


Dieser Artikel führt Sie durch die asynchrone Implementierung und das Ereignisfahren in Node. Ich hoffe, dass er für alle hilfreich ist!

Einige Aufgaben in Computern können im Allgemeinen in zwei Kategorien unterteilt werden, eine wird als IO-intensiv und die andere als rechenintensiv bezeichnet; bei rechenintensiven Aufgaben können Sie nur fortfahren herausdrücken Es wirkt sich auf die Leistung der CPU aus, ist aber für E/A-intensive Aufgaben idealerweise nicht erforderlich. Sie müssen nur das E/A-Gerät zur Verarbeitung benachrichtigen und dann nach einer Weile die Daten abrufen. [Verwandte Tutorial-Empfehlungen: nodejs-Video-Tutorial, Programmiervideo]
Für einige Szenarien müssen einige nicht verwandte Aufgaben ausgeführt werden:
node gab ihre Lösung vor den beiden: Verwenden Sie einen einzelnen Thread, um Multi-Thread-Deadlock, Zustandssynchronisierung und andere Probleme zu vermeiden. Verwenden Sie asynchrone E/A, um das Blockieren eines einzelnen Threads zu verhindern. um die CPU besser zu nutzennode在两者之前给出了它的方案:利用单线程,远离多线程死锁、状态同步等问题;利用异步IO,让单线程远离阻塞,以更好地使用CPU
刚才讲了
node在多任务处理的方案,但是node内部想要实现却并不容易,下面介绍操作系统的几个概念,方面后续大家更好理解,后面再讲一讲异步的实现以及node的事件循环机制:
操作系统中一切皆文件,输入输出设备同样被抽象为了文件,内核在执行IO操作时,通过文件描述符进行管理
