


Linux-Swap bezieht sich auf die Linux-Swap-Partition, bei der es sich um einen Bereich auf der Festplatte handelt. Dabei kann es sich um eine Partition, eine Datei oder eine Kombination aus beidem handeln. Der Swap ähnelt dem virtuellen Speicher von Windows nicht ausreicht, virtualisieren Sie einen Teil des Festplattenspeichers im Speicher, um das Problem der unzureichenden Speicherkapazität zu lösen.

Die Betriebsumgebung dieses Tutorials: Linux5.9.8-System, Dell G3-Computer.
Linux-Swap
Linux-Swap-Partition (Swap) oder Speicherersatzraum (Swap-Space) ist ein Bereich auf der Festplatte, der eine Partition, eine Datei oder eine Kombination daraus sein kann.
SWAP funktioniert ähnlich wie „virtueller Speicher“ unter Windows. Wenn der physische Speicher nicht ausreicht, wird ein Teil des Festplattenspeichers als SWAP-Partition verwendet (virtuell in Speicher umgewandelt), um das Problem der unzureichenden Speicherkapazität zu lösen.
SWAP bedeutet Swap. Wenn ein Prozess Speicher vom Betriebssystem anfordert und feststellt, dass dieser nicht ausreicht, lagert das Betriebssystem die vorübergehend nicht verwendeten Daten im Speicher aus und platziert sie in der SWAP-Partition AUSTAUSCHEN. Wenn ein Prozess diese Daten benötigt und das Betriebssystem feststellt, dass freier physischer Speicher vorhanden ist, lagert es die Daten in der SWAP-Partition zurück in den physischen Speicher. Dieser Vorgang wird als SWAP IN bezeichnet.
Natürlich gibt es eine Obergrenze für die Swap-Größe. Sobald der Swap aufgebraucht ist, löst das Betriebssystem den OOM-Killer-Mechanismus aus, um den Prozess abzubrechen, der den meisten Speicher verbraucht, um Speicher freizugeben.
Warum mag das Datenbanksystem keinen Austausch?
Offensichtlich besteht die ursprüngliche Absicht des Swap-Mechanismus darin, die Peinlichkeit zu lindern, wenn der physische Speicher knapp wird und den OOM-Prozess direkt beeinträchtigt. Aber ehrlich gesagt mögen fast alle Datenbanken keinen Swap, egal ob MySQL, Oracal, MongoDB oder HBase. Dies hängt hauptsächlich mit den folgenden zwei Aspekten zusammen:
1. Datenbanksysteme reagieren im Allgemeinen empfindlich auf Antwortverzögerungen. Wenn Swap anstelle von Speicher verwendet wird, ist die Leistung des Datenbankdienstes zwangsläufig inakzeptabel. Bei Systemen, die äußerst empfindlich auf Antwortverzögerungen reagieren, gibt es keinen Unterschied zwischen zu großer Verzögerung und Nichtverfügbarkeit des Dienstes. Schwerwiegender als die Nichtverfügbarkeit des Dienstes ist, dass der Prozess im Swap-Szenario nicht abstürzt, was bedeutet, dass das System immer nicht verfügbar war ...Denken Sie noch einmal darüber nach. Ist es eine bessere Wahl, direkt ohne Swap zu wechseln? Auf diese Weise wechseln viele Hochverfügbarkeitssysteme direkt zwischen Master und Slave, ohne dass sich die Benutzer dessen bewusst sind.
2. Darüber hinaus machen wir uns bei verteilten Systemen wie HBase eigentlich keine Sorgen, dass ein bestimmter Knoten ausfällt, sondern dass ein bestimmter Knoten hängen bleibt. Wenn ein Knoten ausfällt, ist höchstens eine kleine Anzahl von Anfragen vorübergehend nicht verfügbar und kann durch einen erneuten Versuch wiederhergestellt werden. Wenn jedoch ein Knoten blockiert ist, werden alle verteilten Anforderungen blockiert und die serverseitigen Thread-Ressourcen werden belegt, was dazu führt, dass die gesamte Clusteranforderung blockiert wird und sogar der Cluster heruntergefahren wird.
