

Dieser Artikel stellt Ihnen 15 Fallstricke vor, die bei der Verwendung von Redis auftreten können. Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.

Hallo zusammen, mein Name ist Kaito.
In diesem Artikel möchte ich mit Ihnen über die „Pits“ sprechen, auf die Sie bei der Verwendung von Redis stoßen können.
Wenn Sie bei der Verwendung von Redis auf die folgenden „seltsamen“ Szenarien gestoßen sind, ist es sehr wahrscheinlich, dass Sie in eine „Grube“ geraten sind:
Für einen Schlüssel ist eine Ablaufzeit festgelegt. Wie kann er nicht abgelaufen sein? Bereits?
Mit dem O(1)-Komplexitäts-SETBIT-Befehl wurde Redis OOMed?
Führen Sie RANDOMKEY aus und wählen Sie zufällig einen Schlüssel aus. Wird Redis dadurch blockiert?
Warum kann die Master-Datenbank mit demselben Befehl die Daten nicht finden, die Slave-Datenbank jedoch?
Warum benötigt die Slave-Datenbank mehr Speicher als die Master-Datenbank?
Warum gehen die auf Redis geschriebenen Daten aus unerklärlichen Gründen verloren?
...
[Verwandte Empfehlung: Redis-Video-Tutorial]
Was genau ist der Grund, der diese Probleme verursacht?
In diesem Artikel werde ich mit Ihnen die Fallstricke besprechen, auf die Sie bei der Verwendung von Redis stoßen können, und wie Sie diese vermeiden können.
Ich habe diese Fragen in drei Teile unterteilt:
Was sind die Fallstricke allgemeiner Befehle?
Was sind die Fallstricke der Datenpersistenz?
Was sind die Fallstricke der Master-Slave-Datenbanksynchronisierung?
Die Ursachen dieser Probleme werden Ihr Verständnis wahrscheinlich „untergraben“. Wenn Sie bereit sind, dann folgen Sie meinen Ideen und beginnen Sie!
Dieser Artikel enthält viele nützliche Informationen. Ich hoffe, Sie können ihn geduldig lesen.
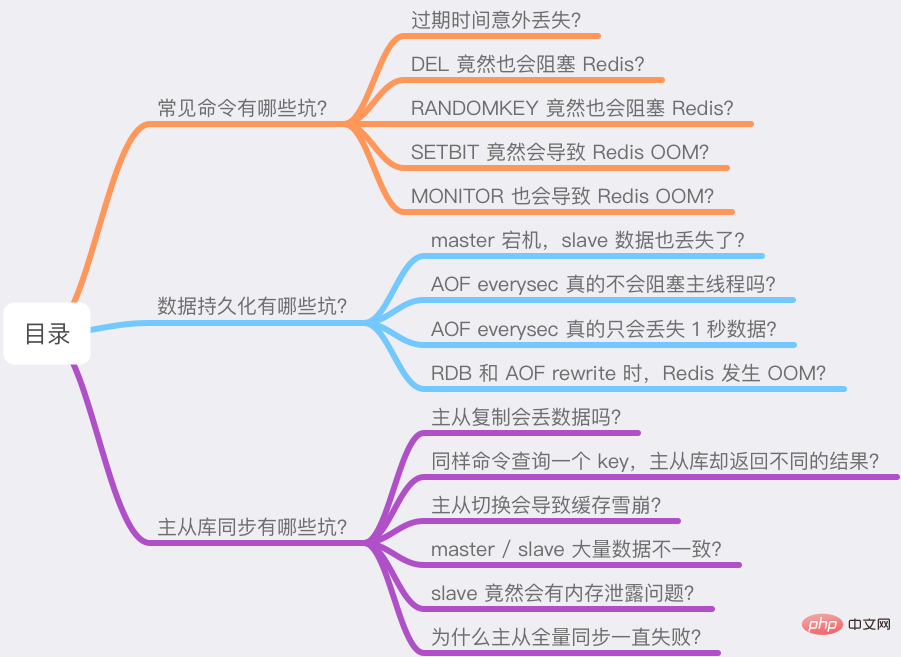
Werfen wir zunächst einen Blick auf einige gängige Befehle, die bei der Verwendung von Redis zu „unerwarteten“ Ergebnissen führen können.
1) Ablaufdatum versehentlich verloren?
Wenn Sie Redis verwenden, müssen Sie häufig den SET-Befehl verwenden. Dies ist sehr einfach.
Zusätzlich zum Festlegen des Schlüsselwerts kann SET auch die Ablaufzeit des Schlüssels wie folgt festlegen:
127.0.0.1:6379> SET testkey val1 EX 60 OK 127.0.0.1:6379> TTL testkey (integer) 59
Wenn Sie den Wert des Schlüssels zu diesem Zeitpunkt ändern möchten, verwenden Sie einfach den SET-Befehl, ohne ihn hinzuzufügen Parameter „Ablaufzeit“, dann wird die Ablaufzeit dieses Schlüssels „gelöscht“.
127.0.0.1:6379> SET testkey val2 OK 127.0.0.1:6379> TTL testkey // key永远不过期了! (integer) -1
Hast du es gesehen? Der Testschlüssel läuft niemals ab!
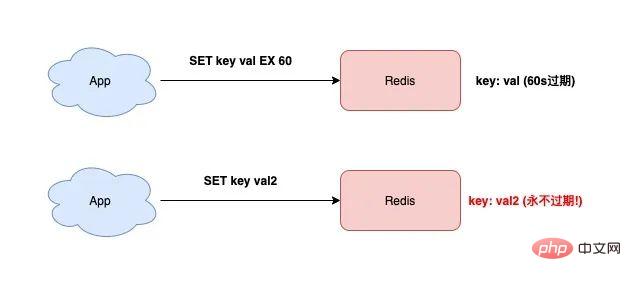
Wenn Sie gerade erst mit der Verwendung von Redis begonnen haben, sind Sie meiner Meinung nach in diese Falle geraten.
Der Grund für dieses Problem ist: Wenn die Ablaufzeit nicht im SET-Befehl festgelegt ist, „löscht“ Redis automatisch die Ablaufzeit des Schlüssels.
Wenn Sie feststellen, dass der Speicher von Redis weiter wächst und für viele Schlüssel ursprünglich Ablaufzeiten festgelegt waren, später jedoch feststellen, dass die Ablaufzeit verloren geht, liegt dies höchstwahrscheinlich an diesem Grund.
Zu diesem Zeitpunkt befindet sich in Ihrem Redis eine große Anzahl nicht abgelaufener Schlüssel, die zu viele Speicherressourcen verbrauchen.
Wenn Sie also den SET-Befehl verwenden und die Ablaufzeit zu Beginn festlegen, müssen Sie beim späteren Ändern des Schlüssels auch den Ablaufzeitparameter hinzufügen, um das Problem des Verlusts der Ablaufzeit zu vermeiden.
2) DEL kann auch Redis blockieren?
Um einen Schlüssel zu löschen, verwenden Sie auf jeden Fall den Befehl DEL. Ich frage mich, ob Sie nicht über die zeitliche Komplexität nachgedacht haben.
O(1)? Nicht unbedingt.
Wenn Sie die offizielle Dokumentation von Redis sorgfältig lesen, werden Sie feststellen: Die Zeit, die zum Löschen eines Schlüssels benötigt wird, hängt vom Typ des Schlüssels ab.