非阻塞IO存在的一些问题:虽然其让CPU的利用率提高了,但是由于立即返回的是一个文件描述符,我们并不知道IO操作什么时候完成,为了确认状态变更,我们只能作轮询操作
read :最原始、性能最低的一种,通过重复检查IO状态来完成完整数据的获取select:通过对文件描述符上的事件状态来进行判断,相对来说消耗更少;缺点就是它采用了一个1024长度的数组来存储状态,所以它最多可以同时检查1024个文件描述符poll:由于select的限制,poll改进为链表的存储方式,其他的基本都一致;但是当文件描述符较多的时候,它的性能还是非常低下的eopll:该方案是linux下效率最高的IO事件通知机制,在进入轮询的时候如果没有检查IO事件,将会进行休眠,直到事件发生将它唤醒kqueue:与epoll类似,不过仅在FreeBSD系统下存在尽管epoll利用了事件来降低对CPU的耗用,但休眠期间CPU几乎是闲置的;我们期待的异步IO应该是应用程序发起非阻塞调用,无须通过遍历或事件唤醒等方式轮询,可以直接处理下一个任务,只需IO完成后通过信号或者回调将数据传递给应用程序即可。
linux下还有中AIO方式就是通过信号或回调来传递数据的,不过只有Linux有,并且有限制无法利用系统缓存
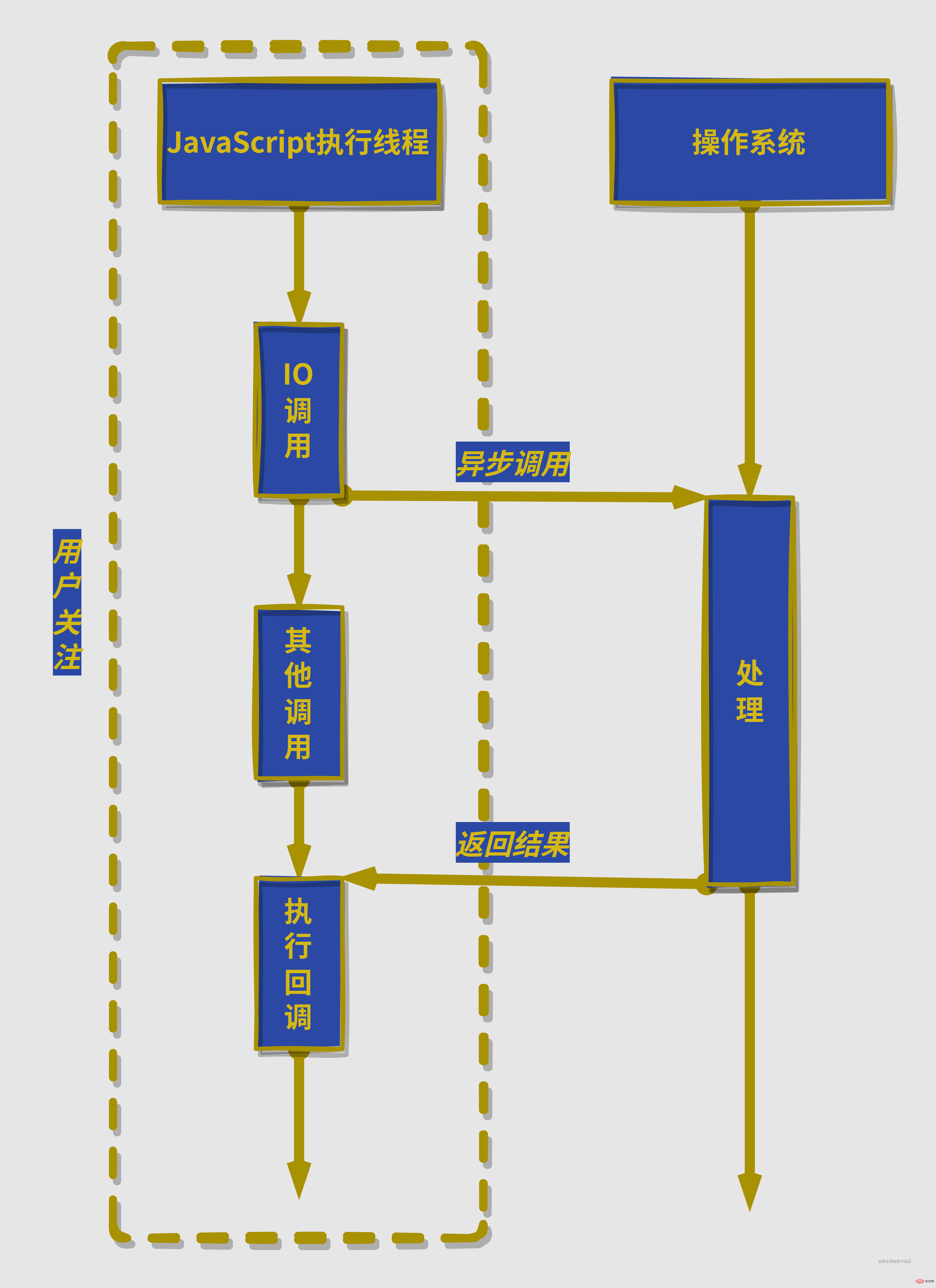
先说结论,node对异步IO的实现是通过多线程实现的。可能会混淆的地方就是node内部虽然是多线程的,但是我们程序员开发的JavaScript
node gesprochen, aber node Es ist nicht einfach, sie intern zu implementieren, damit Sie sie in Zukunft besser verstehen können. Später werden wir über die Implementierung der asynchronen Implementierung und den Ereignisschleifenmechanismus des Knotens sprechen read: Die primitivste und leistungsschwächste Methode vervollständigt die Erfassung von Vervollständigen Sie die Daten durch wiederholtes Überprüfen des E/A-Status. select code>: Die Beurteilung erfolgt durch Beurteilung des Ereignisstatus 🎜 anhand des 🎜Dateideskriptors. Der Nachteil besteht darin, dass ein 1024-Wert