Aus diesen beiden Perspektiven macht es Sinn, dass nicht alle Datenbanken Swaps mögen!
Der Funktionsmechanismus von Swap
Da Datenbanken Swap nicht mögen, ist es notwendig, den Befehl swapoff zu verwenden, um die Festplatten-Cache-Funktion zu deaktivieren? Nein, Sie können darüber nachdenken. Was bedeutet das Ausschalten des Festplatten-Cache? Kein System in der tatsächlichen Produktionsumgebung wird so radikal sein. Sie müssen wissen, dass die Welt niemals entweder 0 oder 1 ist. Jeder wird sich mehr oder weniger dafür entscheiden, in der Mitte zu gehen, aber einige tendieren zu 0 und andere zu 1. Wenn es um den Austausch geht, muss sich die Datenbank natürlich dafür entscheiden, ihn so wenig wie möglich zu verwenden. Mehrere Anforderungen in den offiziellen HBase-Dokumenten bestehen tatsächlich darin, diese Richtlinie umzusetzen: die Auswirkungen des Swaps so weit wie möglich zu reduzieren. Nur wenn Sie sich selbst und Ihren Feind kennen, können Sie jeden Kampf gewinnen. Um die Auswirkungen des Austauschs zu verringern, müssen Sie verstehen, wie das Linux-Speicherrecycling funktioniert, um keine möglichen Zweifel zu übersehen.
Werfen wir zunächst einen Blick darauf, wie der Tausch ausgelöst wird?
Um es einfach auszudrücken: Linux löst das Speicherrecycling in zwei Szenarien aus. Zum einen wird das Speicherrecycling sofort ausgelöst, wenn festgestellt wird, dass während der Speicherzuweisung nicht genügend freier Speicher vorhanden ist Der Prozesszyklus wird gestartet. Überprüft kontinuierlich den Systemspeicher und löst aktiv die Speicherrückgewinnung aus, nachdem der verfügbare Speicher auf einen bestimmten Schwellenwert gesunken ist. Zum ersten Szenario gibt es nichts zu sagen. Konzentrieren wir uns auf das zweite Szenario, wie in der folgenden Abbildung dargestellt:

Hier ist der erste Parameter, der uns beschäftigt: vm.min_free_kbytes, der den reservierten freien Speicher darstellt Das Mindestwasserzeichen wird vom System festgelegt und wirkt sich auf Wasserzeichen [niedrig] und Wasserzeichen [hoch] aus. Man kann es sich einfach wie folgt vorstellen:
watermark[min] = min_free_kbytes watermark[low] = watermark[min] * 5 / 4 = min_free_kbytes * 5 / 4 watermark[high] = watermark[min] * 3 / 2 = min_free_kbytes * 3 / 2 watermark[high] - watermark[low] = watermark[low] - watermark[min] = min_free_kbytes / 4
Es ist ersichtlich, dass diese Wasserstände von Linux untrennbar mit dem Parameter min_free_kbytes verbunden sind. Die Bedeutung von min_free_kbytes für das System liegt auf der Hand. Es darf nicht zu groß oder zu klein sein.
Wenn min_free_kbytes zu klein ist, wird der Wasserstandspuffer zwischen [min, niedrig] sehr klein sein. Sobald die obere Schicht zu schnell Speicher beansprucht (typische Anwendung: Datenbank), wird der freie Speicher leicht abnehmen .Unter dem Wasserzeichen [min] führt der Kernel zu diesem Zeitpunkt eine direkte Wiederherstellung durch, fordert direkt im Prozesskontext der Anwendung zurück und verwendet dann die wiederhergestellten freien Seiten, um die Speicheranforderung zu erfüllen, sodass die Anwendung tatsächlich blockiert und verursacht wird Dort wird eine gewisse Reaktionsverzögerung sein. Natürlich sollte min_free_kbytes nicht zu groß sein, wenn es einerseits den Speicher des Anwendungsprozesses verringert und Systemspeicherressourcen verschwendet. Andererseits führt es auch dazu, dass der kswapd-Prozess verbraucht wird viel Zeit für das Speicherrecycling. Schauen Sie sich diesen Prozess noch einmal an. Ist er dem Recycling-Auslösemechanismus der alten Generation im CMS-Algorithmus im Java-Garbage-Collection-Mechanismus ähnlich? Das offizielle Dokument verlangt, dass min_free_kbytes nicht weniger als 1 GB betragen darf (in Systemen mit großem Speicher auf 8 GB festgelegt), was bedeutet, dass es nicht einfach ist, ein direktes Recycling auszulösen.
