


Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, in dem hauptsächlich Probleme im Zusammenhang mit der Datenverarbeitung und -visualisierung vorgestellt werden, einschließlich der vorläufigen Verwendung von NumPy, der Verwendung des Matplotlib-Pakets und der visuellen Anzeige von Datenstatistiken usw. Ich hoffe, es hilft allen.

Empfohlenes Lernen: Python-Tutorial
Tabelle ist eine allgemeine Darstellung von Daten, aber für die Maschine unverständlich, das heißt, es handelt sich um nicht erkennbare Daten, daher müssen wir Anpassen die Form der Tabelle.
Eine häufig verwendete Darstellung des maschinellen Lernens ist eine Datenmatrix. 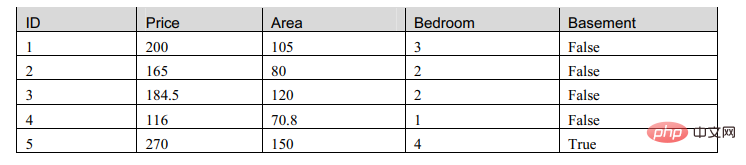
Wir haben uns diese Tabelle angesehen und festgestellt, dass die Matrix zwei Arten von Attributen enthält: eines vom numerischen Typ und das andere vom booleschen Typ. Deshalb werden wir jetzt ein Modell erstellen, um diese Tabelle zu beschreiben:
# 数据的矩阵化import numpy as np data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])row = 0for line in data: row += 1print( row )print(data.size)print(data)
Die erste Codezeile hier bedeutet, NumPy einzuführen und in np umzubenennen. In der zweiten Zeile verwenden wir die Methode mat() in NumPy, um eine Datenmatrix zu erstellen, und row ist die Variable, die zur Berechnung der Anzahl der Zeilen eingeführt wird.
Die Größe hier bedeutet eine Tabelle von 5*5. Sie können die Daten sehen, indem Sie die Daten direkt ausdrucken: 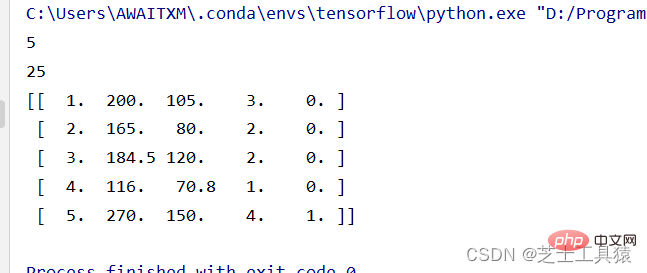
Schauen wir uns die obere Tabelle an der Unterschied bei den Immobilienpreisen ist nicht einfach, den Unterschied intuitiv zu erkennen (da es nur Zahlen gibt), also hoffen wir, ihn zu zeichnen (Die Möglichkeit, numerische Unterschiede und Anomalien zu untersuchen, besteht darin, die Verteilung von Daten zu zeichnen):
import numpy as npimport scipy.stats as statsimport pylab data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])coll = []for row in data: coll.append(row[0,1])stats.probplot(coll,plot=pylab)pylab.show()
Das Ergebnis dieses Codes ist die Generierung eines Bildes: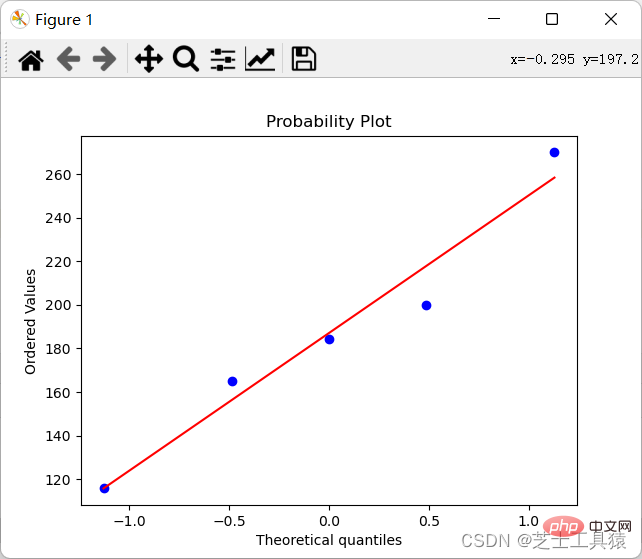
Damit wir den Unterschied klar erkennen können.
