


In JavaScript bezieht sich Hash auf eine Hash-Tabelle, bei der es sich um eine Datenstruktur handelt, die basierend auf Schlüsselwörtern direkt auf den Speicherort zugreift. Über die Hash-Tabelle wird eine bestimmte Beziehung zwischen dem Speicherort des Datenelements und dem Schlüsselwort hergestellt Das Datenelement ist eine entsprechende Beziehung und die Funktion, die diese entsprechende Beziehung herstellt, wird als Hash-Funktion bezeichnet.

Die Betriebsumgebung dieses Tutorials: Windows 7-System, JavaScript-Version 1.8.5, Dell G3-Computer.
Grundkonzept von Javascript-Hash:
Hash-Tabelle (Hash-Tabelle) ist eine Datenstruktur, die anhand von Schlüsselwörtern, dem Speicherort der Datenelemente und dem Speicherort direkt auf den Speicherort zugreift der Datenelemente Es wird eine bestimmte Entsprechung zwischen Schlüsselwörtern hergestellt, und die Funktion, die diese Entsprechung herstellt, wird Hash-Funktion genannt. 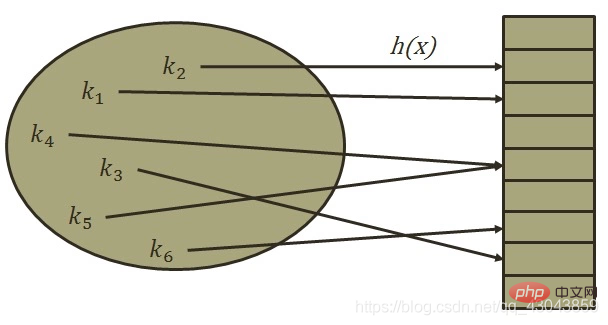
So erstellen Sie eine Hash-Tabelle:
Nehmen Sie an, dass die Anzahl der zu speichernden Datenelemente n beträgt, legen Sie eine kontinuierliche Speichereinheit mit einer Länge von m (m > n) fest und verwenden Sie für jedes das Schlüsselwort Ki ( Datenelement) 0
Aus mathematischer Sicht handelt es sich bei der Hash-Funktion tatsächlich um eine Zuordnung von Schlüsselwörtern zu Speichereinheiten. Daher hoffen wir, dass die von der Hash-Funktion berechnete Huaxi-Adresse durch eine möglichst einfache Operation einem Ort zugeordnet werden kann In einer Reihe von Speichereinheiten gibt es drei Schlüsselpunkte beim Aufbau einer Hash-Funktion: (1) Der Operationsprozess sollte so einfach und effizient wie möglich sein, um die Einfügungs- und Abrufeffizienz der Hash-Tabelle zu verbessern Die Funktion sollte einen guten Hash-Typ haben. Um die Wahrscheinlichkeit einer Hash-Kollision zu verringern, sollte die Hash-Funktion drittens eine stärkere Komprimierung aufweisen, um Speicher zu sparen.