Die offizielle Dokumentation von Redis beschreibt den DEL-Befehl wie folgt:
key ist vom Typ String und die DEL-Zeitkomplexität ist O(1)
key ist vom Typ List/Hash/Set/ZSet, Die Zeit Die Komplexität von DEL ist O(M), M ist die Anzahl der Elemente
Das heißt, wenn Sie einen Schlüssel vom Typ Nicht-String löschen möchten, dauert es umso länger, je mehr Elemente der Schlüssel hat ausführen DEL Je länger es dauert!
Warum ist das so?
Der Grund dafür ist, dass Redis beim Löschen dieser Art von Schlüsseln nacheinander den Speicher jedes Elements freigeben muss. Je mehr Elemente vorhanden sind, desto zeitaufwändiger wird dieser Vorgang.
Und ein so langer Vorgang blockiert unweigerlich die gesamte Redis-Instanz und beeinträchtigt die Leistung von Redis.
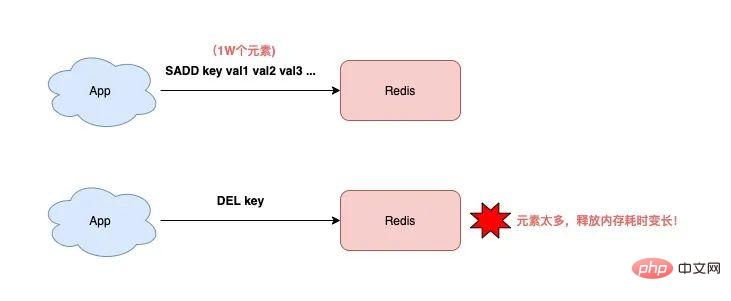
Wenn Sie also Schlüssel vom Typ List/Hash/Set/ZSet löschen, müssen Sie DEL nicht ohne nachzudenken ausführen. Stattdessen sollten Sie es wie folgt löschen:
Abfrage die Anzahl der Elemente: Führen Sie den Befehl LLEN/HLEN/SCARD/ZCARD aus
, um die Anzahl der Elemente zu bestimmen: Wenn die Anzahl der Elemente gering ist, können Sie die DEL-Löschung direkt ausführen, andernfalls stapelweise löschen
Löschen in Stapeln: LRANGE/HSCAN/SSCAN/ZSCAN + LPOP/RPOP/HDEL/SREM/ZREM ausführen Löschen
Nachdem wir nun die Auswirkungen von DEL auf Daten vom Typ List/Hash/Set/ZSet verstanden haben, analysieren wir sie noch einmal. Verursacht das Löschen eines Schlüssels vom Typ „String“ dieses Problem?
Hä? Habe ich nicht bereits erwähnt, dass im offiziellen Redis-Dokument beschrieben wird, dass die zeitliche Komplexität des Löschens eines Schlüssels vom Typ String O(1) beträgt? Das führt nicht dazu, dass Redis blockiert, oder?
Eigentlich ist das nicht unbedingt der Fall!
Denken Sie darüber nach: Was ist, wenn dieser Schlüssel sehr viel Speicher belegt?
Wenn dieser Schlüssel beispielsweise 500 MB Daten speichert (offensichtlich ist es ein Bigkey), dauert die Ausführung von DEL immer noch länger!
Das liegt daran, dass Redis Zeit braucht, um einen so großen Speicher für das Betriebssystem freizugeben, sodass der Vorgang länger dauert.
Für den String-Typ sollten Sie also besser keine zu großen Datenmengen speichern, da es sonst beim Löschen zu Leistungsproblemen kommt.
An diesem Punkt denken Sie vielleicht: Hat Redis 4.0 nicht den Lazy-Free-Mechanismus eingeführt? Wenn dieser Mechanismus aktiviert ist, wird der Speicherfreigabevorgang im Hintergrundthread ausgeführt. Blockiert er nicht den Hauptthread?
Das ist eine sehr gute Frage.
Ist das wirklich so?
Hier verrate ich Ihnen zunächst die Schlussfolgerung: Auch wenn Lazy-Free in Redis aktiviert ist, wird beim Löschen eines Bigkeys vom Typ String dieser immer noch im Hauptthread verarbeitet und nicht in einem Hintergrundthread ausgeführt. Daher besteht weiterhin die Gefahr einer Blockierung von Redis!
Warum ist das so?
Ich gebe Ihnen zunächst einen Hinweis. Interessierte Schüler können zunächst die entsprechenden Informationen überprüfen, um die Antwort zu finden. :)
Tatsächlich gibt es viele Wissenspunkte zum Thema Lazy-Free. Aus Platzgründen habe ich vor, später einen speziellen Artikel zu schreiben. ~
3) RANDOMKEY kann auch Redis blockieren?
Wenn Sie einen Schlüssel in Redis zufällig überprüfen möchten, verwenden Sie normalerweise den Befehl RANDOMKEY.
Dieser Befehl extrahiert „zufällig“ einen Schlüssel aus Redis.
Da es zufällig ist, muss die Ausführungsgeschwindigkeit sehr hoch sein, oder?
Tatsächlich ist es das nicht.
Um dieses Problem klar zu erklären, müssen wir es mit der Ablaufstrategie von Redis kombinieren.
Wenn Sie etwas über die Ablaufstrategie von Redis wissen, sollten Sie wissen, dass Redis abgelaufene Schlüssel mithilfe einer Kombination aus geplanter Reinigung und verzögerter Reinigung bereinigt.
Nachdem RANDOMKEY zufällig einen Schlüssel entnommen hat, prüft es zunächst, ob der Schlüssel abgelaufen ist.
Wenn der Schlüssel abgelaufen ist, löscht Redis ihn. Dieser Vorgang ist Lazy Cleanup.
Aber die Bereinigung ist noch nicht abgeschlossen. Redis muss noch einen „nicht abgelaufenen“ Schlüssel finden und ihn an den Client zurückgeben.
Zu diesem Zeitpunkt entnimmt Redis weiterhin zufällig einen Schlüssel und stellt dann fest, ob er abgelaufen ist, bis ein nicht abgelaufener Schlüssel gefunden und an den Client zurückgegeben wird.
Der gesamte Vorgang läuft folgendermaßen ab:
Der Meister wählt zufällig einen Schlüssel aus und stellt fest, ob er abgelaufen ist.
Wenn der Schlüssel abgelaufen ist, löschen Sie ihn und fahren Sie mit der zufälligen Auswahl von Schlüsseln fort Dieser Zyklus wird fortgesetzt, bis ein nicht abgelaufener Schlüssel zurückgegeben wird.
Aber hier gibt es ein Problem:
Wenn zu diesem Zeitpunkt eine große Anzahl von Schlüsseln in Redis abgelaufen ist, aber noch nicht gelöscht wurde, dauert dieser Zyklus an lange, bevor es endet, und diese Zeit wird für das Bereinigen abgelaufener Schlüssel und die Suche nach nicht abgelaufenen Schlüsseln aufgewendet.导致的结果就是,RANDOMKEY 执行耗时变长,影响 Redis 性能。
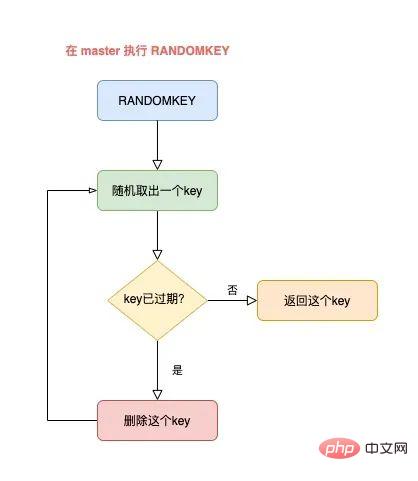
以上流程,其实是在 master 上执行的。
如果在 slave 上执行 RANDOMEKY,那么问题会更严重!
