Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL-Protokolle. Wir müssen uns auf das Binärprotokoll (Binlog) und das Transaktionsprotokoll (einschließlich Redo-Protokoll und Rückgängig-Protokoll) konzentrieren.

1. Binlog
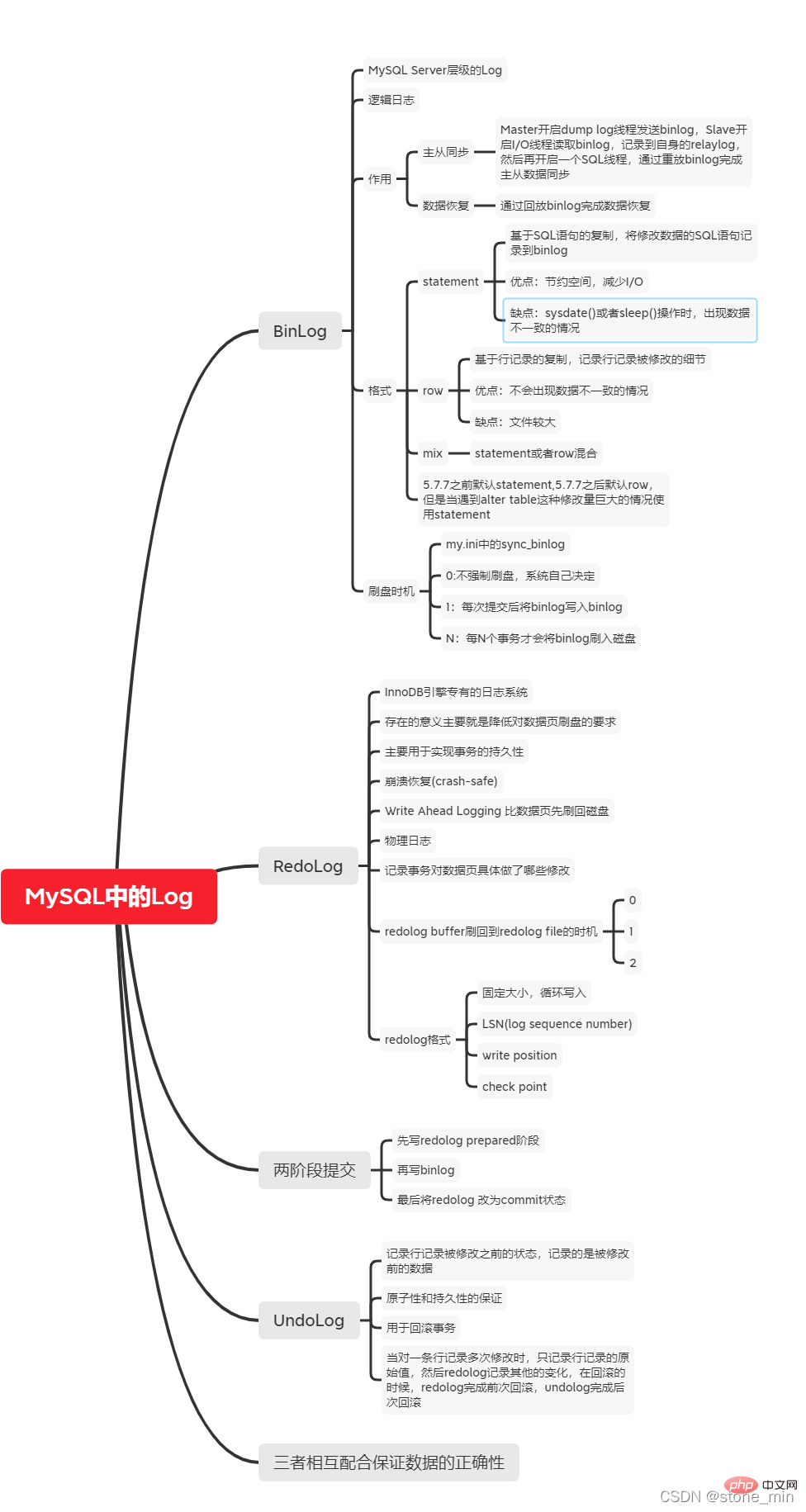
Binlog wird zum Aufzeichnen von von der Datenbank durchgeführten Informationen zu Schreibvorgängen (ausgenommen Abfragen) verwendet und in binärer Form auf der Festplatte gespeichert. Binlog ist das logische Protokoll von MySQL und wird von der Serverebene mit jeder Speicher-Engine aufgezeichnet, die Binlog-Protokolle aufzeichnet.
