Wie stelle ich die Ablaufzeit und die dauerhafte Gültigkeit des Redis-Schlüssels ein?
EXPIRE- und PERSIST-Befehle.
Wir wissen, dass Ablauf zum Festlegen der Ablaufzeit des Schlüssels verwendet wird. Wie gehe ich also mit abgelaufenen Daten um?
Zusätzlich zur Cache-Invalidierungsstrategie, die mit dem Cache-Server geliefert wird (Redis hat 6 Strategien zur Auswahl). Standardmäßig können wir auch eine angepasste Cache-Entfernung entsprechend den spezifischen Geschäftsanforderungen durchführen. Es gibt zwei gängige Strategien:
1 Bereinigen Sie abgelaufene Caches regelmäßig.
2 Der verwendete Cache ist abgelaufen. Wenn er abgelaufen ist, rufen Sie das zugrunde liegende System auf, um neue Daten abzurufen und den Cache zu aktualisieren.
Beide haben ihre eigenen Vor- und Nachteile. Der Nachteil des ersten besteht darin, dass es schwieriger ist, eine große Anzahl zwischengespeicherter Schlüssel zu verwalten. Der Nachteil des zweiten besteht darin, dass der Cache jedes Mal, wenn ein Benutzer ihn anfordert, gespeichert werden muss als ungültig beurteilt werden, und die Logik ist relativ kompliziert! Welche Lösung konkret zum Einsatz kommt, kann anhand der eigenen Anwendungsszenarien abgewogen werden.
Es gibt 20 Millionen Daten in MySQL, aber nur 200.000 Daten werden in Redis gespeichert. Wie kann sichergestellt werden, dass es sich bei den Daten in Redis um heiße Daten handelt?
Wenn die Größe des Redis-Speicherdatensatzes auf eine bestimmte Größe ansteigt, wird die Dateneliminierungsstrategie implementiert.
Was sind die Speichereliminierungsstrategien von Redis?
Die Speichereliminierungsstrategie von Redis bezieht sich auf den Umgang mit Daten, die neu geschrieben werden müssen und zusätzlichen Speicherplatz erfordern, wenn der für das Caching in Redis verwendete Speicher nicht ausreicht .
1. Selektive Entfernung des globalen Schlüsselraums
noeviction: Wenn der Speicher nicht ausreicht, um die neu geschriebenen Daten aufzunehmen, meldet der neue Schreibvorgang einen Fehler.
allkeys-lru: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, entfernen Sie im Schlüsselbereich den zuletzt verwendeten Schlüssel. (Dies wird am häufigsten verwendet)
allkeys-random: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, wird ein Schlüssel zufällig aus dem Schlüsselraum entfernt.
2. Selektives Entfernen von Schlüsselräumen mit festgelegter Ablaufzeit
volatile-lru: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, wird im Schlüsselraum mit festgelegter Ablaufzeit der zuletzt verwendete Schlüssel entfernt .
flüchtig-zufällig: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, wird ein Schlüssel nach dem Zufallsprinzip mit einer festgelegten Ablaufzeit aus dem Schlüsselraum entfernt.
volatile-ttl: Wenn der Speicher nicht ausreicht, um neu geschriebene Daten aufzunehmen, werden im Schlüsselraum mit festgelegter Ablaufzeit zuerst Schlüssel mit einer früheren Ablaufzeit entfernt.
Zusammenfassung
Die Auswahl der Speichereliminierungsstrategie von Redis hat keinen Einfluss auf die Verarbeitung abgelaufener Schlüssel. Die Speichereliminierungsrichtlinie wird verwendet, um Daten zu verarbeiten, die zusätzlichen Speicherplatz benötigen, wenn der Speicher nicht ausreicht. Die Ablaufrichtlinie wird verwendet, um abgelaufene zwischengespeicherte Daten zu verarbeiten.
Welche physischen Ressourcen verbraucht Redis hauptsächlich?
Speicher.
Was passiert, wenn Redis nicht mehr über genügend Speicher verfügt?
