


Dieser Artikel vermittelt Ihnen das relevante Wissen über die Indizierung in MySQL-Datenbanken, das fast alle Wissenspunkte der Indizierung enthält. Ich hoffe, dass es für alle hilfreich ist.

Offizielle Einführung Der Index ist eine Datenstruktur, die MySQL dabei hilft, Daten effizient zu erhalten. Allgemeiner ausgedrückt ist ein Datenbankindex wie das Inhaltsverzeichnis am Anfang eines Buches, das „Datenbankabfragen beschleunigen“ kann.
Im Allgemeinen ist der Index selbst auch sehr groß und es ist unmöglich, ihn vollständig im Speicher zu speichern. Daher werden
Vor- und Nachteile des Index
Sortieren Sie Daten über
Die indizierten Spalten werden automatisch sortiert, einschließlich [Einzelspaltenindex] und [Kombinationsindex], aber die Sortierung des Kombinationsindex ist komplizierter.
Indextyp
Prinzip der Übereinstimmung von Präfixen ganz links (Prinzip der Übereinstimmung ganz links)
folgen. Im Allgemeinen werden kombinierte Indizes anstelle mehrerer einspaltiger Indizes verwendet, wenn die Bedingungen dies zulassen.Indizierte Datenstruktur
Offensichtlich ist dies nicht für die Verwendung als Datenbankindex geeignet, der häufig Suchvorgänge und Bereichssuchen erfordert.
Binärer Suchbaum
Binärer Baum, ich denke, jeder wird ein Bild im Kopf haben.Merkmale von Binärbäumen: Jeder Knoten hat bis zu 2 Gabeln, und die Datenreihenfolge des linken Teilbaums und des rechten Teilbaums ist links kleiner und rechts größer. 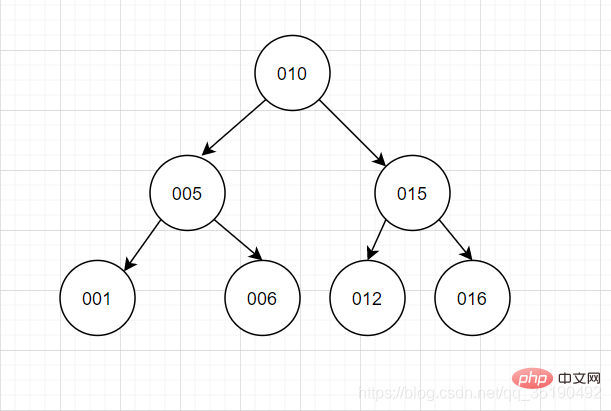
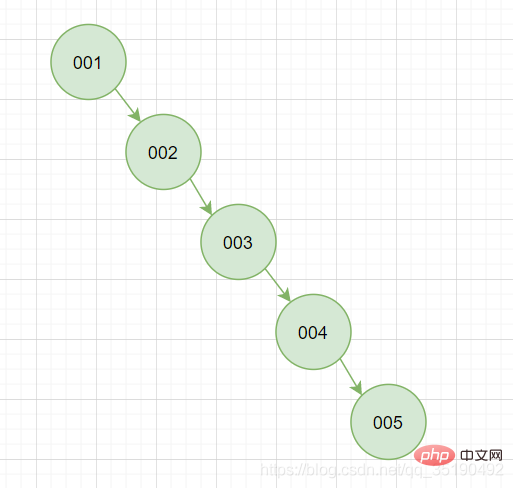 Offensichtlich ist diese Situation instabil und wir werden diese Situation auf jeden Fall im Design vermeiden.
Offensichtlich ist diese Situation instabil und wir werden diese Situation auf jeden Fall im Design vermeiden.
Ausgewogener Binärbaum
Ausgewogener Binärbaum verfügt nicht nur über die Eigenschaften eines Binärbaums, sondern auch über ein dichotomes Denken Das wichtigste Merkmal ist, dass sich die Ebenen des linken und rechten Teilbaums des Baums um höchstens 1 unterscheiden. Beim Einfügen und Löschen von Daten wird die Links-/Rechtsdrehung verwendet, um das Gleichgewicht des Binärbaums aufrechtzuerhalten, sodass der linke Teilbaum nicht sehr hoch und der rechte Teilbaum kurz ist.Die Leistung der Abfrage mithilfe eines ausgeglichenen binären Suchbaums kommt der binären Suchmethode nahe und die Zeitkomplexität beträgt O(log2n). Die Abfrage von id=6 erfordert nur zwei IOs.
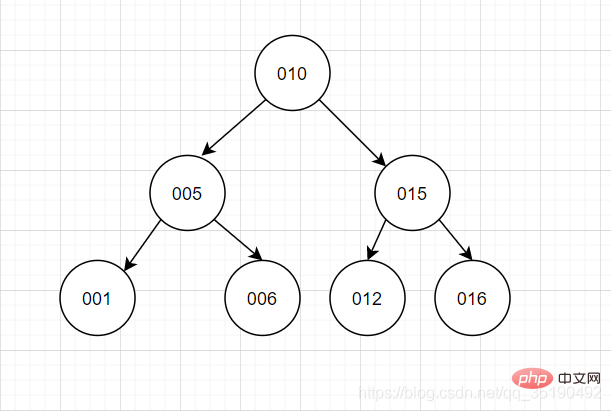
Wenn Sie sich diese Funktion ansehen, denken Sie vielleicht, dass sie sehr gut ist und die ideale Situation eines Binärbaums erreichen kann. Allerdings gibt es immer noch einige Probleme:
Die Zeitkomplexität hängt mit der Baumhöhe zusammen. Wie oft der Baum abgerufen werden muss, hängt davon ab, wie hoch er ist. Der Lesevorgang jedes Knotens entspricht einem Festplatten-E/A-Vorgang. Die Höhe des Baums entspricht der Anzahl der Festplatten-E/A-Vorgänge bei jeder Datenabfrage. Die Suchzeit pro Festplatte beträgt 10 ms. Wenn die Tabellendatenmenge groß ist, ist die Abfrageleistung sehr schlecht. (1 Million Datenvolumen, log2n entspricht ungefähr 20 Festplatten-IO-Zeiten, Zeit 20*10=0,2 s)
Balanced Binary Tree unterstützt keine Bereichsabfrage für eine schnelle Suche. Bereichsabfragen erfordern mehrere Durchläufe vom Wurzelknoten. Abfrageeffizienz Nicht hoch.
