


Unter Linux lautet der vollständige Name von fd „Dateideskriptor“ und der chinesische Name ist „Dateideskriptor“. Es handelt sich um einen vom Kernel erstellten Index, um diese geöffneten Dateien effizient zu verwalten Ganzzahl, mit Um auf eine geöffnete Datei zu verweisen, werden alle Systemaufrufe, die E/A-Vorgänge ausführen, über Dateideskriptoren implementiert.

Die Betriebsumgebung dieses Tutorials: Linux7.3-System, Dell G3-Computer.
Unter Linux lautet der vollständige Name von fd „Dateideskriptor“ und der chinesische Name ist „Dateideskriptor“. Ein Dateideskriptor ist eine nicht negative Ganzzahl, im Wesentlichen ein Indexwert (dieser Satz ist sehr wichtig).
Wir wissen, dass alles im Linux-System als Datei betrachtet werden kann und Dateien unterteilt werden können in: normale Dateien, Verzeichnisdateien, Linkdateien und Gerätedateien. Wenn wir diese sogenannten Dateien bearbeiten, müssen wir bei jedem Vorgang den Namen finden, was viel Zeit und Effizienz kostet. Daher schreibt Linux vor, dass jede Datei einem Index entspricht. Wenn wir also eine Datei bearbeiten möchten, können wir den Index direkt finden und bedienen.
Der Dateideskriptor ist ein vom Kernel erstellter Index, um diese geöffneten Dateien effizient zu verwalten. Es handelt sich um eine nicht negative Ganzzahl (normalerweise eine kleine Ganzzahl), die verwendet wird, um auf die geöffnete Datei zu verweisen. O-Operationen werden über Dateideskriptoren implementiert. Gleichzeitig wird auch festgelegt, dass beim geraden Systemstart 0 die Standardeingabe, 1 die Standardausgabe und 2 der Standardfehler ist. Das heißt, wenn Sie zu diesem Zeitpunkt eine neue Datei öffnen, lautet der Dateideskriptor 3, und wenn Sie eine andere Datei öffnen, lautet der Dateideskriptor 4...
Der Linux-Kernel verfügt über eine Dateibeschreibung für alle geöffneten Dateien. Deskriptortabelle, die die Beziehung zwischen jedem Dateideskriptor und einer geöffneten Datei speichert, wie unten gezeigt. Der Dateideskriptor (Index) ist der Index des Arrays Der Inhalt besteht aus Hinweisen, um Dateien einzeln zu öffnen.

Das Obige ist nur ein einfaches Verständnis. Tatsächlich verwaltet der Linux-Kernel drei Datenstrukturen:
3 verwendet, kann ein anderer Prozess auch 3 verwenden. Zusätzlich zur Dateideskriptortabelle auf Prozessebene muss das System auch zwei weitere Tabellen verwalten: die Open-File-Tabelle und die I-Node-Tabelle. Diese beiden Tabellen speichern das Open-File-Handle jeder geöffneten Datei. Ein Open-File-Handle speichert alle Informationen zu einer geöffneten Datei.
Deskriptortabelle für geöffnete Dateien auf Systemebene:
Die I-Node-Tabelle des Dateisystems:
Die Beziehung zwischen Dateideskriptoren, offenen Dateihandles und I-Nodes ist wie folgt:
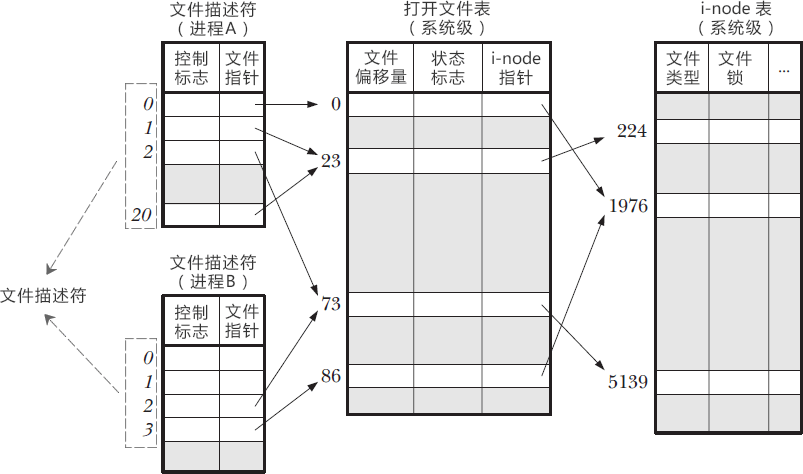
Das bedeutet: Verschiedene Dateideskriptoren desselben Prozesses können auf dieselbe Datei verweisen; verschiedene Prozesse können denselben Dateideskriptor verschiedener Prozesse auf verschiedene Dateien verweisen (dies ist im Allgemeinen der Fall). Zusätzlich zu den drei Spezialdateien 0, 1 und 2 können auch verschiedene Dateideskriptoren verschiedener Prozesse auf dieselbe Datei verweisen.
Beispiel für das Öffnen einer Datei unter Linux
Verwenden Sie beispielsweise vim test.py unter Linux Öffnen Sie eine Datei, lassen Sie sie geöffnet, öffnen Sie dann eine neue Shell, geben Sie den Befehl pidof vim Get ein die PID-Nummer des VIM-Prozesses und dann ll /proc/$pid/fd, um die Liste der vom VIM-Prozess verwendeten Dateideskriptoren anzuzeigen.
/dev/pts ist das Verzeichnis, in dem sich die nach der Remote-Anmeldung (Telnet, SSH usw.) erstellten Konsolengerätedateien befinden. Da ich mich remote über Xshell angemeldet habe, verweisen die Dateideskriptoren von Standardeingabe 0, Standardausgabe 1 und Standardfehler 2 alle auf die virtuelle Terminalkonsole /dev/pts/6. Sehen Sie sich den Dateideskriptor der neu geöffneten test.py unten an. Es stellt sich heraus, dass es 4 ist. Haben Sie zugestimmt, mit 3 zu beginnen?
Nachdem ich verschiedene Informationen überprüft habe, habe ich mit Hilfe eines großen Chefs endlich den Grund gefunden. Wenn man es nicht auf Chinesisch finden kann, muss man es versuchen Englische Suche. Denn das Prinzip eines Editors wie vim besteht darin, zuerst die Quelldatei zu öffnen und zu kopieren, dann die Quelldatei zu schließen und dann Ihre eigene Kopie zu öffnen. Nachdem Sie die Datei geändert und gespeichert haben, benennen Sie die Kopie direkt um und überschreiben Sie die Quelldatei. Wenn Sie also die Quelldatei öffnen, verwenden Sie den Dateideskriptor 3. Wenn Sie dann Ihre eigene Kopie öffnen, ist es an der Zeit, den Dateideskriptor 4 zu verwenden. Schließen Sie dann die Quelldatei und der Dateideskriptor 3. Wir Bei der Überprüfung ist nur noch 4 übrig, was hier auf die von vim erstellte Kopierdatei verweist. Dies ist nur eine allgemeine Idee. Um tiefer in das Implementierungsprinzip von vim - Oort Nebula Ambassador einzutauchen, finden Sie hier einen Screenshot der Informationen, die ich damals im Forum gesehen habe: StackOverFlow.

