


Dieser Artikel bringt Ihnen relevantes Wissen über MySQL, das hauptsächlich die Probleme im Zusammenhang mit Erklärungen in MySQL erläutert. Wir können es zur Analyse der entsprechenden SQL-Anweisungen verwenden hilft allen.

Empfohlenes Lernen: MySQL-Video-Tutorial
Die Optimierung der Datenbankleistung ist eine der grundlegenden Fähigkeiten, die jeder Back-End-Programmierer haben muss, und die Erklärung in MySQL kann als Artefakt zur Leistungsoptimierungsanalyse von MySQL bezeichnet werden Verwendung Es analysiert, wie der entsprechende Ausführungsplan der SQL-Anweisung am Ende von MySQL ausgeführt wird. Für uns ist es von großer Bedeutung, die Ausführungseffizienz von SQL zu bewerten und die Richtung der Leistungsoptimierung von MySQL zu bestimmen. Viele Studenten sind jedoch immer noch verwirrt darüber, wie sie eine detaillierte Ausführungsanalyse von vorhandenem SQL auf der Grundlage von EXPLAIN durchführen können. Daher wird in diesem Artikel auf die Lokalisierung von Datenbankleistungsproblemen mithilfe der EXPLAIN-Analyse eingegangen.
Wenn jedes SQL vom Client an den MySQL-Server gesendet wird, wird es von der MySQL-Optimierungskomponente analysiert, die hauptsächlich einige spezielle Verarbeitungen und Änderungen in der Ausführungsreihenfolge umfasst, um eine optimale Ausführungseffizienz sicherzustellen. und schließlich den entsprechenden Ausführungsplan generieren. Der sogenannte Ausführungsplan bezieht sich tatsächlich darauf, wie Daten auf der Ebene der Speicher-Engine abgerufen werden, ob Daten über einen Index oder einen vollständigen Tabellenscan abgerufen werden sollen, ob die Tabelle nach dem Abruf der Daten zurückgegeben werden muss usw. Ein einfaches Verständnis ist der Prozess des Abrufens von Daten in MySQL.
Schauen wir uns als Nächstes genauer an, was diese Erklärung ist und warum sie uns bei der Leistungsoptimierung unterstützen kann. Wenn wir die folgende Anweisung ausführen:
explain SELECT * FROM user_info where NAME='mufeng'
Nach der Ausführung der EXPLAIN-Anweisung erhalten wir die folgenden Ausführungsergebnisse. Diese 12 Felder ähneln der Datenbanktabelle und sind tatsächlich eine detaillierte Beschreibung des von MySQL ausgeführten Ausführungsplans. Schauen wir uns die Bedeutung dieser 12 Felder genauer an. Nur wenn wir ihre Bedeutung verstehen, können wir verstehen, wie MySQL Datenabfragen durchführt.

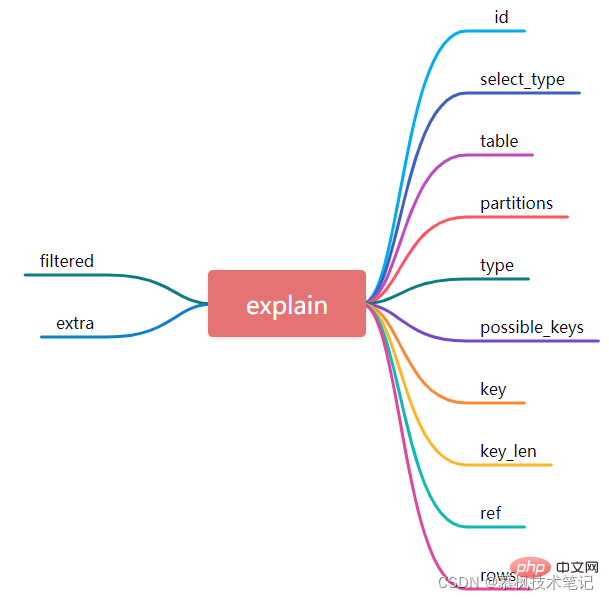
1. id
Tatsächlich entspricht jede Auswahlabfrage einer ID, die die Reihenfolge der SQL-Ausführung darstellt. Je größer der ID-Wert ist, desto höher ist die Priorität der entsprechenden SQL-Anweisung Ausführung hoch. Einige komplexe Abfrage-SQL-Anweisungen enthalten häufig einige Unterabfragen. Wenn eine verschachtelte Abfrage vorhanden ist, können wir feststellen, dass die innerste Abfrage der größten ID entspricht, sodass sie zuerst ausgeführt wird.