- Logisches Protokoll: kann einfach als SQL-Anweisung verstanden werden;
- Physisches Protokoll: Daten in MySQL werden auf der Datenseite gespeichert, und das physische Protokoll zeichnet Änderungen auf der Datenseite auf.
Binlog wird durch Anhängen geschrieben. Sie können die Größe jeder Binlog-Datei über den Parameter max_binlog_size festlegen. Wenn die Dateigröße einen bestimmten Wert erreicht, wird eine neue Datei zum Speichern des Protokolls generiert.
Binlog-Nutzungsszenarien
Projekt In praktischen Anwendungen gibt es zwei Hauptnutzungsszenarien von Binlog, nämlich Master-Slave-Replikation und Datenwiederherstellung.
- Master-Slave-Replikation: Aktivieren Sie das Binlog auf der Master-Seite und senden Sie das Binlog dann an jede Slave-Seite. Die Slave-Seite spielt das Binlog erneut ab, um eine Master-Slave-Datenkonsistenz zu erreichen.
- Datenwiederherstellung: Stellen Sie Daten mit dem mysqlbinlog-Tool wieder her.
MySQL-Master-Slave-Synchronisationsprinzip
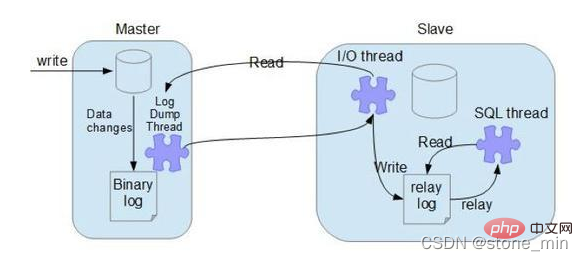
- Master-Knoten-Binlog-Dump-Thread
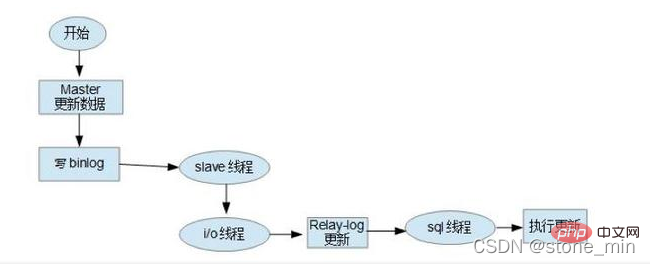
Wenn der Slave-Knoten eine Verbindung zum Master-Knoten herstellt, erstellt der Master-Knoten einen Log-Dump-Thread, um den Inhalt des Binlogs zu senden. Bei Lesevorgängen im Binlog sperrt dieser Thread das Binlog auf dem Master-Knoten. Wenn der Lesevorgang abgeschlossen ist, wird die Sperre aufgehoben, noch bevor sie an den Slave-Knoten gesendet wird Slave-Knoten Nach der Ausführung des Start-Slave-Befehls auf dem Knoten erstellt der Slave-Knoten einen E/A-Thread, um eine Verbindung zum Master-Knoten herzustellen und das aktualisierte Binlog in der Master-Bibliothek anzufordern. Nachdem der E/A-Thread die Aktualisierung vom Binlog-Dump-Prozess des Master-Knotens erhalten hat, speichert er sie im lokalen Relaylog und deren Ausführung, um letztendlich die Konsistenz der Master-Slave-Daten sicherzustellen; MySQL-Datenbank-Master-Slave-Synchronisationsprinzip
- Inhalt von Binlog
Wie oben erwähnt, ist Binlog ein logisches Protokoll, das einfach als SQL-Anweisung verstanden werden kann. Tatsächlich umfasst es jedoch auch die Ausführung der umgekehrten Logik der SQL-Anweisung. delete entspricht dem Löschen selbst, und das Reverse-Insert-Update enthält Informationen über die Datenzeilen vor und nach der Ausführung des entsprechenden Updates.
