


Empfohlenes Lernen: Redis-Video-Tutorial
Vorwort: Das Problem der Schnittstellen-Idempotenz ist ein öffentliches Problem, das für Entwickler nichts mit Sprache zu tun hat. Bei einigen Benutzeranfragen kann es sein, dass sie wiederholt gesendet werden. Wenn es sich um einen Abfragevorgang handelt, handelt es sich bei einigen um Schreibvorgänge, die jedoch schwerwiegende Folgen haben können Bei wiederholter Nachfrage nach der Schnittstelle kann es zu wiederholten Bestellungen kommen. Schnittstellen-Idempotenz bedeutet, dass die Ergebnisse einer oder mehrerer vom Benutzer initiierter Anforderungen für denselben Vorgang konsistent sind und es keine Nebenwirkungen durch mehrere Klicks gibt. 接口幂等性问题,对于开发人员来说,是一个跟语言无关的公共问题。对于一些用户请求,在某些情况下是可能重复发送的,如果是查询类操作并无大碍,但其中有些是涉及写入操作的,一旦重复了,可能会导致很严重的后果,例如交易的接口如果重复请求可能会重复下单。接口幂等性是指用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
在HTTP/1.1中,对幂等性进行了定义。它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果,即第一次请求的时候对资源产生了副作用,但是以后的多次请求都不会再对资源产生副作用。这里的副作用是不会对结果产生破坏或者产生不可预料的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
这类问题多发于接口的:
insert操作,这种情况下多次请求,可能会产生重复数据。update操作,如果只是单纯的更新数据,比如:update user set status=1 where id=1,是没有问题的。如果还有计算,比如:update user set status=status+1 where id=1,这种情况下多次请求,可能会导致数据错误。在接口调用时一般情况下都能正常返回信息不会重复提交,不过在遇见以下情况时可以就会出现问题,如:
本文讨论的是如何在服务端优雅地统一处理这种接口幂等性情况,如何禁止用户重复点击等客户端操作不在此次讨论范围。
幂等性是为了简化客户端逻辑处理,能放置重复提交等操作,但却增加了服务端的逻辑复杂性和成本,其主要是:
所以在使用时候需要考虑是否引入幂等性的必要性,根据实际业务场景具体分析,除了业务上的特殊要求外,一般情况下不需要引入的接口幂等性。
幂等意味着一条请求的唯一性。不管是你哪个方案去设计幂等,都需要一个全局唯一的ID ,去标记这个请求是独一无二的。
全局唯一性ID,我们怎么去生成呢?你可以回想下,数据库主键Id怎么生成的呢?
是的,我们可以使用UUID
insert-Vorgang In diesem Fall können mehrere Anfragen zu doppelten Daten führen. update-Vorgang: Wenn Sie nur Daten aktualisieren, zum Beispiel: update user set status=1 where id=1, gibt es kein Problem. Bei Berechnungen wie: update user set status=status+1 where id=1 können mehrere Anfragen in diesem Fall zu Datenfehlern führen. UUID verwenden, aber die Nachteile von UUID liegen auf der Hand. Die Zeichenfolge nimmt viel Platz ein, die generierte ID ist zu zufällig, schlecht lesbar und erhöht sich nicht. 🎜Wir können auch den Snowflake-Algorithmus (Snowflake) verwenden, um eindeutige IDs zu generieren. 雪花算法(Snowflake) 生成唯一性ID。
雪花算法是一种生成分布式全局唯一ID的算法,生成的ID称为Snowflake IDs。这种算法由Twitter创建,并用于推文的ID。
一个Snowflake ID有64位。
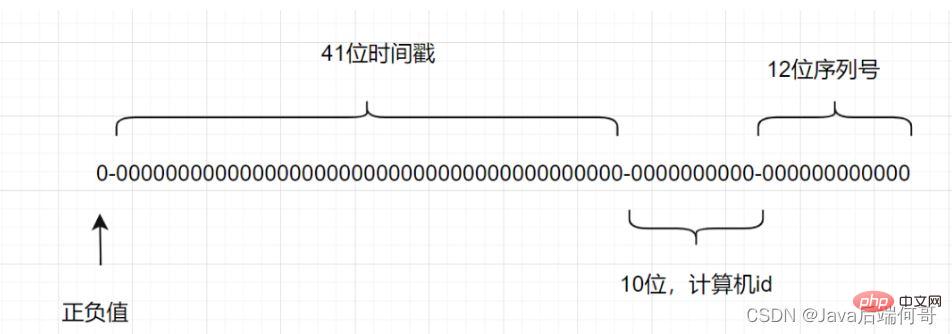
当然,全局唯一性的ID,还可以使用百度的Uidgenerator,或者美团的Leaf。
幂等处理的过程,说到底其实就是过滤一下已经收到的请求,当然,请求一定要有一个全局唯一的ID标记
Snowflake-IDs genannt. Dieser Algorithmus wurde von Twitter erstellt und wird für Tweet-IDs verwendet. Eine Snowflake-ID hat 64 Bit. 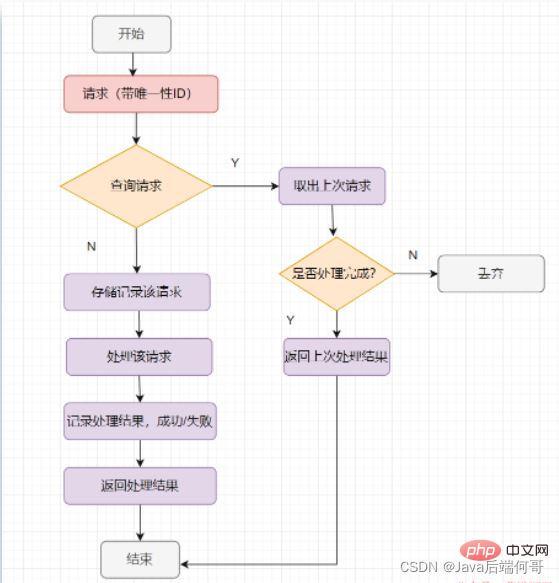
Natürlich ist die weltweit eindeutige ID, Sie können auch den Uidgenerator von Baidu oder den Leaf von Meituan verwenden.