Wie in der obigen Abbildung gezeigt, ist in der SQL-Abfrageanweisung die ID des ersten Ausführungsplans 1, die ID des zweiten Ausführungsplans 2 und die Tabelle, die dem Ausführungsplan mit der ID 1 entspricht, ist geordnet , und die ID ist 2. Die dem Ausführungsplan entsprechende Tabelle ist user_info. In Kombination mit der SQL-Anweisung wissen wir, dass zuerst die Unterabfrage-Auswahl-ID von user_info und dann die Datenabfrage zur Tabellenreihenfolge ausgeführt wird.
2. select_type
select_type stellt den Abfragetyp dar, der dem Ausführungsplan entspricht. Zu den gängigen Abfragetypen gehören hauptsächlich normale Abfragen, gemeinsame Abfragen und Unterabfragen. SIMPLE (die Abfrageanweisung ist eine einfache Abfrage und enthält keine Unterabfragen), PRIMARY (wenn die Abfrageanweisung Unterabfragen enthält, entspricht sie dem äußersten Abfragetyp), UNION (der Abfragetyp, der der SELECT-Anweisung entspricht, die nach der Vereinigung angezeigt wird). Dieser Typ), SUBQUERY (Unterabfrage wird als dieser Typ markiert), DEPENDENT SUBQUERY (hängt von der externen Abfrage ab)

3, Tabelle
Tabelle stellt den Tabellennamen dar und gibt an, welche Tabelle abgefragt werden soll. Natürlich ist es nicht unbedingt der Name der echten Tabelle, es kann sich auch um einen Alias der Tabelle oder eine temporäre Tabelle handeln.
4, Partitionen
Partitionen stellen das Konzept der Partition dar, was bedeutet, dass bei der Abfrage, ob die entsprechende Tabelle eine tote Partitionstabelle ist, hier die spezifischen Partitionsinformationen angezeigt werden.
5. Typ
Typ ist ein sehr zentrales Attribut, das beherrscht werden muss. Es gibt die aktuelle Methode für den Zugriff auf die Datenbanktabelle an.
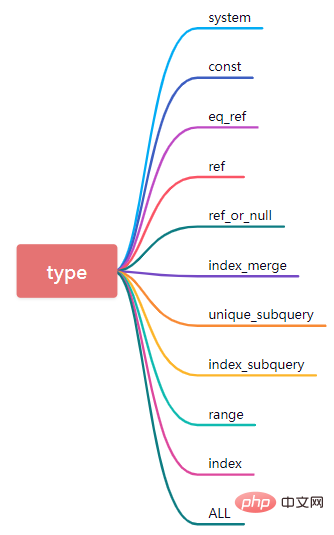
(1)System
Die Tabelle hat nur eine Zeile (entspricht der Systemtabelle), die Datenmenge ist gering und die Abfragegeschwindigkeit ist sehr hoch. System ist ein Sonderfall vom Typ const.
(2) const
Wenn der Typ const ist, bedeutet dies, dass bei der Durchführung einer Datenabfrage der Primärschlüssel oder der eindeutige Index getroffen wird.

(3) eq_ref
Wenn im Prozess der Datenabfrage die SQL-Anweisung auf dem Clustered-Index oder dem eindeutigen Index mit einem Nicht-Null-Wert basieren kann, um die Daten im Fall einer Tabellenverbindung zu speichern, dann der dieser Zeit entsprechende Typ. Der Wert wird als eq_ref angezeigt.
(4) ref
Wenn der Trefferindex während der Datenabfrage ein sekundärer Index und kein eindeutiger Index ist, ist die Geschwindigkeit der Testabfrage sehr hoch, aber der Typ ist ref. Wenn es sich außerdem um einen Mehrfeld-Joint-Index handelt, ist der Gleichheitsvergleich von Feldern in mehreren aufeinanderfolgenden Spalten, beginnend mit der äußersten linken Seite des Joint-Index, gemäß dem Matching-Prinzip ganz links ebenfalls ein Ref-Typ.

(5) ref_or_null
Dieser Join-Typ ähnelt ref, der Unterschied besteht darin, dass MySQL zusätzlich nach Zeilen sucht, die NULL-Werte enthalten.
(7) unique_subquery
Der Satz von Unterabfragebedingungen in der Where-Bedingung
(8) index_subquery
unterscheidet sich von unique_subquery, wird für nicht eindeutige Indizes verwendet und kann doppelte Werte zurückgeben.
(9)Bereich
Verwenden Sie den Index, um Zeilendaten abzurufen, und rufen Sie nur Zeilendaten innerhalb des angegebenen Bereichs ab. Mit anderen Worten: Daten werden in einem angegebenen Bereich für ein indiziertes Feld abgerufen. Bei Verwendung von bettween...and, <, >, <=, in und anderen bedingten Abfragetypen in der where-Anweisung ist der Typ „range“.