verwendet wird -length-Array zum Speichern des Status, sodass bis zu 1024 Dateideskriptoren gleichzeitig überprüft werden können 🎜🎜<code>poll: Aufgrund der Einschränkungen von select, poll wurde zu einer Speichermethode für verknüpfte Listen verbessert, und die anderen sind grundsätzlich gleich; wenn der Dateideskriptor jedoch größer ist als Meistens ist die Leistung immer noch sehr gering🎜🎜eopll: Diese Lösung ist der effizienteste IO-Ereignisbenachrichtigungsmechanismus unter linux. Wenn kein IO-Ereignis vorliegt, wird es in den Ruhezustand versetzt, bis das Ereignis eintritt, um es aufzuwecken🎜🎜kqueuecode>: Ähnlich wie <code>epoll, existiert aber nur unter dem FreeBSD-System🎜🎜🎜Obwohl epoll Ereignisse verwendet, um den CPU-Verbrauch zu reduzieren, ist die CPU im asynchronen Zustand fast im Leerlauf Wir gehen davon aus, dass IO ein nicht blockierender Aufruf sein sollte, der von der Anwendung initiiert wird, ohne dass eine Abfrage durch Durchquerung oder Ereignisaktivierung erforderlich ist. Sie können die nächste Aufgabe direkt bearbeiten und die Daten anschließend einfach über ein Signal oder einen Rückruf an die Anwendung übergeben Das IO ist abgeschlossen. 