为什么?
主要原因就在于,slave 自己是不会清理过期 key。
那 slave 什么时候删除过期 key 呢?
其实,当一个 key 要过期时,master 会先清理删除它,之后 master 向 slave 发送一个 DEL 命令,告知 slave 也删除这个 key,以此达到主从库的数据一致性。
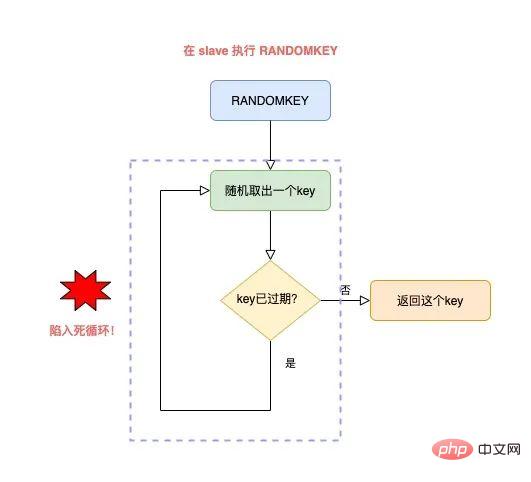
还是同样的场景:Redis 中存在大量已过期,但还未被清理的 key,那在 slave 上执行 RANDOMKEY 时,就会发生以下问题:
slave 随机取出一个 key,判断是否已过期
key 已过期,但 slave 不会删除它,而是继续随机寻找不过期的 key
由于大量 key 都已过期,那 slave 就会寻找不到符合条件的 key,此时就会陷入「死循环」!
也就是说,在 slave 上执行 RANDOMKEY,有可能会造成整个 Redis 实例卡死!
是不是没想到?在 slave 上随机拿一个 key,竟然有可能造成这么严重的后果?
这其实是 Redis 的一个 Bug,这个 Bug 一直持续到 5.0 才被修复。
修复的解决方案是,在 slave 上执行 RANDOMKEY 时,会先判断整个实例所有 key 是否都设置了过期时间,如果是,为了避免长时间找不到符合条件的 key,slave 最多只会在哈希表中寻找 100 次,无论是否能找到,都会退出循环。
这个方案就是增加上了一个最大重试次数,这样一来,就避免了陷入死循环。
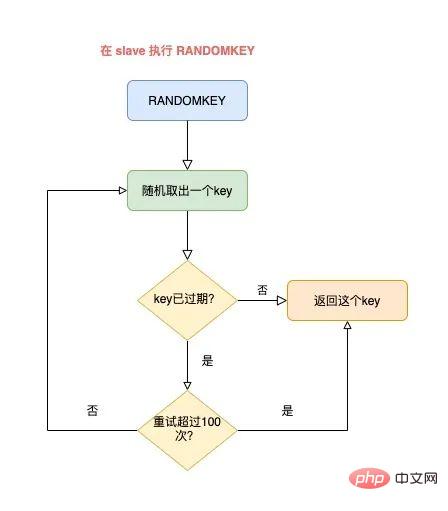
虽然这个方案可以避免了 slave 陷入死循环、卡死整个实例的问题,但是,在 master 上执行这个命令时,依旧有概率导致耗时变长。
所以,你在使用 RANDOMKEY 时,如果发现 Redis 发生了「抖动」,很有可能是因为这个原因导致的!
4) O(1) 复杂度的 SETBIT,竟然会导致 Redis OOM?
在使用 Redis 的 String 类型时,除了直接写入一个字符串之外,还可以把它当做 bitmap 来用。
具体来讲就是,我们可以把一个 String 类型的 key,拆分成一个个 bit 来操作,就像下面这样:
127.0.0.1:6379> SETBIT testkey 10 1 (integer) 1 127.0.0.1:6379> GETBIT testkey 10 (integer) 1
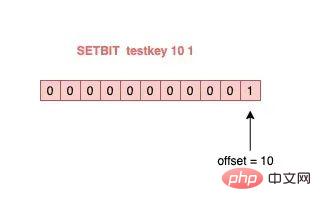
其中,操作的每一个 bit 位叫做 offset。
但是,这里有一个坑,你需要注意起来。
如果这个 key 不存在,或者 key 的内存使用很小,此时你要操作的 offset 非常大,那么 Redis 就需要分配「更大的内存空间」,这个操作耗时就会变长,影响性能。
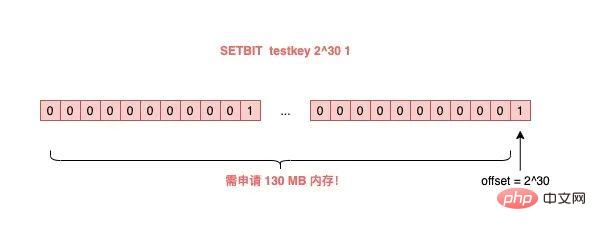
所以,当你在使用 SETBIT 时,也一定要注意 offset 的大小,操作过大的 offset 也会引发 Redis 卡顿。
这种类型的 key,也是典型的 bigkey,除了分配内存影响性能之外,在删除它时,耗时同样也会变长。
5) 执行 MONITOR 也会导致 Redis OOM?
这个坑你肯定听说过很多次了。
当你在执行 MONITOR 命令时,Redis 会把每一条命令写到客户端的「输出缓冲区」中,然后客户端从这个缓冲区读取服务端返回的结果。
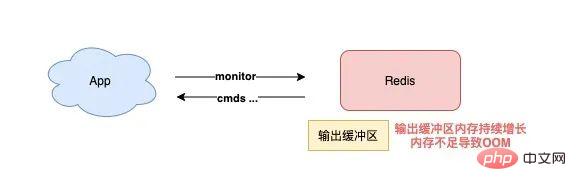
但是,如果你的 Redis QPS 很高,这将会导致这个输出缓冲区内存持续增长,占用 Redis 大量的内存资源,如果恰好你的机器的内存资源不足,那 Redis 实例就会面临被 OOM 的风险。
Daher müssen Sie MONITOR mit Vorsicht verwenden, insbesondere wenn der QPS hoch ist.
Die oben genannten Problemszenarien treten alle auf, wenn wir gängige Befehle verwenden, und es ist wahrscheinlich, dass sie „unbeabsichtigt“ ausgelöst werden.
Werfen wir einen Blick auf die Fallstricke der „Datenpersistenz“ von Redis?
Die Datenpersistenz von Redis ist in zwei Methoden unterteilt: RDB und AOF.
Unter diesen ist RDB ein Daten-Snapshot und AOF zeichnet jeden Schreibbefehl in einer Protokolldatei auf.
Probleme mit der Datenpersistenz konzentrieren sich hauptsächlich auf diese beiden Blöcke. Schauen wir sie uns der Reihe nach an.