Binlog-Format Es gibt drei Binlog-Formate, nämlich Anweisung, Zeile und gemischt. Vor MySQL 5.7.7 wurde standardmäßig die Anweisung verwendet, und nach MySQL 5.7.7 wurde standardmäßig die Zeile verwendet. Das Format des Protokolls kann über binlog-format in der Konfigurationsdatei my.ini geändert werden.
(1) Anweisung: Aussagebasierte Replikation (SBR), jede SQL-Anweisung, die Daten ändert, wird im Binlog aufgezeichnet.
Vorteile: Änderungen in einer bestimmten Zeile müssen nicht speziell aufgezeichnet werden, was Platz spart, E/A reduziert und die Leistung verbessert.
Nachteile: Bei der Ausführung von Vorgängen wie sysdate() oder sleep() kann es zu Inkonsistenzen zwischen Mastern kommen und Slave-Daten;
(2)Zeile: Zeilenbasierte Replikation (RBR), die keine kontextbezogenen Informationen der SQL-Anweisung aufzeichnet, sondern die Details darüber aufzeichnet, welcher Datensatz geändert wurde. -
- Vorteile: Die Details der Änderung jeder Datensatzzeile werden sehr detailliert aufgezeichnet, sodass es keine Situation gibt, in der die Daten nicht korrekt kopiert werden können.
Nachteile: Da die Details der Änderung jedes Datensatzes aufgezeichnet werden Im Detail wird dadurch eine große Anzahl von Protokollinhalten generiert. Gehen Sie davon aus, dass eine Aktualisierungsanweisung vorliegt und viele Datensätze geändert werden. Jeder geänderte Datensatz wird im Binlog aufgezeichnet. Insbesondere bei der Operation alter table ändert sich aufgrund von Änderungen in der Tabellenstruktur jede Datensatzzeile, was zu einem plötzlichen Anstieg des Protokollvolumens führt.
(3) gemischt: Gemäß der obigen Anweisung und Zeile Jedes hat seine eigenen Vor- und Nachteile. Daher erschien die gemischte Version, in der beide gemischt wurden. Unter normalen Umständen wird zum Speichern das Anweisungsformat verwendet. Wenn die Anweisung nicht gelöst werden kann, wechseln Sie zum Speichern in das Zeilenformat. - Wie oben erwähnt, verwendet die neue Version (nach MySQL 5.7.7) standardmäßig das Zeilenformat, wenn die Änderungstabellenoperation auftritt Andere Vorgänge verwenden weiterhin das Zeilenformat.
- Binlog-Löschzeitpunkt
Für die InnoDB-Speicher-Engine wird das Binlog nur aufgezeichnet, wenn die Transaktion übermittelt wird. Zu diesem Zeitpunkt befindet sich der Datensatz noch im Speicher, und zwar über sync_binlog Wertebereich ist 0-N:
- 0: Es ist nicht erzwungen, auf die Festplatte zu schreiben, und das System entscheidet, wann es auf die Festplatte geschrieben wird.
- 1: Das Binlog muss nach jeder Übermittlung auf die Festplatte geschrieben werden , das Binlog wird auf die Festplatte geschrieben.
- Wie aus dem Obigen ersichtlich ist, ist die sicherste Einstellung für sync_binlog 1, was auch der Standardwert für MySQL-Versionen nach 5.7.7 ist. Das Festlegen eines größeren Werts kann jedoch die Datenbankleistung verbessern. Daher können Sie in tatsächlichen Situationen den Wert auch entsprechend erhöhen und einen gewissen Grad an Konsistenz opfern, um eine bessere Leistung zu erzielen.
Die physische Dateigröße von Binlog
In der Konfigurationsdatei my.ini kann die Größe des Binlogs über max_binlog_size konfiguriert werden. Wenn das Protokollvolumen die Größe der Binlog-Datei überschreitet, generiert das System eine neue Datei neu, um mit dem Speichern der Datei fortzufahren. Was soll ich tun, wenn eine Transaktion relativ groß ist oder immer mehr Protokolle vorhanden sind und der zu diesem Zeitpunkt belegte physische Speicherplatz zu groß ist? MySQL bietet einen automatischen Löschmechanismus, der durch Konfigurieren des Parameters „expire_logs_days“ in der Konfigurationsdatei „my.ini“ gelöst werden kann. Die Einheit ist Tage. Wenn dieser Parameter 0 ist, bedeutet dies, dass er niemals gelöscht wird. Wenn er N ist, bedeutet dies, dass er nach dem N-ten Tag automatisch gelöscht wird.