An dieser Stelle werden im Wesentlichen der Speicherrecycling-Auslösemechanismus von Linux und der erste Parameter vm.min_free_kbytes erläutert, der uns Sorgen bereitet. Als nächstes werfen wir einen kurzen Blick darauf, was das Linux-Speicherrecycling recycelt. Linux-Speicherrecyclingobjekte werden hauptsächlich in zwei Typen unterteilt:
1. Dateicache, dies ist leicht zu verstehen. Um zu vermeiden, dass Dateidaten jedes Mal von der Festplatte gelesen werden müssen, speichert das System Hotspot-Daten im Speicher um die Leistung zu verbessern. Wenn Sie die Datei nur lesen, muss durch das Speicherrecycling nur dieser Teil des Speichers freigegeben werden. Wenn Sie die Dateidaten das nächste Mal lesen, können Sie sie direkt von der Festplatte lesen (ähnlich wie beim HBase-Dateicache). Wenn die Dateien nicht nur ausgelesen werden, sondern auch die zwischengespeicherten Dateidaten verändert werden (schmutzige Daten), muss dieser Teil der Datendatei auf die Festplatte geschrieben und dann freigegeben werden, um den Speicher wiederzuverwenden (ähnlich wie bei der MySQL-Datei). Cache).
2. Anonymer Speicher, dieser Teil des Speichers hat keinen tatsächlichen Träger, im Gegensatz zum Datei-Cache, der einen Träger wie Festplattendateien, wie etwa typische Heap- und Stack-Daten, hat. Dieser Teil des Speichers kann beim Recycling nicht direkt freigegeben oder auf ein dateiähnliches Medium zurückgeschrieben werden. Aus diesem Grund wurde der Swap-Mechanismus entwickelt, um diesen Speichertyp auf die Festplatte auszulagern und bei Bedarf wieder zu laden.
Der spezifische Algorithmus, der von Linux verwendet wird, um zu bestimmen, welche Datei-Caches oder anonymen Speicher recycelt werden müssen, ist hier nicht von Belang. Wenn Sie interessiert sind, können Sie hier nachschlagen. Aber es gibt eine Frage, über die wir nachdenken müssen: Da es zwei Arten von Speicher gibt, die recycelt werden können, wie entscheidet Linux, welcher Speichertyp recycelt werden soll, wenn beide Speichertypen recycelt werden können? Oder werden beide recycelt? Dies bringt uns zum zweiten Parameter, der uns wichtig ist: Swapiness. Dieser Wert wird verwendet, um zu definieren, wie aktiv der Kernel Swap verwendet. Positivität. Der Wert liegt zwischen 0 und 100, der Standardwert ist 60. Wie wird diese Austauschbarkeit erreicht? Das spezifische Prinzip ist sehr kompliziert. Vereinfacht ausgedrückt erreicht Swapiness diesen Effekt, indem es steuert, ob beim Speicherrecycling mehr anonyme Seiten oder mehr Dateicaches recycelt werden. swappiness ist gleich 100, was bedeutet, dass anonymer Speicher und Dateicache mit derselben Priorität recycelt werden. Der Standardwert 60 bedeutet, dass der Dateicache zuerst recycelt werden sollte Denken Sie darüber nach (die übliche Situation, in der der Dateicache wiederverwendet wird. Es verursacht keine E/A-Vorgänge und hat kaum Auswirkungen auf die Systemleistung). Bei Datenbanken sollte Swap so weit wie möglich vermieden werden, daher muss es auf 0 gesetzt werden. Hierbei ist zu beachten, dass die Einstellung auf 0 nicht bedeutet, dass der Swap nicht ausgeführt wird!