1) Der Master ist ausgefallen und auch die Slave-Daten sind verloren?
Wenn Ihr Redis im folgenden Modus bereitgestellt wird, kommt es zu Datenverlust:
Master-Slave + Sentinel-Bereitstellungsinstanz
Master aktiviert keine Datenpersistenz
Der Redis-Prozess verwendet Supervisor-Management, und als „Prozess heruntergefahren, automatisch neu starten“ konfiguriert
Wenn der Master zu diesem Zeitpunkt ausfällt, führt dies zu folgenden Problemen:
Der Master fällt aus und der Sentinel hat den Wechsel nicht eingeleitet Zu diesem Zeitpunkt wird der Master-Prozess sofort automatisch vom Supervisor aufgerufen
Aber der Master aktiviert keine Datenpersistenz und ist nach dem Start eine „leere“ Instanz
Zu diesem Zeitpunkt, um konsistent zu sein Der Master und der Slave „löschen“ automatisch alle Daten in der Instanz, der Slave ist ebenfalls zu einer „leeren“ Instanz geworden
Haben Sie es gesehen? In diesem Szenario gehen alle Master-/Slave-Daten verloren.
Wenn die Geschäftsanwendung zu diesem Zeitpunkt auf Redis zugreift und feststellt, dass sich keine Daten im Cache befinden, sendet sie alle Anforderungen an die Back-End-Datenbank, was eine weitere „Cache-Lawine“ auslöst und große Auswirkungen hat das Geschäft.
Sie müssen also vermeiden, dass diese Situation eintritt:
Die Redis-Instanz wird automatisch hochgezogen, ohne Prozessmanagement-Tools zu verwenden.
Nachdem der Master ausgefallen ist, lassen Sie den Sentinel den Wechsel einleiten Schalten Sie den Slave um. Nachdem das Upgrade zum Master abgeschlossen ist, starten Sie den Master neu und lassen Sie ihn zum Slave herabstufen. Sie sollten dieses Problem vermeiden, wenn Sie die Datenpersistenz konfigurieren.
Basierend auf der Balance zwischen Leistung und Datensicherheit werden Sie auf jeden Fall die Appendfsync-Everysec-Lösung übernehmen.
Der Arbeitsmodus dieser Lösung besteht darin, dass der Hintergrundthread von Redis die Daten des AOF-Seitencaches alle 1 Sekunde auf die Festplatte (fsync) schreibt. Der Vorteil dieser Lösung besteht darin, dass der zeitaufwändige Vorgang des AOF-Disk-Bürstens im Hintergrund-Thread ausgeführt wird, wodurch Auswirkungen auf den Haupt-Thread vermieden werden.
Aber hat es wirklich keinen Einfluss auf den Hauptthread?
Die Antwort ist nein.
Tatsächlich gibt es ein solches Szenario:
Wenn der Redis-Hintergrundthread das AOF-Seiten-Cache-Flushing (fysnc) durchführt und die Festplatten-E/A-Last zu diesem Zeitpunkt zu hoch ist, wird der Aufruf von fsync blockiert.Zu diesem Zeitpunkt empfängt der Hauptthread noch Schreibanforderungen, sodass der Hauptthread zu diesem Zeitpunkt zunächst ermittelt, ob der letzte Hintergrundthread die Festplatte erfolgreich geleert hat.
Wie beurteilt man?
Nachdem der Festplatten-Flash erfolgreich war, zeichnet der Hintergrundthread die Flash-Zeit auf. Der Hauptthread wird diese Zeit nutzen, um festzustellen, wie lange seit dem letzten Pinsel vergangen ist. Der gesamte Vorgang ist wie folgt:
Vor dem Schreiben des AOF-Seitencaches (Systemaufruf schreiben) prüft der Hauptthread zunächst, ob die Hintergrund-Fsync abgeschlossen wurde.
fsync ist abgeschlossen, der Hauptthread schreibt direkt in den AOF-Seitencache
fsync ist nicht abgeschlossen. Überprüfen Sie dann, wie lange seit dem letzten fsync vergangen ist?
Wenn seit dem erfolgreichen letzten Fysnc weniger als 2 Sekunden vergangen sind, kehrt der Hauptthread direkt zurück, ohne den AOF-Seitencache zu schreiben.
Wenn seit dem erfolgreichen letzten Fysnc mehr als 2 Sekunden vergangen sind, der Hauptthread wird den AOF-Seiten-Cache zwangsweise schreiben (Systemaufruf schreiben) Das Betreiben desselben fd, fsync und write schließt sich gegenseitig aus. Eine Partei muss warten, bis die andere Partei erfolgreich ist, bevor sie mit der Ausführung fortfahren kann, andernfalls wird sie blockiert und gewartet)
Durch Analyse können wir feststellen, dass selbst wenn die von Ihnen konfigurierte AOF-Flushing-Strategie „appendfsync everysec“ ist, immer noch das Risiko besteht, dass der Hauptthread blockiert wird.
Tatsächlich besteht der Kernpunkt dieses Problems darin, dass die E/A-Last der Festplatte zu hoch ist, was zu einer Blockierung von fynsc führt, was wiederum dazu führt, dass der Hauptthread beim Schreiben in den AOF-Seitencache blockiert.
Sie müssen also sicherstellen, dass die Festplatte über ausreichende E/A-Ressourcen verfügt, um dieses Problem zu vermeiden.
3) Verliert AOF everysec wirklich nur 1 Sekunde an Daten?
Analysieren Sie weiterhin die oben genannten Fragen.
Wie oben erwähnt, müssen wir uns hier auf Schritt 4 oben konzentrieren.
Das heißt: Wenn der Hauptthread in den AOF-Seitencache schreibt, ermittelt er zunächst den Zeitpunkt, zu dem der letzte fsync erfolgreich war. Wenn der letzte fysnc innerhalb von 2 Sekunden erfolgreich war, kehrt der Hauptthread direkt zurück und schreibt nicht mehr in den AOF-Seitencache.
Das bedeutet, dass wenn der Hintergrundthread fsync ausführt, um die Festplatte zu leeren, der Hauptthread bis zu 2 Sekunden wartet und nicht in den AOF-Seitencache schreibt.
Wenn Redis zu diesem Zeitpunkt abstürzt, gehen 2 Sekunden Daten in der AOF-Datei verloren, nicht 1 Sekunde!
Lassen Sie uns weiter analysieren: Warum wartet der Redis-Hauptthread 2 Sekunden, ohne den AOF-Seitencache zu schreiben?
Wenn Redis AOF als appendfsync everysec konfiguriert ist, führt der Hintergrundthread normalerweise jede Sekunde eine Fsync-Festplattenspülung aus. Wenn die Festplattenressourcen ausreichen, wird dies nicht der Fall sein.
Mit anderen Worten, der Redis-Hauptthread muss sich eigentlich nicht darum kümmern, ob der Hintergrundthread die Festplatte erfolgreich leert, solange der AOF-Seitencache gedankenlos geschrieben wird.
Der Redis-Autor war jedoch der Ansicht, dass der Hintergrundthread fsync möglicherweise blockiert wird, wenn die E/A-Ressourcen der Festplatte zu diesem Zeitpunkt relativ knapp sind.