MySQL-Daten werden in Festplattendateien gespeichert. Das Laden der Daten von der Festplatte in den Speicher ist sehr zeitaufwändig. Deshalb haben wir optimiert. Der Sinn besteht darin, Festplatten-E/A-Vorgänge zu minimieren. Der Zugriff auf jeden Knoten des Binärbaums führt zu einer E/A. Wenn Sie die E/A-Vorgänge auf der Festplatte reduzieren möchten, müssen Sie die Höhe des Baums so weit wie möglich reduzieren. Wie kann man also die Höhe des Baumes reduzieren?
Wenn der Schlüssel bigint=8 Bytes ist, hat jeder Knoten zwei Zeiger, jeder Zeiger ist 4 Bytes groß und ein Knoten belegt 16 Bytes Platz (8+4*2=16).
Weil die InnoDB-Speicher-Engine von MySQL die Datenmenge einer Seite (Standardseite ist 16 KB) in einem IO liest, während die effektive Datenmenge in einem IO eines Binärbaums nur 16 Byte und die Speicherplatznutzung beträgt ist extrem niedrig. Um die Nutzung eines E/A-Speicherplatzes zu maximieren, besteht eine einfache Idee darin, mehrere Elemente in jedem Knoten zu speichern und so viele Daten wie möglich in jedem Knoten zu speichern. Jeder Knoten kann 1000 Indizes speichern (16k/16=1000), wodurch der Binärbaum in einen Baum mit mehreren Gabeln umgewandelt wird. Durch Erhöhen des Gabelbaums des Baums wird der Baum von hoch und dünn zu kurz und fett geändert. Um 1 Million Daten zu erstellen, benötigt die Höhe des Baums nur 2 Ebenen (1000 * 1000 = 1 Million), was bedeutet, dass zum Abfragen der Daten nur 2 Festplatten-IOs erforderlich sind. Die Anzahl der Festplatten-IOs wird reduziert und die Effizienz der Datenabfrage verbessert.
Wir nennen diese Datenstruktur einen B-Baum. Der B-Baum ist ein ausgeglichener Suchbaum mit mehreren Gabeln, wie unten gezeigt. Die Hauptmerkmale sind wie folgt:
Die Knoten des B-Baums speichern mehrere Elemente und jeder interne Knoten hat mehrere Elemente.
Die Elemente im Knoten enthalten Schlüsselwerte und Daten. Die Schlüsselwerte im Knoten sind von groß nach klein angeordnet. Mit anderen Worten: Daten werden auf allen Knoten gespeichert.
Elemente im übergeordneten Knoten werden nicht in den untergeordneten Knoten angezeigt.
Alle Blattknoten befinden sich auf derselben Ebene, die Blattknoten haben die gleiche Tiefe und es gibt keine Zeigerverbindungen zwischen Blattknoten.
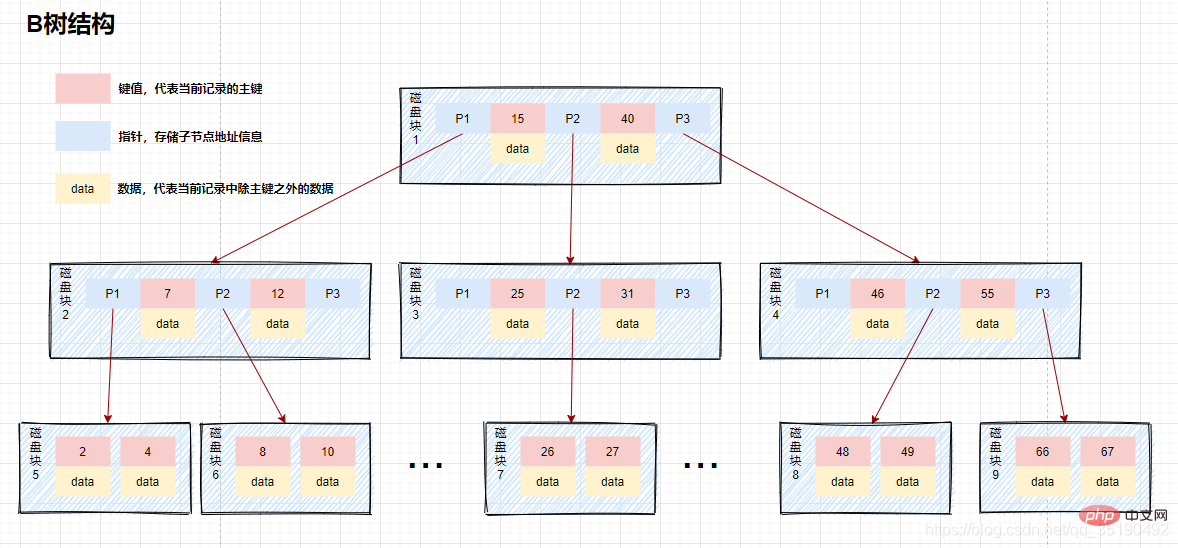
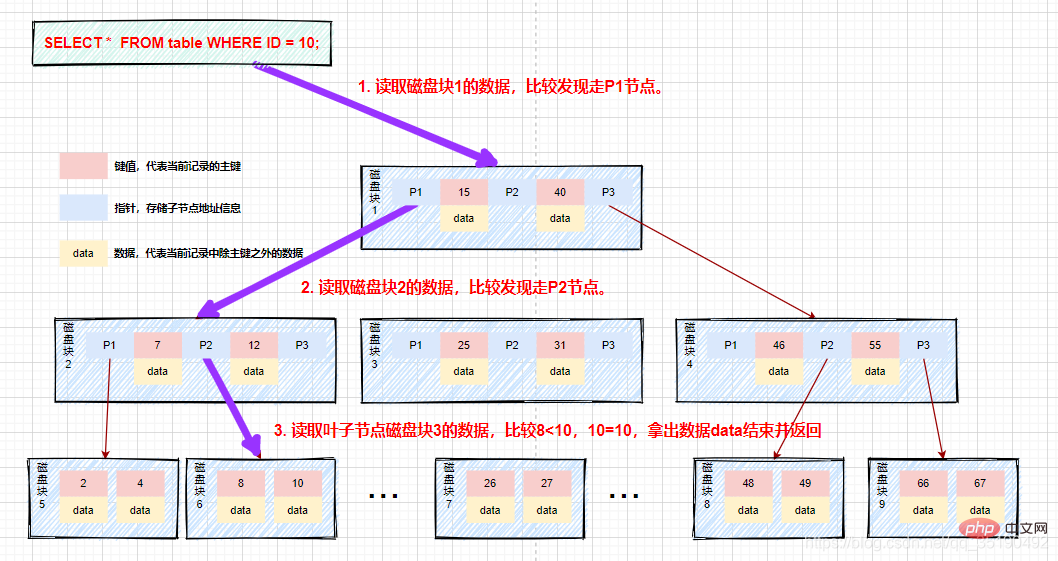
Zum Beispiel beim Abfragen von Daten in einem B-Baum:
Angenommen, wir fragen Daten mit einem Wert gleich 10 ab. Abfragepfad Festplattenblock 1-> Festplattenblock 2-> Festplattenblock 5.