2. Redo-Log
redolog ist das proprietäre Protokollsystem der InnoDB-Engine. Es wird hauptsächlich verwendet, um Transaktionsdauerhaftigkeit und absturzsichere Funktionen zu erreichen. Redolog ist ein physisches Protokoll, das die spezifischen Änderungen auf der Datenseite aufzeichnet, nachdem die SQL-Anweisung ausgeführt wurde.
Wir alle wissen, dass Daten von der Festplatte in den Speicher geladen werden, wenn MySQL ausgeführt wird. Wenn eine SQL-Anweisung zum Ändern der Daten ausgeführt wird, wird der geänderte Inhalt tatsächlich nur vorübergehend im Speicher gespeichert. Wenn zu diesem Zeitpunkt die Stromversorgung unterbrochen wird oder andere Umstände eintreten, gehen diese Änderungen verloren. Daher sucht MySQL nach der Änderung der Daten nach Möglichkeiten, diese Speicherdatensätze zurück auf die Festplatte zu schreiben. Es gibt jedoch ein Leistungsproblem, hauptsächlich in zwei Aspekten:
InnoDB interagiert mit der Festplatte in Dateneinheiten von Seiten, und eine Transaktion ändert möglicherweise nur einige Bytes auf einer Seite, wenn ein Zurückspülen vollständiger Datenseiten auf die Festplatte erfolgt Verschwendung von Ressourcen;
Eine Transaktion kann mehrere Datenseiten umfassen, die nur logisch, aber nicht physisch kontinuierlich sind. Daher ist die Leistung von MySQL zu gering, um die spezifischen Änderungen aufzuzeichnen die Datenseite durch die Transaktion und leeren Sie dann das Redolog zurück auf die Festplatte. Möglicherweise haben Sie Zweifel. Ursprünglich wollte ich io reduzieren. Würde dies nicht ein weiteres io hinzufügen? Die Designer von InnoDB haben diese zu Beginn des Entwurfs berücksichtigt. Redolog-Dateien sind im Allgemeinen relativ klein, und der Vorgang des Zurückflashens auf die Festplatte erfolgt über sequentielle E/A, was eine bessere Leistung als zufällige E/A bietet.
Grundkonzept des Redo-Logs
Redolog besteht aus zwei Teilen: Einer ist der Redo-Log-Puffer im Speicher und der andere ist die Redo-Log-Datei auf der Festplatte. Jedes Mal, wenn der Datensatz geändert wird, werden diese Änderungen zuerst in den Redo-Log-Puffer geschrieben und dann auf die entsprechende Gelegenheit gewartet, um die Änderungen im Speicher zurück in die Redo-Log-Datei zu schreiben. Diese Technologie, bei der zuerst Protokolle geschrieben und dann auf die Festplatte geschrieben werden, ist die WAL-Technologie (Write-Ahead Logging). Es ist zu beachten, dass das Redolog vor der Datenseite auf die Festplatte zurückgeschrieben wird. Änderungen am Clustered-Index, am Sekundärindex und an der Rückgängig-Seite müssen alle im Redolog aufgezeichnet werden.
