


Dieser Artikel vermittelt Ihnen relevantes Wissen über Pufferpools in MySQL, einschließlich Datenseiten, Cache-Seiten-frei verknüpfte Listen, Flush-verknüpfte Listen, LRU-verknüpfte Listenblöcke usw. Ich hoffe, dass er Ihnen hilfreich sein wird.

Durch das vorherige Gespräch wissen wir, dass es sich bei Tabellen, die InnoDB als Speicher-Engine verwenden, unabhängig davon um einen Index handelt, der zum Speichern von Benutzerdaten (einschließlich Clustering) verwendet wird Indizes und Sekundärindizes) oder verschiedene Systemdaten werden im Tablespace in Form von Seiten, dem sogenannten Tablespace, abgelegt >code> ist nichts anderes als die Abstraktion einer oder mehrerer tatsächlicher Dateien im Dateisystem durch InnoDB, was bedeutet, dass unsere Daten immer noch auf der Festplatte gespeichert sind. Aber jeder weiß auch, dass die Geschwindigkeit einer Festplatte so langsam ist wie die einer Schildkröte. Wie kann sie einer CPU würdig sein, die „schnell wie der Wind und so schnell wie Elektrizität“ ist? Wenn die InnoDB-Speicher-Engine die Anfrage des Clients verarbeitet und auf die Daten einer bestimmten Seite zugreifen muss, lädt sie daher alle Daten der gesamten Seite in den Speicher. Selbst wenn wir nur auf einen Datensatz pro Seite zugreifen müssen, müssen zuerst die Daten der gesamten Seite in den Speicher geladen werden. Nachdem Sie die gesamte Seite in den Speicher geladen haben, können Sie einen Lese- und Schreibzugriff durchführen. Nachdem Sie den Lese- und Schreibzugriff abgeschlossen haben, müssen Sie den der Seite entsprechenden Speicherplatz nicht freigeben, sondern ihn zwischenspeichern Auf diese Weise kann der Overhead von Festplatten-IO eingespart werden, wenn in Zukunft erneut auf die Seite zugegriffen werden soll. InnoDB作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以页的形式存放在表空间中的,而所谓的表空间只不过是InnoDB对文件系统上一个或几个实际文件的抽象,也就是说我们的数据说到底还是存储在磁盘上的。但是各位也都知道,磁盘的速度慢的跟乌龟一样,怎么能配得上“快如风,疾如电”的CPU呢?所以InnoDB存储引擎在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个页的一条记录,那也需要先把整个页的数据加载到内存中。将整个页加载到内存中后就可以进行读写访问了,在进行完读写访问之后并不着急把该页对应的内存空间释放掉,而是将其缓存起来,这样将来有请求再次访问该页面时,就可以省去磁盘IO的开销了。
设计InnoDB的大叔为了缓存磁盘中的页,在MySQL服务器启动的时候就向操作系统申请了一片连续的内存,他们给这片内存起了个名,叫做Buffer Pool(中文名是缓冲池)。那它有多大呢?这个其实看我们机器的配置,如果你是土豪,你有512G内存,你分配个几百G作为Buffer Pool也可以啊,当然你要是没那么有钱,设置小点也行呀~ 默认情况下Buffer Pool只有128M大小。当然如果你嫌弃这个128M太大或者太小,可以在启动服务器的时候配置innodb_buffer_pool_size参数的值,它表示Buffer Pool的大小,就像这样:
[server] innodb_buffer_pool_size = 268435456
其中,268435456的单位是字节,也就是我指定Buffer Pool的大小为256M。需要注意的是,Buffer Pool也不能太小,最小值为5M(当小于该值时会自动设置成5M)。
Buffer Pool中默认的缓存页大小和在磁盘上默认的页大小是一样的,都是16KB。为了更好的管理这些在Buffer Pool中的缓存页,设计InnoDB的大叔为每一个缓存页都创建了一些所谓的控制信息,这些控制信息包括该页所属的表空间编号、页号、缓存页在Buffer Pool中的地址、链表节点信息、一些锁信息以及LSN信息(锁和LSN我们之后会具体唠叨,现在可以先忽略),当然还有一些别的控制信息,我们这就不全唠叨一遍了,挑重要的说嘛~
每个缓存页对应的控制信息占用的内存大小是相同的,我们就把每个页对应的控制信息占用的一块内存称为一个控制块吧,控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 后边,所以整个Buffer Pool对应的内存空间看起来就是这样的:
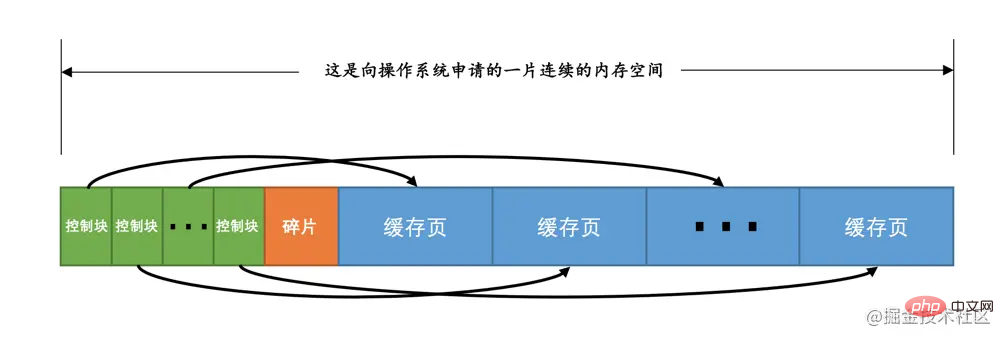
咦?控制块和缓存页之间的那个碎片是个什么玩意儿?你想想啊,每一个控制块都对应一个缓存页,那在分配足够多的控制块和缓存页后,可能剩余的那点儿空间不够一对控制块和缓存页的大小,自然就用不到喽,这个用不到的那点儿内存空间就被称为碎片了。当然,如果你把Buffer Pool的大小设置的刚刚好的话,也可能不会产生碎片
InnoDB entworfen hat, um die Seiten auf der Festplatte zwischenzuspeichern, in MySQLAls der Server startete, beantragte er einen zusammenhängenden Speicherbereich vom Betriebssystem. Sie gaben diesem Speicher einen Namen, genannt Pufferpool (der chinesische Name ist ). Pufferpool >). Wie groß ist es also? Dies hängt tatsächlich von der Konfiguration unserer Maschine ab. Wenn Sie über 512G Speicher verfügen, können Sie natürlich ein paar Hundert G als Pufferpool zuweisen Das gibt es nicht. Wenn Sie Geld haben, können Sie es kleiner einstellen ~ Standardmäßig ist der Pufferpool nur 128M groß. Wenn Ihnen dieser 128M nicht zu groß oder zu klein ist, können Sie natürlich beim Starten des Servers den Wert des Parameters innodb_buffer_pool_size konfigurieren, der den Puffer darstellt Die Größe des Pools lautet wie folgt: 🎜mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.01 sec)
268435456 Bytes, das heißt, ich habe die Größe des Pufferpools angegeben 256M. Es ist zu beachten, dass der Mindestwert 5M nicht zu klein sein darf (wenn er kleiner als dieser Wert ist, wird er automatisch auf 5M gesetzt). ). 🎜Pufferpool ist dieselbe wie die Standard-Seitengröße auf der Festplatte, beide sind 16KB. Um diese Cache-Seiten im Buffer Pool besser verwalten zu können, hat der Onkel, der InnoDB entworfen hat, einige sogenannte Kontrollinformationen für jede Cache-Seite erstellt. Zu diesen Steuerinformationen gehören die Tabellenbereichsnummer, die Seitennummer, die Cache-Seitenadresse im Pufferpool, Knoteninformationen für verknüpfte Listen, einige Sperrinformationen und LSN-Informationen (Sperren und LSN, über die wir später im Detail sprechen werden, Sie können es vorerst ignorieren) und natürlich einige andere Kontrollinformationen, wir werden hier nicht auf alle eingehen, lasst uns die wichtigen auswählen~🎜 🎜 Die Steuerinformationen, die jeder Cache-Seite entsprechen, belegen die gleiche Speichergröße. Nennen wir den Speicher, der von den Steuerinformationen jeder Seite belegt wird, einen Steuerblock. Eine Entsprechung: Sie werden alle im Pufferpool gespeichert, und die Cache-Seite wird im hinteren Teil des Pufferpools gespeichert Pufferpool Es sieht so aus: 🎜 🎜🎜Eh? Was ist das
🎜🎜Eh? Was ist das Fragment zwischen dem Steuerblock und der Cache-Seite? Denken Sie darüber nach, dass jeder Steuerblock einer Cache-Seite entspricht. Nachdem genügend Steuerblöcke und Cache-Seiten zugewiesen wurden, reicht der verbleibende Speicherplatz möglicherweise nicht für ein Paar Steuerblöcke und Cache-Seiten aus Ein kleiner Teil des Speicherplatzes, der nicht verwendet wird, wird Fragmentierung genannt. Wenn Sie die Größe des Pufferpools genau richtig einstellen, werden natürlich möglicherweise keine Fragmente generiert~🎜
Tipps: Jeder Steuerblock belegt ungefähr 5 % der Cache-Seitengröße. In der Version von MySQL 5.7.21 beträgt die Größe jedes Steuerblocks 808 Byte. Die von uns festgelegte innodb_buffer_pool_size berücksichtigt nicht den von diesem Teil des Steuerblocks belegten Speicherplatz. Das heißt, wenn InnoDB vom Betriebssystem kontinuierlichen Speicherplatz für den Pufferpool beantragt, ist dieser kontinuierliche Speicherplatz im Allgemeinen 5 größer der Wert von innodb_buffer_pool_size %about.