Bevor der Redis-Autor den AOF-Seitencache in den Hauptthread schreibt, überprüft er zunächst die Zeit, seit der letzte fsync erfolgreich war. Wenn mehr als 1 Sekunde erfolglos vergangen ist, weiß der Hauptthread zu diesem Zeitpunkt, dass fsync möglicherweise blockiert.
Der Hauptthread wartet also 2 Sekunden, ohne den AOF-Seitencache zu schreiben. Der Zweck besteht darin:
Das Risiko einer Blockierung des Hauptthreads zu verringern (wenn der AOF-Seitencache unachtsam geschrieben wird, wird der Hauptthread blockiert). sofort blockiert)
Wenn fsync blockiert, lässt der Hauptthread 1 Sekunde Zeit, damit der Hintergrundthread auf den Erfolg von fsync wartet
Aber der Preis ist, dass AOF 2 Sekunden verliert, wenn zu diesem Zeitpunkt eine Ausfallzeit auftritt von Daten statt 1 Sekunde.
Diese Lösung sollte ein weiterer Kompromiss zwischen Leistung und Datensicherheit durch den Redis-Autor sein.
Alles, was Sie hier wissen müssen, ist, dass selbst wenn AOF so konfiguriert ist, dass die Festplatten jede Sekunde geleert werden, der Datenverlust durch AOF in der oben genannten Extremsituation tatsächlich 2 Sekunden beträgt.
4) OOM tritt in Redis auf, wenn RDB und AOF neu geschrieben werden?
Abschließend werfen wir einen Blick auf die Probleme, die auftreten, wenn Redis RDB-Snapshots und AOF-Rewrite durchführt.
Wenn Redis einen RDB-Snapshot und ein AOF-Rewrite durchführt, erstellt es einen untergeordneten Prozess, um die Daten in der Instanz auf der Festplatte beizubehalten.
Durch das Erstellen eines untergeordneten Prozesses wird die Fork-Funktion des Betriebssystems aufgerufen.
Nach Abschluss der Fork-Ausführung teilen der übergeordnete Prozess und der untergeordnete Prozess gleichzeitig dieselben Speicherdaten.
Aber der Hauptprozess kann zu diesem Zeitpunkt weiterhin Schreibanforderungen empfangen, und eingehende Schreibanforderungen verwenden Copy On Write, um Speicherdaten zu verarbeiten.
Mit anderen Worten: Sobald der Hauptprozess Daten enthält, die geändert werden müssen, ändert Redis die Daten nicht direkt im vorhandenen Speicher, sondern kopiert zuerst die Speicherdaten und ändert dann die Daten im neuen Speicher nennt man „Copy-on-Write“.
Copy-on-Write kann auch so verstanden werden, dass derjenige, der etwas schreiben muss, es zuerst kopiert und dann ändert.
Sie sollten herausgefunden haben, dass der übergeordnete Prozess, wenn er einen Schlüssel ändern möchte, die ursprünglichen Speicherdaten in den neuen Speicher kopieren muss. Dieser Prozess beinhaltet die Anwendung für „neuen Speicher“.
Wenn Ihre Geschäftsmerkmale „mehr Schreiben und weniger Lesen“ lauten und der OPS sehr hoch ist, wird beim RDB- und AOF-Umschreiben eine große Menge an Speicherkopierarbeit generiert.
Was ist das Problem dabei?
Da es viele Schreibanforderungen gibt, beansprucht der übergeordnete Redis-Prozess viel Speicher. In diesem Zeitraum gilt: Je größer der Umfang der Schlüsseländerung, desto mehr neue Speicheranwendungen sind erforderlich.
Wenn Ihr Computer nicht über ausreichende Speicherressourcen verfügt, besteht bei Redis das Risiko von OOM!
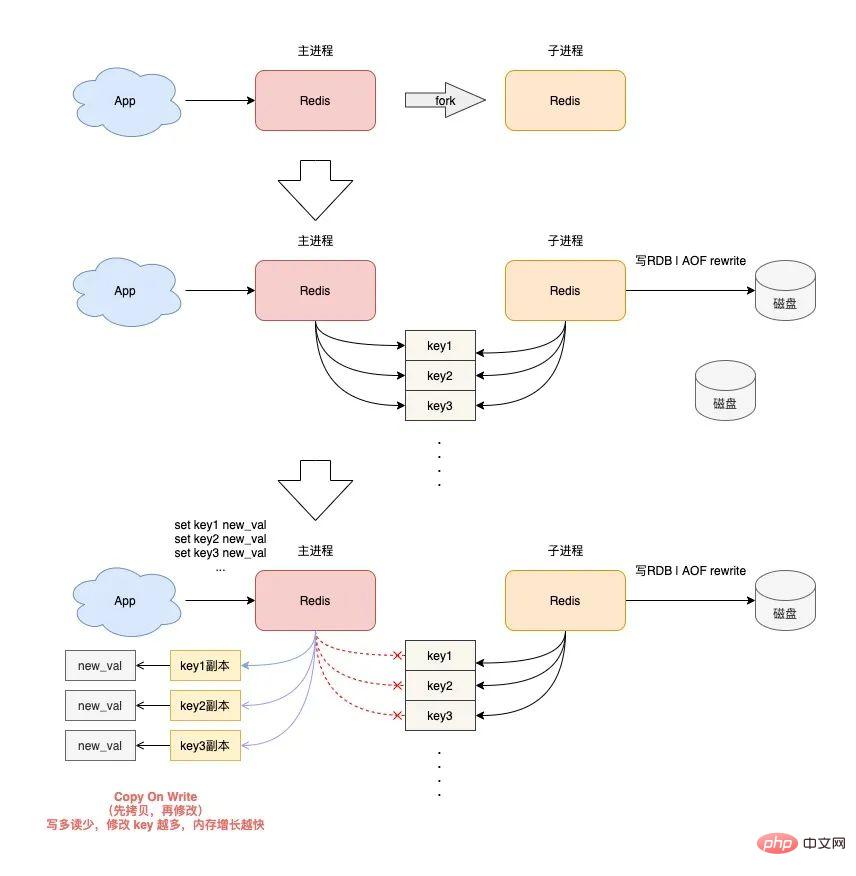
这就是你会从 DBA 同学那里听到的,要给 Redis 机器预留内存的原因。
其目的就是避免在 RDB 和 AOF rewrite 期间,防止 Redis OOM。
以上这些,就是「数据持久化」会遇到的坑,你踩到过几个?
下面我们再来看「主从复制」会存在哪些问题。
Redis 为了保证高可用,提供了主从复制的方式,这样就可以保证 Redis 有多个「副本」,当主库宕机后,我们依旧有从库可以使用。
在主从同步期间,依旧存在很多坑,我们依次来看。
1) 主从复制会丢数据吗?
首先,你需要知道,Redis 的主从复制是采用「异步」的方式进行的。
这就意味着,如果 master 突然宕机,可能存在有部分数据还未同步到 slave 的情况发生。
这会导致什么问题呢?
如果你把 Redis 当做纯缓存来使用,那对业务来说没有什么影响。
master 未同步到 slave 的数据,业务应用可以从后端数据库中重新查询到。
但是,对于把 Redis 当做数据库,或是当做分布式锁来使用的业务,有可能因为异步复制的问题,导致数据丢失 / 锁丢失。
关于 Redis 分布式锁可靠性的更多细节,这里先不展开,后面会单独写一篇文章详细剖析这个知识点。这里你只需要先知道,Redis 主从复制是有概率发生数据丢失的。
2) 同样命令查询一个 key,主从库却返回不同的结果?