Erste Festplatten-E/A: Laden Sie Festplattenblock 1 in den Speicher, durchlaufen Sie den Speicher und vergleichen Sie ihn von Anfang an, 10
Zweite Festplatten-E/A: Laden Sie Festplattenblock 2 in den Speicher, durchlaufen Sie den Speicher und vergleichen Sie ihn von Anfang an, 7
Die dritte Festplatten-E/A: Laden Sie Festplattenblock 5 in den Speicher, durchlaufen und vergleichen Sie den Speicher von Anfang an, 10 = 10, finden Sie 10, nehmen Sie die Daten heraus. Wenn der in den Daten gespeicherte Zeilendatensatz herausgenommen wird, wird der Abfrage endet. Wenn die Festplattenadresse gespeichert ist, müssen die Daten entsprechend der Festplattenadresse von der Festplatte abgerufen werden, und die Abfrage wird beendet.
Im Vergleich zum binär ausgeglichenen Suchbaum wird während des gesamten Suchvorgangs die Anzahl der Datenvergleiche zwar nicht wesentlich reduziert, die Anzahl der Festplatten-E/As jedoch erheblich. Da unser Vergleich gleichzeitig im Speicher durchgeführt wird, ist die Vergleichszeit vernachlässigbar. Die Höhe des B-Baums beträgt im Allgemeinen 2 bis 3 Schichten, was den meisten Anwendungsszenarien gerecht wird. Daher kann die Verwendung des B-Baums zum Erstellen eines Index die Abfrageeffizienz erheblich verbessern.
Der Prozess ist wie im Bild dargestellt:
Wenn Sie das sehen, müssen Sie denken, dass B-Baum ideal ist, aber Senioren werden Ihnen sagen, dass es noch Orte gibt, die optimiert werden können:
B-Tree unterstützt die Geschwindigkeit der Bereichsabfrage nicht. Wenn wir nach Daten zwischen 10 und 35 suchen möchten, müssen wir zum Stammknoten zurückkehren und die Suche erneut durchführen muss mehrmals vom Stammknoten aus durchlaufen werden, und die Abfrageeffizienz muss verbessert werden.
Wenn Daten Zeilendatensätze speichern, nimmt die Größe der Zeilen mit zunehmender Anzahl der Spalten zu und der belegte Platz nimmt zu. Zu diesem Zeitpunkt nimmt die Datenmenge ab, die auf einer Seite gespeichert werden kann, der Baum wird größer und die Anzahl der Festplatten-E/As nimmt zu.
B+-Baum, als aktualisierte Version des B-Baums, basierend auf dem B-Baum, transformiert MySQL weiterhin basierend auf dem B-Baum und verwendet den B+-Baum zum Erstellen von Indizes. Der Hauptunterschied zwischen einem B+-Baum und einem B-Baum besteht in der Frage, ob Nicht-Blattknoten Daten speichern
- B-Baum: Sowohl Nicht-Blattknoten als auch Blattknoten speichern Daten.
- B+-Baum: Nur Blattknoten speichern Daten und Nicht-Blattknoten speichern Schlüsselwerte. Blattknoten werden mithilfe bidirektionaler Zeiger verbunden, und die untersten Blattknoten bilden eine bidirektional geordnete verknüpfte Liste.