Häufig verwendete Methoden:
1) Offene Adressierungsmethode
Hi=(H(key) + di) MOD m i=1,2,…k(k Wobei H(key) der Hash ist Funktion; m ist die Länge der Hash-Tabelle; di ist eine inkrementelle Sequenz. Es gibt 3 inkrementelle Sequenzen:
①Lineare Erkennung und dann Hashing: di=1,2,3,…,m-1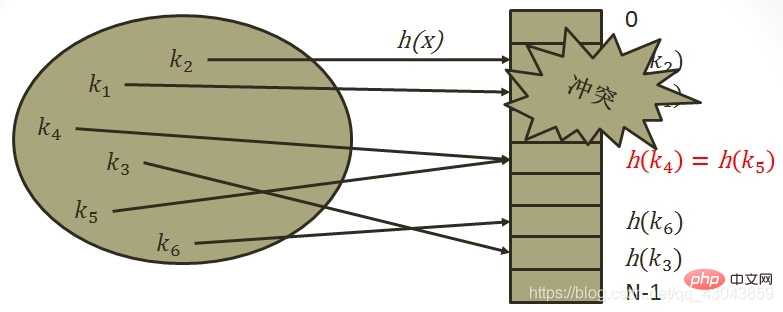 ②Sekundäre Erkennung und dann Hashing: di=1
②Sekundäre Erkennung und dann Hashing: di=1
2,-1
2,-2
2,…±k^2(k ③Pseudozufallserkennung und anschließendes Hashing: di=PseudozufallszahlenfolgeWir können ein Phänomen beobachten: Wenn Datensätze bereits an den Positionen i, i+1 und i+2 in der Tabelle ausgefüllt sind, werden die Datensätze mit den nächsten Hash-Adressen von i, i+1, i+2 und i+ angezeigt 3 sind alle Die Position von i+3 wird ausgefüllt. Dieses Phänomen, bei dem zwei Datensätze mit unterschiedlichen ersten Hash-Adressen um dieselbe nachfolgende Hash-Adresse konkurrieren, das während der Konfliktverarbeitung auftritt, wird als „sekundäre Aggregation“ bezeichnet, d. h. bei der Verarbeitung von Synonymen In Dem Konfliktprozess kommen nicht-synonyme Konflikte hinzu. Andererseits kann durch die Verwendung linearer Erkennung und anschließendes Hashing zur Bewältigung von Konflikten sichergestellt werden, dass immer eine Adresse Hk gefunden werden kann, die keinen Konflikt verursacht, solange die Hash-Tabelle nicht voll ist. Eine sekundäre Erkennung und Wiederaufbereitung ist nur möglich, wenn die Hash-Tabellenlänge m eine Primzahl der Form 4j+3 ist (j ist eine ganze Zahl). Das heißt, die offene Adressierungsmethode führt zu einer sekundären Aggregation, was sich nachteilig auf die Suche auswirkt.
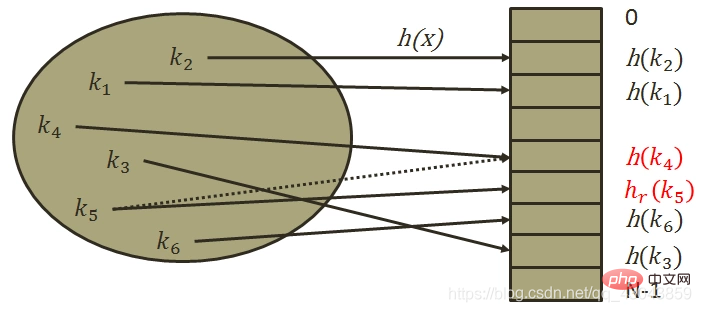
2) Re-Hash-Methode
Hi = RHi (Schlüssel), i=1,2,...k RHi sind alle verschiedene Hash-Funktionen, das heißt, wenn Synonyme Adresskonflikte verursachen, wird die Adresse eines anderen Hashs verwendet Die Funktion wird berechnet, bis keine Konflikte mehr auftreten. Diese Methode ist weniger anfällig für Aggregation, erhöht jedoch die Berechnungszeit.
Nachteile: Erhöhte Berechnungszeit.
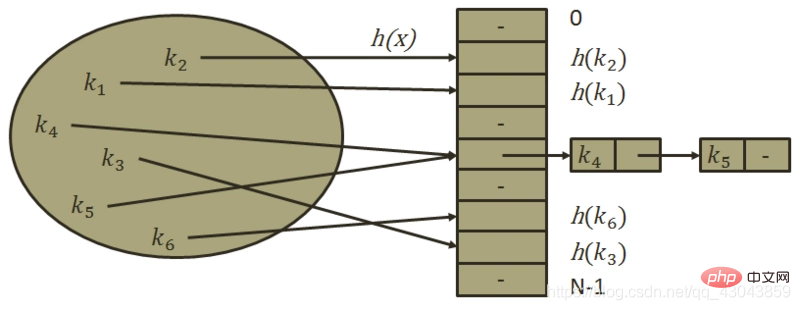
3) Kettenadressmethode (Zipper-Methode)
Speichert alle Datensätze, deren Schlüsselwörter Synonyme sind, in derselben linear verknüpften Liste.