🎜🎜🎜Es gibt auch eine AIO-Methode unter Linux, die Daten über Signale oder Rückrufe überträgt, diese ist jedoch nur unter Linux verfügbar und es gibt Einschränkungen, die den Systemcache nicht verwenden können🎜🎜node asynchrone E/A durch Multithreading implementiert. Was möglicherweise verwirrend ist, ist, dass node zwar intern multithreaded ist, der von unseren Programmierern entwickelte JavaScript-Code jedoch nur in einem einzigen Thread ausgeführt wird. 🎜node verwendet einige Threads, um blockierende E/A oder nicht blockierende E/A durchzuführen, plus Abfragetechnologie, um die Datenerfassung abzuschließen, sodass ein Thread die Berechnungsverarbeitung durchführen und die von E/A erhaltenen Daten durch Kommunikation zwischen Threads übertragen kann Implementiert problemlos die asynchrone IO-Simulation. node通过部分线程进行阻塞IO或者非阻塞IO加上轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将IO得到的数据进行传递,这就轻松实现了异步IO的模拟。
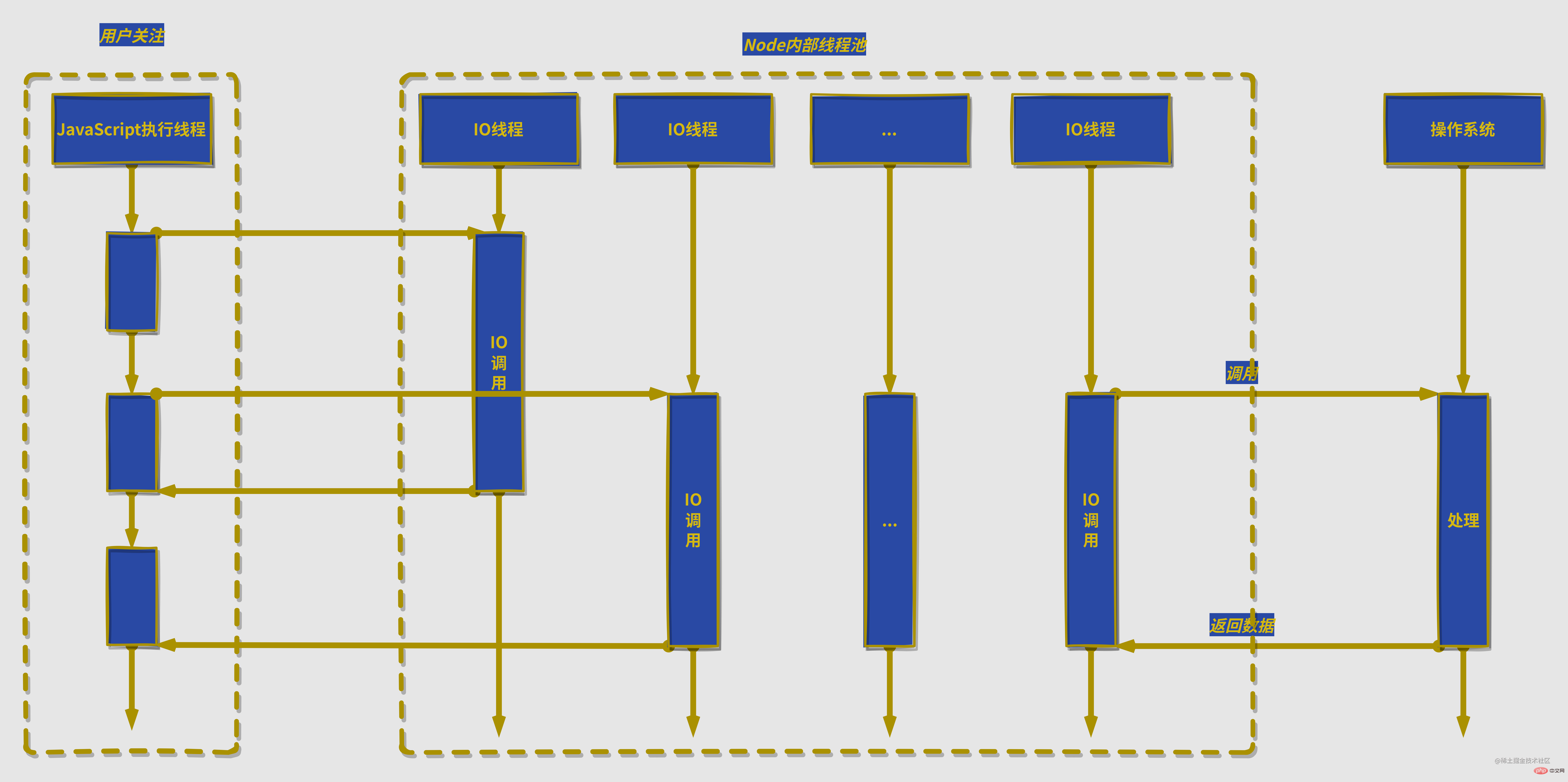
除了异步IO,计算机中的其他资源也适用,因为linux中一切皆文件,磁盘、硬件、套接字等几乎所有计算机资源都被抽象为了文件,接下来介绍对计算机资源的调用都以IO为例子。
在进程启动时,node便会创建一个类似与while(true)的循环,每执行一次循环体的过程我们成为Tick;
下方为node中事件循环流程图:
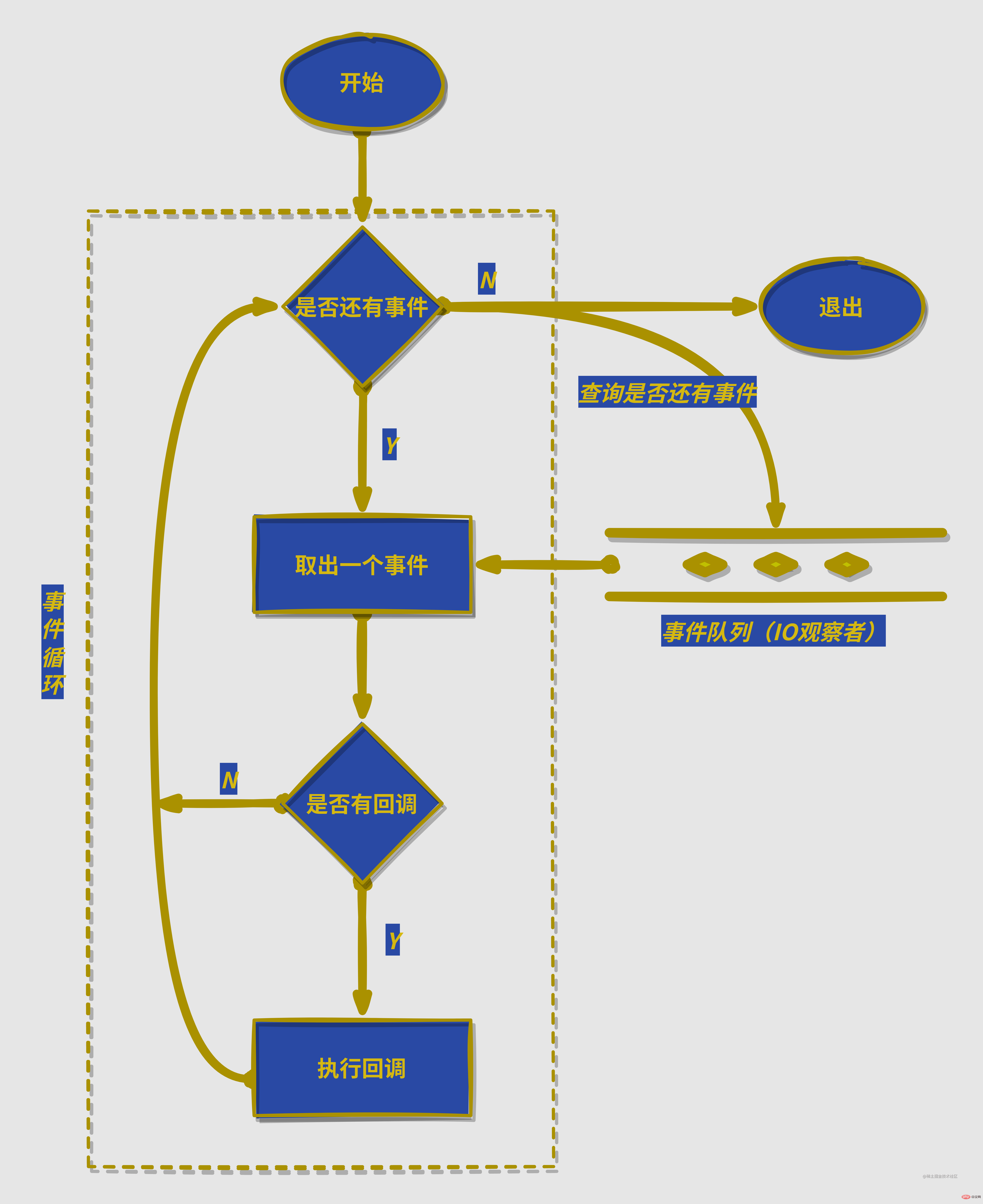
很简单的一张图,简单解释一下:就是每次都从IO观察者里面获取执行完成的事件(是个请求对象,简单理解就是包含了请求中产生的一些数据),然后没有回调函数的话就继续取出下一个事件(请求对象),有回调就执行回调函数
