|
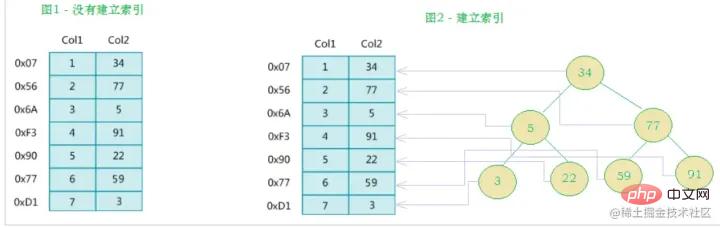
Was wir normalerweise als Indizes bezeichnen, bezieht sich, sofern nicht anders angegeben, auf Indizes, die in einer B+-Baumstruktur (Mehrwege-Suchbaum, nicht unbedingt binär) organisiert sind. Unter diesen verwenden Clustered-Index, Compound-Index, Präfix-Index und Unique-Index standardmäßig alle den B+Tree-Index, der gemeinsam als Index bezeichnet wird. BTREE m/2)-1 bis m-1
ceil bedeutet Aufrunden, ceil(2.3)=3
- Schlüsselwort Groß-/Kleinschreibung einfügen
, um sicherzustellen, dass die Eigenschaften des B-Baums m-Ordnung vorliegen nicht zerstört Da Level 3 höchstens 2 Knoten haben kann, sind 26 und 30 am Anfang zusammen, und dann beginnt 85, sich zu teilen, 26 bleibt übrig und 85 geht an rechts Das heißt:  Die obere Position in der Mitte Die obere Position in der Mitte , dann bleibt die linke Seite beim alten Knoten und die rechte Seite geht zum neuen Knoten
Wenn 70 erneut in das Bild eingefügt wird, ist zufällig 70 drin In der mittleren Position wird 62 beibehalten und 85 wird in einen neuen Knoten unterteilt Vorteile
Im Vergleich zu binären Suchbäumen ist die Höhe/Tiefe geringer und die natürliche Abfrageeffizienz höher. B+BAUM
B+-Baum hat zwei Arten von Knoten: interne Knoten (auch Indexknoten genannt) und 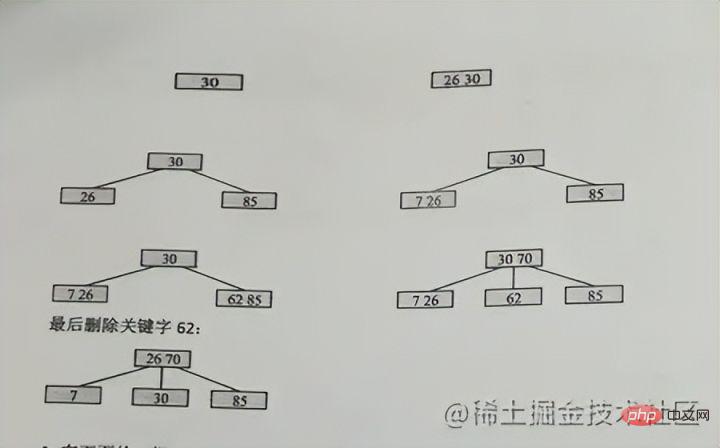 Blattknoten Blattknoten . Interne Knoten sind Nicht-Blattknoten. Interne Knoten speichern keine Daten, sondern nur Indizes, und Daten werden in Blattknoten gespeichert. Die Schlüssel im internen Knoten sind in der Reihenfolge von klein bis groß angeordnet. Für einen Schlüssel im internen Knoten sind alle Schlüssel im linken Baum kleiner als dieser und alle Schlüssel im rechten Teilbaum sind größer oder gleich dazu. Datensätze in Blattknoten werden ebenfalls nach Schlüsselgröße geordnet.