不知道你是否思考过这样一个问题:如果一个 key 已过期,但这个 key 还未被 master 清理,此时在 slave 上查询这个 key,会返回什么结果呢?
slave 正常返回 key 的值
slave 返回 NULL
你认为是哪一种?可以思考一下。
答案是:不一定。
嗯?为什么会不一定?
这个问题非常有意思,请跟紧我的思路,我会带你一步步分析其中的原因。
其实,返回什么结果,这要取决于以下 3 个因素:
Redis 的版本
具体执行的命令
机器时钟
先来看 Redis 版本。
如果你使用的是 Redis 3.2 以下版本,只要这个 key 还未被 master 清理,那么,在 slave 上查询这个 key,它会永远返回 value 给你。
也就是说,即使这个 key 已过期,在 slave 上依旧可以查询到这个 key。
// Redis 2.8 版本 在 slave 上执行 127.0.0.1:6479> TTL testkey (integer) -2 // 已过期 127.0.0.1:6479> GET testkey "testval" // 还能查询到!
但如果此时在 master 上查询这个 key,发现已经过期,就会把它清理掉,然后返回 NULL。
// Redis 2.8 版本 在 master 上执行 127.0.0.1:6379> TTL testkey (integer) -2 127.0.0.1:6379> GET testkey (nil)
发现了吗?在 master 和 slave 上查询同一个 key,结果竟然不一样?
其实,slave 应该要与 master 保持一致,key 已过期,就应该给客户端返回 NULL,而不是还正常返回 key 的值。
为什么会发生这种情况?
其实这是 Redis 的一个 Bug:3.2 以下版本的 Redis,在 slave 上查询一个 key 时,并不会判断这个 key 是否已过期,而是直接无脑返回给客户端结果。
这个 Bug 在 3.2 版本进行了修复,但是,它修复得「不够彻底」。
什么叫修复得「不够彻底」?
这就要结合前面提到的,第 2 个影响因素「具体执行的命令」来解释了。
Redis 3.2 虽然修复了这个 Bug,但却遗漏了一个命令:EXISTS。
也就是说,一个 key 已过期,在 slave 直接查询它的数据,例如执行 GET/LRANGE/HGETALL/SMEMBERS/ZRANGE 这类命令时,slave 会返回 NULL。
但如果执行的是 EXISTS,slave 依旧会返回:key 还存在。
// Redis 3.2 版本 在 slave 上执行 127.0.0.1:6479> GET testkey (nil) // key 已逻辑过期 127.0.0.1:6479> EXISTS testkey (integer) 1 // 还存在!
原因在于,EXISTS 与查询数据的命令,使用的不是同一个方法。
Redis 作者只在查询数据时增加了过期时间的校验,但 EXISTS 命令依旧没有这么做。
直到 Redis 4.0.11 这个版本,Redis 才真正把这个遗漏的 Bug 完全修复。
如果你使用的是这个之上的版本,那在 slave 上执行数据查询或 EXISTS,对于已过期的 key,就都会返回「不存在」了。
这里我们先小结一下,slave 查询过期 key,经历了 3 个阶段:
3.2 以下版本,key 过期未被清理,无论哪个命令,查询 slave,均正常返回 value
3.2 - 4.0.11 版本,查询数据返回 NULL,但 EXISTS 依旧返回 true
4.0.11 以上版本,所有命令均已修复,过期 key 在 slave 上查询,均返回「不存在」
这里要特别鸣谢《Redis开发与运维》的作者,付磊。
这个问题我是在他的文章中看到的,感觉非常有趣,原来 Redis 之前还存在这样的 Bug 。随后我又查阅了相关源码,并对逻辑进行了梳理,在这里才写成文章分享给大家。
虽然已在微信中亲自答谢,但在这里再次表达对他的谢意~
最后,我们来看影响查询结果的第 3 个因素:「机器时钟」。
假设我们已规避了上面提到的版本 Bug,例如,我们使用 Redis 5.0 版本,在 slave 查询一个 key,还会和 master 结果不同吗?
答案是,还是有可能会的。
这就与 master / slave 的机器时钟有关了。
无论是 master 还是 slave,在判断一个 key 是否过期时,都是基于「本机时钟」来判断的。
如果 slave 的机器时钟比 master 走得「快」,那就会导致,即使这个 key 还未过期,但以 slave 上视角来看,这个 key 其实已经过期了,那客户端在 slave 上查询时,就会返回 NULL。
是不是很有意思?一个小小的过期 key,竟然藏匿这么多猫腻。
如果你也遇到了类似的情况,就可以通过上述步骤进行排查,确认是否踩到了这个坑。
3) 主从切换会导致缓存雪崩?
这个问题是上一个问题的延伸。
我们假设,slave 的机器时钟比 master 走得「快」,而且是「快很多」。
此时,从 slave 角度来看,Redis 中的数据存在「大量过期」。
如果此时操作「主从切换」,把 slave 提升为新的 master。
它成为 master 后,就会开始大量清理过期 key,此时就会导致以下结果:
master 大量清理过期 key,主线程发生阻塞,无法及时处理客户端请求
Redis 中数据大量过期,引发缓存雪崩
你看,当 master / slave 机器时钟严重不一致时,对业务的影响非常大!
所以,如果你是 DBA 运维,一定要保证主从库的机器时钟一致性,避免发生这些问题。
4) master / slave 大量数据不一致?
还有一种场景,会导致 master / slave 的数据存在大量不一致。
这就涉及到 Redis 的 maxmemory 配置了。
Redis 的 maxmemory 可以控制整个实例的内存使用上限,超过这个上限,并且配置了淘汰策略,那么实例就开始淘汰数据。
但这里有个问题:假设 master / slave 配置的 maxmemory 不一样,那此时就会发生数据不一致。
例如,master 配置的 maxmemory 为 5G,而 slave 的 maxmemory 为 3G,当 Redis 中的数据超过 3G 时,slave 就会「提前」开始淘汰数据,此时主从库数据发生不一致。
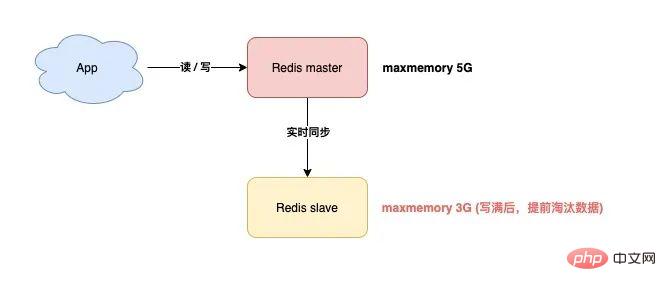
Obwohl die maximalen Speichereinstellungen von Master / Slave gleich sind, müssen Sie besonders darauf achten, wenn Sie deren Obergrenze anpassen möchten, da sonst auch der Slave dazu führt, dass die Daten gelöscht werden:
Beim Erhöhen der maxmemory, passen Sie zuerst den Slave und dann den Master an vermieden.
Der Hauptgrund dafür ist, dass, nachdem
slave den maximalen Speicher überschreitet, die Daten „selbst“ gelöscht werdenWenn der Slave die Daten nicht selbst löschen darf, können all diese Probleme vermieden werden?