In Computer-Betriebssystemen können Pufferdaten im Benutzerbereich im Allgemeinen nicht direkt auf die Festplatte geschrieben werden und müssen den Kernel-Speicherplatzpuffer (OS-Puffer) des Betriebssystems durchlaufen. Wenn Sie also den Redo-Log-Puffer in die Redo-Log-Datei schreiben, wird er tatsächlich zuerst in den Betriebssystempuffer geschrieben und dann über den Systemaufruf fsync () in die Redo-Log-Datei geleert. Der Prozess ist wie folgt:
MySQL unterstützt drei Arten von Redo-Log-Puffer Der Zeitpunkt des Schreibens der Redo-Log-Datei kann über den Parameter innodb_flush_log_at_trx_commit konfiguriert werden. Die Bedeutung jedes Parameterwerts ist wie folgt:
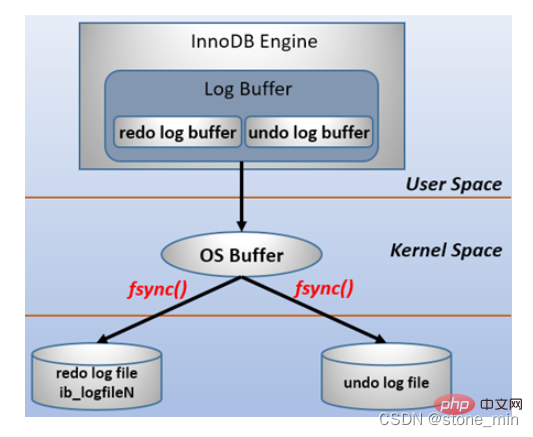
Parameterwert
Bedeutung
|
|
0 (verzögert). Schreiben)
Das Redo wird nicht festgeschrieben, wenn die Transaktion übermittelt wird. Das Protokoll im Protokollpuffer wird in den Betriebssystempuffer geschrieben. Stattdessen wird das Protokoll jede Sekunde in den Betriebssystempuffer geschrieben und fsync() wird aufgerufen, um es zu schreiben die Redo-Log-Datei. Das heißt, bei der Einstellung 0 werden (ungefähr) jede Sekunde Daten auf die Festplatte geschrieben. Bei einem Systemabsturz geht 1 Sekunde Daten verloren.
|
1 (Echtzeitschreiben, Echtzeitbürsten) |
Jedes Mal, wenn eine Transaktion übermittelt wird, wird das Protokoll im Redo-Log-Puffer in den Betriebssystempuffer geschrieben und fsync() wird aufgerufen, um es dorthin zu leeren die Redo-Log-Datei. Bei dieser Methode gehen auch bei einem Systemabsturz keine Daten verloren. Da jedoch jede Übermittlung auf die Festplatte geschrieben wird, ist die E/A-Leistung schlecht.
|
2 (Echtzeitschreiben, verzögertes Bürsten) |
Jede Übermittlung wird nur in den Betriebssystempuffer geschrieben, und dann wird jede Sekunde fsync() aufgerufen, um das Protokoll im Betriebssystempuffer in die Redo-Log-Datei zu schreiben.
|
Redo-Log-Aufzeichnungsformat
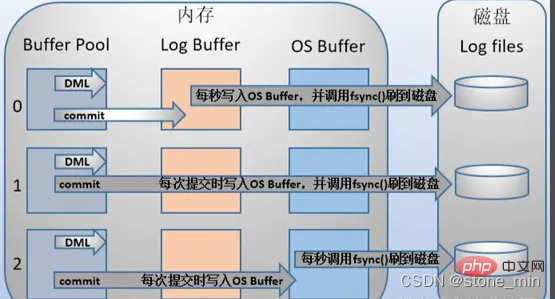
Redolog verwendet eine feste Größe und ein zyklisches Schreibformat. Wenn das Redolog voll ist, wird es erneut von Anfang an geschrieben. Warum ist es so konzipiert?
Der Hauptzweck des Redo-Logs besteht darin, den Bedarf für das Leeren von Datenseiten zu reduzieren. Redolog zeichnet die Änderungen auf der Datenseite auf, aber wenn die Datenseite auch zurück auf die Festplatte geleert wird, verlieren diese Datensätze ihre Wirkung. Wenn MySQL also feststellt, dass das vorherige Redolog seine Wirkung verloren hat, überschreiben die neuen Daten die ungültigen Daten. Wie kann man also beurteilen, ob es abgedeckt werden sollte?