Wenn die festgelegte Obergrenze erreicht ist, gibt der Redis-Schreibbefehl eine Fehlermeldung zurück (der Lesebefehl kann jedoch weiterhin normal zurückkehren). Sie können auch den Speicherbeseitigungsmechanismus konfigurieren und Redis die obere Speichergrenze erreichen, Der alte Inhalt wird gelöscht.
Wie führt Redis eine Speicheroptimierung durch?
Sie können Daten vom Sammlungstyp wie Hash, Liste, sortierter Satz, Satz usw. gut nutzen, da normalerweise viele kleine Schlüsselwerte kompakter zusammen gespeichert werden können. Verwenden Sie so viele Hashes wie möglich (d. h. die in einer Hash-Tabelle gespeicherte Anzahl ist gering) und beanspruchen sehr wenig Speicher. Daher sollten Sie Ihr Datenmodell so weit wie möglich in eine Hash-Tabelle abstrahieren. Wenn in Ihrem Websystem beispielsweise ein Benutzerobjekt vorhanden ist, legen Sie keinen separaten Schlüssel für den Namen, den Nachnamen, die E-Mail-Adresse und das Passwort des Benutzers fest. Speichern Sie stattdessen alle Informationen des Benutzers in einer Hash-Tabelle.
Redis-Thread-Modell
Redis hat einen Netzwerkereignisprozessor entwickelt, der auf dem Reactor-Muster basiert. Dieser Prozessor wird als Dateiereignishandler bezeichnet. Seine Struktur besteht aus 4 Teilen: mehreren Sockets, IO-Multiplexer, Dateiereignis-Dispatcher und Ereignisprozessor. Da der Verbrauch der Dateiereignis-Dispatcher-Warteschlange Single-Threaded ist, wird Redis als Single-Threaded-Modell bezeichnet.
1. Der Dateiereignisprozessor verwendet ein E/A-Multiplexprogramm, um mehrere Sockets gleichzeitig zu überwachen, und ordnet den Sockets basierend auf den aktuell von den Sockets ausgeführten Aufgaben unterschiedliche Ereignisprozessoren zu.
2. Wenn der überwachte Socket bereit ist, Vorgänge wie Verbindungsantwort (Akzeptieren), Lesen (Lesen), Schreiben (Schreiben), Schließen (Schließen) usw. auszuführen, wird das dem Vorgang entsprechende Dateiereignis generiert. , dann ruft der Datei-Ereignishandler den zuvor dem Socket zugeordneten Ereignishandler auf, um diese Ereignisse zu verarbeiten.
Obwohl der Datei-Event-Handler im Single-Thread-Modus ausgeführt wird, implementiert der Datei-Event-Handler durch die Verwendung eines E/A-Multiplexers zum Abhören mehrerer Sockets sowohl ein leistungsstarkes Netzwerkkommunikationsmodell als auch eine gute Verbindung andere Module im Redis-Server, die ebenfalls im Single-Thread-Modus ausgeführt werden, wodurch die Einfachheit des Single-Thread-Designs in Redis erhalten bleibt.
Was ist eine Transaktion?
Eine Transaktion ist eine einzelne isolierte Operation: Alle Befehle in der Transaktion werden serialisiert und der Reihe nach ausgeführt. Während der Ausführung der Transaktion wird diese nicht durch Befehlsanfragen anderer Clients unterbrochen.
Eine Transaktion ist eine atomare Operation: Entweder werden alle Befehle in der Transaktion ausgeführt, oder keiner von ihnen wird ausgeführt.
Das Konzept der Redis-Transaktion
Das Wesentliche einer Redis-Transaktion ist eine Sammlung von Befehlen wie MULTI, EXEC und WATCH. Transaktionen unterstützen die gleichzeitige Ausführung mehrerer Befehle und alle Befehle in einer Transaktion werden serialisiert. Während des Transaktionsausführungsprozesses werden die Befehle in der Warteschlange serialisiert und der Reihe nach ausgeführt, und von anderen Clients übermittelte Befehlsanforderungen werden nicht in die Befehlssequenz für die Transaktionsausführung eingefügt.
Zusammenfassend: Eine Redis-Transaktion ist eine einmalige, sequentielle und exklusive Ausführung einer Reihe von Befehlen in einer Warteschlange.
