


Wie lade ich mit So verwenden Sie So verwenden Sie Python, um Bilder gleichzeitig mit mehreren Threads herunterzuladen, um Bilder gleichzeitig mit mehreren Threads herunterzuladen eine große Anzahl von Bildern herunter? Im folgenden Artikel erfahren Sie, wie Sie mit So verwenden Sie So verwenden Sie Python, um Bilder gleichzeitig mit mehreren Threads herunterzuladen, um Bilder gleichzeitig mit mehreren Threads herunterzuladen Bilder gleichzeitig mit mehreren Threads herunterladen. Ich hoffe, er ist hilfreich für Sie!

Manchmal dauert es Stunden, eine große Anzahl von Bildern herunterzuladen – lassen Sie uns das beheben
Ich verstehe – Sie haben es satt, darauf zu warten, dass Ihr Programm Bilder herunterlädt. Manchmal muss ich Tausende von Bildern herunterladen, was Stunden dauert, und Sie können nicht darauf warten, dass Ihr Programm diese dummen Bilder herunterlädt. Sie haben viele wichtige Dinge zu erledigen.
Lassen Sie uns ein einfaches Bild-Downloader-Skript erstellen, das eine Textdatei liest und alle in einem Ordner aufgelisteten Bilder superschnell herunterlädt.
Das ist es, was wir am Ende aufbauen werden.
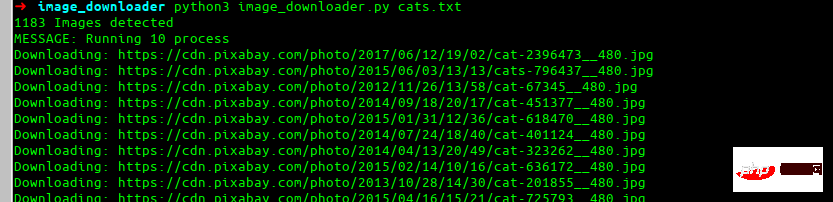

Lassen Sie uns die Lieblingsanfragebibliothek aller installieren.
pip install requests
Jetzt sehen wir einen grundlegenden Code zum Herunterladen einer einzelnen URL und zum Versuch, den Bildnamen automatisch zu finden und wie Wiederholungsversuche verwendet werden.
import requests
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1Hier versuchen wir fünfmal, das Bild herunterzuladen, falls es fehlschlägt. Versuchen wir nun, den Namen des Bildes automatisch zu finden und zu speichern.
import more required library
import io
from PIL import Image
# lets try to find the image name
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]Angenommen, die URL, die wir herunterladen möchten, lautet:
instagram.fktm7-1.fna.fbcdn.net/vp...
Okay, das ist ein Durcheinander. Lassen Sie uns aufschlüsseln, was der Code für die URL bewirkt. Wir verwenden zuerst rfind, um den letzten Schrägstrich (/) zu finden und wählen dann alles danach aus. Hier sind die Ergebnisse: rfind 找到最后一个正斜杠(/),然后选择之后的所有内容。这是结果:
65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
现在我们的第二部分找到一个 ?,然后只取它前面的任何东西。
这是我们最终的图像名称:
65872070_1200425330158967_6201268309743367902_n.jpg
这个结果非常好,适用于大多数用例。
现在我们已经下载了图像名称和图像,我们将保存它。
i = Image.open(io.BytesIO(res.content)) i.save(image_name)
如果你在想,「我到底应该怎么使用上面的代码?」那么你的想法是正确的。这是一个漂亮的函数,我们在上面所做的一切都被扁平处理了。在这里,我们还测试了下载的类型是否为图像,以防找不到图像名称。
def image_downloader(img_url: str):
"""
Input:
param: img_url str (Image url)
Tries to download the image url and use name provided in headers. Else it randomly picks a name
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1
# checking the type for image
if 'image' not in res.headers.get("content-type", ''):
print('ERROR: URL doesnot appear to be an image')
return False
# Trying to red image name from response headers
try:
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
except:
image_name = str(random.randint(11111, 99999))+'.jpg'
i = Image.open(io.BytesIO(res.content))
download_location = 'cats'
i.save(download_location + '/'+image_name)
return f'Download complete: {img_url}'现在,你可能会问:「这个人所说的多处理在哪里?」。
这很简单。我们将简单地定义我们的池并将我们的函数和图像 URL 传递给它。
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)让我们把它放在一个函数中:
def run_downloader(process:int, images_url:list):
"""
Inputs:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)再一次,你可能会说,「这一切都很好,但我想立即开始下载我的 1000 张图像列表。我不想复制和粘贴所有这些代码并试图弄清楚如何合并所有内容。」
这是一个完整的脚本。它执行以下操作:
以图像列表文本文件和进程号作为输入
按照您想要的速度下载它们
打印下载文件的总时间
还有一些不错的函数可以帮助我们读取文件名并处理错误和其他东西
# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通过读取终端中作为参数提供的 txt 文件返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
输入选项:
参数: img_url str (Image url)
尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1
# checking the type for image
if 'image' not in res.headers.get("content-type", ''):
print('ERROR: URL doesnot appear to be an image')
return False
# Trying to red image name from response headers
try:
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
except:
image_name = str(random.randint(11111, 99999))+'.jpg'
i = Image.open(io.BytesIO(res.content))
download_location = get_download_location()
i.save(download_location + '/'+image_name)
return f'Download complete: {img_url}'
def run_downloader(process:int, images_url:list):
"""
输入项:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)
try:
num_process = int(sys.argv[2])
except:
num_process = 10
images_url = get_urls()
run_downloader(num_process, images_url)
end = time.time()
print('Time taken to download {}'.format(len(get_urls())))
print(end - start)将其保存到 So verwenden Sie So verwenden Sie Python, um Bilder gleichzeitig mit mehreren Threads herunterzuladen, um Bilder gleichzeitig mit mehreren Threads herunterzuladen 文件中,然后运行它。
python3 image_downloader.py cats.txt
这是 GitHub 存储库的链接。
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process>
这将读取文本文件中的所有 URL,并将它们下载到名称与文件名相同的文件夹中。
num_of_process
65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111Jetzt unser zweiter Teil Finden Sie einfach einen ? und nehmen Sie einfach etwas hinein Front.
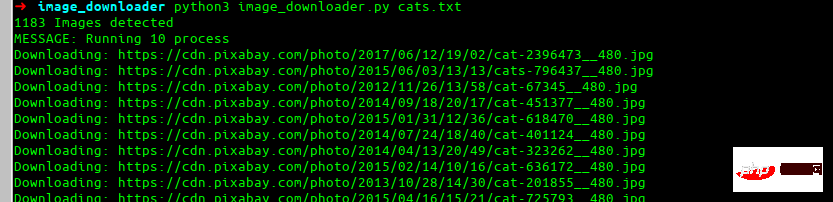

python3 image_downloader.py cats.txt
num_of_process ist optional (standardmäßig werden 10 Prozesse verwendet). 🎜🎜🎜🎜Beispiel🎜🎜🎜rrreee🎜🎜🎜🎜🎜🎜🎜Ich würde mich über jede Antwort freuen, wie ich das noch weiter verbessern kann. 🎜🎜【Verwandte Empfehlungen: 🎜So verwenden Sie So verwenden Sie Python, um Bilder gleichzeitig mit mehreren Threads herunterzuladen, um Bilder gleichzeitig mit mehreren Threads herunterzuladen3-Video-Tutorial🎜】🎜Das obige ist der detaillierte Inhalt vonSo verwenden Sie Python, um Bilder gleichzeitig mit mehreren Threads herunterzuladen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