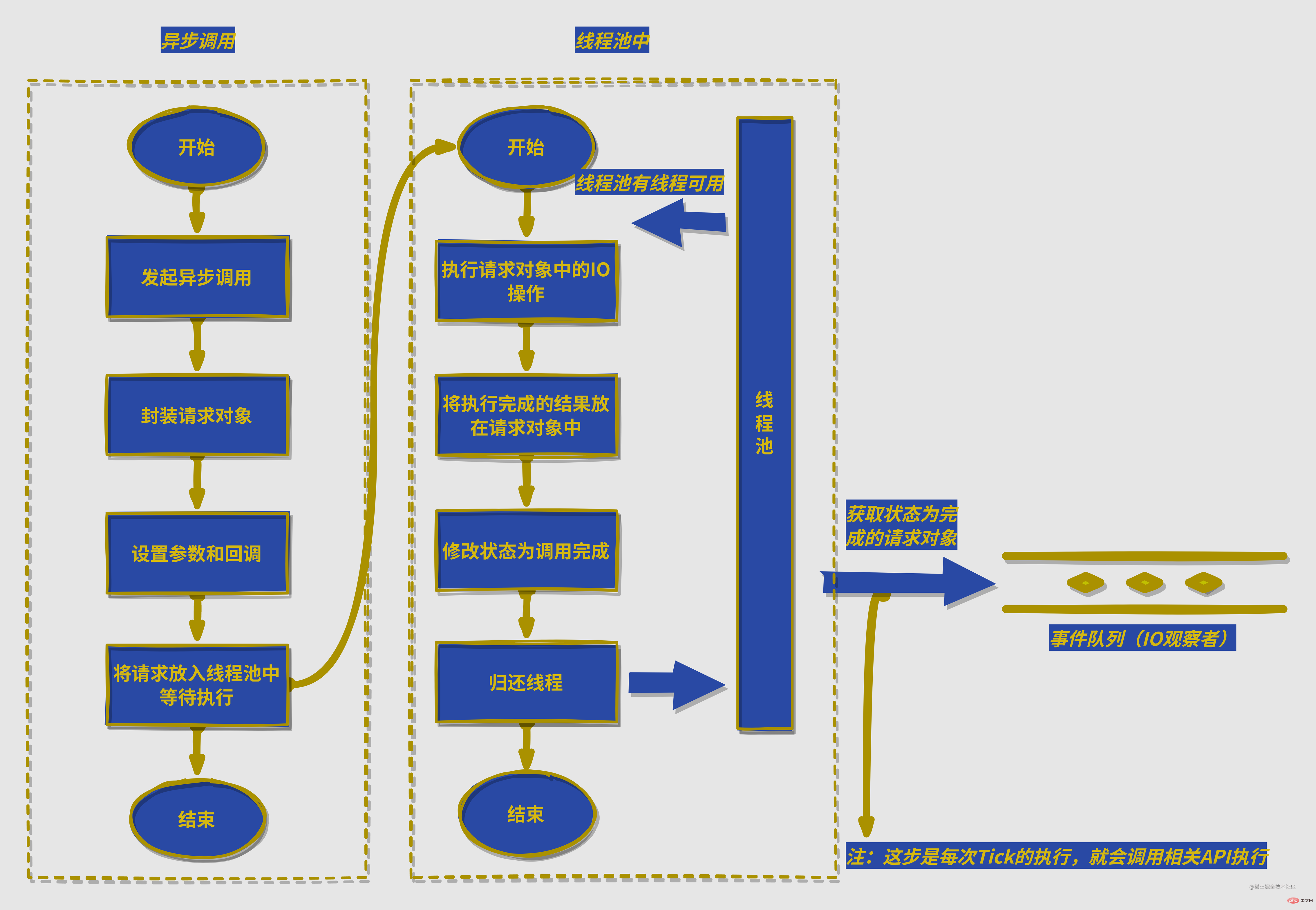
注:不同平台有不同的细节实现,这张图隐藏了相关平台兼容细节,比如windows下使用IOCP中的
PostQueuedCompletionStatus()提交执行状态,通过GetQueuedCompletionStatus获取执行完成的请求,并且IOCP内部实现了线程池的细节,而linux等平台通过eopll实现这个过程,并在libuv下自实现了线程池
setTimtout与setInterval除了IO等计算机资源需要异步调用之外,node本身还存在一些与异步IO无关的一些其他异步API:
setTimeoutsetIntervalsetImmediateprocess.nextTick该小节先讲解前面两个api
它们的实现原理与异步IO比较类似,只是不需要IO线程池的参与:
setTimtout与setInterval创建的定时器会被插入到定时器观察者内部的一个红黑树中tick
Wenn der Prozess startet, erstelltnodeein Ereignis ähnlich wiewhile (true)-Schleife, jedes Mal, wenn der Schleifenkörper ausgeführt wird, werden wir zuTick. Das Folgende ist das Flussdiagramm der Ereignisschleife innode:
node selbst hat auch einige Probleme, die nichts mit asynchronem IO zu tun haben. EinigeAndere asynchrone APIs: setTimeoutsetImmediateprocess.nextTicksetTimtout und setInterval erstellte Timer wird dies tun in einen rot-schwarzen Baum innerhalb des Timer-Beobachters eingefügt werdenjedes Mal tickBei der Ausführung wird das Timer-Objekt iterativ aus dem rot-schwarzen Baum entnommen und überprüft, ob der Timer überschritten wird. Wenn dies der Fall ist, wird das Ereignis (Anforderungsobjekt) in die Ereigniswarteschlange verschoben und in der Ereignisschleife ausgeführt -Balancing. Die