Wenn wir den MySQL-Server zum ersten Mal starten, müssen wir den Initialisierungsprozess des Pufferpools abschließen, der zuerst angewendet werden soll Das BetriebssystemPufferpools wird dann in mehrere Paare von Steuerblöcken und Cache-Seiten unterteilt. Derzeit werden jedoch keine echten Festplattenseiten im Pufferpool zwischengespeichert (da sie noch nicht verwendet wurden). Später, während das Programm ausgeführt wird, werden Seiten auf der Festplatte weiterhin in >Pufferpool. Die Frage ist also: Wenn eine Seite von der Festplatte in den Pufferpool gelesen wird, wo soll sie auf der Cache-Seite platziert werden? Oder wie kann man unterscheiden, welche Cache-Seiten im Buffer Pool frei sind und welche verwendet wurden? Wir sollten besser irgendwo aufzeichnen, welche Cache-Seiten im Pufferpool verfügbar sind. Zu diesem Zeitpunkt ist der der Cache-Seite entsprechende Kontrollblock hilfreich. Wir können alle freien Cache-Seiten dem Kontrollblock zuordnen wird als Knoten in einer verknüpften Liste platziert. Diese verknüpfte Liste kann auch als freie verknüpfte Liste (oder freie verknüpfte Liste) bezeichnet werden. Alle gerade initialisierten Cache-Seiten im Pufferpool sind frei, daher wird der jeder Cache-Seite entsprechende Steuerblock zur freien verknüpften Liste hinzugefügt Die Anzahl der Cache-Seiten, die im Code>Pufferpool untergebracht werden können, beträgt n. Der Effekt des Hinzufügens von freier verknüpfter Liste ist wie folgt: MySQL服务器的时候,需要完成对Buffer Pool的初始化过程,就是先向操作系统申请Buffer Pool的内存空间,然后把它划分成若干对控制块和缓存页。但是此时并没有真实的磁盘页被缓存到Buffer Pool中(因为还没有用到),之后随着程序的运行,会不断的有磁盘上的页被缓存到Buffer Pool中。那么问题来了,从磁盘上读取一个页到Buffer Pool中的时候该放到哪个缓存页的位置呢?或者说怎么区分Buffer Pool中哪些缓存页是空闲的,哪些已经被使用了呢?我们最好在某个地方记录一下Buffer Pool中哪些缓存页是可用的,这个时候缓存页对应的控制块就派上大用场了,我们可以把所有空闲的缓存页对应的控制块作为一个节点放到一个链表中,这个链表也可以被称作free链表(或者说空闲链表)。刚刚完成初始化的Buffer Pool中所有的缓存页都是空闲的,所以每一个缓存页对应的控制块都会被加入到free链表中,假设该Buffer Pool中可容纳的缓存页数量为n,那增加了free链表的效果图就是这样的:
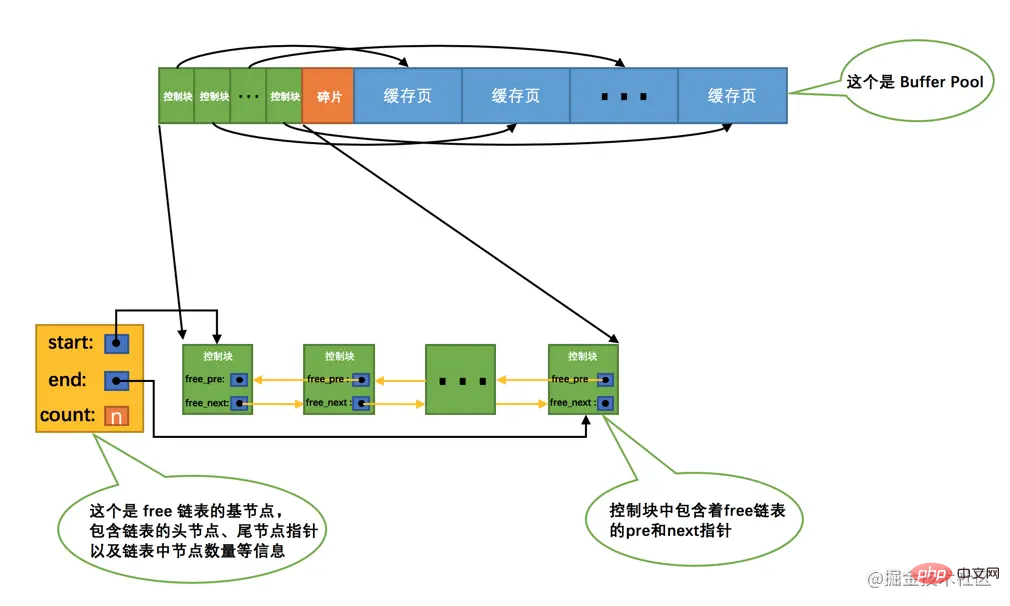
从图中可以看出,我们为了管理好这个free链表,特意为这个链表定义了一个基节点,里边儿包含着链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。这里需要注意的是,链表的基节点占用的内存空间并不包含在为Buffer Pool申请的一大片连续内存空间之内,而是单独申请的一块内存空间。
小贴士: 链表基节点占用的内存空间并不大,在MySQL5.7.21这个版本里,每个基节点只占用40字节大小。后边我们即将介绍许多不同的链表,它们的基节点和free链表的基节点的内存分配方式是一样一样的,都是单独申请的一块40字节大小的内存空间,并不包含在为Buffer Pool申请的一大片连续内存空间之内。
有了这个free链表之后事儿就好办了,每当需要从磁盘中加载一个页到Buffer Pool中时,就从free链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上(就是该页所在的表空间、页号之类的信息),然后把该缓存页对应的free链表节点从链表中移除,表示该缓存页已经被使用了~
我们前边说过,当我们需要访问某个页中的数据时,就会把该页从磁盘加载到Buffer Pool中,如果该页已经在Buffer Pool中的话直接使用就可以了。那么问题也就来了,我们怎么知道该页在不在Buffer Pool中呢?难不成需要依次遍历Buffer Pool中各个缓存页么?一个Buffer Pool中的缓存页这么多都遍历完岂不是要累死?
再回头想想,我们其实是根据表空间号 + 页号来定位一个页的,也就相当于表空间号 + 页号是一个key,缓存页就是对应的value,怎么通过一个key来快速找着一个value呢?哈哈,那肯定是哈希表喽~
小贴士: 啥?你别告诉我你不知道哈希表是个啥?我们这个文章不是讲哈希表的,如果你不会那就去找本数据结构的书看看吧~ 啥?外头的书看不懂?别急,等我~
所以我们可以用表空间号 + 页号作为key,缓存页作为value创建一个哈希表,在需要访问某个页的数据时,先从哈希表中根据表空间号 + 页号看看有没有对应的缓存页,如果有,直接使用该缓存页就好,如果没有,那就从free链表
freien verknüpften Liste speziell einen Basisknoten für diese verknüpfte Liste definiert, der die enthält Kopfknotenadresse der verknüpften Liste, Endknotenadresse und die Anzahl der Knoten in der aktuellen verknüpften Liste sowie andere Informationen. Hierbei ist zu beachten, dass der vom Basisknoten der verknüpften Liste belegte Speicherplatz nicht im großen zusammenhängenden Speicherplatz enthalten ist, der für Pufferpool angewendet wird, sondern ein separater Teil des angewendeten Speicherplatzes ist für. 🎜🎜🎜Tipps: Der vom Basisknoten der verknüpften Liste belegte Speicherplatz ist nicht groß. In der Version von MySQL5.7.21 belegt jeder Basisknoten nur 40 Byte. Wir werden später viele verschiedene verknüpfte Listen vorstellen. Die Speicherzuweisungsmethoden ihrer Basisknoten und der Basisknoten freier verknüpfter Listen sind alle unabhängig für einen 40-Byte-Speicherplatz, der nicht in der Anwendung enthalten ist Pufferpool innerhalb eines großen zusammenhängenden Speicherbereichs. 🎜🎜🎜Mit dieser kostenlosen verknüpften Liste wird es einfacher, wenn Sie eine Seite von der Festplatte in den Pufferpool laden müssen Nehmen Sie eine freie Cache-Seite aus der freien verknüpften Liste und geben Sie die Informationen des Steuerblocks ein, der der Cache-Seite entspricht (d. h. dem Tabellenbereich, in dem sich die Seite befindet, Seite). Nummer usw.) und entfernen Sie dann den Knoten freie verknüpfte Liste, der der Cache-Seite entspricht, aus der verknüpften Liste, um anzuzeigen, dass die Cache-Seite verwendet wurde ~ 🎜🎜🎜Hash-Verarbeitung der Cache-Seite🎜 🎜🎜Wir haben bereits gesagt: Wenn wir auf die Daten auf einer bestimmten Seite zugreifen müssen, laden wir die Seite von der Festplatte in den Pufferpool, wenn sich die Seite bereits im Pufferpool befindet. Code>, verwenden Sie es direkt. Dann stellt sich die Frage: Woher wissen wir, ob sich die Seite im <code>Buffer Pool befindet? Ist es notwendig, jede Cache-Seite im Pufferpool nacheinander zu durchlaufen? Wäre es nicht anstrengend, so viele Cache-Seiten in einem Pufferpool zu durchlaufen? 🎜🎜Rückblickend erkennen wir eine Seite tatsächlich anhand von Tabellenbereichsnummer + Seitennummer, was äquivalent dazu ist, dass Tabellenbereichsnummer + Seitennummer ein Schlüssel, Cache-Seite ist der entsprechende Wert. So finden Sie schnell einen WertSchlüssel. Was ist mit /code>? ? Haha, das muss eine Hash-Tabelle sein~🎜🎜🎜Tipps: Was? Sagen Sie mir nicht, dass Sie nicht wissen, was eine Hash-Tabelle ist? In unserem Artikel geht es nicht um Hash-Tabellen. Wenn Sie nicht wissen, wie es geht, dann suchen Sie sich ein Buch über Datenstrukturen und lesen Sie es ~ Was? Kannst du die Bücher nicht draußen lesen? Keine Sorge, warte auf mich~🎜🎜🎜Wir können also Tabellenbereichsnummer + Seitennummer als Schlüssel und Cache-Seite als verwenden WertErstellen Sie eine Hash-Tabelle. Wenn Sie auf die Daten einer bestimmten Seite zugreifen müssen, prüfen Sie zunächst, ob eine entsprechende Cache-Seite basierend auf Tabellenbereichsnummer + Seitennummer vorhanden ist Wenn ja, verwenden Sie einfach die Cache-Seite. Wenn nicht, wählen Sie eine freie Cache-Seite aus der freien verknüpften Liste aus und laden Sie dann die entsprechende Seite von der Festplatte an den Speicherort des Caches Seite. 🎜Wenn wir die Daten einer Cache-Seite im Pufferpool ändern, ist sie nicht mit der Seite auf der Festplatte konsistent. Eine solche Cache-Seite wird auch Dirty page