globalen eindeutigen ID-Taghaben >Ha. Wie kann dann festgestellt werden, ob die Anfrage schon einmal eingegangen ist? Speichern Sie die Anfrage. Überprüfen Sie zunächst den Speicherdatensatz. Wenn der Datensatz vorhanden ist, wird das letzte Ergebnis zurückgegeben. Wenn es vorhanden ist, bedeutet dies, dass die nachgelagerte Anfrage nach der Seriennummer verarbeitet wurde. Zu diesem Zeitpunkt können Sie direkt auf die Fehlermeldung der wiederholten Anfrage reagieren.
Wenn er nicht vorhanden ist, verwenden Sie den Schlüssel als Redis-Schlüssel, verwenden Sie die Downstream-Schlüsselinformationen als gespeicherten Wert (z. B. einige vom Downstream-Anbieter übergebene Geschäftslogikinformationen), speichern Sie das Schlüssel-Wert-Paar in Redis und Führen Sie dann die entsprechende Geschäftslogik normal aus. 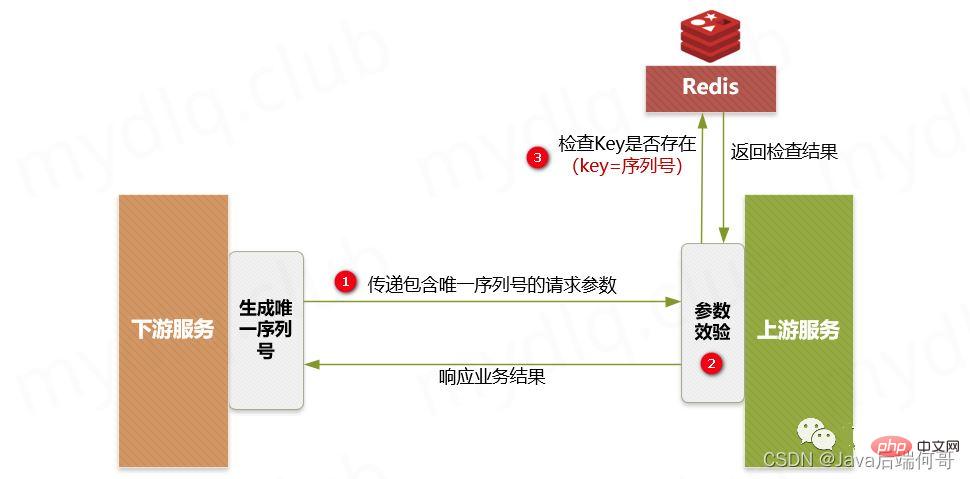
Antierbarer Betrieb:
Usage Beschränkungen:
🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 einen dritten Partner übergeben, um eine eindeutige Seriennummer zu übergeben; Redis zur Datenvalidierung; 🎜🎜 🎜Hauptprozess: 🎜🎜🎜🎜🎜 Hauptschritte: 🎜🎜🎜 Der Downstream-Dienst generiert eine verteilte ID als Seriennummer und führt dann die Anforderung zum Aufrufen der Upstream-Schnittstelle zusammen mit dem „einzigartigen“ aus Seriennummer“ und die angeforderte „Authentifizierungs-ID“. 🎜🎜 Der Upstream-Dienst führt eine Sicherheitsüberprüfung durch und erkennt, ob die „Seriennummer“ und die „Anmeldeinformations-ID“ in den Downstream-Parametern vorhanden sind. 🎜🎜 Der Upstream-Dienst erkennt, ob in Redis ein Schlüssel vorhanden ist, der aus der entsprechenden „Seriennummer“ und „Authentifizierungs-ID“ besteht. Wenn dieser vorhanden ist, löst er eine Ausnahmemeldung zur wiederholten Ausführung aus und antwortet dann auf die entsprechende Fehlermeldung flussabwärts. Wenn dies nicht der Fall ist, wird die Kombination aus „Seriennummer“ und „Authentifizierungs-ID“ als Schlüssel verwendet, und die Downstream-Schlüsselinformationen werden als Wert verwendet und dann in Redis und dann in der nachfolgenden Geschäftslogik gespeichert normal ausgeführt werden. 🎜🎜🎜In den obigen Schritten müssen Sie beim Einfügen von Daten in Redis die Ablaufzeit festlegen. Dadurch wird sichergestellt, dass innerhalb dieses Zeitraums bei wiederholtem Aufruf der Schnittstelle eine Beurteilung und Identifizierung erfolgen kann. Wenn die Ablaufzeit nicht festgelegt ist, wird wahrscheinlich eine unbegrenzte Datenmenge in Redis gespeichert, was dazu führt, dass Redis nicht ordnungsgemäß funktioniert. 