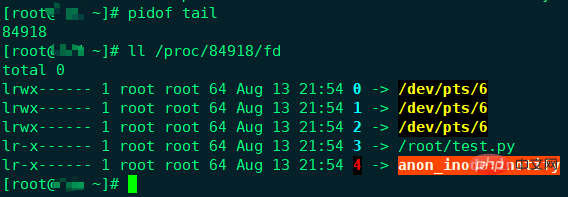
Wenn Sie es nicht glauben, können Sie einen anderen Prozess ausprobieren, z. B. Tail.
Öffnen Sie eine Datei unter Linux mit tail -f test.py Lassen Sie sie geöffnet, öffnen Sie dann eine neue Shell, geben Sie den Befehl pidof tail ein Rufen Sie die PID-Nummer des Tail-Prozesses ab und dann ll /proc/$ pid/fd Überprüfen Sie die Liste der vom Tail-Prozess verwendeten Dateideskriptoren. Sie können sehen, dass die Dateideskriptoren tatsächlich ab 3 verwendet werden. Tail ändert die Datei im Editor nicht, daher wird die Quelldatei direkt über den Dateideskriptor geöffnet. Sie können tatsächlich den Befehl ll /proc/$pid/fd verwenden, um die Dateideskriptornutzung jedes aktuell ausgeführten Prozesses abzurufen.
Erweiterte Kenntnisse: Maximale Anzahl offener Dateideskriptoren im Linux-Konfigurationssystem
(1) Einschränkungen auf Systemebene
Theoretisch können Sie so viele Dateideskriptoren öffnen, wie Systemspeicher vorhanden ist, aber in der Praxis wird der Kernel entsprechend damit umgehen. Im Allgemeinen beträgt die maximale Anzahl geöffneter Dateien 10 % des Systemspeichers (berechnet in KB). wird als Einschränkungen auf Systemebene bezeichnet. Diese Nummer kann über den Befehl cat /proc/sys/fs/file-max oder sysctl -a | angezeigt werden.

sysctl -w fs.file-max=xxxx, wobei xxxx die festzulegende Zahl ist.
/etc/sysctl.conf und fügt am Ende fs.file-max=xxxx hinzu, wobei xxxx die festzulegende Zahl ist. Verwenden Sie nach dem Speichern und Beenden den Befehl sysctl -p, um ihn wirksam zu machen.
(2) Einschränkungen auf Benutzerebene
Gleichzeitig legt der Kernel zur Kontrolle der von jedem Prozess verbrauchten Dateiressourcen auch ein Standardlimit für die maximale Anzahl geöffneter Dateien für einen einzelnen Prozess fest Prozess, d. h. Einschränkungen auf Benutzerebene. Der Standardwert für 32-Bit-Systeme ist im Allgemeinen 1024 und der Standardwert für 64-Bit-Systeme ist im Allgemeinen 65535. Sie können ihn mit dem Befehlulimit -n anzeigen.

ulimit -SHn xxxx, um es zu ändern, wobei xxxx die festzulegende Zahl ist.
/etc/security/limits.conf und ändert die hard nofile xxxx und soft nofile xxxx, wobei xxxx die festzulegende Nummer ist. Speichern und beenden. Informationen zum Unterschied zwischen hart und weich finden Sie im 5. Referenzlink unten.
Linux-Video-Tutorial“
Das obige ist der detaillierte Inhalt vonWas ist Linux fd. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



