


Dieser Artikel vermittelt Ihnen relevantes Wissen über Python. Er stellt hauptsächlich Probleme im Zusammenhang mit Datenstrukturen vor, einschließlich Zahlen, Zeichenfolgen, Listen, Tupeln, Wörterbüchern usw. Ich hoffe, dass er für alle hilfreich ist.

Empfohlenes Lernen: Python-Video-Tutorial
Integer-Typ (int) – normalerweise Ganzzahl oder Ganzzahl genannt, ist eine positive oder negative Ganzzahl ohne Dezimalpunkt. Python3-Ganzzahlen haben keine Größenbeschränkung und können als Long-Typen verwendet werden. Boolean ist ein Untertyp von Integer.
Gleitkommatyp (Float) – Der Gleitkommatyp besteht aus einem ganzzahligen Teil und einem Dezimalteil und kann auch in wissenschaftlicher Notation ausgedrückt werden (2,5e2 = 2,5 x 102 = 250).
Pluralzahl ( ( komplex )) – Eine komplexe Zahl besteht aus einem Realteil und einem Imaginärteil, die durch a + bj oder komplex(a,b) dargestellt werden können. Der Realteil a und der Imaginärteil b der komplexen Zahl sind beide gleitend Punkttypen.
int(x) Wandelt x in eine Ganzzahl um.
float(x) Wandelt x in eine Gleitkommazahl um.
complex(x) Wandle x in eine komplexe Zahl um, wobei der Realteil x und der Imaginärteil 0 ist.
complex(x, y) Wandelt x und y in eine komplexe Zahl um, wobei der Realteil x und der Imaginärteil y ist. x und y sind numerische Ausdrücke.
# + - * / %(取余) **(幂运算) # 整数除法中,除法 / 总是返回一个浮点数, # 如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // print(8 / 5) # 1.6 print(8 // 5) # 1 # 注意:// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系 print(8 // 5.0) # 1.0 # 使用 ** 操作来进行幂运算 print(5 ** 2) # 5的平方 25
index(): Finden Sie das erste Vorkommen des Teilstrings substr. Wenn der gesuchte Teilstring nicht vorhanden ist, lösen Sie die Ausnahme ValueErrorrindex () aus
rindex (): Finden Sie das letzte Vorkommen der Teilzeichenfolge substr. Wenn die gesuchte Teilzeichenfolge nicht vorhanden ist, wird eine ValueError()-Ausnahme ausgelöst
find(): Finden Sie die Position der Teilzeichenfolge substr erscheint einmal. Wenn der gesuchte Teilstring nicht existiert, wird -1 zurückgegeben.
rfind(): Findet die Position, an der der Teilstring zuletzt erschien wird zurückgegeben.
s = 'hello, hello'
print(s.index('lo')) # 3
print(s.find('lo')) # 3
print(s.find('k')) # -1
print(s.rindex('lo')) # 10
print(s.rfind('lo')) # 10upper(): Konvertiert alle Zeichen in der Zeichenfolge in Großbuchstaben
lower(): Konvertiert alle Zeichen in der Zeichenfolge in Kleinbuchstaben
swapcase(): Wandelt alle Großbuchstaben in der Zeichenfolge in Kleinbuchstaben um und wandelt alle Kleinbuchstaben in Großbuchstaben um
capitalize(): Wandelt das erste Zeichen in Großbuchstaben um und wandelt die übrigen Zeichen in Kleinbuchstaben um
Titel (): Wandeln Sie das erste Zeichen jedes Wortes in Großbuchstaben um und wandeln Sie die restlichen Zeichen jedes Wortes in Kleinbuchstaben um Der zweite Parameter gibt den Füller an. Wenn die eingestellte Breite kleiner als die tatsächliche Breite ist, wird die ursprüngliche Zeichenfolge zurückgegeben.