Drei Phasen von Redis-Transaktionen
1. Transaktionsstart MULTI
2. Transaktionsausführung EXEC
Während der Transaktionsausführung empfängt der Server EXEC, DISCARD und andere Anforderungen als WATCH MULTI wird in die Warteschlange gestellt.
Redis-Transaktionsbezogene Befehle in Ordnung. 1. redis unterstützt kein Rollback: „Redis führt kein Rollback durch, wenn eine Transaktion fehlschlägt, sondern führt die verbleibenden Befehle weiterhin aus“, sodass die Interna von Redis einfach und schnell bleiben können.
2.
Wenn bei einem Befehl in einer Transaktion ein Fehler auftritt, werden nicht alle Befehle ausgeführt.
3 Wenn bei einer Transaktion ein Fehler auftritt, wird der richtige Befehl ausgeführt.
Der WATCH-Befehl ist eine optimistische Sperre, die Check-and-Set-Verhalten (CAS) für Redis-Transaktionen bereitstellt. Ein oder mehrere Schlüssel können überwacht werden. Sobald einer der Schlüssel geändert (oder gelöscht) wird, werden nachfolgende Transaktionen nicht ausgeführt und die Überwachung wird bis zum EXEC-Befehl fortgesetzt. Der Befehl MULTI wird zum Starten einer Transaktion verwendet und gibt immer OK zurück. Nachdem MULTI ausgeführt wurde, kann der Client weiterhin beliebig viele Befehle an den Server senden. Diese Befehle werden nicht sofort ausgeführt, sondern in eine Warteschlange gestellt. Beim Aufruf des EXEC-Befehls werden alle Befehle in der Warteschlange ausgeführt .
EXEC: Befehle in allen Transaktionsblöcken ausführen. Gibt die Rückgabewerte aller Befehle innerhalb des Transaktionsblocks zurück, geordnet in der Reihenfolge der Befehlsausführung. Wenn der Vorgang unterbrochen wird, wird der leere Wert Null zurückgegeben. Durch Aufrufen von DISCARD kann der Client die Transaktionswarteschlange leeren und die Ausführung der Transaktion aufgeben, und der Client verlässt den Transaktionsstatus.
Der Befehl UNWATCH kann die Überwachung aller Tasten durch die Uhr abbrechen.
Überblick über das Transaktionsmanagement (ACID)
Atomizität (Atomizität) Atomizität bedeutet, dass eine Transaktion eine unteilbare Arbeitseinheit ist und alle Vorgänge in einer Transaktion stattfinden.
-
Konsistenz
Die Integrität der Daten vor und nach der Transaktion muss konsistent sein.
-
Isolation
Wenn mehrere Transaktionen gleichzeitig ausgeführt werden, sollte die Ausführung einer Transaktion keinen Einfluss auf die Ausführung anderer Transaktionen haben.
-
Dauerhaftigkeit
Dauerhaftigkeit bedeutet, dass die Änderungen an den Daten in der Datenbank dauerhaft sind, sobald eine Transaktion festgeschrieben wurde, und dass sie keine Auswirkungen haben sollten, selbst wenn die Datenbank ausfällt.
-
Redis-Transaktionen weisen immer ACID-Konsistenz und -Isolation auf, andere Funktionen werden nicht unterstützt. Transaktionen sind auch dauerhaft, wenn der Server im AOF-Persistenzmodus ausgeführt wird und der Wert der Option appendfsync immer ist. Unterstützt die Redis-Transaktion die Isolation?
Redis ist ein Einzelprozessprogramm und garantiert, dass die Transaktion beim Ausführen der Transaktion nicht unterbrochen wird und die Transaktion ausgeführt werden kann, bis alle Befehle in der Transaktionswarteschlange ausgeführt sind. Daher sind Redis-Transaktionen immer isoliert.
Garantiert die Redis-Transaktion Atomizität und unterstützt sie ein Rollback? In Redis wird ein einzelner Befehl atomar ausgeführt, aber die Transaktion garantiert keine Atomizität und es gibt kein Rollback. Wenn ein Befehl in der Transaktion nicht ausgeführt werden kann, werden die verbleibenden Befehle trotzdem ausgeführt.