Vorteile:
①Die Zipper-Methode ist einfach mit Konflikten umzugehen und weist kein Akkumulationsphänomen auf, d Die Reißverschlussmethode wird dynamisch angewendet und eignet sich daher besser für Situationen, in denen die Tabellenlänge vor dem Erstellen der Tabelle nicht bestimmt werden kann.
③ Um Konflikte zu reduzieren, erfordert die offene Adressierungsmethode einen kleinen Füllfaktor α Wenn die Größe groß ist, wird viel Platz verschwendet. Bei der Zipper-Methode ist α ≥ 1 akzeptabel, und wenn der Knoten groß ist, ist die in der Zipper-Methode hinzugefügte Zeigerdomäne vernachlässigbar, wodurch Platz gespart wird
④ In einer mit der Zipper-Methode erstellten Hash-Tabelle wird der Vorgang zum Löschen von Knoten ausgeführt ist einfach umzusetzen. Löschen Sie einfach den entsprechenden Knoten in der verknüpften Liste. Bei der mit der offenen Adressmethode erstellten Hash-Tabelle kann beim Löschen eines Knotens der Speicherplatz des gelöschten Knotens nicht einfach leer bleiben, da sonst der Suchpfad des Synonymknotens, der in die Hash-Tabelle eingefügt wird, abgeschnitten wird. Dies liegt daran, dass bei verschiedenen offenen Adressmethoden leere Adresseinheiten (d. h. offene Adressen) Bedingungen für einen Suchfehler sind. Wenn daher ein Löschvorgang für eine Hash-Tabelle ausgeführt wird, der die offene Adressmethode zur Konfliktbehandlung verwendet, kann der gelöschte Knoten nur zum Löschen markiert, der Knoten jedoch nicht tatsächlich gelöscht werden.
class Hash {
constructor() {
this.table = new Array(1024);
}
hash(data) {
//就将字符串中的每个字符的ASCLL码值相加起来,再对数组的长度取余
var total = 0;
for (var i = 0; i < data.length; i++) {
total += data.charCodeAt(i);
}
console.log("Hash Value: " + data + " -> " + total);
return total % this.table.length;
}
insert(key, val) {
var pos = this.hash(key);
this.table[pos] = val;
}
get(key) {
var pos = this.hash(key);
return this.table[pos]
}
show() {
for (var i = 0; i < this.table.length; i++) {
if (this.table[i] != undefined) {
console.log(i + ":" + this.table[i]);
}
}
}
}
var someNames = ["David", "Jennifer", "Donnie", "Raymond", "Cynthia", "Mike", "Clayton", "Danny", "Jonathan"];
var hash = new Hash();
for (var i = 0; i < someNames.length; ++i) {
hash.insert(someNames[i], someNames[i]);
}
hash.show();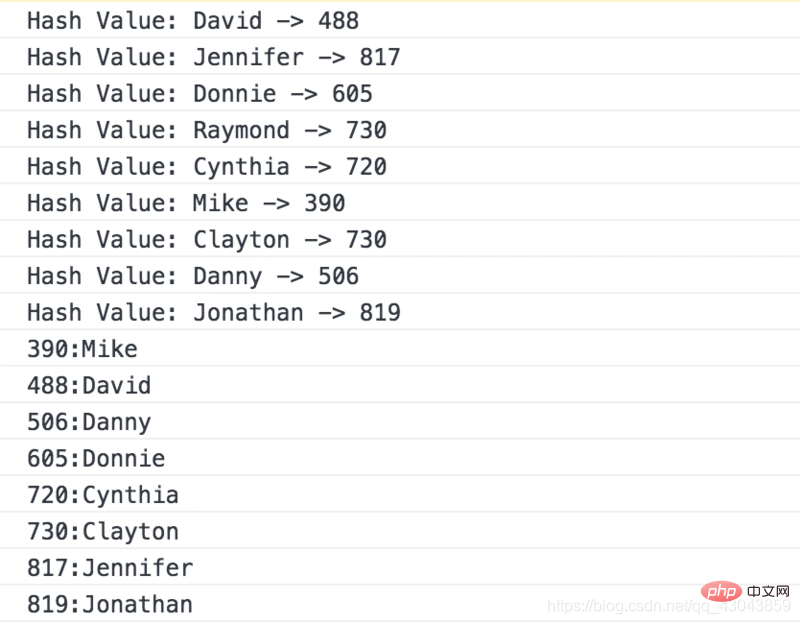 verwendet die quadratische Mid-Step-Methode zum Erstellen der Hash-Funktion und die lineare Erkennungsmethode der offenen Adressmethode zur Lösung von Konflikten.