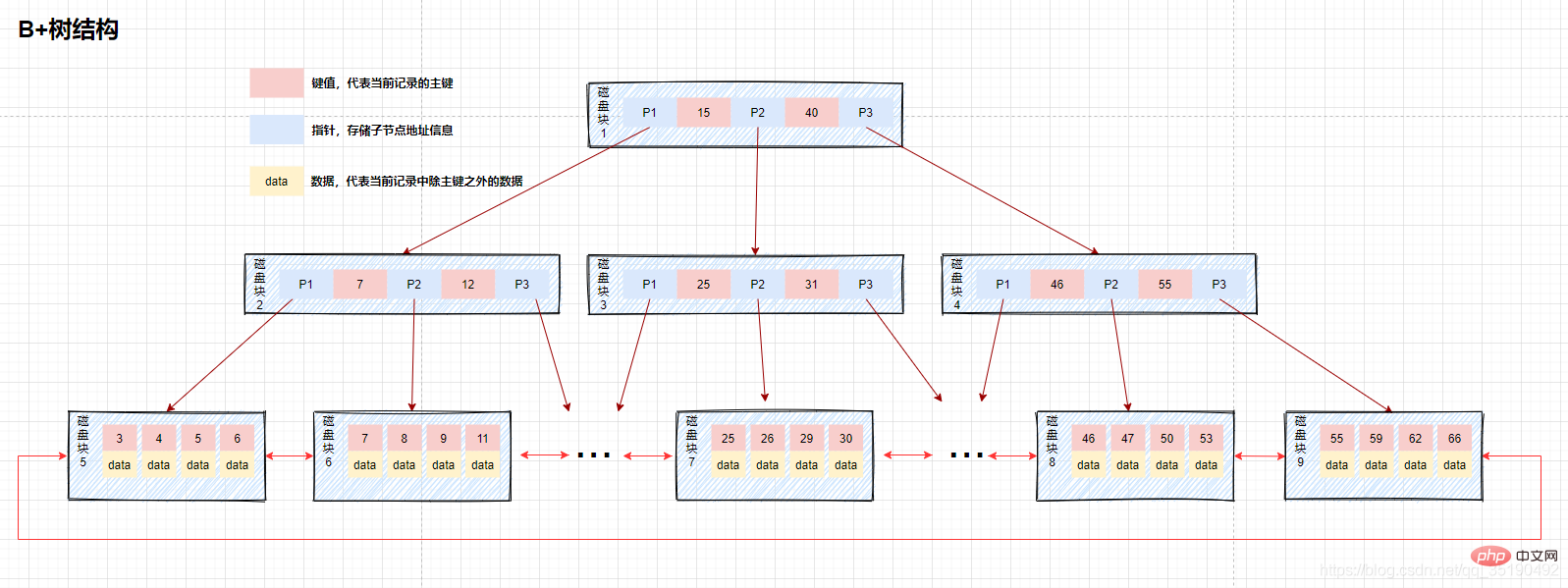
Der unterste Blattknoten des B+-Baums enthält alle Indexelemente. Aus der Abbildung ist ersichtlich, dass bei der Suche nach Daten im B+-Baum die Daten auf den Blattknoten unten gespeichert werden und bei jeder Suche die Blattknoten abgerufen werden müssen, um die Daten abzufragen. Wenn Daten abgefragt werden müssen, hängt die Höhe jedes Festplatten-E/A direkt von der Höhe des Baums ab. Da die Daten jedoch in Blattknoten platziert werden, ist die Anzahl der im Festplattenblock gespeicherten Indizes gesperrt Es wird damit zunehmen, sodass die Höhe des B+-Baums im Vergleich zum B-Baum theoretisch kürzer ist als die des B-Baums. Es gibt auch Fälle, in denen der Index die Abfrage abdeckt. In diesem Fall müssen Sie nur den Index finden, der sofort zurückgegeben werden soll, ohne den untersten Blattknoten abzurufen.
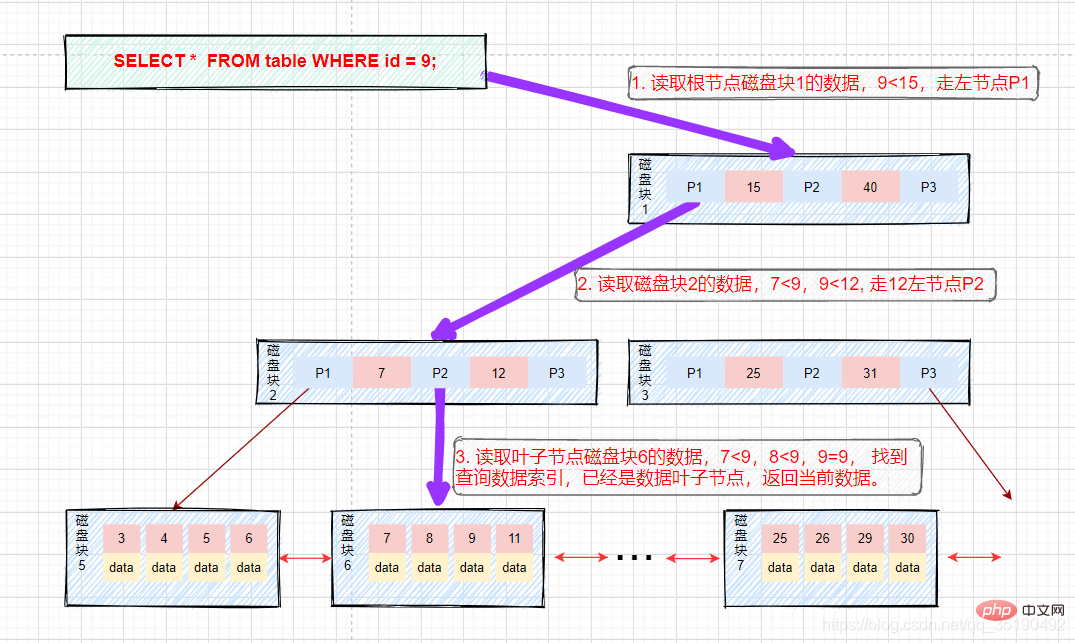
Zum Beispiel:
Bereichsabfrage:
- Äquivalente Abfrage:
Angenommen, wir fragen Daten mit einem Wert gleich 9 ab. Abfragepfad Festplattenblock 1-> Festplattenblock 2-> Festplattenblock 6.
