = {
id: 'hello',
exports: {}
};
load()函数最终返回module.exports:
var load = function (exports, module) {
// hello.js的文件内容
...
// load函数返回:
return module.exports;
};
var exportes = load(module.exports, module);也就是说,默认情况下,Node准备的exports变量和module.exports变量实际上是同一个变量,并且初始化为空对象{},于是,我们可以写:
exports.foo = function () { return 'foo'; };
exports.bar = function () { return 'bar'; };也可以写:
module.exports.foo = function () { return 'foo'; };
module.exports.bar = function () { return 'bar'; };换句话说,Node默认给你准备了一个空对象{},这样你可以直接往里面加东西。
但是,如果我们要输出的是一个函数或数组,那么,只能给module.exports赋值:
module.exports = function () { return 'foo'; };给exports赋值是无效的,因为赋值后,module.exports仍然是空对象{}。
结论 如果要输出一个键值对象{},可以利用exports这个已存在的空对象{},并继续在上面添加新的键值;
如果要输出一个函数或数组,必须直接对module.exports对象赋值。
所以我们可以得出结论:直接对module.exports赋值,可以应对任何情况:
module.exports = {
foo: function () { return 'foo'; }
};或者:
module.exports = function () { return 'foo'; };最终,我们强烈建议使用module.exports = xxx的方式来输出模块变量,这样,你只需要记忆一种方法。
通过上面的问题,面试官又抛出一个问题,每个require的js文件,作用域如何保证独立呢?
其实每一个require的js文件,本身就是一个字符串, 文件是不是字符串嘛,所以我们需要一种机制能够把字符串编译为可以运行的javascript语言。
实际上从上面的讨论我们知道,require会把引入的js包裹在function中,所以它的作用域天然就是独立的。
接着讲本章的vm模块,vm模块和function都可以建立自己独立的作用域,并且vm、function、eval还可以把字符串当做目标代码执行。所以这三者的区别就需要面试者了解。
eval、Function,在执行目标代码时,会有一个最大的问题就是安全性,无论如何目标代码不能影响我正常的服务,也就是说,这个执行环境得是一个沙盒环境,而eval显然并不具备这个能力。如果需要一段不信任的代码放任它执行,那么不光服务,整个服务器的文件系统、数据库都暴露了。甚至目标代码会修改eval函数原型,埋入陷阱等等。
function也有一个安全问题就是可以修改全局变量,所有这种new Function的代码执行时的作用域为全局作用域,不论它的在哪个地方调用的,它访问的都是全局变量。