Sucheffizienz ist im Wesentlichen die Tiefe des Binärbaumsg 🎜🎜🎜 🎜2🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜n🎜🎜)🎜🎜🎜 🎜🎜🎜🎜🎜Haben Sie jemals über dieses Problem nachgedacht? Wenn Sie die Implementierungsprinzipien von asynchronem IO in den vorherigen Kapiteln verstanden haben, glaube ich Sollte es erklären können, hier eine kurze Erklärung der Gründe, Ihr Gedächtnis zu vertiefen: 🎜Der IO-Thread-Pool in node ist eine Möglichkeit, IO aufzurufen und auf die Rückgabe von Daten zu warten (siehe spezifische Implementierung). Er ermöglicht den Aufruf eines einzelnen Threads von JavaScript IO asynchron, und es besteht keine Notwendigkeit, auf den Abschluss der IO-Ausführung zu warten (da der IO-Thread-Pool dies tut), und die endgültigen Daten können abgerufen werden (über den Beobachtermodus: Der IO-Beobachter erhält das Ausführungsabschlussereignis vom Thread-Pool und der Ereignisschleifenmechanismus führen nachfolgende Rückrufe aus (Funktion)node中的IO线程池是用来调用IO并等待数据返回(看具体实现)的一种方式,它使JavaScript单线程得以异步调用IO,并且不需要等待IO执行完成(因为是IO线程池做了),并且能获取到最终的数据(通过观察者模式:IO观察者从线程池获取执行完成的事件,事件循环机制执行后续的回调函数)
上述这段话可能有点简略,如果你还不明白,可以看下之前的那几种图~
process.nextTick与setImmediate这两个函数都是代表立即异步执行一个函数,那为什么不用setTimeout(() => { ... }, 0)来完成呢?