dirty page). Am einfachsten ist es natürlich, bei jeder Änderung sofort eine Synchronisierung mit der entsprechenden Seite auf der Festplatte durchzuführen, aber häufiges Schreiben von Daten auf die Festplatte beeinträchtigt die Leistung des Programms erheblich (schließlich ist die Festplatte so langsam wie eine Schildkröte). ). Jedes Mal, wenn wir die Cache-Seite ändern, haben wir es nicht eilig, die Änderung sofort mit der Festplatte zu synchronisieren, sondern sie zu einem bestimmten Zeitpunkt in der Zukunft zu synchronisieren. Wir werden ihn später erklären, also nicht Machen Sie sich jetzt keine Sorgen. Ha~Buffer Pool中某个缓存页的数据,那它就和磁盘上的页不一致了,这样的缓存页也被称为脏页(英文名:dirty page)。当然,最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能(毕竟磁盘慢的像乌龟一样)。所以每次修改缓存页后,我们并不着急立即把修改同步到磁盘上,而是在未来的某个时间点进行同步,至于这个同步的时间点我们后边会作说明说明的,现在先不用管哈~但是如果不立即同步到磁盘的话,那之后再同步的时候我们怎么知道Buffer Pool中哪些页是脏页,哪些页从来没被修改过呢?总不能把所有的缓存页都同步到磁盘上吧,假如Buffer Pool被设置的很大,比方说300G,那一次性同步这么多数据岂不是要慢死!所以,我们不得不再创建一个存储脏页的链表,凡是修改过的缓存页对应的控制块都会作为一个节点加入到一个链表中,因为这个链表节点对应的缓存页都是需要被刷新到磁盘上的,所以也叫flush链表。链表的构造和free链表差不多,假设某个时间点Buffer Pool中的脏页数量为n,那么对应的flush链表就长这样:
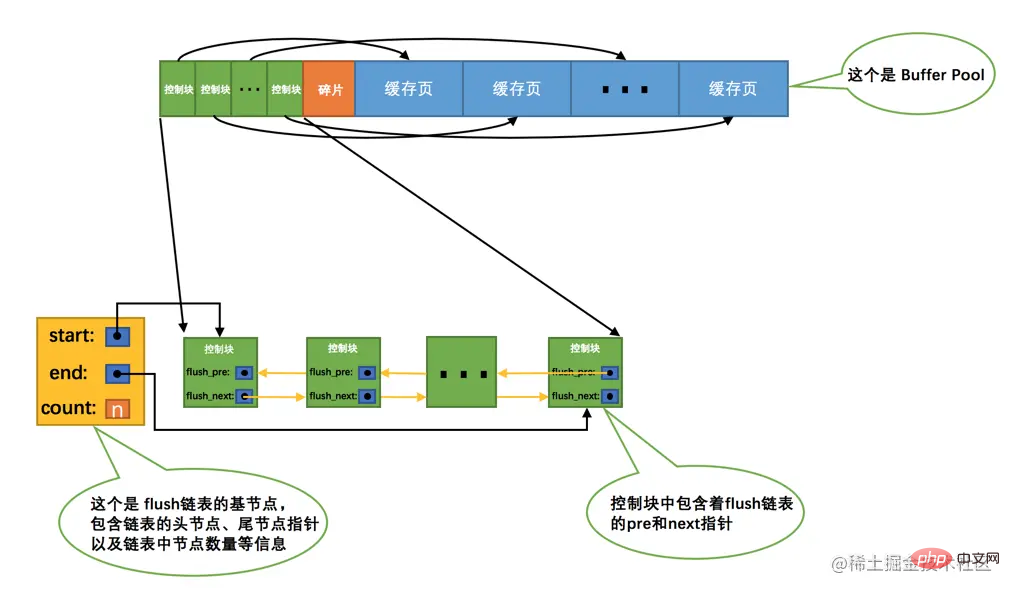
缓存不够的窘境
Buffer Pool对应的内存大小毕竟是有限的,如果需要缓存的页占用的内存大小超过了Buffer Pool大小,也就是free链表中已经没有多余的空闲缓存页的时候岂不是很尴尬,发生了这样的事儿该咋办?当然是把某些旧的缓存页从Buffer Pool中移除,然后再把新的页放进来喽~ 那么问题来了,移除哪些缓存页呢?
为了回答这个问题,我们还需要回到我们设立Buffer Pool的初衷,我们就是想减少和磁盘的IO交互,最好每次在访问某个页的时候它都已经被缓存到Buffer Pool中了。假设我们一共访问了n次页,那么被访问的页已经在缓存中的次数除以n就是所谓的缓存命中率,我们的期望就是让缓存命中率越高越好~ 从这个角度出发,回想一下我们的微信聊天列表,排在前边的都是最近很频繁使用的,排在后边的自然就是最近很少使用的,假如列表能容纳下的联系人有限,你是会把最近很频繁使用的留下还是最近很少使用的留下呢?废话,当然是留下最近很频繁使用的了~
简单的LRU链表
管理Buffer Pool的缓存页其实也是这个道理,当Buffer Pool中不再有空闲的缓存页时,就需要淘汰掉部分最近很少使用的缓存页。不过,我们怎么知道哪些缓存页最近频繁使用,哪些最近很少使用呢?呵呵,神奇的链表再一次派上了用场,我们可以再创建一个链表,由于这个链表是为了按照最近最少使用的原则去淘汰缓存页的,所以这个链表可以被称为LRU链表(LRU的英文全称:Least Recently Used)。当我们需要访问某个页时,可以这样处理LRU链表:
如果该页不在Buffer Pool中,在把该页从磁盘加载到Buffer Pool中的缓存页时,就把该缓存页对应的控制块作为节点塞到链表的头部。
如果该页已经缓存在Buffer Pool中,则直接把该页对应的控制块移动到LRU链表的头部。
也就是说:只要我们使用到某个缓存页,就把该缓存页调整到LRU链表的头部,这样LRU链表尾部就是最近最少使用的缓存页喽~ 所以当Buffer Pool中的空闲缓存页使用完时,到LRU链表的尾部找些缓存页淘汰就OK啦,真简单,啧啧...
划分区域的LRU链表
高兴的太早了,上边的这个简单的LRU链表
Pufferpool ungültige Seiten sind? und welche Seiten wurden noch nie synchronisiert? Wurde es geändert? Sie können nicht alle Cache-Seiten mit der Festplatte synchronisieren, wenn der Pufferpool auf eine große Größe eingestellt ist, z. B. 300G So viele Daten auf einmal? Langsam sterben! Daher müssen wir eine weitere verknüpfte Liste erstellen, um fehlerhafte Seiten zu speichern. Die Steuerblöcke, die den geänderten Cache-Seiten entsprechen, werden als Knoten zu einer verknüpften Liste hinzugefügt, da die Cache-Seiten, die den verknüpften Listenknoten entsprechen, aktualisiert werden müssen disk, daher wird es auch Flush Linked List genannt. Die Struktur der verknüpften Liste ähnelt der der freien verknüpften Liste. Gehen Sie davon aus, dass die Anzahl der fehlerhaften Seiten im Pufferpool zu einem bestimmten Zeitpunkt n beträgt , dann sieht die entsprechende Die bündig verknüpfte Liste folgendermaßen aus: 🎜 🎜🎜Verwaltung verknüpfter LRU-Listen🎜🎜Das Dilemma des unzureichenden Caches🎜🎜Die entsprechende Speichergröße Der
🎜🎜Verwaltung verknüpfter LRU-Listen🎜🎜Das Dilemma des unzureichenden Caches🎜🎜Die entsprechende Speichergröße Der Pufferpool ist schließlich begrenzt. Wenn die von den Seiten, die zwischengespeichert werden müssen, belegte Speichergröße die Größe des Pufferpools überschreitet, ist das nicht der Fall Es gibt keine freien Cache-Seiten mehr in der kostenlosen verknüpften Liste. Was soll ich tun? Natürlich werden einige alte Cache-Seiten aus dem Pufferpool entfernt und dann neue Seiten eingefügt. Die Frage ist also: Welche Cache-Seiten sollten entfernt werden? 🎜🎜Um diese Frage zu beantworten, müssen wir zu der ursprünglichen Absicht zurückkehren, den Pufferpool einzurichten. Wir wollen lediglich die IO-Interaktion mit der Festplatte reduzieren. Am besten greifen Sie jedes Mal auf einen bestimmten Pool zu, wenn er bis zum Erreichen der Seite im Pufferpool zwischengespeichert wurde. Unter der Annahme, dass wir die Seite insgesamt n Mal besucht haben, dann ist die Häufigkeit, mit der sich die besuchte Seite im Cache befand, dividiert durch n der sogenannte Cache-Trefferrate , unsere Erwartung ist es, die Cache-Trefferrate so hoch wie möglich zu machen ~ Denken Sie aus dieser Perspektive an unsere WeChat-Chatliste zurück, diejenigen an der Spitze sind diejenigen, die dies getan haben Wenn die Liste nur eine begrenzte Anzahl von Kontakten aufnehmen kann, behalten Sie die in letzter Zeit häufig verwendeten Kontakte bei die in letzter Zeit selten verwendet wurden? Unsinn, natürlich verlasse ich diejenigen, die in letzter Zeit häufig verwendet wurden Wenn keine freien Cache-Seiten mehr vorhanden sind, müssen einige Cache-Seiten, die in letzter Zeit selten verwendet wurden, entfernt werden. Doch woher wissen wir, welche zwischengespeicherten Seiten in letzter Zeit häufig und welche selten verwendet wurden? Haha, die magische verknüpfte Liste ist wieder praktisch. Da diese verknüpfte Liste dazu verwendet wird, Cache-Seiten nach dem Prinzip der letzten Verwendung zu eliminieren, kann diese verknüpfte Liste aufgerufen werden code>LRU-verknüpfte Liste (der vollständige englische Name von LRU: Least Recent Used). Wenn wir auf eine Seite zugreifen müssen, können wir die LRU-verknüpfte Liste wie folgt verarbeiten: 🎜