所以也有一定的安全隐患,接下来我们的主角vm模块登场。
使用vm的模块会比eval更为安全,因为vm模块运行的脚本完全无权访问外部作用域(或自行设置一个有限的作用域)。 脚本仍在同一进程中运行,因此为了获得最佳安全性。当然你可以给上下文传入一些通用的API方便开发:
vm.runInNewContext(`
const util = require(‘util’);
console.log(util);
`, {
require: require,
console: console
});此外,另一个开源库vm2针对vm的安全性等方面做了更多的提升,vm2。避免了一些运行脚本有可能“逃出”沙盒运行的边缘情况,语法也跟易于上手,很推荐使用。
npm的包管理机制你一定要了解,不仅仅是node需要,我们前端浏览器项目本身也会引用很多第三方模块。面试必备知识点。
下图摘自抖音前端团队的npm包管理机制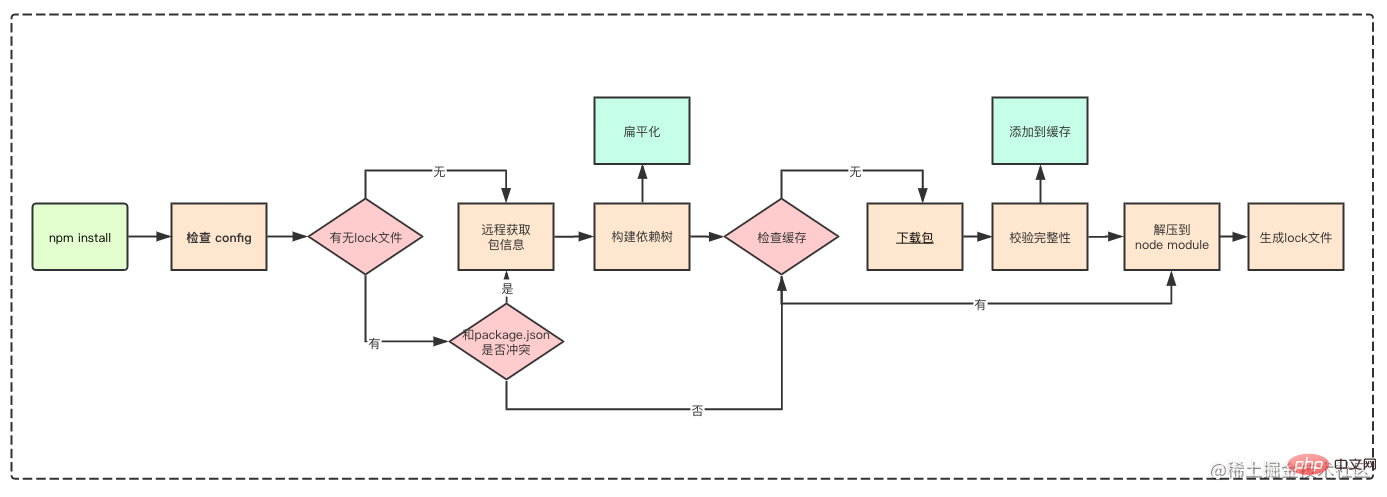
本图如果你理解的话,后面的内容就不用看了。
讲npm install 要从嵌套结构讲起
在 npm 的早期版本中,npm 处理依赖的方式简单粗暴,以递归的方式,严格按照 package.json 结构以及子依赖包的 package.json 结构将依赖安装到他们各自的 node_modules 中。
如下图: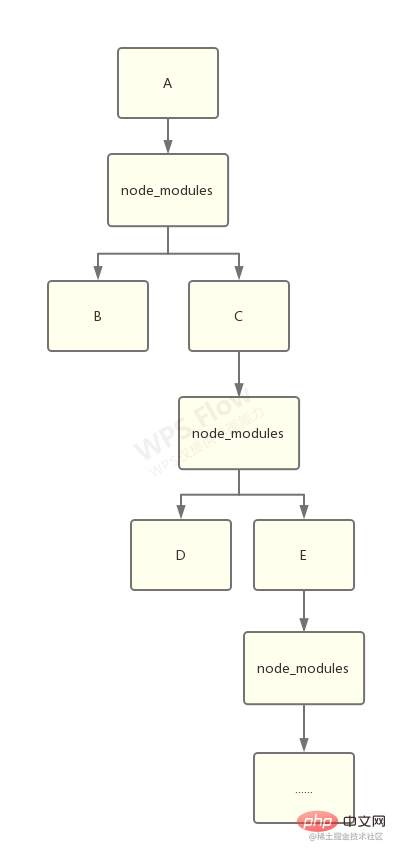 这样的方式优点很明显, node_modules 的结构和 package.json 结构一一对应,层级结构明显,并且保证了每次安装目录结构都是相同的。
这样的方式优点很明显, node_modules 的结构和 package.json 结构一一对应,层级结构明显,并且保证了每次安装目录结构都是相同的。
从上图这种情况,我们不难得出嵌套结构拥有以下缺点:
2016 年,yarn 诞生了。yarn 解决了 npm 几个最为迫在眉睫的问题:
如下图,我们简单看下什么是扁平化的结构:
没错,这就是扁平化依赖管理的结果。相比之前的嵌套结构,现在的目录结构类似下面这样: 假如之前嵌套的结构如下:
node_modules ├─ a | ├─ index.js | |- node_modules -└─ b | | ├─ index.js | | └─ package.json | └─ package.json
那么扁平化处理以后,就编程下面这样,被拍平了
node_modules ├─ a | ├─ index.js | └─ package.json └─ b ├─ index.js └─ package.json
但是扁平化的结构又会引出新的问题:
最主要的就是依赖结构的不确定性!
啥意思,我就懒得画图了,拿网上的一个例子来说:
想象一下有一个 library-a,它同时依赖了 library-b、c、d、e:
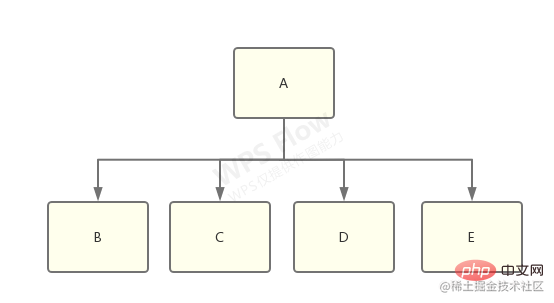
而 b 和 c 依赖了 f@1.0.0,d 和 e 依赖了 f@2.0.0:
这时候,node_modules 树需要做出选择了,到底是将 f@1.0.0 还是 f@2.0.0 扁平化,然后将另一个放到嵌套的 node_modules 中?