Erste Festplatten-E/A: Laden Sie Festplattenblock 1 in den Speicher, durchlaufen Sie den Speicher und vergleichen Sie ihn von Anfang an, 9
Zweite Festplatten-E/A: Laden Sie Festplattenblock 2 in den Speicher, durchlaufen und vergleichen Sie den Speicher von Anfang an, 7
Die dritte Festplatten-E/A: Laden Sie Festplattenblock 6 in den Speicher, durchqueren und vergleichen Sie den Speicher von Anfang an, suchen Sie 9 im dritten Index, nehmen Sie die Daten heraus, wenn der in den Daten gespeicherte Zeilendatensatz herausgenommen wird, Die Abfrage endet. Wenn die Festplattenadresse gespeichert ist, müssen die Daten entsprechend der Festplattenadresse von der Festplatte abgerufen werden, und die Abfrage wird beendet. (Was hier unterschieden werden muss, ist, dass Data in InnoDB Zeilendaten speichert, während MyIsam Festplattenadressen speichert.) Der Prozess ist wie in der Abbildung dargestellt:
- Angenommen, wir Ich möchte Daten zwischen 9 und 26 finden. Der Suchpfad ist Plattenblock 1->Plattenblock 2->Plattenblock 6->Plattenblock 7.
Suchen Sie zunächst die Daten mit einem Wert gleich 9 und speichern Sie die Daten mit einem Wert gleich 9 im Ergebnissatz. Dieser Schritt ist derselbe wie der vorherige entsprechende Abfrageprozess und es finden drei Festplatten-E/As statt.
Nachdem wir 15 gefunden haben, ist der zugrunde liegende Blattknoten eine geordnete Liste. Wir beginnen mit Festplattenblock 6 und Schlüsselwert 9 und gehen zurück, um alle Daten zu filtern, die die Filterbedingungen erfüllen.
Vierter Platten-E/A: Adressieren und lokalisieren Sie Plattenblock 7 gemäß dem Nachfolgezeiger von Platte 6, laden Sie Platte 7 in den Speicher, durchlaufen und vergleichen Sie den Speicher von Anfang an, 9
Der Primärschlüssel ist eindeutig (es werden später keine
Sie sehen, dass der B+-Baum eine schnelle Suche nach Gleichheits- und Bereichsabfragen gewährleisten kann. Der MySQL-Index verwendet die B+-Baum-Datenstruktur.