Pufferpool befindet, Entfernen Sie die Seite von Wenn die Festplatte in die Cache-Seite im Pufferpool geladen wird, wird der der Cache-Seite entsprechende Steuerblock als a in den Kopf der verknüpften Liste eingefügt Knoten. 🎜Pufferpool zwischengespeichert wurde, verschieben Sie den entsprechenden Kontrollblock der Seite direkt in die LRU-verknüpfte Liste -Header. 🎜
LRU-verknüpften Liste an, sodass LRU-verknüpfte Liste ist die zuletzt verwendete Cache-Seite ~ Wenn also die freien Cache-Seiten im Pufferpool aufgebraucht sind, gehen Sie zum Ende von LRU-Linked Liste, um einige Cache-Seiten zu finden, die entfernt werden müssen. Es ist in Ordnung, es ist wirklich einfach, wow ... 🎜🎜LRU-verknüpfte Liste in Regionen unterteilt🎜🎜Ich bin so glücklich, die obige einfache LRU-verknüpfte Liste code> hat nicht lange gebraucht, um das Problem zu finden, denn es gibt zwei peinliche Situationen: 🎜<ul>
<li>
<p>Situation 1: <code>InnoDB bietet einen scheinbar rücksichtsvollen Service – read ahead (englischer Name: read ahead). Das sogenannte Vorlesen bedeutet, dass InnoDB denkt, dass bestimmte Seiten nach der Ausführung der aktuellen Anfrage gelesen werden könnten, und sie daher in den Pufferpoollädt > im Voraus. Entsprechend den verschiedenen Auslösemethoden kann Vorlesen in die folgenden zwei Typen unterteilt werden: InnoDB提供了一个看起来比较贴心的服务——预读(英文名:read ahead)。所谓预读,就是InnoDB认为执行当前的请求可能之后会读取某些页面,就预先把它们加载到Buffer Pool中。根据触发方式的不同,预读又可以细分为下边两种:
线性预读
设计InnoDB的大叔提供了一个系统变量innodb_read_ahead_threshold,如果顺序访问了某个区(extent)的页面超过这个系统变量的值,就会触发一次异步读取下一个区中全部的页面到Buffer Pool的请求,注意异步读取意味着从磁盘中加载这些被预读的页面并不会影响到当前工作线程的正常执行。这个innodb_read_ahead_threshold系统变量的值默认是56,我们可以在服务器启动时通过启动参数或者服务器运行过程中直接调整该系统变量的值,不过它是一个全局变量,注意使用SET GLOBAL命令来修改哦。
小贴士: InnoDB是怎么实现异步读取的呢?在Windows或者Linux平台上,可能是直接调用操作系统内核提供的AIO接口,在其它类Unix操作系统中,使用了一种模拟AIO接口的方式来实现异步读取,其实就是让别的线程去读取需要预读的页面。如果你读不懂上边这段话,那也就没必要懂了,和我们主题其实没太多关系,你只需要知道异步读取并不会影响到当前工作线程的正常执行就好了。其实这个过程涉及到操作系统如何处理IO以及多线程的问题,找本操作系统的书看看吧,什么?操作系统的书写的都很难懂?没关系,等我~
随机预读
如果Buffer Pool中已经缓存了某个区的13个连续的页面,不论这些页面是不是顺序读取的,都会触发一次异步读取本区中所有其的页面到Buffer Pool的请求。设计InnoDB的大叔同时提供了innodb_random_read_ahead系统变量,它的默认值为OFF,也就意味着InnoDB并不会默认开启随机预读的功能,如果我们想开启该功能,可以通过修改启动参数或者直接使用SET GLOBAL命令把该变量的值设置为ON。
预读本来是个好事儿,如果预读到Buffer Pool中的页成功的被使用到,那就可以极大的提高语句执行的效率。可是如果用不到呢?这些预读的页都会放到LRU链表的头部,但是如果此时Buffer Pool的容量不太大而且很多预读的页面都没有用到的话,这就会导致处在LRU链表尾部的一些缓存页会很快的被淘汰掉,也就是所谓的劣币驱逐良币,会大大降低缓存命中率。
情况二:有的小伙伴可能会写一些需要扫描全表的查询语句(比如没有建立合适的索引或者压根儿没有WHERE子句的查询)。
扫描全表意味着什么?意味着将访问到该表所在的所有页!假设这个表中记录非常多的话,那该表会占用特别多的页,当需要访问这些页时,会把它们统统都加载到Buffer Pool中,这也就意味着吧唧一下,Buffer Pool中的所有页都被换了一次血,其他查询语句在执行时又得执行一次从磁盘加载到Buffer Pool的操作。而这种全表扫描的语句执行的频率也不高,每次执行都要把Buffer Pool中的缓存页换一次血,这严重的影响到其他查询对 Buffer Pool的使用,从而大大降低了缓存命中率。
总结一下上边说的可能降低Buffer Pool的两种情况:
加载到Buffer Pool中的页不一定被用到。
如果非常多的使用频率偏低的页被同时加载到Buffer Pool时,可能会把那些使用频率非常高的页从Buffer Pool中淘汰掉。
因为有这两种情况的存在,所以设计InnoDB的大叔把这个LRU链表按照一定比例分成两截,分别是:
一部分存储使用频率非常高的缓存页,所以这一部分链表也叫做热数据,或者称young区域。
另一部分存储使用频率不是很高的缓存页,所以这一部分链表也叫做冷数据,或者称old区域
InnoDB entworfen hat, stellte a zur Verfügung Systemvariable innodb_read_ahead_threshold, wenn die Seiten, auf die in einem bestimmten Bereich (extent) nacheinander zugegriffen wird, den Wert dieser Systemvariablen überschreiten, erfolgt ein asynchroner Lesevorgang Ausgelöst werden alle Seiten im Bereich zum Pufferpool. Beachten Sie, dass das Laden dieser vorab gelesenen Seiten von der Festplatte keine Auswirkungen auf die normale Ausführung des aktuellen Arbeitsthreads hat . Der Wert dieser Systemvariablen innodb_read_ahead_threshold ist standardmäßig 56. Wir können den Wert dieser Systemvariablen direkt über Startparameter anpassen, wenn der Server startet oder während der Server läuft Es handelt sich um globale Variablen. Bitte verwenden Sie den Befehl SET GLOBAL, um sie zu ändern. 🎜🎜Tipps: Wie implementiert InnoDB asynchrones Lesen? Auf Windows- oder Linux-Plattformen ist es möglicherweise möglich, die vom Betriebssystemkernel bereitgestellte AIO-Schnittstelle direkt aufzurufen. In anderen Unix-ähnlichen Betriebssystemen wird eine Methode zur Simulation der AIO-Schnittstelle verwendet, um asynchrones Lesen zu erreichen um andere Threads lesen zu lassen Holen Sie sich die Seite, die gelesen werden muss, im Voraus. Wenn Sie den obigen Absatz nicht verstehen, besteht keine Notwendigkeit, ihn zu verstehen. Er hat nichts mit unserem Thema zu tun. Sie müssen nur wissen, dass das asynchrone Lesen keinen Einfluss auf die normale Ausführung des aktuellen Arbeitsthreads hat. Tatsächlich geht es bei diesem Prozess darum, wie das Betriebssystem mit E/A- und Multithreading-Problemen umgeht. Suchen Sie ein Buch über das Betriebssystem und lesen Sie es. Ist die Schreibweise des Betriebssystems schwer zu verstehen? Es ist okay, warte auf mich~🎜🎜🎜🎜Zufälliges Vorlesen🎜🎜Wenn 13 aufeinanderfolgende Seiten in einem bestimmten Bereich im