(10) Index
Index und ALL lesen tatsächlich die gesamte Tabelle. Der Unterschied besteht darin, dass Index durch Durchlaufen des Indexbaums liest, während ALL von der Festplatte liest.
(11)alle
Durchsuchen Sie die gesamte Tabelle zum Datenabgleich. Die Datenabfrageleistung ist zu diesem Zeitpunkt am schlechtesten.
6. Mögliche_Schlüssel
gibt an, welche Indizes vom MySQL-Optimierer ausgewählt werden können, also welche Indexkandidaten es gibt. 7, Schlüssel
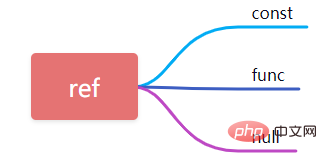
9, ref
Bei Verwendung von Feldern für konstante äquivalente Abfragen ist ref hier const. Wenn Ausdrücke oder Funktionen in den Abfragebedingungen verwendet werden, wird ref als func und andere als null angezeigt.10, Zeilen
Die Zeilenspalte zeigt die Anzahl der Zeilen an, die MySQL bei der Ausführung der Abfrage überprüfen muss. Je weniger Reihen, desto effizienter!11. gefiltert
 gefiltert Dies ist ein Prozentwert, der Prozentsatz der Anzahl der Datensätze, die die Bedingungen in der Tabelle erfüllen. Vereinfacht ausgedrückt stellt dieses Feld den Anteil der verbleibenden Datensätze dar, die die Bedingungen erfüllen, nachdem die von der Speicher-Engine zurückgegebenen Daten gefiltert wurden.
gefiltert Dies ist ein Prozentwert, der Prozentsatz der Anzahl der Datensätze, die die Bedingungen in der Tabelle erfüllen. Vereinfacht ausgedrückt stellt dieses Feld den Anteil der verbleibenden Datensätze dar, die die Bedingungen erfüllen, nachdem die von der Speicher-Engine zurückgegebenen Daten gefiltert wurden.
Zusätzliche Informationen werden nicht in anderen Spalten angezeigt und werden in dieser Spalte angezeigt.
(1) Verwendung des Index
Bei der Datenabfrage verwendet die Datenbank einen abdeckenden Index, das heißt, die abgefragte Spalte wird durch den Index abgedeckt, wodurch die Abfragegeschwindigkeit sehr hoch ist. Anstelle von „select *“ verwenden Sie „select phone_number“, wodurch der Abdeckungsindex verwendet wird.
(2) Verwendung von whereWährend der Abfrage wird kein verfügbarer Index gefunden und die erforderlichen Daten werden durch die Where-Bedingungsfilterung abgerufen. Es ist jedoch zu beachten, dass nicht alle Abfragen mit where-Anweisungen „Verwenden von where“ anzeigen.
(3) Die Verwendung von temporär
bedeutet, dass die Abfrageergebnisse in einer temporären Tabelle gespeichert werden müssen, die im Allgemeinen beim Sortieren oder Gruppieren von Abfragen verwendet wird.
(4) Verwenden von Filesort
上文中我们阐述了explain在分析SQL语句时,可以通过12个属性来分析SQL的大致执行过程,并以此来判断SQL存在的性能问题。那么接下来我们通过一个实际的例子,来具体看下如何结合explain来实现SQL的性能分析。
其实所谓的Mysql性能问题,大部分都指的是平台出现了慢查询问题。慢查询实际上是可以通过配置进行记录的,把执行时间超过某个设定的阈值的sql都记录下来,当出现问题的时候可以通过记录的慢查询日志进行问题的定位。但是有的时候,出现大量慢查询会导致数据库连接给占满,导致整个平台的出现异常。
实际上我们在产品评价表product_evaluation中是建立了索引的,正常来说应该是可以使用到对应的索引字段进行查询的。但是实际上查询耗时有几十秒的时间,远远超过我们的预期。那我们猜测是不是由于某种原因导致Mysql优化器没有选择对应的索引进行数据检索,最后造成慢查询的发生。到底执行计划是怎样的,还是得借助于explain来看下。