Jeder Blattknoten speichert Zeiger auf benachbarte Blattknoten. Die Blattknoten selbst sind in der Reihenfolge von klein nach groß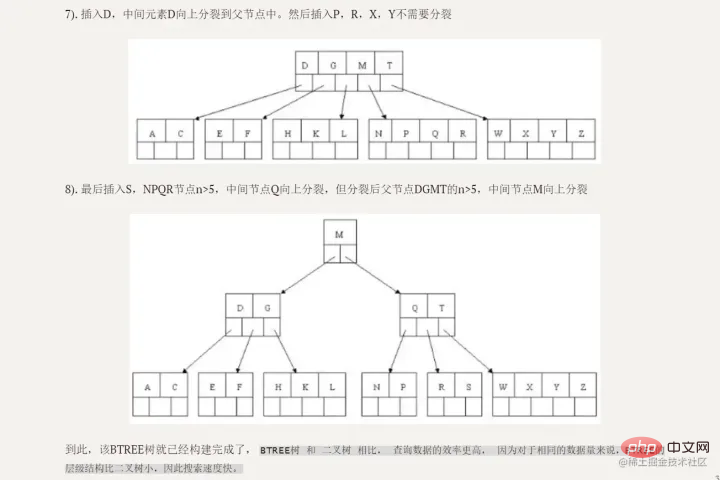 entsprechend der Größe der Schlüsselwörter verbunden. entsprechend der Größe der Schlüsselwörter verbunden.
Der übergeordnete Knoten speichert den Index des ersten Elements des rechten untergeordneten Knotens.
-
Verglichen mit dem Vorteil B+Trees Abfrageeffizienz
ist stabiler- . Da nur die Blattknoten von B+Tree Schlüsselinformationen speichern, erfordert die Abfrage eines beliebigen Schlüssels den Übergang von der Wurzel zu den Blättern und ist daher stabiler. Sie müssen nur die Blattknoten durchlaufen, um den gesamten Baum zu durchlaufen.
- B+Tree in MySQL
MySql-Indexdatenstruktur optimiert den klassischen B+Tree. Auf der Grundlage des ursprünglichen B + Baums wird ein verknüpfter Listenzeiger hinzugefügt, der auf den benachbarten Blattknoten zeigt (die Gesamtstruktur ähnelt einer doppelt verknüpften Liste), um einen B + Baum mit einem sequentiellen Zeiger zu bilden und die Leistung des Intervalls zu verbessern Zugang. -
Aufmerksame Schüler können erkennen, was der größte Unterschied zwischen diesem Bild und unserem binären Suchbaumdiagramm ist?
Beim Übergang vom 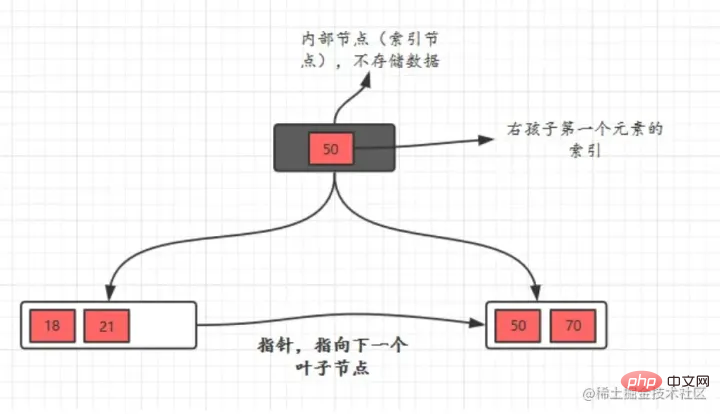 binären Suchbaum zum B-Baum binären Suchbaum zum B-Baum besteht eine wesentliche Änderung darin, dass ein Knoten mehrere Daten speichern kann, was einem Festplattenblock entspricht, der mehrere Daten speichern kann, was unsere IO-Zeiten erheblich verkürzt! !
B+Baum-Indexstrukturdiagramm in MySQL: - Binäres Suchbaumdiagramm:
IndexprinzipBBaumindex:
InitialisierungseinführungDer hellblaue heißt A Festplattenblock, Sie können sehen, dass jeder Festplattenblock mehrere Datenelemente (in Dunkelblau dargestellt) und Zeiger (in Gelb dargestellt) enthält. Beispielsweise enthält Festplattenblock 1 die Datenelemente 17 und 35, einschließlich der Zeiger P1, P2, P3. - P1 stellt die Festplatte dar Blöcke kleiner als 17, P2 repräsentiert Plattenblöcke zwischen 17 und 35 und P3 repräsentiert Plattenblöcke größer als 35.