Pufferpool zwischengespeichert wurden, unabhängig davon, ob diese Seiten gelesen werden Sequentiell löst eine asynchrone-Anfrage aus, um alle Seiten in diesem Bereich in den Pufferpool zu lesen. Der Onkel, der InnoDB entworfen hat, hat auch die Systemvariable innodb_random_read_ahead bereitgestellt. Ihr Standardwert ist OFF, was InnoDB bedeutet Die zufällige Vorauslesefunktion ist standardmäßig nicht aktiviert. Wenn wir diese Funktion aktivieren möchten, können wir den Wert dieser Variablen auf ON setzen, indem wir die Startparameter ändern oder direkt den Befehl <code>SET GLOBAL verwenden. Code> Befehl. Code>. 🎜🎜🎜🎜<code>Vorlesen ist ursprünglich eine gute Sache. Wenn die Seiten im Vorlesen-Pufferpool erfolgreich verwendet werden, kann dies die Ausführung von Anweisungen erheblich verbessern. Effizienz. Was aber, wenn es nicht genutzt wird? Diese vorgelesenen Seiten werden an der Spitze der verknüpften LRU-Liste platziert, aber wenn die Kapazität des Pufferpools zu diesem Zeitpunkt nicht zu groß ist und viele vorgelesen werden Wenn keine Seiten verwendet werden, führt dies dazu, dass einige Cache-Seiten am Ende der LRU-verknüpften Liste schnell gelöscht werden, was die sogenannten schlechten Münzen verdrängen gute Münzen, wodurch die Cache-Trefferrate erheblich reduziert wird. 🎜🎜🎜🎜Szenario 2: Einige Freunde schreiben möglicherweise einige Abfrageanweisungen, die die gesamte Tabelle scannen müssen (z. B. Abfragen, die keine geeigneten Indizes erstellen oder überhaupt keine WHERE-Klausel haben). 🎜🎜Was bedeutet es, die gesamte Tabelle zu scannen? Das bedeutet, dass auf alle Seiten zugegriffen wird, auf denen sich die Tabelle befindet! Unter der Annahme, dass diese Tabelle sehr viele Datensätze enthält, wird die Tabelle besonders viele Seiten belegen. Wenn auf diese Seiten zugegriffen werden muss, werden sie alle in den Pufferpool bedeutet dies auch, dass alle Seiten im <code>Buffer Pool einmal ersetzt wurden und andere Abfrageanweisungen dann von der Festplatte in den Buffer Pool geladen werden müssen ausgeführt. Code> Operation. Die Ausführungshäufigkeit dieser Art von vollständigen Tabellenscan-Anweisungen ist nicht hoch. Bei jeder Ausführung muss die Cache-Seite im Pufferpool ersetzt werden. Dies beeinträchtigt die Verwendung anderer Abfragen im Buffer. Die Verwendung von Pool reduziert die Cache-Trefferquote erheblich. 🎜🎜🎜🎜 Fassen Sie die beiden oben genannten Situationen zusammen, die den Pufferpool reduzieren können: 🎜🎜🎜🎜Die in den Pufferpool geladenen Seiten werden möglicherweise nicht unbedingt verwendet. 🎜🎜🎜🎜Wenn viele Seiten mit geringer Nutzungshäufigkeit gleichzeitig in den Pufferpool geladen werden, werden die Seiten mit sehr hoher Nutzungshäufigkeit möglicherweise aus dem Pufferpool entfernt. Code> Eliminieren. 🎜🎜🎜🎜Da diese beiden Situationen existieren, hat der Onkel, der <code>InnoDB entworfen hat, diese LRU-verknüpfte Liste entsprechend einem bestimmten Verhältnis in zwei Teile geteilt, nämlich: 🎜🎜🎜🎜 Ein Teil der Cache-Seite speichert sehr häufig verwendete Cache-Seiten, daher wird dieser Teil der verknüpften Liste auch heiße Daten oder junger Bereich genannt. 🎜🎜🎜🎜Der andere Teil speichert Cache-Seiten, die nicht sehr häufig verwendet werden. Daher wird dieser Teil der verknüpften Liste auch als kalte Daten oder alter Bereich bezeichnet. 🎜🎜🎜🎜Um das Verständnis für alle zu erleichtern, haben wir das schematische Diagramm vereinfacht: Verstehen Sie einfach den Geist: 🎜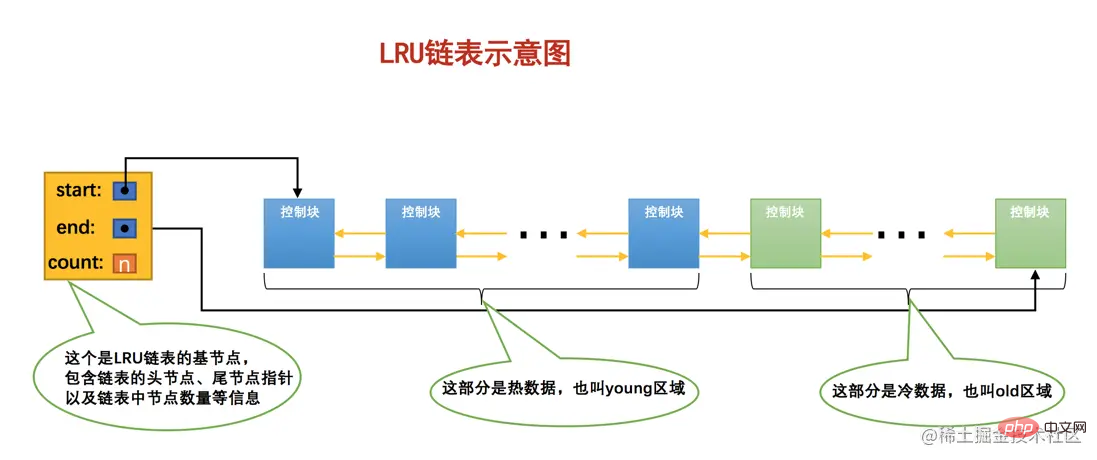
大家要特别注意一个事儿:我们是按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。那这个划分成两截的比例怎么确定呢?对于InnoDB存储引擎来说,我们可以通过查看系统变量innodb_old_blocks_pct的值来确定old区域在LRU链表中所占的比例,比方说这样:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.01 sec)
从结果可以看出来,默认情况下,old区域在LRU链表中所占的比例是37%,也就是说old区域大约占LRU链表的3/8。这个比例我们是可以设置的,我们可以在启动时修改innodb_old_blocks_pct参数来控制old区域在LRU链表中所占的比例,比方说这样修改配置文件:
[server] innodb_old_blocks_pct = 40
这样我们在启动服务器后,old区域占LRU链表的比例就是40%。当然,如果在服务器运行期间,我们也可以修改这个系统变量的值,不过需要注意的是,这个系统变量属于全局变量,一经修改,会对所有客户端生效,所以我们只能这样修改:
SET GLOBAL innodb_old_blocks_pct = 40;
有了这个被划分成young和old区域的LRU链表之后,设计InnoDB的大叔就可以针对我们上边提到的两种可能降低缓存命中率的情况进行优化了:
针对预读的页面可能不进行后续访问情况的优化
设计InnoDB的大叔规定,当磁盘上的某个页面在初次加载到Buffer Pool中的某个缓存页时,该缓存页对应的控制块会被放到old区域的头部。这样针对预读到Buffer Pool却不进行后续访问的页面就会被逐渐从old区域逐出,而不会影响young区域中被使用比较频繁的缓存页。
针对全表扫描时,短时间内访问大量使用频率非常低的页面情况的优化
在进行全表扫描时,虽然首次被加载到Buffer Pool的页被放到了old区域的头部,但是后续会被马上访问到,每次进行访问的时候又会把该页放到young区域的头部,这样仍然会把那些使用频率比较高的页面给顶下去。有同学会想:可不可以在第一次访问该页面时不将其从old区域移动到young区域的头部,后续访问时再将其移动到young区域的头部。回答是:行不通!因为设计InnoDB的大叔规定每次去页面中读取一条记录时,都算是访问一次页面,而一个页面中可能会包含很多条记录,也就是说读取完某个页面的记录就相当于访问了这个页面好多次。
咋办?全表扫描有一个特点,那就是它的执行频率非常低,谁也不会没事儿老在那写全表扫描的语句玩,而且在执行全表扫描的过程中,即使某个页面中有很多条记录,也就是去多次访问这个页面所花费的时间也是非常少的。所以我们只需要规定,在对某个处在old区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。上述的这个间隔时间是由系统变量innodb_old_blocks_time控制的,你看:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | innodb_old_blocks_time | 1000 | +------------------------+-------+ 1 row in set (0.01 sec)
这个innodb_old_blocks_time的默认值是1000,它的单位是毫秒,也就意味着对于从磁盘上被加载到LRU链表的old区域的某个页来说,如果第一次和最后一次访问该页面的时间间隔小于1s(很明显在一次全表扫描的过程中,多次访问一个页面中的时间不会超过1s),那么该页是不会被加入到young区域的~ 当然,像innodb_old_blocks_pct一样,我们也可以在服务器启动或运行时设置innodb_old_blocks_time的值,这里就不赘述了,你自己试试吧~ 这里需要注意的是,如果我们把innodb_old_blocks_time的值设置为0,那么每次我们访问一个页面时就会把该页面放到young区域的头部。
Zusammenfassend lässt sich sagen, dass die verknüpfte Liste LRU in zwei Teile unterteilt ist: die Bereiche jung und alt und hinzugefügt wurde Die Systemvariable innodb_old_blocks_time hat das Problem der verringerten Cache-Trefferrate, die durch den Read-Ahead-Mechanismus und den vollständigen Tabellenscan verursacht wird, eingedämmt, da ungenutzte Pre-Read-Seiten und vollständige Tabellenscan-Seiten nur in old-Bereich, ohne die zwischengespeicherten Seiten im <code>young-Bereich zu beeinträchtigen. LRU链表划分为young和old区域这两个部分,又添加了innodb_old_blocks_time这个系统变量,才使得预读机制和全表扫描造成的缓存命中率降低的问题得到了遏制,因为用不到的预读页面以及全表扫描的页面都只会被放到old区域,而不影响young区域中的缓存页。
更进一步优化LRU链表
LRU链表这就说完了么?没有,早着呢~ 对于young区域的缓存页来说,我们每次访问一个缓存页就要把它移动到LRU链表的头部,这样开销是不是太大啦,毕竟在young区域的缓存页都是热点数据,也就是可能被经常访问的,这样频繁的对LRU链表进行节点移动操作是不是不太好啊?是的,为了解决这个问题其实我们还可以提出一些优化策略,比如只有被访问的缓存页位于young区域的1/4的后边,才会被移动到LRU链表头部,这样就可以降低调整LRU链表的频率,从而提升性能(也就是说如果某个缓存页对应的节点在young区域的1/4中,再次访问该缓存页时也不会将其移动到LRU链表头部)。