Das stimmt.
Als Reaktion auf dieses Problem sollten die Redis-Verantwortlichen auch Feedback von vielen Benutzern erhalten haben. In der Redis 5.0-Version hat der Beamte dieses Problem endlich vollständig gelöst! Redis 5.0 fügt ein Konfigurationselement hinzu: Replica-ignore-maxmemory, der Standardwert ist „Ja“.
Dieser Parameter bedeutet, dass die Daten selbst dann nicht gelöscht werden, wenn der Slave-Speicher den maximalen Speicher überschreitet!
Auf diese Weise ist der Slave immer auf Augenhöhe mit dem Master und kopiert nur die vom Master gesendeten Daten originalgetreu und macht keine „kleinen Tricks“ von alleine.Zu diesem Zeitpunkt kann garantiert werden, dass die Daten von Master/Slave vollständig konsistent sind!
Wenn Sie Version 5.0 verwenden, müssen Sie sich über dieses Problem keine Sorgen machen.5) Der Sklave hat tatsächlich ein Speicherverlustproblem?
Ja, das hast du richtig gelesen. Wie ist das passiert? Schauen wir es uns im Detail an.
Wenn Sie Redis verwenden, wird der Slave-Speicherverlust ausgelöst, wenn die folgenden Szenarien erfüllt sind:
Redis verwendet Versionen unter 4.0
Slave-Konfigurationselement ist schreibgeschützt = nein (schreibbar aus der Bibliothek). )
Schreiben Sie einen Schlüssel mit Ablaufzeit für den Slave
Zu diesem Zeitpunkt weist der Slave einen Speicherverlust auf:
Der Schlüssel im Slave wird nicht automatisch bereinigt, selbst wenn die Ablaufzeit erreicht ist.Wenn Sie es nicht aktiv löschen, bleiben diese Schlüssel im Slave-Speicher und verbrauchen den Speicher des Slaves.
Das ist das Slave-„Speicherleck“-Problem.
Das ist eigentlich ein Fehler von Redis. Dieses Problem wurde nur in Redis 4.0 behoben. Die Lösung ist:Wenn auf einem beschreibbaren Slave Schlüssel mit Ablaufzeit geschrieben werden, „zeichnet“ der Slave diese Schlüssel auf.
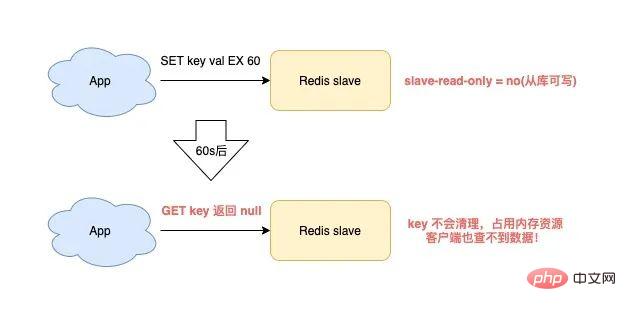 Dann scannt der Slave diese Schlüssel regelmäßig und wenn die Ablaufzeit erreicht ist, werden sie gelöscht.
Dann scannt der Slave diese Schlüssel regelmäßig und wenn die Ablaufzeit erreicht ist, werden sie gelöscht.
Wenn Ihr Unternehmen vorübergehend Daten auf dem Slave speichern muss und für diese Schlüssel Ablaufzeiten festgelegt sind, sollten Sie auf dieses Problem achten.
Sie müssen Ihre Redis-Version bestätigen, wenn sie unter 4.0 liegt, vermeiden Sie diese Gefahr. Tatsächlich besteht die beste Lösung darin, eine Redis-Nutzungsspezifikation zu formulieren. Der Slave muss schreibgeschützt sein und darf nicht nur die Datenkonsistenz des Masters/Slaves gewährleisten, sondern auch vermeiden Slave-Speicherleckproblem.
6) Warum schlägt die vollständige Master-Slave-Synchronisierung immer wieder fehl?Während der vollständigen Master-Slave-Synchronisierung kann das Problem eines Synchronisierungsfehlers auftreten. Das spezifische Szenario ist wie folgt:
Slave initiiert eine vollständige Synchronisierungsanforderung an den Master, der Master generiert eine RDB und sendet sie an den Slave. und der Slave lädt die RDB.
Da die RDB-Daten zu groß sind, wird auch die Slave-Ladezeit sehr lang. Zu diesem Zeitpunkt werden Sie feststellen, dass der Slave das Laden der RDB noch nicht abgeschlossen hat, die Verbindung zwischen Master und Slave jedoch getrennt wurde und die Datensynchronisierung fehlgeschlagen ist.
Danach werden Sie feststellen, dass der Slave erneut die vollständige Synchronisierung initiiert und der Master eine RDB generiert und an den Slave sendet.
Ähnlicherweise schlägt die Master/Slave-Synchronisierung erneut fehl, wenn der Slave die RDB lädt, und so weiter.
Was ist los?
Eigentlich ist dies das „Replikationssturm“-Problem von Redis.
Was ist Copy Storm?
Genau wie gerade beschrieben: Die vollständige Master-Slave-Synchronisierung ist fehlgeschlagen, dann wurde die Synchronisierung neu gestartet und dann ist die Synchronisierung erneut fehlgeschlagen. Dies geht hin und her, ein Teufelskreis, der weiterhin Maschinenressourcen verschwendet.
Warum verursacht dies dieses Problem?
Wenn Ihr Redis die folgenden Eigenschaften aufweist, kann dieses Problem auftreten:
Die Instanzdaten des Masters sind zu groß und der Slave braucht zu lange, um die RDB zu laden
Kopieren Sie den Puffer (Slave-Client-Ausgabe). -buffer-limit) ist zu klein konfiguriert
Der Master hat eine große Menge an Schreibanfragen
Wenn Master und Slave die Daten vollständig synchronisieren, werden die vom Master empfangenen Schreibanfragen zuerst an den Master geschrieben -Slave „Kopierpuffer“. Die „Obergrenze“ dieses Puffers wird durch die Konfiguration bestimmt.
Wenn der Slave die RDB zu langsam lädt, kann der Slave die Daten im „Replikationspuffer“ nicht rechtzeitig lesen, was zu einem „Überlauf“ des Replikationspuffers führt.
Um ein kontinuierliches Speicherwachstum zu vermeiden, trennt der Master den Slave zu diesem Zeitpunkt „gewaltsam“ und die vollständige Synchronisierung schlägt fehl.
Danach wird der Slave, der nicht synchronisiert werden konnte, die vollständige Synchronisierung „erneut“ einleiten und dann in das oben beschriebene Problem geraten und sich in einem Teufelskreis wiederholen. Dies ist der sogenannte „Replikationssturm“.
Wie kann dieses Problem gelöst werden? Ich gebe Ihnen folgende Vorschläge:
Redis-Instanz sollte nicht zu groß sein, zu große RDB vermeiden
Konfigurieren Sie den Kopierpuffer so groß wie möglich, geben Sie dem Slave genügend Zeit, um die RDB zu laden, und verringern Sie die Wahrscheinlichkeit eines vollständigen Synchronisierungsfehlers
Wenn auch Sie auf diese Falle gestoßen sind, können Sie sie mit dieser Lösung lösen.