process.nextTick更加轻量轻量具体来说:我们在每次调用process.nextTick的时候,只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器中采用红黑树的方式时,nextTick为
那process.nextTick与setImmediate又有什么区别呢?毕竟它们都是将回调函数立即异步执行
process.nextTick的回调执行优先级高于setImmediate
process.nextTick的回调函数保存在一个数组中,每轮事件循环下全部执行,setImmediate的结果则是保存在链表中,每轮循环按序执行第一个回调注意:之所以process.nextTick的回调执行优先级高于setImmediate,因为事件循环对观察者的检查是有顺序的,process.nextTick属于idle观察者,setImmediate属于check观察者。iedl观察者 > IO 观察者 > check观察者
对于网络套接字的处理,
node也应用到了异步IO,网络套接字上侦听到的请求都会形成事件交给IO观察者,事件循环会不停地处理这些网络IO事件,如果我们在JavaScrpt层面上有传入对应的回调函数,这些回调函数就会在事件循环中执行(处理这些网络请求)
常见的服务器模型:
而node采用的是事件驱动的方式处理这些请求,无需对每个请求创建额外的对应线程,可以省略掉创建线程和销毁线程的开销,同时操作系统的调度任务因为线程较少(只有node
process .nextTick und setImmediate
setTimeout(() => { ... }, 0) verwenden, um es abzuschließen? 🎜 Process.nextTickLeichtgewichtiger
process.nextTick aufrufen, stellen wir nur die Rückruffunktion wie folgt in die Warteschlange aus und nach einer Tick-Runde ausführen. Bei Verwendung der Rot-Schwarz-Baum-Methode im TimerO(l og2 span >n), nextTick forO(1) 🎜🎜Was ist der Unterschied zwischen process.nextTick und setImmediate? Schließlich führen sie alle die Rückruffunktion sofort asynchron aus🎜process.nextTick ist höher als die von setImmediate
setImmediate wird in einem verknüpften Array gespeichert Liste, und jede Runde der Schleife führt der Reihe nach den ersten Rückruf ausprocess.nextTick höher ist von setImmediate liegt daran, dass die Ereignisschleife den Beobachter überprüft. Es ist in Ordnung, process.nextTick gehört zum idle-Beobachter und setImmediate gehört zum check-Beobachter. iedl Observer> IO Observer> sockets, <code>node wird auch auf asynchrone IOs angewendet, die auf dem Netzwerk-Socket abgehört werden, und an IO-Beobachter übergeben werden. Die Ereignisschleife verarbeitet diese Netzwerk-IOs kontinuierlich In entsprechenden Rückruffunktionen auf der JavaSccrpt-Ebene werden diese Rückruffunktionen in der Ereignisschleife ausgeführt (Verarbeitung dieser Netzwerkanforderungen) 🎜🎜Übliche Servermodelle: 🎜node implementiert.) Der Kontextwechsel ist kostengünstig. 🎜Klassisches Problem – Avalanche-ProblemLösung:
Problembeschreibung: Wenn der Server gerade gestartet wird, befinden sich keine Daten im Cache. Wenn die Zugriffsmenge groß ist, wird dies der Fall sein für wiederholte Abfragen an die Datenbank gesendet werden, was Auswirkungen auf die Leistung hat. SQL会被发送到数据库中反复查询,影响性能。
解决方案:
const proxy = new events.EventEmitter();
let status = "ready"; // 状态锁,避免反复查询
const select = function(callback) {
proxy.once("selected", callback); // 绑定一个只执行一次名为selected的事件
if(status === "ready") {
status = "pending";
// sql
db.select("SQL", (res) => {
proxy.emit("selected", res); // 触发事件,返回查询数据
status = "ready";
})
}
}使用once
Das obige ist der detaillierte Inhalt vonLassen Sie uns über asynchrone Implementierung und Ereignissteuerung in Node sprechen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Ist Python Front-End oder Back-End?
Ist Python Front-End oder Back-End?
 node.js-Debugging
node.js-Debugging
 So implementieren Sie Instant Messaging im Frontend
So implementieren Sie Instant Messaging im Frontend
 Der Unterschied zwischen Front-End und Back-End
Der Unterschied zwischen Front-End und Back-End
 Einführung in die Hauptarbeitsinhalte des Backends
Einführung in die Hauptarbeitsinhalte des Backends
 Einführung in die Beziehung zwischen PHP und Frontend
Einführung in die Beziehung zwischen PHP und Frontend
 So öffnen Sie JSP
So öffnen Sie JSP
 Linux-Versionsinformationen anzeigen
Linux-Versionsinformationen anzeigen











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