小贴士: 我们之前介绍随机预读的时候曾说,如果Buffer Pool中有某个区的13个连续页面就会触发随机预读,这其实是不严谨的(不幸的是MySQL文档就是这么说的[摊手]),其实还要求这13个页面是非常热的页面,所谓的非常热,指的是这些页面在整个young区域的头1/4处。
还有没有什么别的针对LRU链表的优化措施呢?当然有啊,你要是好好学,写篇论文,写本书都不是问题,可是这毕竟是一个介绍MySQL基础知识的文章,再说多了篇幅就受不了了,也影响大家的阅读体验,所以适可而止,想了解更多的优化知识,自己去看源码或者更多关于LRU链表的知识喽~ 但是不论怎么优化,千万别忘了我们的初心:尽量高效的提高 Buffer Pool 的缓存命中率。
为了更好的管理Buffer Pool中的缓存页,除了我们上边提到的一些措施,设计InnoDB的大叔们还引进了其他的一些链表,比如unzip LRU链表用于管理解压页,zip clean链表用于管理没有被解压的压缩页,zip free数组中每一个元素都代表一个链表,它们组成所谓的伙伴系统来为压缩页提供内存空间等等,反正是为了更好的管理这个Buffer Pool引入了各种链表或其他数据结构,具体的使用方式就不啰嗦了,大家有兴趣深究的再去找些更深的书或者直接看源代码吧,也可以直接来找我哈~
小贴士: 我们压根儿没有深入唠叨过InnoDB中的压缩页,对上边的这些链表也只是为了完整性顺便提一下,如果你看不懂千万不要抑郁,因为我压根儿就没打算向大家介绍它们。
后台有专门的线程每隔一段时间负责把脏页刷新到磁盘,这样可以不影响用户线程处理正常的请求。主要有两种刷新路径:
从LRU链表的冷数据中刷新一部分页面到磁盘。
后台线程会定时从LRU链表尾部开始扫描一些页面,扫描的页面数量可以通过系统变量innodb_lru_scan_depth来指定,如果从里边儿发现脏页,会把它们刷新到磁盘。这种刷新页面的方式被称之为BUF_FLUSH_LRU。
从flush链表中刷新一部分页面到磁盘。
后台线程也会定时从flush链表中刷新一部分页面到磁盘,刷新的速率取决于当时系统是不是很繁忙。这种刷新页面的方式被称之为BUF_FLUSH_LIST。
有时候后台线程刷新脏页的进度比较慢,导致用户线程在准备加载一个磁盘页到Buffer Pool时没有可用的缓存页,这时就会尝试看看LRU链表尾部有没有可以直接释放掉的未修改页面,如果没有的话会不得不将LRU链表尾部的一个脏页同步刷新到磁盘(和磁盘交互是很慢的,这会降低处理用户请求的速度)。这种刷新单个页面到磁盘中的刷新方式被称之为BUF_FLUSH_SINGLE_PAGE
LRU-verknüpfte Liste Ist das alles? Nein, es ist früh ~ Bei Cache-Seiten im jungen-Bereich müssen wir sie jedes Mal, wenn wir auf eine Cache-Seite zugreifen, an den Kopf der LRU-verknüpften Liste verschieben Der Overhead ist nicht zu groß. Schließlich handelt es sich bei den zwischengespeicherten Seiten im jungen-Bereich um häufige Zugriffe auf solche häufigen Knotenbewegungsvorgänge auf der LRU list sind notwendig. Ja, um dieses Problem zu lösen, können wir tatsächlich einige Optimierungsstrategien vorschlagen. Beispielsweise wird nur die Cache-Seite aufgerufen, die sich nach 1/4 im Bereich young befindet zwischengespeichert. Verschieben Sie es an den Anfang der LRU-verknüpften Liste, damit die Häufigkeit der Anpassung der LRU-verknüpften Liste verringert und dadurch die Leistung verbessert werden kann (d. h., wenn der Knoten entsprechend einer Cache-Seite befindet sich in In <code>1/4 des jungen-Bereichs wird die Cache-Seite beim erneuten Zugriff nicht an den Kopf des LRU verknüpfte Liste). 🎜🎜Tipps: Als wir zuvor das zufällige Vorlesen eingeführt haben, sagten wir, dass ein zufälliges Vorlesen ausgelöst wird, wenn sich in einem bestimmten Bereich 13 aufeinanderfolgende Seiten befinden. Dies ist (leider) eigentlich nicht streng. Dies ist, was das MySQL-Dokument sagt (zeigen Sie Hände). Tatsächlich müssen diese 13 Seiten sehr heiß sein. Das sogenannte sehr heiße bezieht sich auf diese Seiten, die sich im ersten Viertel des gesamten jungen Bereichs befinden. 🎜🎜Gibt es weitere Optimierungsmaßnahmen für die
LRU-verknüpfte Liste? Natürlich gibt es das. Wenn Sie fleißig lernen, ist es kein Problem, eine Arbeit oder ein Buch zu schreiben. Aber schließlich ist dies ein Artikel, der die Grundkenntnisse von MySQL vermittelt Wenn es zu lang ist, wird es unerträglich sein und das Leseerlebnis aller beeinträchtigen. Wenn Sie also mehr über die Optimierung wissen möchten, gehen Sie selbst zum Quellcode oder erfahren Sie mehr über verknüpfte Listen mit LRU ~ Aber egal, wie wir optimieren, vergessen Sie nicht unsere ursprüngliche Absicht: Versuchen Sie, die Cache-Trefferrate von Buffer Pool so effizient wie möglich zu verbessern. 🎜Buffer Pool besser zu verwalten, entwerfen Sie zusätzlich zu einigen der oben genannten Maßnahmen InnoDB code> Die Onkel führten auch einige andere <code>verknüpfte Listen ein, wie z. B. unzip LRU verknüpfte Liste zum Verwalten dekomprimierter Seiten und Zip clean verknüpfte Liste zum Verwalten Bei entpackten komprimierten Seiten stellt jedes Element im zip free array eine verknüpfte Liste dar. Sie bilden ein sogenanntes Partnersystem, um Speicherplatz für komprimierte Seiten bereitzustellen. usw. Wie auch immer, dies dient der besseren Verwaltung dieses Pufferpools und führt verschiedene verknüpfte Listen oder andere Datenstrukturen ein. Wenn Sie mehr erfahren möchten, können Sie einige finden Weitere ausführliche Bücher oder direkt den Quellcode lesen. Sie können auch direkt zu mir kommen. ~ 🎜 Nur der Vollständigkeit halber erwähnt: Seien Sie nicht deprimiert, wenn Sie sie nicht verstehen, denn ich habe überhaupt nicht die Absicht, sie Ihnen vorzustellen. 🎜LRU-verknüpften Liste auf der Festplatte. 🎜🎜Der Hintergrundthread scannt regelmäßig einige Seiten, beginnend am Ende der LRU-verknüpften Liste. Die Anzahl der gescannten Seiten kann über die Systemvariable innodb_lru_scan_ Depth angegeben werden Wenn darin eine schmutzige Seite gefunden wird, werden sie auf die Festplatte geleert. Diese Methode zum Aktualisieren der Seite heißt BUF_FLUSH_LRU. 🎜verknüpften Liste löschen auf der Festplatte. 🎜🎜Der Hintergrundthread aktualisiert außerdem regelmäßig einige Seiten aus der verknüpften Liste auf der Festplatte. Die Aktualisierungsrate hängt davon ab, ob das System gerade sehr ausgelastet ist. Diese Methode zum Aktualisieren der Seite heißt BUF_FLUSH_LIST. 🎜Pufferpool vorbereitet Es wird versucht festzustellen, ob am Ende der LRU-verknüpften Liste unveränderte Seiten vorhanden sind, die direkt freigegeben werden können. Andernfalls muss eine fehlerhafte Seite am Ende des BUF_FLUSH_SINGLE_PAGE. 🎜当然,有时候系统特别繁忙时,也可能出现用户线程批量的从flush链表中刷新脏页的情况,很显然在处理用户请求过程中去刷新脏页是一种严重降低处理速度的行为(毕竟磁盘的速度慢的要死),这属于一种迫不得已的情况,不过这得放在后边唠叨redo日志的checkpoint时说了。
我们上边说过,Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理啥的,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,独立的吧啦吧啦,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数,比方说这样:
[server] innodb_buffer_pool_instances = 2
这样就表明我们要创建2个Buffer Pool实例,示意图就是这样:
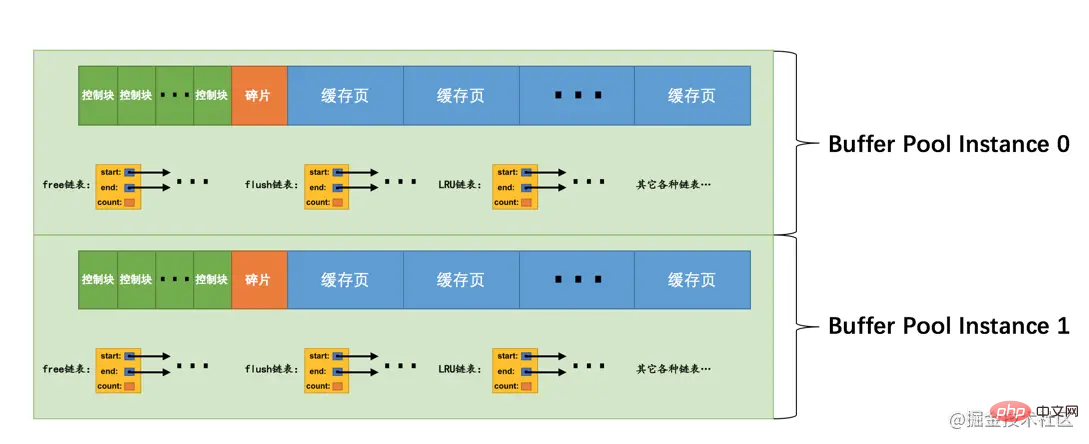
小贴士: 为了简便,我只把各个链表的基节点画出来了,大家应该心里清楚这些链表的节点其实就是每个缓存页对应的控制块!