MySQL-IndeximplementierungNach der Einführung der Indexdatenstruktur muss diese in MySQL eingebracht werden, um das tatsächliche Nutzungsszenario zu sehen. Daher finden Sie hier eine Analyse der Indeximplementierung der beiden Speicher-Engines von MySQL:
MyISAM-IndexMyIsam-IndexNehmen Sie als Beispiel eine einfache Benutzertabelle. Es gibt zwei Indizes in der Benutzertabelle, die ID-Spalte ist der Primärschlüsselindex und die Altersspalte ist der gewöhnliche Index
CREATE TABLE `user`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = MyISAM AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
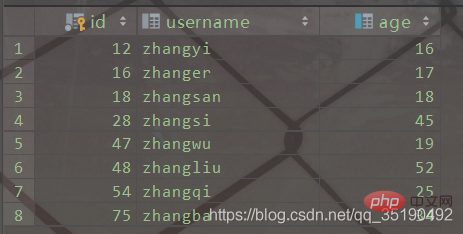 Primärschlüsselindex
Primärschlüsselindex
. 
user.MYI中,数据文件存储在数据文件 user.MYD
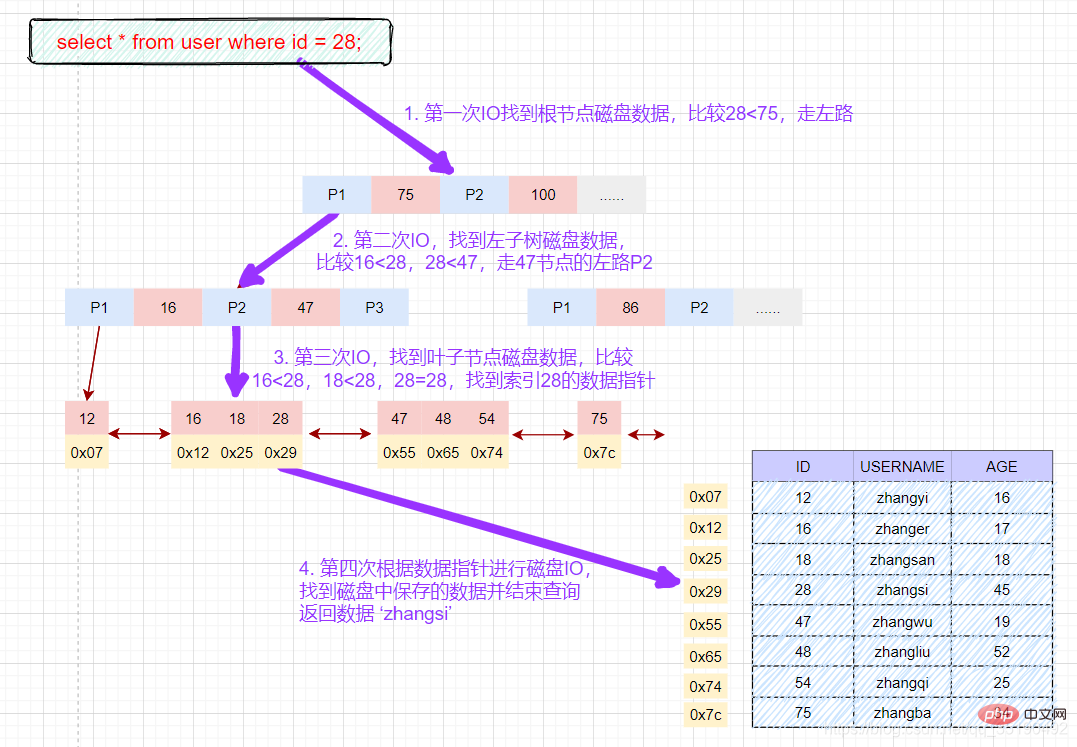
select * from user where id = 28;
磁盘IO次数:3次索引检索+记录数据检索。
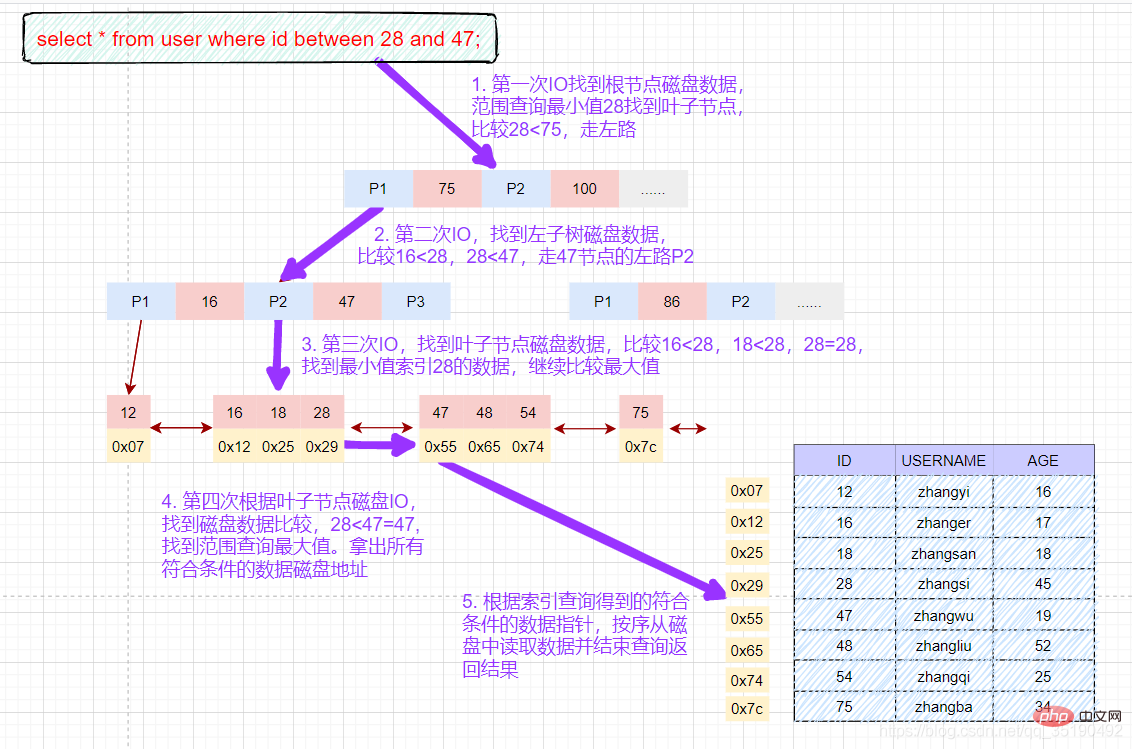
根据主键范围查询数据:
select * from user where id between 28 and 47;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28
将左子树节点加载到内存中,比较16
检索到叶节点,将节点加载到内存中遍历比较16
根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
我们的查询语句时范围查找,需要向后遍历底层叶子链表,直至到达最后一个不满足筛选条件。
向后遍历底层叶子链表,将下一个节点加载到内存中,遍历比较,28
最后得到两条符合筛选条件,将查询结果集返给客户端。
磁盘IO次数:4次索引检索+记录数据检索。
**备注:**以上分析仅供参考,MyISAM在查询时,会将索引节点缓存在MySQL缓存中,而数据缓存依赖于操作系统自身的缓存,所以并不是每次都是走的磁盘,这里只是为了分析索引的使用过程。
在 MyISAM 中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点的数据存储的都是行记录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。
查询数据时,由于辅助索引的键值不唯一,可能存在多个拥有相同的记录,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据。
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下:
- 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值都。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。
CREATE TABLE `user_innodb`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = InnoDB;
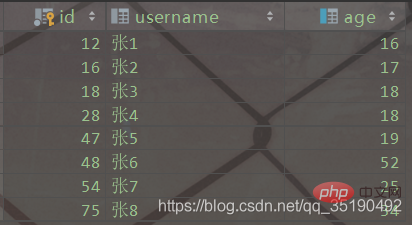
InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