Die Anforderung an ein Koordinatendiagramm besteht darin, die spezifischen Datenwerte in verschiedenen Zeilen und Spalten anzuzeigen.
Natürlich können wir auch das Koordinatendiagramm anzeigen: 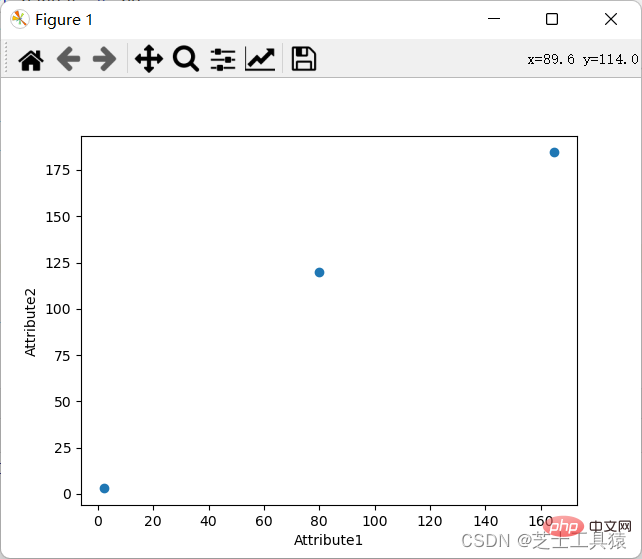
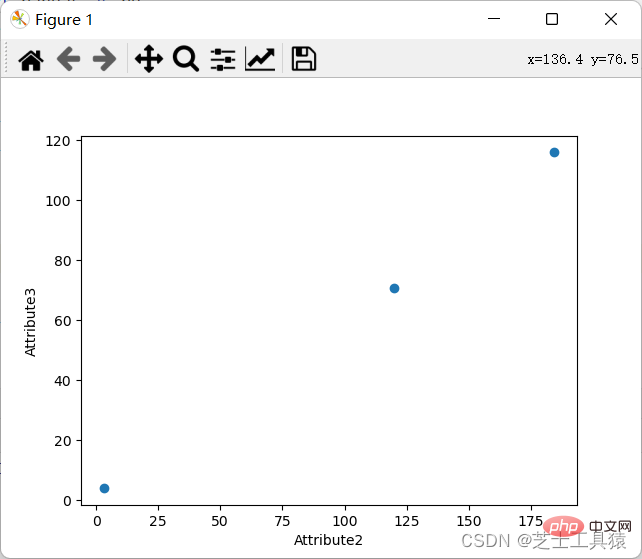
Es gibt viele Möglichkeiten, die Ähnlichkeit zu berechnen. Wir wählen die beiden am häufigsten verwendeten aus. nämlich die Berechnung der euklidischen geodischen Ähnlichkeit und der Kosinusähnlichkeit.
Die euklidische Distanz wird verwendet, um die wahre Distanz zwischen zwei Punkten im dreidimensionalen Raum darzustellen. Eigentlich kennen wir alle die Formel, aber den Namen hören wir selten: 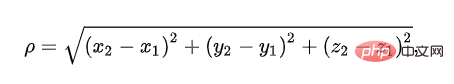
Dann werfen wir einen Blick auf die praktische Anwendung:
Diese Tabelle enthält die Bewertungen von Artikeln durch 3 Benutzer: 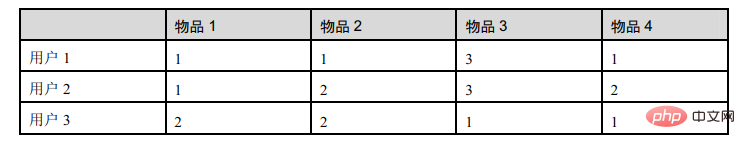
d12 gibt die Ähnlichkeit zwischen Benutzer 1 und an Benutzer 2 Grad, dann gibt es: 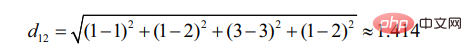
Ebenso d13: 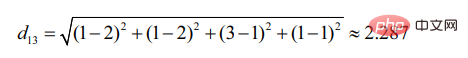
Es ist ersichtlich, dass Benutzer 2 Benutzer 1 ähnlicher ist (je kleiner der Abstand, desto größer die Ähnlichkeit).