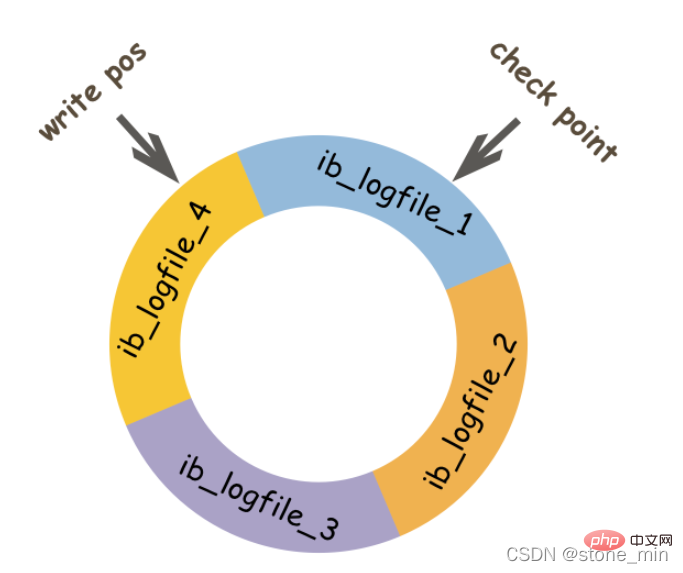
Das obige Bild ist ein schematisches Diagramm der Schreibposition der Redo-Log-Datei, die die aktuell von Redolog aufgezeichnete Log-Sequenznummer LSN (Log-Sequenznummer) darstellt. Wenn die Datenseite zurück auf die Festplatte geleert wurde, wird die LSN in der Redo-Log-Datei aktualisiert, was darauf hinweist, dass die Daten vor dieser LSN auf die Festplatte geschrieben wurden. Diese LSN ist der Prüfpunkt. Der Teil zwischen Schreibposition und Prüfpunkt ist der Ersatzteil von Redolog, der zum Aufzeichnen neuer Datensätze verwendet wird. Der Teil zwischen Prüfpunkt und Schreibposition ist der geänderte Teil der Datenseite, die Redolog aufgezeichnet hat, die Datenseite jedoch nicht wurde zu diesem Zeitpunkt wieder auf die Festplatte zurückgespült. Wenn die Schreibposition den Kontrollpunkt einholt, schiebt sie zunächst den Kontrollpunkt nach vorne, räumt die Position und zeichnet dann ein neues Protokoll auf.
Beim Starten von innodb wird immer ein Wiederherstellungsvorgang durchgeführt, unabhängig davon, ob es beim letzten Mal normal oder ungewöhnlich heruntergefahren wurde. Während der Wiederherstellung wird zuerst die LSN auf der Datenseite überprüft. Wenn diese LSN kleiner ist als die LSN im Redolog, dh die Schreibposition, bedeutet dies, dass die nicht abgeschlossenen Vorgänge auf der Datenseite im Redolog aufgezeichnet werden. und dann beginnt es am nächstgelegenen Kontrollpunkt und beginnt mit der Synchronisierung der Daten.
Ist es möglich, dass die LSN auf der Datenseite größer ist als die LSN im Redolog? Die Antwort ist natürlich möglich. Wenn dies geschieht, wird der Teil, der über das Redolog hinausgeht, nicht wiederholt, da dies selbst bedeutet, dass das, was getan wurde, nicht wiederholt werden muss.
Der Unterschied zwischen Redo Log und Binlog
|
Redo Log |
Binlog |
| Dateigröße |
Die Größe des Redo Log ist festgelegt. |
Binlog kann die Größe jeder Binlog-Datei über den Konfigurationsparameter max_binlog_size festlegen. |
| Implementierungsmethode |
Redo-Log wird von der InnoDB-Engine-Ebene implementiert, nicht alle Engines verfügen darüber. |
Binlog wird von der Serverschicht implementiert. |
| Aufzeichnungsmethode: Redo-Protokollaufzeichnungen in einer Schleife. Beim Schreiben bis zum Ende wird zum Anfang zurückgekehrt, um Protokolle zu schreiben Schleife. |
binlog wird durch Anhängen aufgezeichnet. Wenn die Dateigröße größer als der angegebene Wert ist, werden nachfolgende Protokolle in neuen Dateien aufgezeichnet. |
|
Anwendbare Szenarien:
| Redo-Protokoll eignet sich für die Absturzwiederherstellung (absturzsicher) |
binlog Geeignet für Master-Slave-Replikation und Datenwiederherstellung |
|
Dies lässt sich am Unterschied zwischen Binlog und Redo-Log erkennen: Das Binlog-Log wird nur zur Archivierung verwendet, und wenn man sich nur auf Binlog verlässt, sind die Funktionen nicht absturzsicher. Aber nur das Redo-Protokoll funktioniert nicht, da das Redo-Protokoll nur für InnoDB gilt und die Datensätze im Protokoll nach dem Schreiben auf die Festplatte überschrieben werden. Daher müssen Binlog und Redo-Log gleichzeitig aufgezeichnet werden, um sicherzustellen, dass die Daten nicht verloren gehen, wenn die Datenbank heruntergefahren und neu gestartet wird.