那每个Buffer Pool实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以实例的个数,结果就是每个Buffer Pool实例占用的大小。
不过也不是说Buffer Pool实例创建的越多越好,分别管理各个Buffer Pool也是需要性能开销的,设计InnoDB的大叔们规定:当innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,InnoDB会默认把innodb_buffer_pool_instances 的值修改为1。而我们鼓励在Buffer Pool大于或等于1G的时候设置多个Buffer Pool实例。
在MySQL 5.7.5之前,Buffer Pool的大小只能在服务器启动时通过配置innodb_buffer_pool_size启动参数来调整大小,在服务器运行过程中是不允许调整该值的。不过设计MySQL的大叔在5.7.5以及之后的版本中支持了在服务器运行过程中调整Buffer Pool大小的功能,但是有一个问题,就是每次当我们要重新调整Buffer Pool大小时,都需要重新向操作系统申请一块连续的内存空间,然后将旧的Buffer Pool中的内容复制到这一块新空间,这是极其耗时的。所以设计MySQL的大叔们决定不再一次性为某个Buffer Pool实例向操作系统申请一大片连续的内存空间,而是以一个所谓的chunk为单位向操作系统申请空间。也就是说一个Buffer Pool实例其实是由若干个chunk组成的,一个chunk就代表一片连续的内存空间,里边儿包含了若干缓存页与其对应的控制块,画个图表示就是这样:
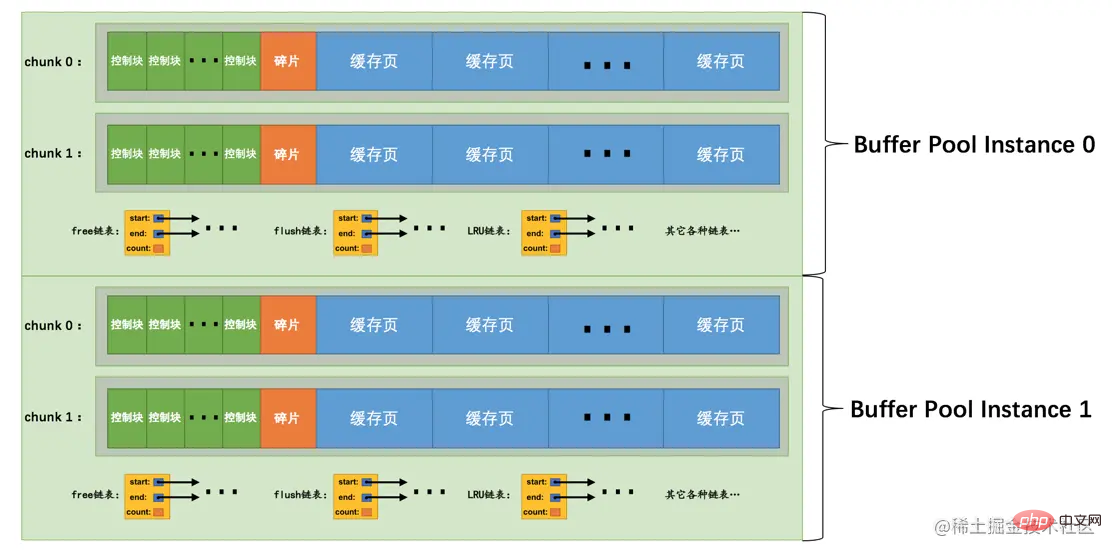
上图代表的Buffer Pool就是由2个实例组成的,每个实例中又包含2个chunk。
正是因为发明了这个chunk的概念,我们在服务器运行期间调整Buffer Pool的大小时就是以chunk为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的chunk的大小是我们在启动操作MySQL服务器时通过innodb_buffer_pool_chunk_size启动参数指定的,它的默认值是134217728,也就是128M。不过需要注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指定,在服务器运行过程中是不可以修改的。
小贴士: 为什么不允许在服务器运行过程中修改innodb_buffer_pool_chunk_size的值?还不是因为innodb_buffer_pool_chunk_size的值代表InnoDB向操作系统申请的一片连续的内存空间的大小,如果你在服务器运行过程中修改了该值,就意味着要重新向操作系统申请连续的内存空间并且将原先的缓存页和它们对应的控制块复制到这个新的内存空间中,这是十分耗时的操作! 另外,这个innodb_buffer_pool_chunk_size的值并不包含缓存页对应的控制块的内存空间大小,所以实际上InnoDB向操作系统申请连续内存空间时,每个chunk的大小要比innodb_buffer_pool_chunk_size的值大一些,约5%。
innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的倍数(这主要是想保证每一个Buffer Pool实例中包含的chunk数量相同)。
假设我们指定的innodb_buffer_pool_chunk_size的值是128M,innodb_buffer_pool_instances的值是16,那么这两个值的乘积就是2G,也就是说innodb_buffer_pool_size的值必须是2G或者2G的整数倍。比方说我们在启动MySQL服务器是这样指定启动参数的:
mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16
默认的innodb_buffer_pool_chunk_size值是128M,指定的innodb_buffer_pool_instances的值是16,所以innodb_buffer_pool_size的值必须是2G或者2G的整数倍,上边例子中指定的innodb_buffer_pool_size的值是8G,符合规定,所以在服务器启动完成之后我们查看一下该变量的值就是我们指定的8G(8589934592字节):
mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 8589934592 | +-------------------------+------------+ 1 row in set (0.00 sec)
如果我们指定的innodb_buffer_pool_size大于2G并且不是2G的整数倍,那么服务器会自动的把innodb_buffer_pool_size的值调整为2G的整数倍,比方说我们在启动服务器时指定的innodb_buffer_pool_size的值是9G:
mysqld --innodb-buffer-pool-size=9G --innodb-buffer-pool-instances=16
那么服务器会自动把innodb_buffer_pool_size的值调整为10G(10737418240字节),不信你看:
mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+-------------+ | Variable_name | Value | +-------------------------+-------------+ | innodb_buffer_pool_size | 10737418240 | +-------------------------+-------------+ 1 row in set (0.01 sec)
如果在服务器启动时,innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的值已经大于innodb_buffer_pool_size的值,那么innodb_buffer_pool_chunk_size的值会被服务器自动设置为innodb_buffer_pool_size/innodb_buffer_pool_instances的值。
比方说我们在启动服务器时指定的innodb_buffer_pool_size的值为2G,innodb_buffer_pool_instances的值为16,innodb_buffer_pool_chunk_size的值为256M:
mysqld --innodb-buffer-pool-size=2G --innodb-buffer-pool-instances=16 --innodb-buffer-pool-chunk-size=256M
由于256M × 16 = 4G,而4G > 2G,所以innodb_buffer_pool_chunk_size值会被服务器改写为innodb_buffer_pool_size/innodb_buffer_pool_instances的值,也就是:2G/16 = 128M(134217728字节),不信你看:
mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 2147483648 | +-------------------------+------------+ 1 row in set (0.01 sec) mysql> show variables like 'innodb_buffer_pool_chunk_size'; +-------------------------------+-----------+ | Variable_name | Value | +-------------------------------+-----------+ | innodb_buffer_pool_chunk_size | 134217728 | +-------------------------------+-----------+ 1 row in set (0.00 sec)
Buffer Pool的缓存页除了用来缓存磁盘上的页面以外,还可以存储锁信息、自适应哈希索引等信息,这些内容等我们之后遇到了再详细讨论哈~
设计MySQL的大叔贴心的给我们提供了SHOW ENGINE INNODB STATUS语句来查看关于InnoDB存储引擎运行过程中的一些状态信息,其中就包括Buffer Pool的一些信息,我们看一下(为了突出重点,我们只把输出中关于Buffer Pool的部分提取了出来):
mysql> SHOW ENGINE INNODB STATUS\G (...省略前边的许多状态) ---------------------- BUFFER POOL AND MEMORY ---------------------- Total memory allocated 13218349056; Dictionary memory allocated 4014231 Buffer pool size 786432 Free buffers 8174 Database pages 710576 Old database pages 262143 Modified db pages 124941 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 6195930012, not young 78247510485 108.18 youngs/s, 226.15 non-youngs/s Pages read 2748866728, created 29217873, written 4845680877 160.77 reads/s, 3.80 creates/s, 190.16 writes/s Buffer pool hit rate 956 / 1000, young-making rate 30 / 1000 not 605 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 710576, unzip_LRU len: 118 I/O sum[134264]:cur[144], unzip sum[16]:cur[0] -------------- (...省略后边的许多状态) mysql>
我们来详细看一下这里边的每个值都代表什么意思:
Total memory allocated:代表Buffer Pool向操作系统申请的连续内存空间大小,包括全部控制块、缓存页、以及碎片的大小。
Dictionary memory allocated:为数据字典信息分配的内存空间大小,注意这个内存空间和Buffer Pool没啥关系,不包括在Total memory allocated中。
Buffer pool size:代表该Buffer Pool可以容纳多少缓存页,注意,单位是页!