Okay, zusammenfassend sprechen wir in diesem Artikel hauptsächlich über die möglichen Fallstricke von Redis in drei Aspekten: „Befehlsverwendung“, „Datenpersistenz“ und „Master-Slave-Synchronisation“.
Wie wäre es damit? Hat es Ihr Verständnis untergraben?
Dieser Artikel enthält eine relativ große Menge an Informationen, keine Sorge, ich habe auch eine Mindmap für Sie vorbereitet, um Ihnen das bessere Verständnis und die Erinnerung zu erleichtern.
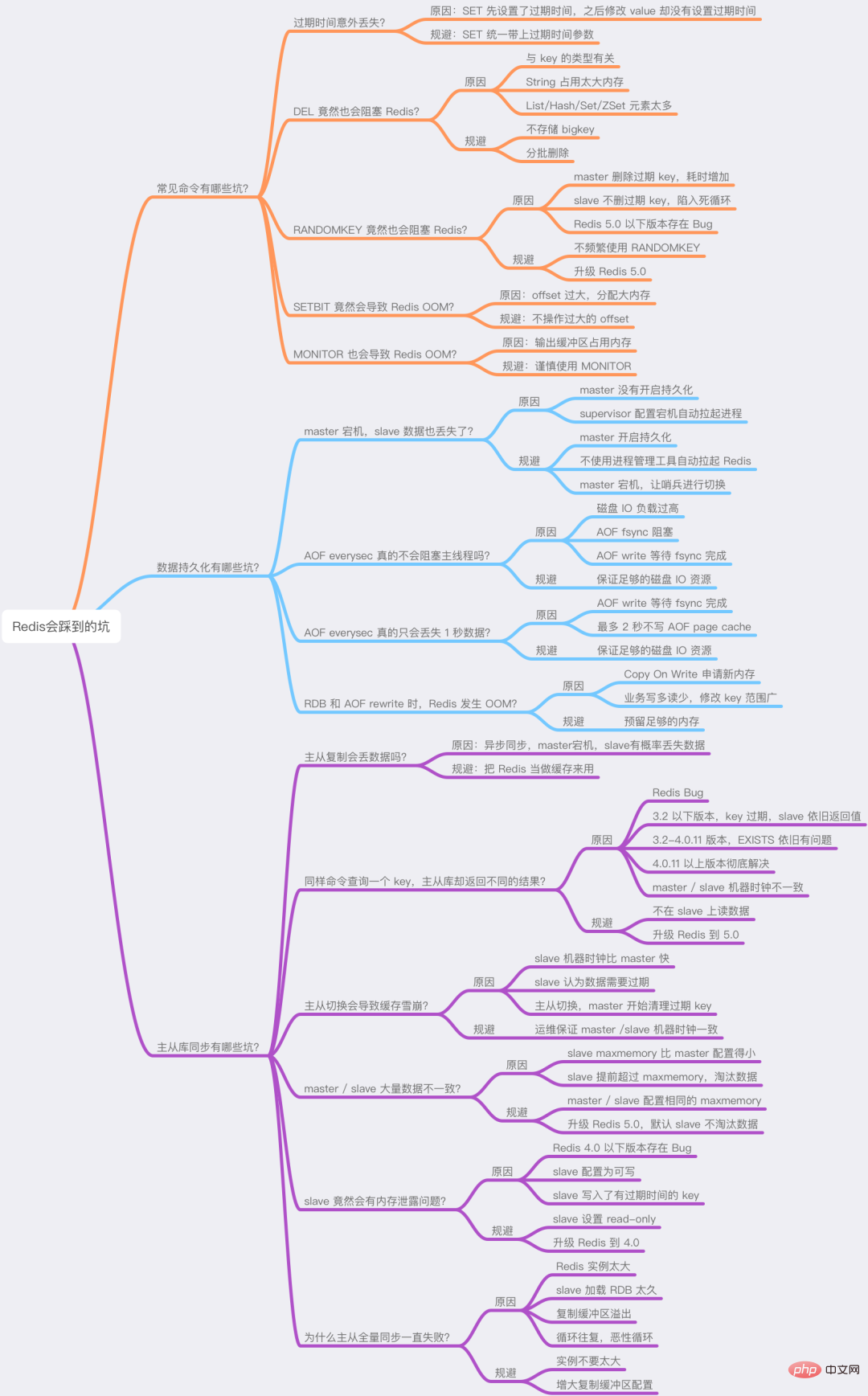
Ich hoffe, Sie können diese Fallstricke bei der Verwendung von Redis im Voraus vermeiden und Redis bessere Dienste bieten lassen.
Abschließend möchte ich mit Ihnen über meine Erfahrungen und Gedanken zum Umgang mit Fallstricken während des Entwicklungsprozesses sprechen.
Tatsächlich durchläuft man, wenn man mit einem neuen Gebiet in Kontakt kommt, mehrere Phasen: Unbekanntheit, Vertrautheit, das Überwinden von Fallstricken, das Aufsaugen von Erfahrungen und das Sichfühlen.
Wie können Sie also in dieser Phase der Fallstricke Fallstricke vermeiden? Oder wie kann man Probleme effizient beheben, nachdem man in eine Falle getappt ist?
Hier habe ich 4 Aspekte zusammengefasst, die Ihnen helfen sollen:
1) Lesen Sie weitere offizielle Dokumente + Kommentare zu Konfigurationsdateien
Lesen Sie unbedingt weitere offizielle Dokumente und Kommentare zu Konfigurationsdateien. Tatsächlich weist Sie eine hervorragende Software auf viele mögliche Risiken in Dokumenten und Kommentaren hin. Wenn Sie diese sorgfältig lesen, können Sie viele grundlegende Probleme im Voraus vermeiden.
2) Lassen Sie die Details Ihrer Fragen nicht los und denken Sie mehr darüber nach, warum?
Immer neugierig bleiben. Wenn Sie auf ein Problem stoßen, beherrschen Sie die Fähigkeit, den Kokon abzuziehen und das Problem schrittweise zu lokalisieren, und behalten Sie stets die Mentalität bei, den Kern des Problems zu erforschen.
3) Wagen Sie es, Fragen zu stellen, der Quellcode wird nicht lügen
Wenn Sie denken, dass ein Problem seltsam ist, es könnte sich um einen Fehler handeln, wagen Sie es, Fragen zu stellen.
Es ist besser, die Wahrheit des Problems anhand des Quellcodes herauszufinden, als hundert voneinander plagiierte Artikel im Internet zu lesen (sie immer wieder zu kopieren ist höchstwahrscheinlich falsch).
4) Es gibt keine perfekte Software, exzellente Software wird Schritt für Schritt iteriert
Jede exzellente Software wird Schritt für Schritt iteriert. Während des Iterationsprozesses ist es normal, dass Fehler auftreten, und wir müssen dies mit der richtigen Mentalität betrachten.
Diese Erfahrungen und Erkenntnisse sind auf jeden Studienbereich anwendbar. Ich hoffe, dass sie für Sie hilfreich sein werden.
Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Programmierlehre! !
Das obige ist der detaillierte Inhalt von15 Fallstricke, auf die Sie bei der Verwendung von Redis stoßen können. Kommen Sie und sammeln Sie sie ein, um Blitzschläge zu vermeiden! !. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