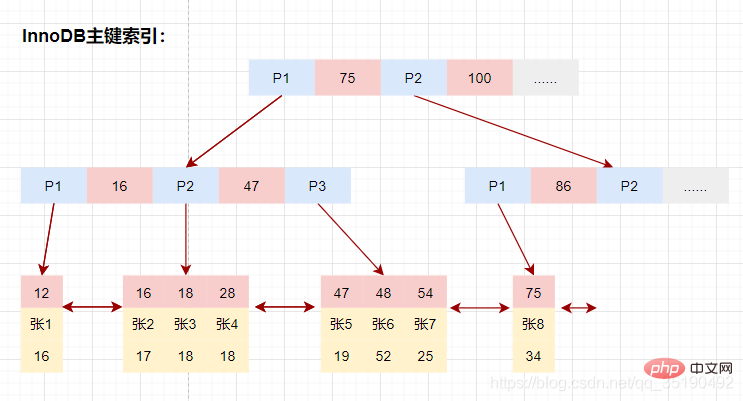
等值查询数据:
select * from user_innodb where id = 28;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28
将左子树节点加载到内存中,比较16
检索到叶节点,将节点加载到内存中遍历,比较16
磁盘IO数量:3次。
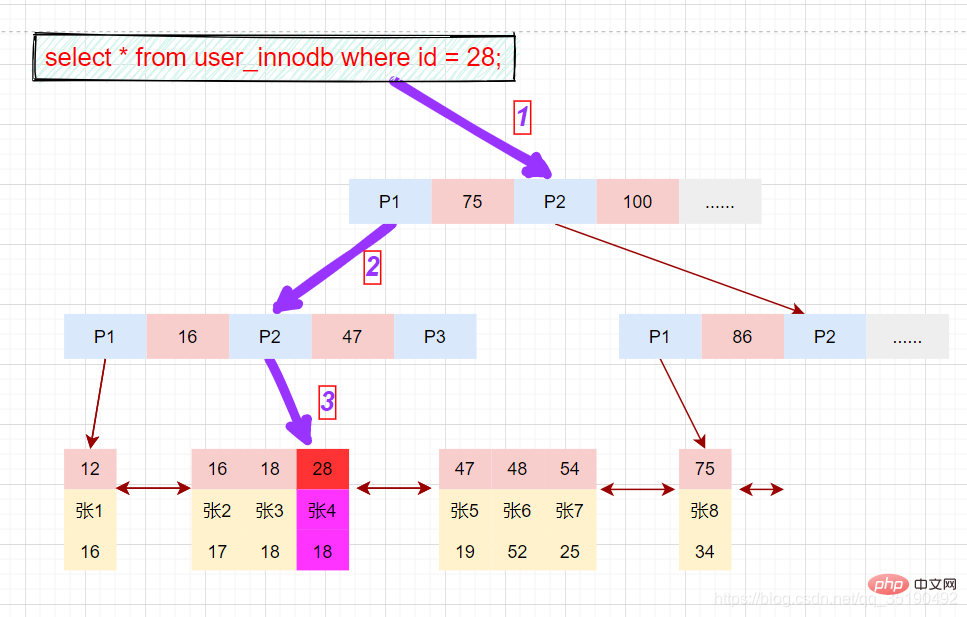
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。
以表user_innodb的age列为例,age索引的索引结果如下图。
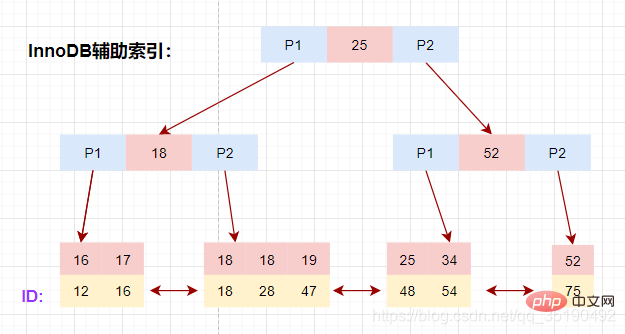
底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。
画图分析等值查询的情况:
select * from t_user_innodb where age=19;
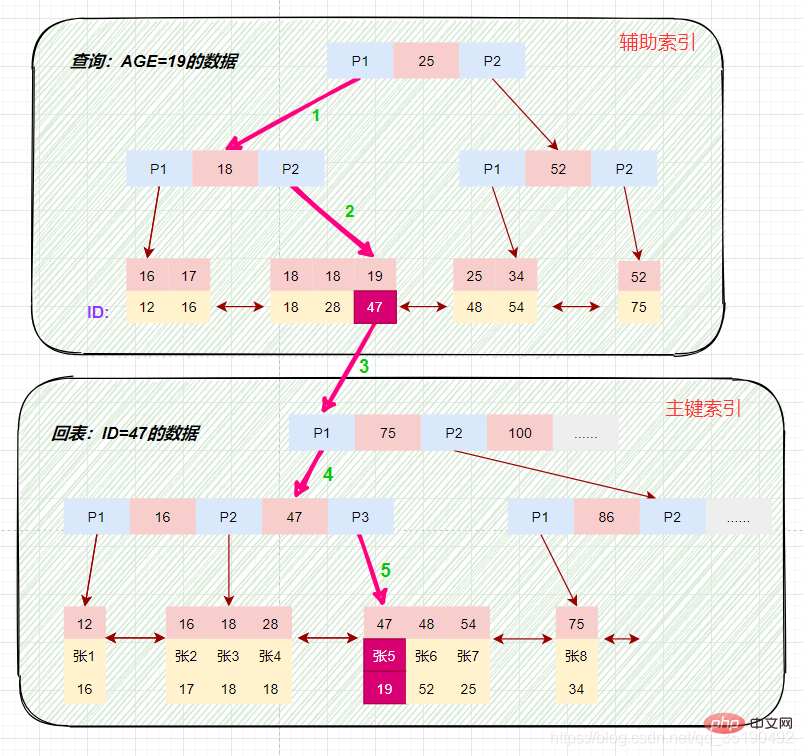
根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
磁盘IO数:辅助索引3次+获取记录回表3次
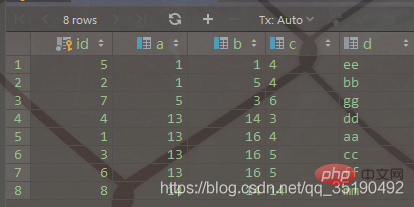
还是以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。
CREATE TABLE `abc_innodb`( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` varchar(10) DEFAULT NULL, `d` varchar(10) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_abc` (`a`, `b`, `c`)) ENGINE = InnoDB;
select * from abc_innodb order by a, b, c, id;
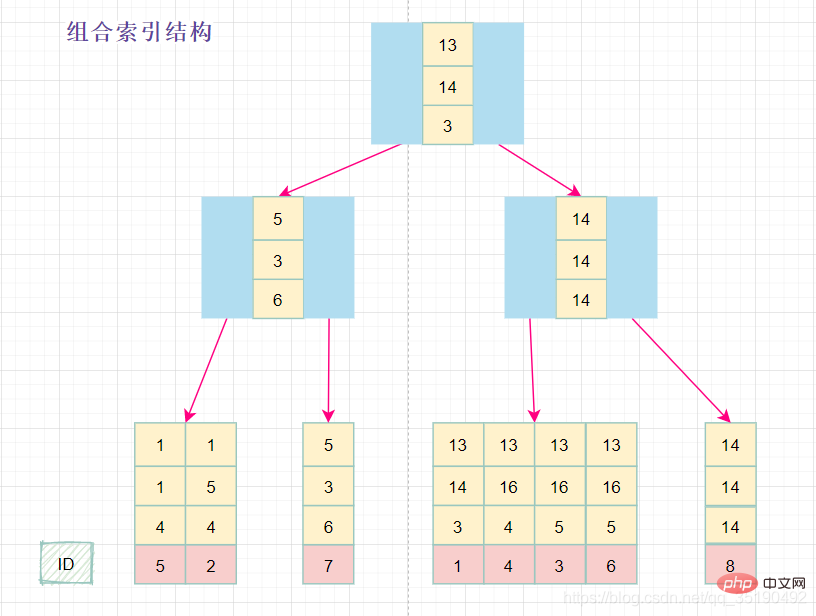
组合索引的数据结构:
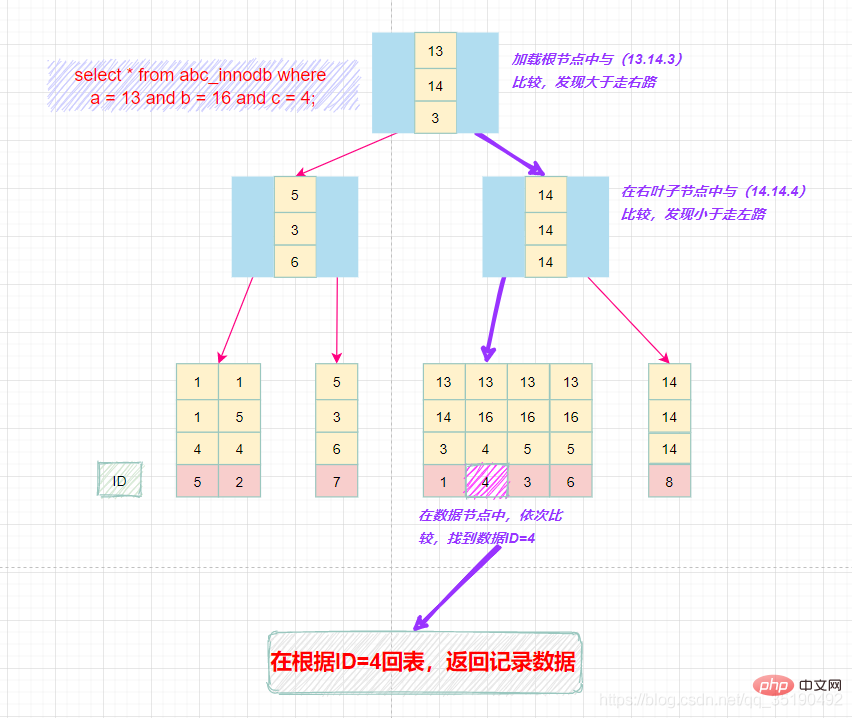
组合索引的查询过程:
select * from abc_innodb where a = 13 and b = 16 and c = 4;
最左匹配原则:
最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。、
组合索引的最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
可以看一下执行计划:
覆盖索引的情况:

未使用到覆盖索引:

看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。比如:
在InnoDB的存储引擎中,使用辅助索引查询的时候,因为辅助索引叶子节点保存的数据不是当前记录的数据而是当前记录的主键索引,索引如果需要获取当前记录完整数据就必然需要根据主键值从主键索引继续查询。这个过程我们成位回表。想想回表必然是会消耗性能影响性能。那如何避免呢?
使用索引覆盖,举个例子:现有User表(id(PK),name(key),sex,address,hobby…)
Wenn in einem Szenario select id,name,sex from user where name ='zhangsan';Diese Anweisung wird häufig in Unternehmen verwendet, und andere Felder der Benutzertabelle werden viel seltener verwendet. In diesem Fall erstellen wir den Index des Namensfelds, anstatt einen einzelnen Index zu verwenden , aber verwenden Sie den gemeinsamen Index (Name, Geschlecht). Wenn Sie in diesem Fall diese Abfrageanweisung erneut ausführen, können Sie die vollständigen Daten der aktuellen Anweisung basierend auf den Ergebnissen der Hilfsindexabfrage erhalten. Dadurch kann effektiv vermieden werden, zum Tisch zurückzukehren, um Geschlechtsdaten zu erhalten.