Zweistufige Übermittlung
Das Obige stellt Redolog und Binlog kurz vor. Beim Ändern von Daten werden diese Änderungen gespeichert, aber eines ist ein physisches Protokoll und das andere ist ein logisches Protokoll. Wie haben sie den Änderungsprozess durchgeführt?
Angenommen, es gibt eine Update-Anweisung, die jetzt ausgeführt werden soll, aktualisieren Sie von table_name set c=c+1 where id=2, der Ausführungsprozess ist wie folgt:
- Suchen Sie zuerst den Datensatz id=2
- Der Executor erhält Addieren Sie 1 zu diesem Wert, um eine neue Datenzeile zu erhalten, und rufen Sie dann die Engine-Schnittstelle auf, um diese neue Datenzeile zu schreiben.
- Die Engine aktualisiert diese neue Datenzeile im Speicher und zeichnet sie auf Aktualisierungsvorgang in Redolog, zu diesem Zeitpunkt befindet sich Redolog im Vorbereitungszustand. Dann wird der Executor darüber informiert, dass die Ausführung abgeschlossen ist und die Transaktion jederzeit übermittelt werden kann.
- Der Executor generiert das Binlog dieser Operation und schreibt das Binlog auf die Festplatte Die Engine ändert das gerade geschriebene Redo-Log in den Commit-Status und die Aktualisierung ist abgeschlossen.
- Das schematische Diagramm sieht wie folgt aus:
Dieser Prozess der Aufteilung des Redolog-Schreibens in zwei Schritte: Vorbereiten und Commit. Phaseneinreichung. 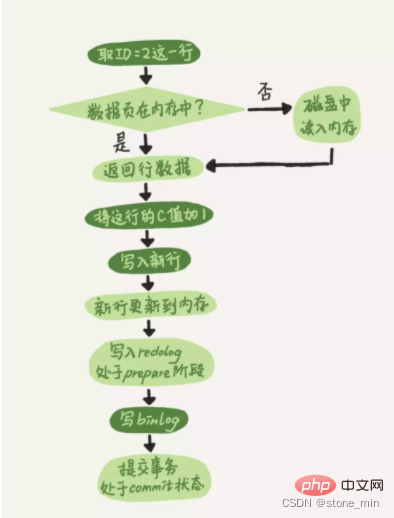
Sowohl Redolog als auch Binlog können verwendet werden, um den Commit-Status einer Transaktion darzustellen, und das zweiphasige Commit dient dazu, die beiden Zustände logisch konsistent zu halten. Wenn Sie kein zweiphasiges Commit verwenden, sondern zuerst das eine und dann das andere schreiben, kann es zu Problemen kommen.
Zu diesem Zeitpunkt wird das Update noch als Beispiel verwendet. Gehen Sie davon aus, dass die aktuelle ID = 2 ist und ein Feld c = 0 vorhanden ist. Analysieren Sie jeweils die folgenden Situationen:
Schreiben Sie zuerst Redolog und dann Binlog. Nehmen Sie an, dass Redolog zuerst geschrieben wird, Binlog jedoch noch nicht. MySQL wird eine plötzliche Ausnahme verursachen, die einen Neustart verursacht. Da das Redolog bereits geschrieben wurde, sind die geänderten Datensätze auch nach dem Neustart des Systems noch vorhanden, sodass der Wert von c in dieser Zeile nach der Wiederherstellung 1 ist. Aufgrund des Systemneustarts ist dieser Eintrag jedoch nicht im Binlog vorhanden. Bei einer späteren Sicherung des Protokolls ist diese Aussage im gespeicherten Binlog nicht vorhanden. Dann werden Sie feststellen, dass, wenn Sie dieses Binlog zum Wiederherstellen der temporären Bibliothek verwenden müssen, die temporäre Bibliothek dieses Mal nicht aktualisiert wird, da das Binlog dieser Anweisung verloren geht. Der Wert von c in der wiederhergestellten Zeile ist 0 derselbe wie der Wert der Originalbibliothek.