-
Die tatsächlichen Daten liegen in den Blattknoten vord. h. 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. „
- Nicht-Blattknoten speichern keine echten Daten, nur Datenelemente, die die Suchrichtung bestimmen, wie 17 und 35, sind in der Datentabelle tatsächlich nicht vorhanden.“ „
Suchvorgang
Wenn Sie das Datenelement 29 finden möchten, wird zunächst Festplattenblock 1 von der Festplatte in den Speicher geladen und zu diesem Zeitpunkt erfolgt ein E/A. Verwenden Sie eine binäre Suche im Speicher, um festzustellen, ob 29 zwischen 17 und 35 liegt, und sperren Sie den P2-Zeiger von Festplattenblock 1. Die Speicherzeit ist vernachlässigbar, da sie sehr kurz ist (im Vergleich zur E/A der Festplatte). Die Adresse des P2-Zeigers von Plattenblock 1 auf Plattenblock 3 wird von der Platte in den Speicher geladen. Der zweite IO liegt zwischen 26 und 30. Der P2-Zeiger von Plattenblock 3 wird gesperrt Der Speicher durchläuft den Zeiger. Der dritte IO erfolgt gleichzeitig. Die binäre Suche erreicht 29 und beendet die Abfrage, was zu insgesamt drei IOs führt.
Die reale Situation ist, dass ein dreischichtiger B+-Baum Millionen von Daten darstellen kann. Wenn für Millionen von Datensuchen nur drei E/As erforderlich sind, ist die Leistungsverbesserung enorm. Wenn kein Index vorhanden ist, muss jedes Datenelement durchsucht werden . Ein IO erfordert insgesamt Millionen von IOs. Die Kosten sind natürlich sehr, sehr hoch.
Indexklassifizierung
In InnoDB werden Tabellen in Form von Indizes entsprechend der Reihenfolge der Primärschlüssel gespeichert. Auf diese Weise gespeicherte Tabellen werden als indexorganisierte Tabellen bezeichnet. Und wie bereits erwähnt, verwendet InnoDB das B+-Baum-Indexmodell, sodass die Daten im B+-Baum gespeichert werden.
Jeder Index entspricht einem B+-Baum in InnoDB.
Angenommen, wir haben eine Tabelle mit der Primärschlüsselspalte als ID, es gibt das Feld k in der Tabelle und es gibt einen Index für k.
Die Tabellenerstellungsanweisung dieser Tabelle lautet:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
复制代码 Nach dem Login kopieren Die (ID,k)-Werte von R1~R5 in der Tabelle sind (100,1), (200,2), (300,3), (500,5) und (600,6), das Beispieldiagramm zweier Bäume lautet wie folgt:
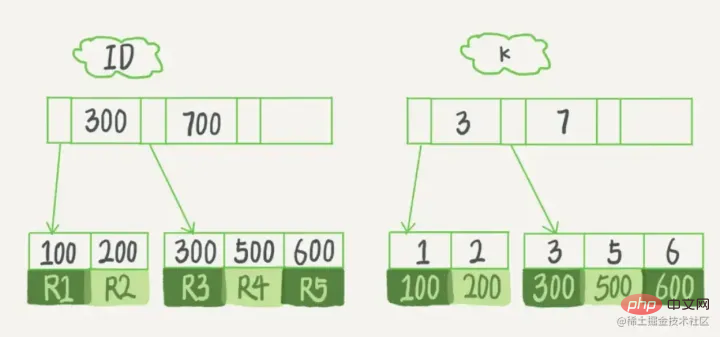
Aus der Abbildung ist leicht ersichtlich, dass der Indextyp entsprechend dem Inhalt des Blattknotens lautet unterteilt in Primärschlüsselindex und Nicht-Primärschlüsselindex.