rjust(): rechtsbündig, der erste Parameter gibt die Breite an , der zweite Parameter gibt den Füller an, der Standardwert ist ein Leerzeichen. Wenn die eingestellte Breite kleiner als die tatsächliche Breite ist, wird die ursprüngliche Zeichenfolge zurückgegeben
zfill(): rechtsbündig, links mit 0 aufgefüllt . Diese Methode empfängt nur einen Parameter, der verwendet wird, um die Breite der Zeichenfolge anzugeben. Wenn die angegebene Breite kleiner oder gleich der Länge der Zeichenfolge ist, wird die Zeichenfolge selbst zurückgegeben
rsplit(): Von der linken Seite der Zeichenfolge trennen Beginnen Sie mit der Aufteilung von rechts
Geben Sie die maximale Anzahl von Teilungen an, wenn Sie die Zeichenfolge über den Parameter maxsplit aufteilen. Nach der maximalen Anzahl von Teilungen werden die verbleibenden Teilzeichenfolgen separat verwendet als Teil
s = 'hello, Python' print(s.upper()) # HELLO, PYTHON print(s.lower()) # hello, python print(s.swapcase()) # HELLO, pYTHON print(s.capitalize()) # Hello, python print(s.title()) # Hello, Python
s = 'hello,Python'
'''居中对齐'''
print(s.center(20, '*')) # ****hello,Python****
'''左对齐 '''
print(s.ljust(20, '*')) # hello,Python********
print(s.ljust(5, '*')) # hello,Python
'''右对齐'''
print(s.rjust(20, '*')) # ********hello,Python
'''右对齐,使用0进行填充'''
print(s.zfill(20)) # 00000000hello,Python
print('-1005'.zfill(8)) # -0001005isdecimal( ): Bestimmen Sie, ob die angegebene Zeichenfolge vollständig aus Dezimalzahlen bestehtisnumeric(): Bestimmen Sie, ob die Die angegebene Zeichenfolge besteht vollständig aus Zahlen
s = 'hello word Python'
print(s.split()) # ['hello', 'word', 'Python']
s1 = 'hello|word|Python'
print(s1.split(sep='|')) # ['hello', 'word', 'Python']
print(s1.split('|', 1)) # ['hello', 'word|Python'] # 左侧开始
print(s1.rsplit('|', 1)) # ['hello|word', 'Python'] # 右侧开始{} Platzhalter: Rufen Sie die Methode format() auf
s = 'hello,world' print(s[:5]) # hello 从索引0开始,到4结束 print(s[6:]) # world 从索引6开始,到最后一个元素 print(s[1:5:1]) # ello 从索引1开始,到4结束,步长为1 print(s[::2]) # hlowrd 从开始到结束,步长为2 print(s[::-1]) # dlrow,olleh 步长为负数,从最后一个元素(索引-1)开始,到第一个元素结束 print(s[-6::1]) # ,world 从索引-6开始,到最后一个结束
s = 'hello,Python,Python,Python'
print(s.replace('Python', 'Java')) # 默认全部替换 hello,Java,Java,Java
print(s.replace('Python', 'Java', 2)) # 设置替换个数 hello,Java,Java,Pythonlst = ['hello', 'java', 'Python']
print(','.join(lst)) # hello,java,Python
print('|'.join(lst)) # hello|java|Python可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存
语法格式:[i*i for i in range(i, 10)]
解释:i表示自定义变量,i*i表示列表元素的表达式,range(i, 10)表示可迭代对象