答案是:具体做那种选择将是不确定的,取决于哪一个 f 出现得更靠前,靠前的那个将被扁平化。
还有一个问题就是幽灵依赖,明明只安装a包,你却可以引用b包,因为a引用了b,并且扁平化处理了。
这就是为啥要有lock文件的原因,lock文件可以保证安装包的扁平化结构的稳定。
pnpm? 可以简单介绍一下为啥它能解决上面扁平化结构和幽灵依赖的问题。
答:不会, 先执行的导出其 未完成的副本, 通过导出工厂函数让对方从函数去拿比较好避免. 模块在导出的只是 var module = { exports: {...} }; 中的 exports。以下摘自阮一峰老师的博客:
CommonJS模块的重要特性是加载时执行,即脚本代码在require的时候,就会全部执行。CommonJS的做法是,一旦出现某个模块被"循环加载",就只输出已经执行的部分,还未执行的部分不会输出。
让我们来看,官方文档里面的例子。脚本文件a.js代码如下。
exports.done = false; var b = require('./b.js'); console.log('在 a.js 之中,b.done = %j', b.done); exports.done = true; console.log('a.js 执行完毕');
上面代码之中,a.js脚本先输出一个done变量,然后加载另一个脚本文件b.js。注意,此时a.js代码就停在这里,等待b.js执行完毕,再往下执行。
再看b.js的代码。
exports.done = false; var a = require('./a.js'); console.log('在 b.js 之中,a.done = %j', a.done); exports.done = true; console.log('b.js 执行完毕');
上面代码之中,b.js执行到第二行,就会去加载a.js,这时,就发生了"循环加载"。系统会去a.js模块对应对象的exports属性取值,可是因为a.js还没有执行完,从exports属性只能取回已经执行的部分,而不是最后的值。
a.js已经执行的部分,只有一行。
exports.done = false; 因此,对于b.js来说,它从a.js只输入一个变量done,值为false。
然后,b.js接着往下执行,等到全部执行完毕,再把执行权交还给a.js。于是,a.js接着往下执行,直到执行完毕。我们写一个脚本main.js,验证这个过程。
var a = require('./a.js'); var b = require('./b.js'); console.log('在 main.js 之中, a.done=%j, b.done=%j', a.done, b.done);
执行main.js,运行结果如下。
$ node main.js
在 b.js 之中,a.done = false b.js 执行完毕 在 a.js 之中,b.done = true a.js 执行完毕 在 main.js 之中, a.done=true, b.done=true
上面的代码证明了两件事。一是,在b.js之中,a.js没有执行完毕,只执行了第一行。二是,main.js执行到第二行时,不会再次执行b.js,而是输出缓存的b.js的执行结果,即它的第四行。
exports.done = true;
ES6模块的运行机制与CommonJS不一样,它遇到模块加载命令import时,不会去执行模块,而是只生成一个引用。等到真的需要用到时,再到模块里面去取值。
因此,ES6模块是动态引用,不存在缓存值的问题,而且模块里面的变量,绑定其所在的模块。请看下面的例子。
// m1.js export var foo = 'bar'; setTimeout(() => foo = 'baz', 500);
// m2.js
import {foo} from './m1.js';
console.log(foo);
setTimeout(() => console.log(foo), 500);上面代码中,m1.js的变量foo,在刚加载时等于bar,过了500毫秒,又变为等于baz。
让我们看看,m2.js能否正确读取这个变化。
$ babel-node m2.js bar baz
上面代码表明,ES6模块不会缓存运行结果,而是动态地去被加载的模块取值,以及变量总是绑定其所在的模块。
这导致ES6处理"循环加载"与CommonJS有本质的不同。ES6根本不会关心是否发生了"循环加载",只是生成一个指向被加载模块的引用,需要开发者自己保证,真正取值的时候能够取到值。
请看下面的例子(摘自 Dr. Axel Rauschmayer 的《Exploring ES6》)。
// a.js
import {bar} from './b.js';
export function foo() {
bar();
console.log('执行完毕');
}
foo();// b.js
import {foo} from './a.js';
export function bar() {
if (Math.random() > 0.5) {
foo();
}
}按照CommonJS规范,上面的代码是没法执行的。a先加载b,然后b又加载a,这时a还没有任何执行结果,所以输出结果为null,即对于b.js来说,变量foo的值等于null,后面的foo()就会报错。
但是,ES6可以执行上面的代码。
$ babel-node a.js 执行完毕
a.js之所以能够执行,原因就在于ES6加载的变量,都是动态引用其所在的模块。只要引用是存在的,代码就能执行。
会,作用域链的嘛。。。。
更多node相关知识,请访问:nodejs 教程!
Das obige ist der detaillierte Inhalt von[Kompilieren und teilen] Einige Interviewfragen und -antworten im Zusammenhang mit Knotenmodulen (Sammlung). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Ist Python Front-End oder Back-End?
Ist Python Front-End oder Back-End?
 node.js-Debugging
node.js-Debugging
 So implementieren Sie Instant Messaging im Frontend
So implementieren Sie Instant Messaging im Frontend
 Der Unterschied zwischen Front-End und Back-End
Der Unterschied zwischen Front-End und Back-End
 Einführung in die Beziehung zwischen PHP und Frontend
Einführung in die Beziehung zwischen PHP und Frontend
 Kann das Laufwerk C erweitert werden?
Kann das Laufwerk C erweitert werden?
 Windows prüft den Portbelegungsstatus
Windows prüft den Portbelegungsstatus
 Was bedeutet Chrom?
Was bedeutet Chrom?












![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