Primärschlüsselindex
Die Primärschlüsselspalte der Datentabelle verwendet den Primärschlüsselindex und wird standardmäßig erstellt. Aus diesem Grund sagte uns der Lehrer, bevor wir die Indizierung lernten, dass die Suche basierend auf dem Primärschlüssel schneller sei Es stellt sich heraus, dass der Primärschlüssel selbst der Index ist. Der Blattknoten des
Primärschlüsselindex speichert die gesamte Datenzeile. In InnoDB wird der Primärschlüsselindex auch „Clustered Index“ (Clustered Index) genannt. Der Blattknoteninhalt des Hilfsindex
Hilfsindex ist der Wert des Primärschlüssels. In InnoDB wird der Hilfsindex auch „Sekundärindex“ (Sekundärindex) genannt. Wie unten gezeigt:
Der Primärschlüsselindex speichert die gesamte Datenzeile
- Der Hilfsindex speichert nur sich selbst und der ID-Primärschlüssel wird für Tabellenabfragen verwendet
-
Gemäß dem Lassen Sie uns über die obige Indexstruktur eine Frage diskutieren: Was ist der Unterschied zwischen Abfragen, die auf dem Primärschlüsselindex und dem Sekundärindex basieren? 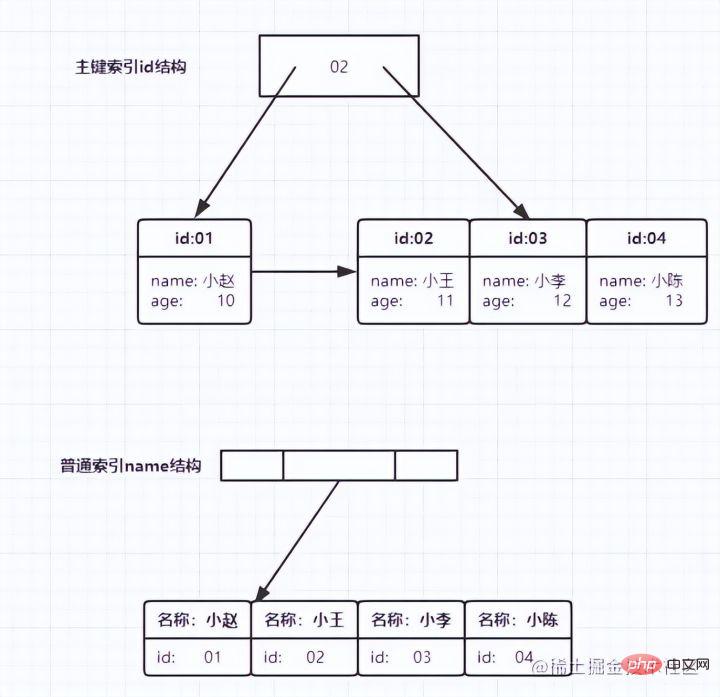
Wenn die Anweisung „select * from T“ ist, wobei ID=500 ist, was die Primärschlüsselabfragemethode ist, müssen Sie nur den B+-Baum der ID durchsuchen;
Wenn die Anweisung „select * from T“ ist, wobei k= 5, eine normale Indexabfragemethode, müssen Sie zuerst den k-Indexbaum- durchsuchen, um den ID-Wert 500 zu erhalten,
und dann erneut im ID-Indexbaum- suchen. Dieser Vorgang wird „Zurück zum Tisch“ genannt. Mit anderen Worten: Abfragen, die auf Hilfsindizes basieren, müssen einen weiteren Indexbaum scannen. Daher sollten wir versuchen, in unseren Anwendungen Primärschlüsselabfragen zu verwenden. Abgesehen davon, dass die Daten, die wir abfragen möchten, zufällig in unserem Indexbaum vorhanden sind, nennen wir ihn „Covering Index“ – das heißt, die Indexspalte enthält alle Daten, die wir abfragen möchten.
Gleichzeitig werden Sekundärindizes in die folgenden Typen unterteilt (überspringen Sie es einfach kurz, wir werden später mehr darüber erfahren):
-
Eindeutiger Schlüssel: Der eindeutige Index ist ebenfalls eine Einschränkung. Duplikatdaten können nicht in der Attributspalte eines eindeutigen Index angezeigt werden, die Daten dürfen jedoch NULL sein. Eine Tabelle ermöglicht die Erstellung mehrerer eindeutiger Indizes. In den meisten Fällen dient die Einrichtung eines eindeutigen Index eher der Eindeutigkeit der Daten in der Attributspalte als der Abfrageeffizienz.
-
Gewöhnlicher Index (Index): Die einzige Funktion eines gewöhnlichen Index besteht darin, Daten schnell abzufragen. Eine Tabelle ermöglicht die Erstellung mehrerer gewöhnlicher Indizes und ermöglicht die Duplizierung von Daten und NULL.