Bisher haben wir über den Linux-Speicherrecycling-Auslösemechanismus, Linux-Speicherrecyclingobjekte und Swap gesprochen und die Parameter min_free_kbytes und swappiness erklärt. Schauen wir uns als Nächstes einen weiteren Parameter im Zusammenhang mit Swap an: Zone_reclaim_mode. Das Dokument besagt, dass das Setzen dieses Parameters auf 0 die Zonenrückgewinnung von NUMA deaktivieren kann. Wenn es um NUMA geht, sind Datenbanken wieder nicht zufrieden. Viele Datenbankadministratoren wurden betrogen. Hier sind drei kleine Fragen: Was ist NUMA? Welche Beziehung besteht zwischen NUMA und Swap? Was ist die spezifische Bedeutung von zone_reclaim_mode?
NUMA (Non-Uniform Memory Access) ist relativ zu UMA. Frühe CPUs wurden als UMA-Strukturen entworfen, wie im Bild unten gezeigt (Bilder aus dem Internet):
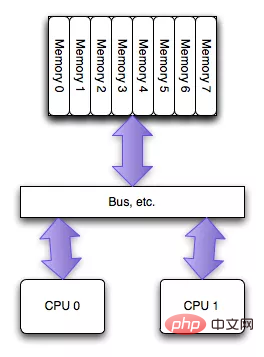
Für To Um das Kanalengpassproblem zu lindern, das bei Multi-Core-CPUs beim Lesen desselben Speichers auftritt, haben Chipingenieure eine NUMA-Struktur entworfen, wie in der folgenden Abbildung (Bild aus dem Internet) dargestellt:
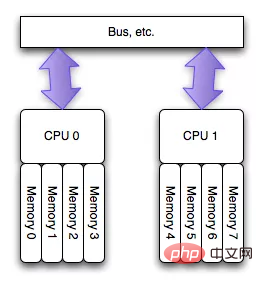
Diese Architektur kann das Problem gut lösen von UMA, das heißt, verschiedene CPUs verfügen über exklusive Speicherbereiche. Um eine „Speicherisolation“ zwischen CPUs zu erreichen, sind zwei Unterstützungspunkte auf Softwareebene erforderlich:
1. 内存分配需要在请求线程当前所处CPU的专属内存区域进行分配。如果分配到其他CPU专属内存区,势必隔离性会受到一定影响,并且跨越总线的内存访问性能必然会有一定程度降低。
2. 另外,一旦local内存(专属内存)不够用,优先淘汰local内存中的内存页,而不是去查看远程内存区是否会有空闲内存借用。
这样实现,隔离性确实好了,但问题也来了:NUMA这种特性可能会导致CPU内存使用不均衡,部分CPU专属内存不够使用,频繁需要回收,进而可能发生大量swap,系统响应延迟会严重抖动。而与此同时其他部分CPU专属内存可能都很空闲。这就会产生一种怪现象:使用free命令查看当前系统还有部分空闲物理内存,系统却不断发生swap,导致某些应用性能急剧下降。见叶金荣老师的MySQL案例分析:《找到MySQL服务器发生SWAP罪魁祸首》。
所以,对于小内存应用来讲,NUMA所带来的这种问题并不突出,相反,local内存所带来的性能提升相当可观。但是对于数据库这类内存大户来说,NUMA默认策略所带来的稳定性隐患是不可接受的。因此数据库们都强烈要求对NUMA的默认策略进行改进,有两个方面可以进行改进:
1. 将内存分配策略由默认的亲和模式改为interleave模式,即会将内存page打散分配到不同的CPU zone中。通过这种方式解决内存可能分布不均的问题,一定程度上缓解上述案例中的诡异问题。对于MongoDB来说,在启动的时候就会提示使用interleave内存分配策略:
WARNING: You are running on a NUMA machine. We suggest launching mongod like this to avoid performance problems: numactl –interleave=all mongod [other options]
2. 改进内存回收策略:此处终于请出今天的第三个主角参数zone_reclaim_mode,这个参数定义了NUMA架构下不同的内存回收策略,可以取值0/1/3/4,其中0表示在local内存不够用的情况下可以去其他的内存区域分配内存;1表示在local内存不够用的情况下本地先回收再分配;3表示本地回收尽可能先回收文件缓存对象;4表示本地回收优先使用swap回收匿名内存。可见,HBase推荐配置zone_reclaim_mode=0一定程度上降低了swap发生的概率。
不都是swap的事
至此,我们探讨了三个与swap相关的系统参数,并且围绕Linux系统内存分配、swap以及NUMA等知识点对这三个参数进行了深入解读。除此之外,对于数据库系统来说,还有两个非常重要的参数需要特别关注:
1. IO调度策略:这个话题网上有很多解释,在此并不打算详述,只给出结果。通常对于sata盘的OLTP数据库来说,deadline算法调度策略是最优的选择。
2. THP(transparent huge pages)特性关闭。THP特性笔者曾经疑惑过很久,主要疑惑点有两点,其一是THP和HugePage是不是一回事,其二是HBase为什么要求关闭THP。经过前前后后多次查阅相关文档,终于找到一些蛛丝马迹。这里分四个小点来解释THP特性:
(1)什么是HugePage?