Der Ausgangspunkt für die Berechnung des Kosinuswinkels ist die Differenz im eingeschlossenen Winkel. 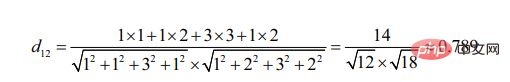
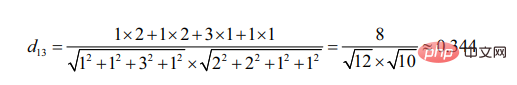
Es ist ersichtlich, dass Benutzer 2 im Vergleich zu Benutzer 3 Benutzer 1 ähnlicher ist (je ähnlicher die beiden Ziele sind, desto kleiner ist der Winkel, den ihre Liniensegmente bilden)
Quartile sind eine Art Quantil in der Statistik, das heißt, die Daten werden von klein nach groß angeordnet und dann in vier gleiche Teile unterteilt. in drei Unterteilungen Die Daten an der Punktposition sind die Quartile.
Erstes Quartil (Q1), auch unteres Quartil genannt;
Zweites Quartil (Q1), auch dritte Quartilmenge (Q1)
genannt; Die Lücke zwischen dem dritten Quartil und dem ersten Quartil wird auch Interquartillücke (IQR) genannt.
若n为项数,则: 四分位示例: 以下是plot运行结果: 那么每月的降水增减程度如何比较? 结果如图: 那么每月降水是否相关? 结果如图: 今天就记录到这里了,我们下次再见!希望本文章对你也有所帮助。 推荐学习:python学习教程
Q1的位置 = (n+1)*0.25
Q2的位置 = (n+1)*0.50
Q3的位置 = (n+1)*0.75
关于这个rain.csv,有需要的可以私我要文件,我使用的是亳州市2010-2019年的月份降水情况。from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()print(summary)array = dataFile.iloc[:,:].values