如上文所说,虽然explain有12个字段属性帮助我们进行执行计划的分析,但是实际上常用的核心字段也就几个。我们可以看的出来在possible_key中实际上包含了我们设置的索引的,但是实际上Mysql却选择了PRIMARY作为其实际使用的。那么问题来了,为什么明明设置了索引,但是实际并没有用上,呗Mysql吃了吗?另外为什么之前的业务中没有出现这个问题,而现在出现了?我们需要进行进一步的分析。
我们所建立的idx_evaluation_type实际上是一个二级索引(叶子节点是主键id),对于数千万一张的大表来说,实际上这个二级索引也是非常大的,而且这个字段本身的值就三个,变化不大。因此Mysql的优化器在分析这个SQL的时候发现,如果按照SQL中的索引来获取数据后再根据where条件进行筛选,筛选后的数据还需要回表到聚簇索引中获取实际的数据。
假如通过二级索引筛选出来的数据有几万条,而后还需要进行排序,这些操作都是基于临时磁盘我恩建进行的,Mysql判断这种方式的性能可能会很差,因此优化器放弃了原有的数据查询方式,直接通过主键id对应的聚簇索引来进行数据的获取,因为id本身就是有序的。
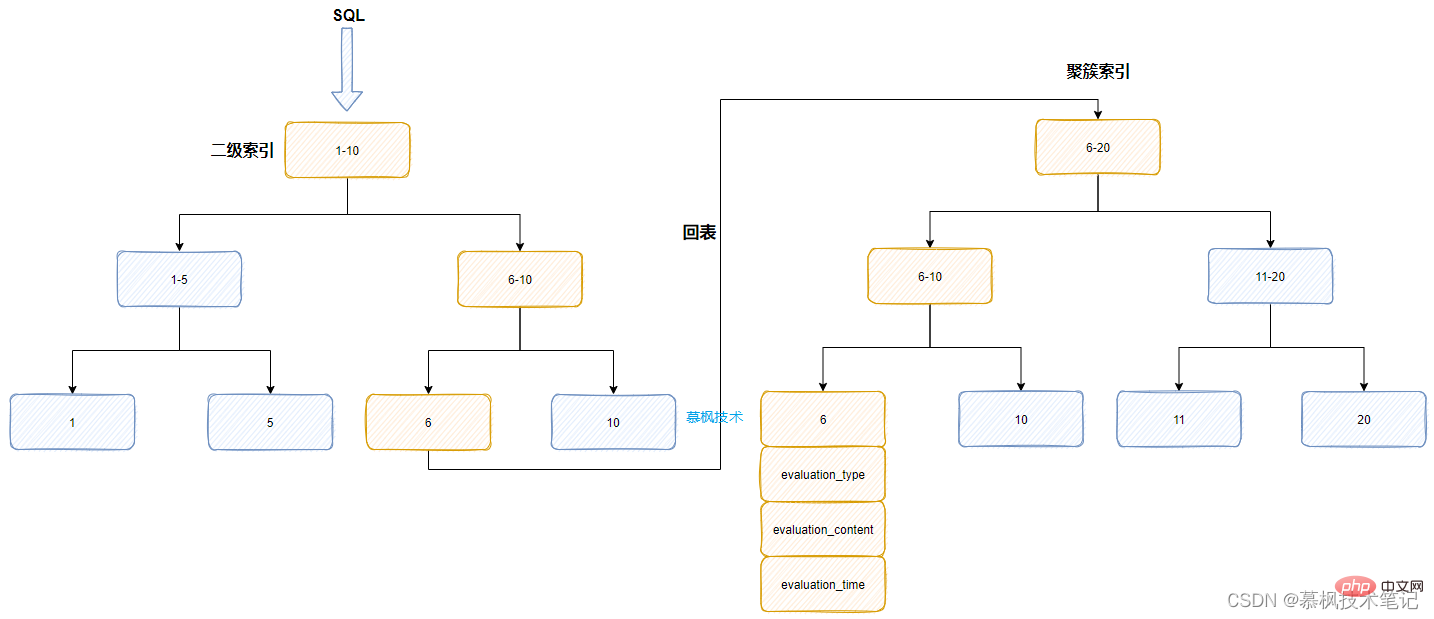
那么知道了查询慢的原因,我们应该怎么进行优化呢?实际上可以在SQL语句中增加force idnex,强制Mysql使用我们设置的二级索引。
SELECT * FROM product_evaluation force index(idx_product_id)WHERE product_id =1 and evaluation_type='GOOD' ORDER BY id desc LIMIT 200
通过上文对于explain使用的介绍,大家在遇到慢SQL问题的时候,可以先通过explain来进行初步的分析,主要明确SQL在Mysql中实际的执行过程是怎样的,如果查询字段没有索引则增加索引,如果有索引就要分析为什么没有用到索引。只要明确具体的执行过程,我们才能确定具体的查询优化方案。
推荐学习:mysql视频教程
Das obige ist der detaillierte Inhalt vonVollständig beherrschende MySQL-Erklärung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen










![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