网上对HugePage的解释有很多,大家可以检索阅读。简单来说,计算机内存是通过表映射(内存索引表)的方式进行内存寻址,目前系统内存以4KB为一个页,作为内存寻址的最小单元。随着内存不断增大,内存索引表的大小将会不断增大。一台256G内存的机器,如果使用4KB小页, 仅索引表大小就要4G左右。要知道这个索引表是必须装在内存的,而且是在CPU内存,太大就会发生大量miss,内存寻址性能就会下降。
HugePage就是为了解决这个问题,HugePage使用2MB大小的大页代替传统小页来管理内存,这样内存索引表大小就可以控制的很小,进而全部装在CPU内存,防止出现miss。
(2)什么是THP(Transparent Huge Pages)?
HugePage是一种大页理论,那具体怎么使用HugePage特性呢?目前系统提供了两种使用方式,其一称为Static Huge Pages,另一种就是Transparent Huge Pages。前者根据名称就可以知道是一种静态管理策略,需要用户自己根据系统内存大小手动配置大页个数,这样在系统启动的时候就会生成对应个数的大页,后续将不再改变。而Transparent Huge Pages是一种动态管理策略,它会在运行期动态分配大页给应用,并对这些大页进行管理,对用户来说完全透明,不需要进行任何配置。另外,目前THP只针对匿名内存区域。
(3)HBase(数据库)为什么要求关闭THP特性?
THP ist eine dynamische Verwaltungsstrategie, die große Seiten während der Laufzeit zuweist und verwaltet, sodass es zu einer gewissen Zuteilungsverzögerung kommt, was für Datenbanksysteme, die Antwortverzögerungen verfolgen, nicht akzeptabel ist. Darüber hinaus hat THP viele weitere Nachteile. Sie können sich auf diesen Artikel „Why-tokudb-hates-transparent-hugepages“ beziehen.
(4) Welchen Einfluss hat das Ein-/Ausschalten von THP auf die Lese- und Schreibleistung von HBase?
Um die Auswirkungen des Ein- und Ausschaltens von THP auf die HBase-Leistung zu überprüfen, habe ich einen einfachen Test in der Testumgebung durchgeführt: Der Testcluster verfügt nur über einen RegionServer und die Testlast beträgt ein Lese-/Schreibverhältnis von 1:1 . THP verfügt über zwei Optionen: „immer“ und „nie“ in einigen Systemen und eine zusätzliche Option namens „Madvise“ in einigen Systemen. Sie können den Befehl echo never/always > /sys/kernel/mm/transparent_hugepage/enabled verwenden, um THP aus-/einzuschalten. Die Testergebnisse sind in der folgenden Abbildung dargestellt:

Wie in der Abbildung oben gezeigt, weist HBase im TPH-Abschaltszenario (nie) die beste Leistung auf und ist relativ stabil. In der Szene, in der THP (immer) eingeschaltet ist, sinkt die Leistung um etwa 30 % im Vergleich zur Szene, in der THP ausgeschaltet ist, und die Kurve zittert stark. Es ist ersichtlich, dass daran gedacht ist, THP online in HBase auszuschalten.
Verwandte Empfehlungen: „Linux-Video-Tutorial“
Das obige ist der detaillierte Inhalt vonWas ist Linux-Swap?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