Free buffers:代表当前Buffer Pool还有多少空闲缓存页,也就是free链表中还有多少个节点。
Datenbankseiten: stellt die Anzahl der Seiten in der verknüpften Liste LRU dar, einschließlich zweier Bereiche: jung und alt Code> Anzahl der Knoten. <code>Database pages:代表LRU链表中的页的数量,包含young和old两个区域的节点数量。
Old database pages:代表LRU链表old区域的节点数量。
Modified db pages:代表脏页数量,也就是flush链表中节点的数量。
Pending reads:正在等待从磁盘上加载到Buffer Pool中的页面数量。
当准备从磁盘中加载某个页面时,会先为这个页面在Buffer Pool中分配一个缓存页以及它对应的控制块,然后把这个控制块添加到LRU的old区域的头部,但是这个时候真正的磁盘页并没有被加载进来,Pending reads的值会跟着加1。
Pending writes LRU:即将从LRU链表中刷新到磁盘中的页面数量。
Pending writes flush list:即将从flush链表中刷新到磁盘中的页面数量。
Pending writes single page:即将以单个页面的形式刷新到磁盘中的页面数量。
Pages made young:代表LRU链表中曾经从old区域移动到young区域头部的节点数量。
这里需要注意,一个节点每次只有从old区域移动到young区域头部时才会将Pages made young的值加1,也就是说如果该节点本来就在young区域,由于它符合在young区域1/4后边的要求,下一次访问这个页面时也会将它移动到young区域头部,但这个过程并不会导致Pages made young的值加1。
Page made not young:在将innodb_old_blocks_time设置的值大于0时,首次访问或者后续访问某个处在old区域的节点时由于不符合时间间隔的限制而不能将其移动到young区域头部时,Page made not young的值会加1。
这里需要注意,对于处在young区域的节点,如果由于它在young区域的1/4处而导致它没有被移动到young区域头部,这样的访问并不会将Page made not young的值加1。
youngs/s:代表每秒从old区域被移动到young区域头部的节点数量。
non-youngs/s:代表每秒由于不满足时间限制而不能从old区域移动到young区域头部的节点数量。
Pages read、created、written:代表读取,创建,写入了多少页。后边跟着读取、创建、写入的速率。
Buffer pool hit rate:表示在过去某段时间,平均访问1000次页面,有多少次该页面已经被缓存到Buffer Pool了。
young-making rate:表示在过去某段时间,平均访问1000次页面,有多少次访问使页面移动到young区域的头部了。
需要大家注意的一点是,这里统计的将页面移动到young区域的头部次数不仅仅包含从old区域移动到young区域头部的次数,还包括从young区域移动到young区域头部的次数(访问某个young区域的节点,只要该节点在young区域的1/4处往后,就会把它移动到young区域的头部)。
not (young-making rate):表示在过去某段时间,平均访问1000次页面,有多少次访问没有使页面移动到young区域的头部。
需要大家注意的一点是,这里统计的没有将页面移动到young区域的头部次数不仅仅包含因为设置了innodb_old_blocks_time系统变量而导致访问了old区域中的节点但没把它们移动到young区域的次数,还包含因为该节点在young区域的前1/4处而没有被移动到young区域头部的次数。
LRU len:代表LRU链表中节点的数量。
unzip_LRU:代表unzip_LRU链表中节点的数量(由于我们没有具体唠叨过这个链表,现在可以忽略它的值)。
I/O sum:最近50s读取磁盘页的总数。
I/O cur:现在正在读取的磁盘页数量。
I/O unzip sum:最近50s解压的页面数量。
I/O unzip cur
Alte Datenbankseiten: stellt die Anzahl der Knoten im Bereich LRU der verknüpften Liste alt dar. 🎜🎜🎜🎜Geänderte Datenbankseiten: stellt die Anzahl der schmutzigen Seiten dar, also die Anzahl der Knoten in der Flush-Linked-Liste. 🎜🎜🎜🎜Ausstehende Lesevorgänge: Die Anzahl der Seiten, die darauf warten, von der Festplatte in den Pufferpool geladen zu werden. 🎜🎜Wenn Sie das Laden einer Seite von der Festplatte vorbereiten, werden dieser Seite zunächst eine Cache-Seite und der entsprechende Steuerblock im Pufferpool zugewiesen und dann dieser Steuerblock zum -Header hinzugefügt Der <code>alte Bereich von LRU, aber die echte Festplattenseite wurde zu diesem Zeitpunkt noch nicht geladen und der Wert von Ausstehende Lesevorgänge wird um 1 erhöht . 🎜🎜🎜🎜Ausstehende LRU-Schreibvorgänge: Die Anzahl der Seiten, die aus der verknüpften LRU-Liste auf die Festplatte geschrieben werden. 🎜🎜🎜🎜Liste für ausstehende Schreibvorgänge: Die Anzahl der Seiten, die aus der verknüpften Liste flush auf die Festplatte geleert werden. 🎜🎜🎜🎜Ausstehende Schreibvorgänge für eine einzelne Seite: Die Anzahl der Seiten, die als einzelne Seite auf die Festplatte geschrieben werden. 🎜🎜🎜🎜Seiten jung gemacht: Stellt dar, dass die verknüpfte Liste LRU vom Bereich alt an den Kopf von jung verschoben wurde Bereichsanzahl der Knoten. 🎜🎜Hier ist zu beachten, dass ein Knoten nur dann den Wert von Pages made young hat, wenn er vom old-Bereich zum Kopf des young-Bereich. Fügen Sie 1 hinzu, das heißt, wenn der Knoten bereits im <code>young-Bereich liegt, da er die Anforderung erfüllt, hinter 1/4 des young-Bereichs zu liegen >-Bereich, es wird auch beim nächsten Besuch dieser Seite an den Kopf des young-Bereichs verschoben, aber dieser Vorgang führt nicht dazu, dass der Wert von Seiten jung gemacht wird um 1 erhöht werden. 🎜🎜🎜🎜Seite nicht jung gemacht: Wenn der Wert von innodb_old_blocks_time auf größer als 0 gesetzt ist, ist der erste Besuch oder nachfolgende Besuch an einem Standort alt Wenn ein Knoten in einer Region nicht an den Kopf der <code>jungen-Region verschoben werden kann, weil er das Zeitintervalllimit nicht einhält, wird der Wert von Seite nicht jung gemacht wird um 1 erhöht. 🎜🎜Hier ist zu beachten, dass für einen Knoten im Bereich young dieser nicht nach young verschoben wird, weil er bei 1/4 des Bereichs <code>young liegt Bereich Region-Header, ein solcher Zugriff erhöht den Wert von Page made not young nicht um 1. 🎜🎜🎜🎜youngs/s: Stellt die Anzahl der Knoten dar, die pro Sekunde vom Bereich old an den Kopf des Bereichs young verschoben werden. 🎜🎜🎜🎜non-youngs/s: stellt jede Sekunde dar, die nicht aus dem Bereich old an die Spitze des Bereichs young verschoben werden kann, weil Das Zeitlimit wird nicht erreicht. 🎜🎜🎜🎜Gelesene Seiten, erstellt, geschrieben: stellt die Anzahl der gelesenen, erstellten und geschriebenen Seiten dar. Gefolgt von der Geschwindigkeit des Lesens, Schaffens und Schreibens. 🎜🎜🎜🎜Pufferpool-Trefferquote: Gibt an, wie oft die Seite im Pufferpool für durchschnittlich 1.000 Seitenbesuche im vergangenen Zeitraum zwischengespeichert wurde. 🎜🎜🎜🎜Nachwuchsrate: Gibt an, dass die Seite in einem bestimmten Zeitraum in der Vergangenheit durchschnittlich 1.000 Mal besucht wurde und wie viele Besuche die Seite an die Spitze der Seite verschoben haben jung Bereich . 🎜🎜Eine Sache, auf die jeder achten muss, ist, dass die hier gezählte Häufigkeit, mit der die Seite in den jungen-Bereich verschoben wird, nicht nur das Verschieben aus dem alten-Bereich umfasst nach young Die Anzahl der Male an der Spitze der Code>-Region, einschließlich der Häufigkeit, mit der von der <code>young-Region an die Spitze der young verschoben wurde Region (Besuch eines Knotens in einer jungen-Region, solange der Knoten 1/4 hinter dem jungen-Bereich liegt, wird er an den Anfang der -Region verschoben junges Gebiet). 🎜🎜🎜🎜nicht (Nachwuchsrate): Gibt an, dass die Seite in einem bestimmten Zeitraum in der Vergangenheit durchschnittlich 1.000 Mal besucht wurde und wie viele Besuche die Seite nicht verschoben haben an den Bereichsleiter jung. 🎜🎜Eine Sache, auf die jeder achten muss, ist, dass die hier gezählte Anzahl der Header-Zeiten, bei denen die Seite nicht in den young-Bereich verschoben wird, nicht nur Besuche umfasst, die durch das Setzen von innodb_old_blocks_time verursacht wurden -Systemvariable Die Häufigkeit, mit der Knoten im Bereich alt nicht in den Bereich jung verschoben wurden, auch weil sich der Knoten im ersten Viertel von befand der young-Bereich Die Häufigkeit, mit der es an die Spitze des young-Bereichs verschoben wurde. 🎜🎜🎜🎜LRU len: stellt die Anzahl der Knoten in der LRU-verknüpften Liste dar. 🎜🎜🎜🎜unzip_LRU: Stellt die Anzahl der Knoten in der verknüpften Liste unzip_LRU dar (da wir nicht speziell über diese verknüpfte Liste gesprochen haben, kann ihr Wert jetzt ignoriert werden). 🎜🎜🎜🎜E/A-Summe: Die Gesamtzahl der in den letzten 50 Sekunden gelesenen Festplattenseiten. 🎜🎜🎜🎜I/O cur: Die Anzahl der Festplattenseiten, die derzeit gelesen werden. 🎜🎜🎜🎜I/O unzip sum: Die Anzahl der Seiten, die in den letzten 50 Sekunden dekomprimiert wurden. 🎜🎜🎜🎜I/O unzip cur: Die Anzahl der Seiten, die dekomprimiert werden. 🎜
磁盘太慢,用内存作为缓存很有必要。
Buffer Pool本质上是InnoDB向操作系统申请的一段连续的内存空间,可以通过innodb_buffer_pool_size来调整它的大小。
Buffer Pool向操作系统申请的连续内存由控制块和缓存页组成,每个控制块和缓存页都是一一对应的,在填充足够多的控制块和缓存页的组合后,Buffer Pool剩余的空间可能产生不够填充一组控制块和缓存页,这部分空间不能被使用,也被称为碎片。
InnoDB使用了许多链表来管理Buffer Pool。
free链表中每一个节点都代表一个空闲的缓存页,在将磁盘中的页加载到Buffer Pool时,会从free链表中寻找空闲的缓存页。
为了快速定位某个页是否被加载到Buffer Pool,使用表空间号 + 页号作为key,缓存页作为value,建立哈希表。
在Buffer Pool中被修改的页称为脏页,脏页并不是立即刷新,而是被加入到flush链表中,待之后的某个时刻同步到磁盘上。
LRU链表分为young和old两个区域,可以通过innodb_old_blocks_pct来调节old区域所占的比例。首次从磁盘上加载到Buffer Pool的页会被放到old区域的头部,在innodb_old_blocks_time间隔时间内访问该页不会把它移动到young区域头部。在Buffer Pool没有可用的空闲缓存页时,会首先淘汰掉old区域的一些页。
我们可以通过指定innodb_buffer_pool_instances来控制Buffer Pool实例的个数,每个Buffer Pool实例中都有各自独立的链表,互不干扰。
自MySQL 5.7.5版本之后,可以在服务器运行过程中调整Buffer Pool大小。每个Buffer Pool实例由若干个chunk组成,每个chunk的大小可以在服务器启动时通过启动参数调整。
可以用下边的命令查看Buffer Pool的状态信息:
SHOW ENGINE INNODB STATUS\G
推荐学习:mysql视频教程
Das obige ist der detaillierte Inhalt vonVertiefendes Verständnis der MySQL-Prinzipien: Pufferpool (detaillierte Grafik- und Texterklärung). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