-
Präfixindex (Präfix): Der Präfixindex gilt nur für Daten vom Typ Zeichenfolge. Der Präfixindex erstellt einen Index für die ersten Zeichen des Textes. Im Vergleich zum normalen Index sind die erstellten Daten kleiner, da nur die ersten Zeichen abgerufen werden.
-
Volltextindex (Volltext): Der Volltextindex wird hauptsächlich zum Abrufen von Schlüsselwortinformationen in großen Textdaten verwendet. Es handelt sich um eine Technologie, die derzeit von Suchmaschinendatenbanken verwendet wird. Vor Mysql5.6 unterstützte nur die MYISAM-Engine die Volltextindizierung. Nach 5.6 unterstützte InnoDB auch die Volltextindizierung. Erweiterung: Index-Pushdown. Wie der Name schon sagt, bedeutet Pushdown tatsächlich Verschiebung Unsere Tabellenrückgabeoperation
, MySQL wird dies nicht tun. Es ist für uns einfach, die Tabelle zurückzugeben, weil es verschwenderisch ist. Was bedeutet es? Betrachten Sie das folgende Beispiel.
Wir haben einen zusammengesetzten Index (Name, Status, Adresse) erstellt, der ebenfalls entsprechend diesem Feld gespeichert wird, ähnlich dem Bild:
Zusammengesetzter Indexbaum (speichert nur Indexspalten und Primärschlüssel für die Tabellenrückgabe)
Name
Status | Adresse | ID (Primärschlüssel) |
Xiaomi 1 |
0. |
| 1 | 1 | Xiaomi 2 |
1 | 1 | 2 |
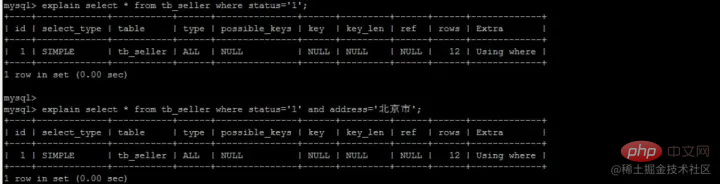
我们执行这样一条语句:
SELECT name FROM tb_seller WHERE name like '小米%' and status ='1' ;
复制代码 Nach dem Login kopieren
- 首先我们在复合索引树上,找到了第一个以小米开头的name -- 小米1
- 此时我们不着急回表(回到主键索引树搜索的过程,我们称为回表),而是先在复合索引树判断status是否=1,此时status=0,我们直接就不回表了,直接继续找下一个以小米开头的name
- 找到第二个-- 小米2,判断status=1,则根据id=2去主键索引树上找,得到所有的数据
这种先在自身索引树上判断是否满足其他的where条件,不满足则直接pass掉,不进行回表的操作,就叫做索引下推。
最左前缀原则
所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个复合索引:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效:
- 按楼梯从低到高,无出现跳跃的情况--此时符合最左前缀原则,索引不会失效

- 出现跳跃的情况
- 直接第一层name都不走,当然都失效
- 走了第一层,但是后续直接第三层,只有出现跳跃情况前的不会失效(此处就只有name成功)

- 同时,这个顺序并不是由我们where中的排列顺序决定,比如: where name='小米科技' and status='1' and address='北京市' where status='1' and name='小米科技' and address='北京市'
这两个尽管where中字段的顺序不一样,第二个看起来越级了,但实际上效果是一样的
其实是因为我们MySQL有一个Optimizer(查询优化器),查询优化器会将SQL进行优化,选择最优的查询计划来执行。
- 关于这个查询优化器,后续文章我们也会谈谈MySQL的逻辑架构与存储引擎
索引设计原则
针对表
- 查询频次高,且数据量多的表
针对字段
- 最好从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
其他原则
- 最好用唯一索引,区分度越高,使用索引的效率越高
- 不是越多越好,维护也需要时间和空间代价,建议单张表索引不超过 5 个
因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
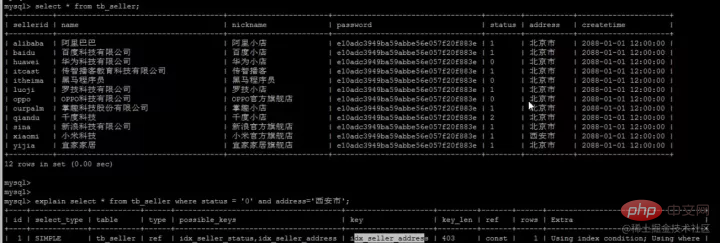
比如:
我们创建了三个单列索引,name,status,address
当我们where中根据status和address两个字段来查询时,数据库只会选择最优的一个索引,不会所有单列索引都使用。
最优的索引:具体是指所查询表中,辨识度最高(所占比例最少)的索引列,比如此处address中有一个辨识度很高的 '西安市'数据;
- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
- 利用最左前缀,比如有N个字段,我们不一定需要创建N个索引,可以用复合索引
也就是说,我们尽量创建复合索引,而不是单列索引
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(name,email,status);
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;
复制代码 Nach dem Login kopieren 举个栗子
假设我们有这么一个表,id为主键,没有创建索引:
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB
复制代码 Nach dem Login kopieren 如果要在此处建立复合索引,我们要遵循什么原则呢?