Schreiben Sie zuerst Binlog und dann Redolog.
Wenn Sie beim Schreiben von Redolog zuerst Binlog schreiben und dann das System neu starten. Nach dem Neustart gibt es im Redolog keine Aufzeichnungen über die Änderung von c, und der Wert von c ist zu diesem Zeitpunkt immer noch 0. Aber das Protokoll „Change c from 0 to 1“ wurde im Binlog aufgezeichnet. Wenn daher später Binlog zum Wiederherstellen verwendet wird, wird eine weitere Transaktion ausgegeben. Der Wert von c in der wiederhergestellten Zeile ist 1, was sich vom Wert in der ursprünglichen Datenbank unterscheidet.
Zusammenfassend lässt sich also sagen, dass, wenn Sie zuerst ein bestimmtes Protokoll schreiben und dann ein weiteres Protokoll schreiben, der Status der Datenbank nicht mit dem Status der mithilfe von binlog wiederhergestellten Bibliothek übereinstimmt.
3. Rückgängig-Protokoll
Undolog wird hauptsächlich zum Aufzeichnen des Status vor der Änderung eines bestimmten Zeilendatensatzes und zum Aufzeichnen der Daten vor der Änderung verwendet. In diesem Fall können die Datensätze beim Zurücksetzen der Transaktion durch Undolog auf den Zustand wiederhergestellt werden, in dem sie vor Beginn der Transaktion waren. Auch die Atomizität und Dauerhaftigkeit von Transaktionen werden durch Undolog erreicht. Das Rückgängig-Protokoll zeichnet hauptsächlich die logischen Änderungen der Daten auf. Beispielsweise entspricht eine INSERT-Anweisung einem DELETE-Rückgängig-Protokoll. Für jede UPDATE-Anweisung entspricht sie einem entgegengesetzten UPDATE-Rückgängig-Protokoll, sodass sie bei Auftreten eines Fehlers rückgängig gemacht werden kann zurück zum Datenstand vor der Transaktion. Gleichzeitig wird es bei der Datenwiederherstellung in Verbindung mit Binlog und Redolog verwendet, um die Richtigkeit der Datenwiederherstellung sicherzustellen.
Der Funktionsprozess von Undolog ist wie folgt:
Schreiben Sie die vorab geänderte Version in das Undo-Protokoll, bevor die Transaktion beginnt; 
Starten Sie die Änderung und speichern Sie die geänderten Daten im Speicher;
- Undolog bleibt bestehen auf die Festplatte;
- Transaktions-Commit; Es ist zu beachten, dass Undolog vor der Datenseite zurück auf die Festplatte geleert werden muss. Wenn bei der Datenwiederherstellung die Undolog-Operation abgeschlossen ist, kann die Transaktion basierend auf der Undolog-Operation zurückgesetzt werden.
Bei einer Transaktion kann das gleiche Datenelement mehrmals geändert werden. Müssen die Datensätze vor jeder Änderung im Undolog aufgezeichnet werden? In diesem Fall ist die Anzahl der Undolog-Protokolle zu groß und Redolog kommt zu diesem Zeitpunkt ins Spiel. Wenn in einer Transaktion derselbe Datensatz geändert wird, zeichnet Undolog nur den ursprünglichen Datensatz auf, bevor die Transaktion beginnt. Wenn dieser Datensatz erneut geändert wird, zeichnet Redolog nachfolgende Änderungen auf. Während der Datenwiederherstellung führt Redolog den Rollforward und Undolog den Rollback durch. Die beiden stimmen sich ab, um die Datenwiederherstellung abzuschließen. Der Prozess ist wie folgt:

Eine weitere Funktion ist die MVCC-Mehrversionskontrollkette.
MySQL MVCC-Implementierungsprinzip
Binlog, Redolog und Undolog sind die drei wichtigsten Protokolle in MySQL Bei der Datenwiederherstellung koordinieren und kooperieren die drei Parteien, um die Richtigkeit der Datenwiederherstellung sicherzustellen.
Empfohlenes Lernen: MySQL-Video-Tutorial
|
Das obige ist der detaillierte Inhalt vonBeherrschen Sie die drei Hauptprotokolle von MySQL vollständig: Binlog, Redo-Log und Undo-Log. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