Hier ist eine typische Optimierungsstrategie, die den Covering-Index verwendet, um die Tabellenrückseite zu reduzieren.
gemeinsamer IndexVersuchen Sie beim Erstellen eines Index zu beurteilen, ob ein gemeinsamer Index für mehrere einspaltige Indizes verwendet werden kann. Die Verwendung gemeinsamer Indizes spart nicht nur Platz, sondern erleichtert auch die Nutzung der Indexabdeckung. Stellen Sie sich vor: Je mehr Felder indiziert sind, desto einfacher ist es, die von der Abfrage zurückgegebenen Daten zu erfüllen. Der gemeinsame Index (a_b_c) entspricht beispielsweise drei Indizes: a, a_b, a_b_c. Spart dies natürlich nicht das Dreifache des Platzbedarfs der drei Indizes (a, a_b, a_b_c). Denn die Daten im Indexbaum haben sich nicht geändert, die Daten im Indexdatenfeld werden jedoch tatsächlich gespeichert.
Das Prinzip der Erstellung eines gemeinsamen Indexes: Bei der Erstellung eines gemeinsamen Indexes sollten häufig verwendete Spalten und Spalten mit hoher Unterscheidungskraft im Vordergrund stehen, und hohe Unterscheidungskraft bedeutet große Filtergranularität Alle Optimierungsszenarien, die beim Erstellen eines Index berücksichtigt werden müssen. Sie können dem gemeinsamen Index auch Felder hinzufügen, die häufig als Abfragen zurückgegeben werden. Wenn Sie einen abdeckenden Index verwenden, empfehle ich diese Situation. Verwenden Sie unten den gemeinsamen Index.
Verwendung von gemeinsamen Indizes
MySQL-Video-Tutorial】
Das obige ist der detaillierte Inhalt vonVerstehen Sie alle Wissenspunkte des MySQL-Index in einem Artikel (empfohlen zum Sammeln).. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