通过调整顺序,可以少维护一个索引
- 比如我们的业务需求里边,有如下两种查询方式: 根据name查询 根据name和age查询
如果我们建立索引(age,name),由于最左前缀原则,我们这个索引能实现的是根据age,根据age和name查询,并不能单纯根据name查询(因为跳跃了),为了实现我们的需求,我们还得再建立一个name索引;
而如果我们通过调整顺序,改成(name,age),就能实现我们的需求了,无需再维护一个name索引,这就是通过调整顺序,可以少维护一个索引。
考虑空间->短索引
- 比如我们的业务需求里边,有以下两种查询方式: 根据name查询 根据age查询 根据name和age查询
我们有两种方案:
- 建立联合索引(name,age),建立单列索引:age索引。
- 建立联合索引(age,name),建立单列索引:name索引。
这两种方案都能实现我们的需求,这个时候我们就要考虑空间了,name字段是比age字段大的,显然方案1所耗费的空间是更小的,所以我们更倾向于方案1。
何时建立索引
- where中的查询字段
- 查询中与其他表关联的字段,比如外键
- 排序的字段
- 统计或分组的字段
何时达咩索引
- 表中数据量很少
- 经常改动的表
- 频繁更新的字段
-
数据重复且分布均匀的表字段(比如包含了很多重复数据,那此时多叉树的二分查找,其实用处不大,可以理解为O(logn)退化了)
索引相关语法
创建索引
默认会为主键创建索引--primary
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
复制代码 Nach dem Login kopieren 查找索引
结尾加上\G,可以变成竖屏显示
select index from tbl_name\G;
复制代码 Nach dem Login kopieren 删除索引
drop INDEX index_name on tbl_name ;
复制代码 Nach dem Login kopieren 变更索引
1). alter table tb_name add primary key(column_list);
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
2). alter table tb_name add unique index_name(column_list);
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
3). alter table tb_name add index index_name(column_list);
添加普通索引, 索引值可以出现多次。
4). alter table tb_name add fulltext index_name(column_list);
该语句指定了索引为FULLTEXT, 用于全文索引
复制代码 Nach dem Login kopieren 查看索引使用情况
show status like 'Handler_read%'; -- 查看当前会话索引使用情况
show global status like 'Handler_read%'; -- 查看全局索引使用情况
复制代码 Nach dem Login kopieren Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低越好)。
Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(这个值越高越好)。
Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。
Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。
Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
总结
- 索引简单来说就是一个排好序的数据结构,可以方便我们检索数据,而不需要盲目的进行全表扫描。
- 索引底层有很多种实现结构,这篇主要只是讲解了BTREE索引,如果对树这一数据结构还不太熟悉的小伙伴,可以关注我后续数据结构专栏,会整理关于普通树,二叉树,二叉排序树的文章。
- 索引分类:
- 主键索引
- 辅助索引
这里我们还扩展了索引下推,是一个十分重要的知识点,需要仔细回味。
- 索引的相关设计原则,索引虽好,但也不可贪杯,不能为了用索引而建索引。
- 索引的相关语法,很容易上手的。
- 查看索引的使用情况。
推荐学习:mysql视频教程
|
|




 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