verwendet die quadratische Mid-Step-Methode zum Erstellen der Hash-Funktion und die lineare Erkennungsmethode der offenen Adressmethode zur Lösung von Konflikten.
class Hash {
constructor() {
this.table = new Array(1000);
}
hash(data) {
var total = 0;
for (var i = 0; i < data.length; i++) {
total += data.charCodeAt(i);
}
//把字符串转化为字符用来求和之后进行平方运算
var s = total * total + ""
//保留中间2位
var index = s.charAt(s.length / 2 - 1) * 10 + s.charAt(s.length / 2) * 1
console.log("Hash Value: " + data + " -> " + index);
return index;
}
solveClash(index, value) {
var table = this.table
//进行线性开放地址法解决冲突
for (var i = 0; index + i < 1000; i++) {
if (table[index + i] == null) {
table[index + i] = value;
break;
}
}
}
insert(key, val) {
var index = this.hash(key);
//把取中当做哈希表中索引
if (this.table[index] == null) {
this.table[index] = val;
} else {
this.solveClash(index, val);
}
}
get(key) {
var pos = this.hash(key);
return this.table[pos]
}
show() {
for (var i = 0; i < this.table.length; i++) {
if (this.table[i] != undefined) {
console.log(i + ":" + this.table[i]);
}
}
}
}
var someNames = ["David", "Jennifer", "Donnie", "Raymond", "Cynthia", "Mike", "Clayton", "Danny", "Jonathan"];
var hash = new Hash();
for (var i = 0; i < someNames.length; ++i) {
hash.insert(someNames[i], someNames[i]);
}
hash.show();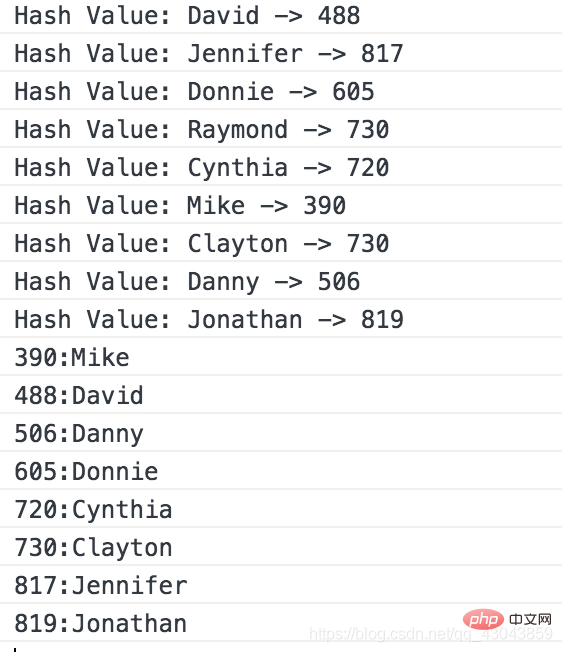
Javascript-Tutorial für Fortgeschrittene】
Das obige ist der detaillierte Inhalt vonWas ist Javascript-Hash?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