print([i * i for i in range(1, 10)])# [1, 4, 9, 16, 25, 36, 49, 64, 81]
in / not in
for item in list: print(item)
list.index(item)
list = [1, 4, 9, 16, 25, 36, 49, 64, 81]print(list[3]) # 16print(list[3:6]) # [16, 25, 36]
append():在列表的末尾添加一个元素
extend():在列表的末尾至少添加一个元素
insert0:在列表的指定位置添加一个元素
切片:在列表的指定位置添加至少一个元素
rerove():一次删除一个元素,
重复元素只删除第一个,
元素不存在抛出ValceError异常
pop():删除一个指定索引位置上的元素,
指定索引不存在抛出IndexError异常,
不指定索引,删除列表中最后一个元素
切片:一次至少删除一个元素
clear0:清空列表
del:删除列表
list.sort()
sorted(list)
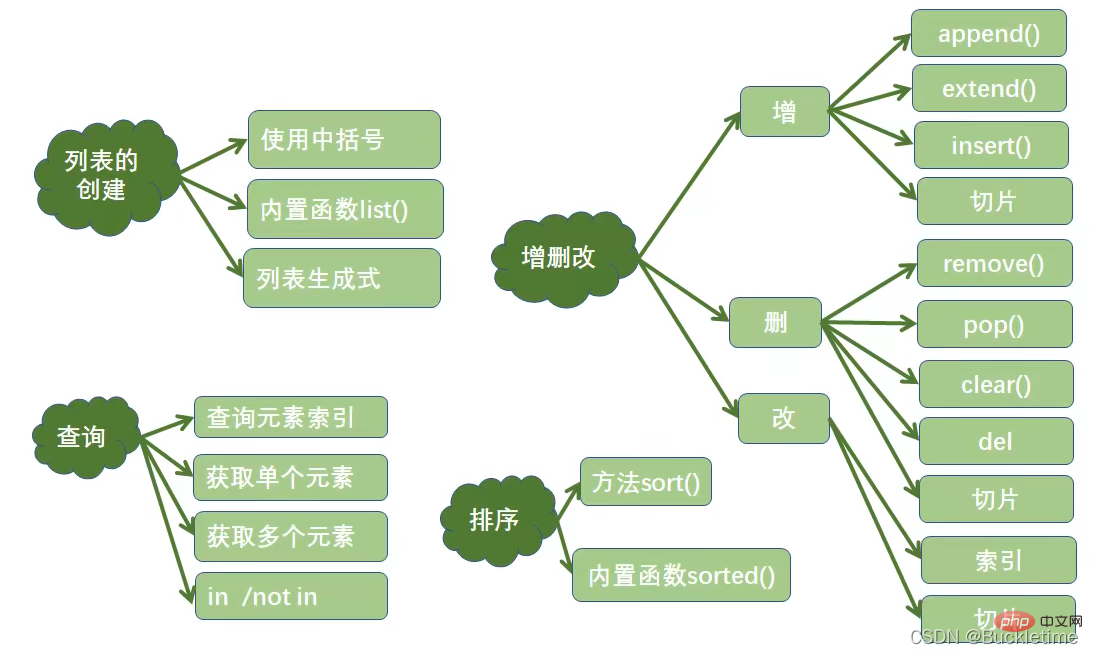
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号
t = ('Python', 'hello', 90)tuple(('Python', 'hello', 90))t = (10,)
items = ['fruits', 'Books', 'Others']
prices = [12, 36, 44]
d = {item.upper(): price for item, price in zip(items, prices)}
print(d) # {'FRUITS': 12, 'BOOKS': 36, 'OTHERS': 44}user = {"id": 1, "name": "zhangsan"}
user["age"] = 25
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 25}user = {"id": 1, "name": "zhangsan", "age": 25}
user["age"] = 18
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 18}user = {"id": 1, "name": "zhangsan"}del user["id"]print(user) # {'name': 'zhangsan'}del useruser = {"id": 1, "name": "zhangsan"}user.clear()print(user) # {}scores = {'张三': 100, '李四': 95, '王五': 88}for name in scores:
print(name, scores[name])scores = {'张三': 100, '李四': 95, '王五': 88}for name, score in scores.items():
print(name, score)
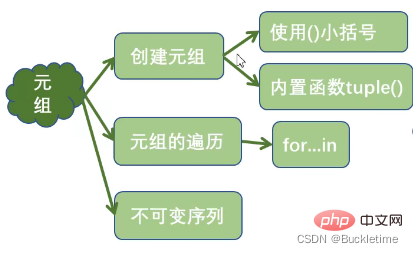
s = {'Python', 'hello', 90}print(set("Python"))print(set(range(1,6)))print(set([3, 4, 7]))print(set((3, 2, 0)))print(set({"a", "b", "c"}))# 定义空集合:set()print(set())print({i * i for i in range(1, 10)})# {64, 1, 4, 36, 9, 16, 49, 81, 25}两个集合是否相等:可以使用运算符 == 或 != 进行判断,只要元素相同就相等
一个集合是否是另一个集合的子集:issubset()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {10, 70}print(s2.issubset(s1))
# Trueprint(s3.issubset(s1)) # Falseprint(s1.issuperset(s2)) # Trueprint(s1.issuperset(s3)) # False
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {20, 70}print(s1.isdisjoint(s2))
# False 有交集print(s3.isdisjoint(s2)) # True 无交集s1 = {10, 20, 30, 40}s2 = {20, 30, 40, 50, 60}print(s1.intersection(s2)) # {40, 20, 30}print(s1 & s2) # {40, 20, 30}print(s1.union(s2)) # {40, 10, 50, 20, 60, 30}print(s1 | s2) # {40, 10, 50, 20, 60, 30}print(s2.difference(s1)) # {50, 60}print(s2 - s1) # {50, 60}print(s2.symmetric_difference(s1)) # {10, 50, 60}print(s2 ^ s1) # {10, 50, 60}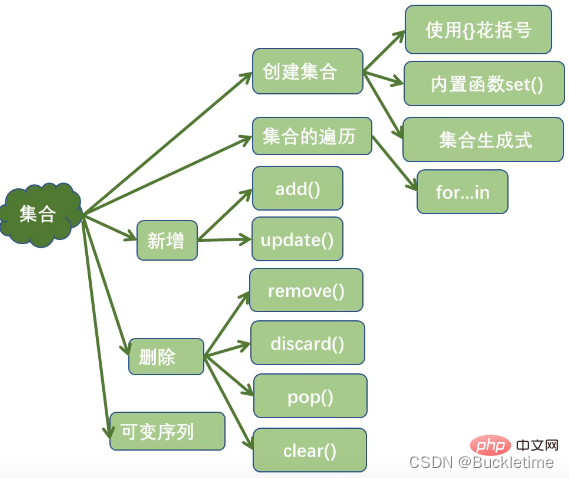
推荐学习:python教程
Das obige ist der detaillierte Inhalt vonDetaillierte Einführung in die Wissenspunkte zur Python3-Datenstruktur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