boxplot(array)plot.xlabel("year")plot.ylabel("rain")show()Nach dem Login kopieren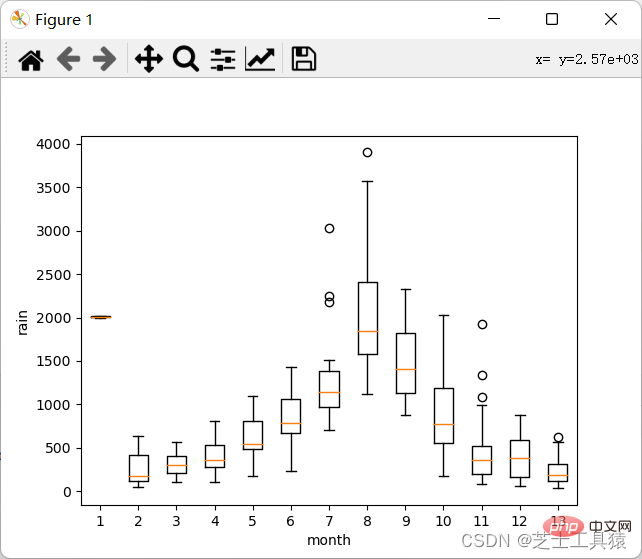
这个是pandas的运行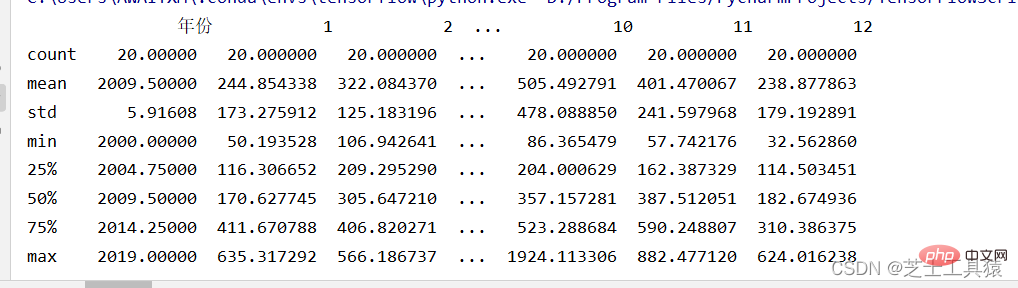
这里就可以很清晰的看出来数据的波动范围。
可以看出,不同月份的降水量有很大差距,8月最多,1-4月和10-12月最少。from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()minRings = -1maxRings = 99nrows = 11for i in range(nrows):
dataRow = dataFile.iloc[i,1:13]
labelColor = ( (dataFile.iloc[i,12] - minRings ) / (maxRings - minRings) )
dataRow.plot(color = plot.cm.RdYlBu(labelColor),alpha = 0.5)plot.xlabel("Attribute")plot.ylabel(("Score"))show()Nach dem Login kopieren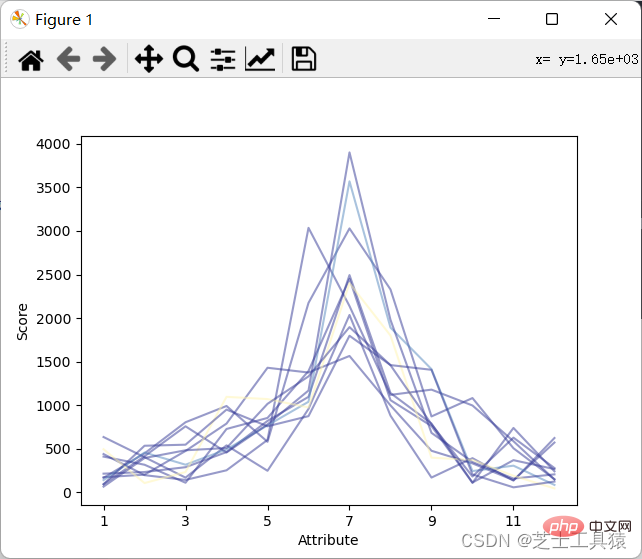
可以看出来降水月份并不规律的上涨或下跌。from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()corMat = pd.DataFrame(dataFile.iloc[1:20,1:20].corr())plot.pcolor(corMat)plot.show()Nach dem Login kopieren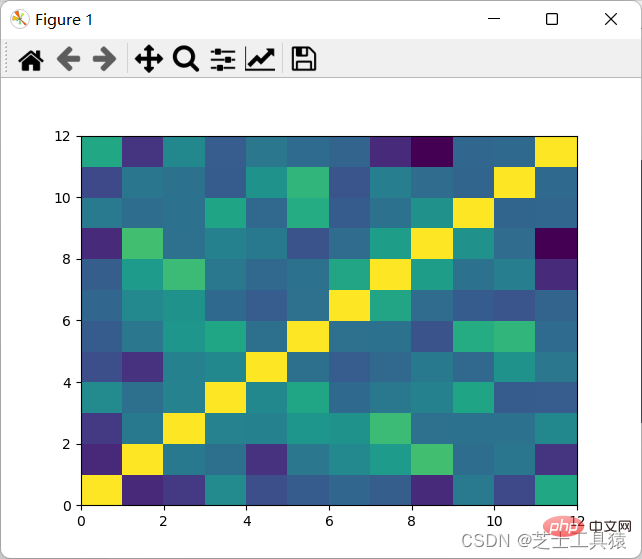
可以看出,颜色分布十分均匀,表示没有多大的相关性,因此可以认为每月的降水是独立行为。
Das obige ist der detaillierte Inhalt vonVertiefte Kenntnisse der Python-Datenverarbeitung und -visualisierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