🎜🎜🎜3.2. Anti-Duplikat-Token-Token🎜🎜🎜Projektbeschreibung: 🎜🎜Angesichts der kontinuierlichen Klicks des Kunden oder der Timeout-Wiederholungsversuche des Anrufers, z. B. beim Senden einer Bestellung, kann dieser Vorgang den Token-Mechanismus verwenden, um wiederholte Übermittlungen zu verhindern. Vereinfacht ausgedrückt fordert der Aufrufer beim Aufruf der Schnittstelle zunächst eine globale ID (Token) vom Backend an und trägt diese globale ID mit der Anfrage (am besten fügt man das Token in Header ein). Das Backend muss dieses Token verwenden Als Schlüssel werden die Benutzerinformationen als Wert zur Überprüfung des Schlüsselwertinhalts an Redis gesendet. Wenn der Schlüssel vorhanden ist und der Wert übereinstimmt, wird der Löschbefehl ausgeführt, und dann wird die nachfolgende Geschäftslogik normal ausgeführt. Wenn kein entsprechender Schlüssel vorhanden ist oder der Wert nicht übereinstimmt, wird eine wiederholte Fehlermeldung zurückgegeben, um idempotente Operationen sicherzustellen. 🎜
Nutzungsbeschränkungen:
Hauptprozess:
Der Server stellt eine Schnittstelle zum Erhalten von Token bereit. Dies kann eine Sequenznummer sein, die auch eine verteilte ID oder UUID-Zeichenfolge sein kann.
Der Client ruft die Schnittstelle auf, um das Token zu erhalten. Zu diesem Zeitpunkt generiert der Server eine Token-Zeichenfolge.
Speichern Sie dann die Zeichenfolge in der Redis-Datenbank und verwenden Sie dabei das Token als Redis-Schlüssel (beachten Sie die Ablaufzeit).
Geben Sie das Token an den Kunden zurück. Nachdem der Kunde es erhalten hat, sollte es im versteckten Feld des Formulars gespeichert werden.
Wenn der Client das Formular ausführt und absendet, speichert er das Token in den Headern und überträgt die Header bei der Ausführung der Geschäftsanfrage.
Nach Erhalt der Anfrage ruft der Server das Token aus den Headern ab und prüft dann anhand des Tokens, ob der Schlüssel in Redis vorhanden ist.
Der Server bestimmt, ob der Schlüssel in Redis vorhanden ist. Wenn er vorhanden ist, löschen Sie den Schlüssel und führen Sie dann die Geschäftslogik normal aus. Wenn es nicht vorhanden ist, wird eine Ausnahme ausgelöst und bei wiederholten Übermittlungen wird eine Fehlermeldung zurückgegeben.
Beachten Sie, dass unter gleichzeitigen Bedingungen beim Ausführen der Redis-Datensuche und -löschung die Atomizität sichergestellt werden muss, andernfalls kann die Idempotenz unter Parallelität möglicherweise nicht garantiert werden. Seine Implementierung kann verteilte Sperren oder Lua-Ausdrücke verwenden, um Abfrage- und Löschvorgänge abzumelden.
Empfohlenes Lernen: Redis-Video-Tutorial
Das obige ist der detaillierte Inhalt vonLassen Sie uns kurz über zwei Lösungen für Redis sprechen, um mit Schnittstellen-Idempotenz umzugehen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