Andere Implementierungen von Redis-Transaktionen
Basierend auf Lua-Skripten kann Redis sicherstellen, dass die Befehle im Skript einmal und nacheinander ausgeführt werden. Es bietet auch kein Rollback von Transaktionsoperationsfehlern nicht ordnungsgemäß ausgeführt wird, werden die verbleibenden Befehle weiterhin ausgeführt.
Basierend auf der Zwischenmarkierungsvariablen wird eine weitere Markierungsvariable verwendet, um festzustellen, ob die Transaktion abgeschlossen ist. Beim Lesen von Daten wird zunächst die Markierungsvariable gelesen, um festzustellen, ob die Transaktion abgeschlossen ist. Dafür muss jedoch zusätzlicher Code implementiert werden, was umständlicher ist.
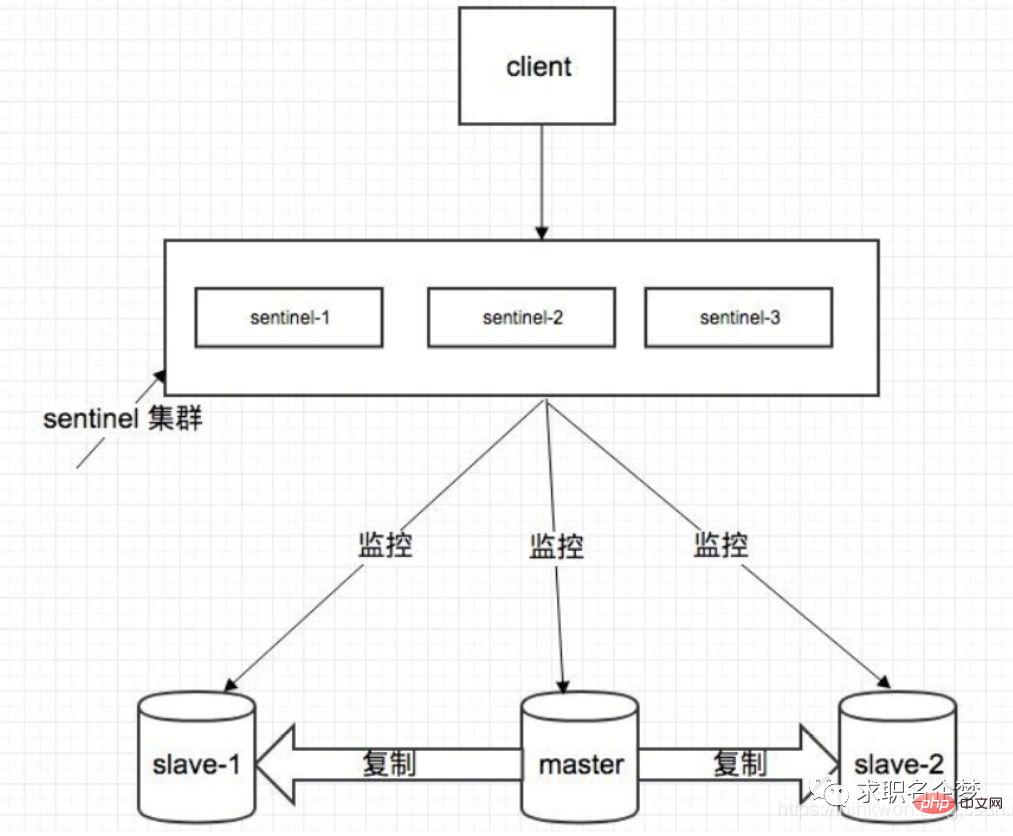
Sentinel-Modus

Einführung in Sentinel
Sentinel, der chinesische Name ist Sentinel. Sentinel ist eine sehr wichtige Komponente in der Redis-Clusterorganisation. Es hat hauptsächlich die folgenden Funktionen:
Clusterüberwachung: Verantwortlich für die Überwachung, ob die Redis-Master- und Slave-Prozesse normal funktionieren.
Nachrichtenbenachrichtigung: Wenn eine Redis-Instanz ausfällt, ist Sentinel dafür verantwortlich, Nachrichten als Alarmbenachrichtigungen an den Administrator zu senden.
Failover: Wenn der Master-Knoten hängt, wird er automatisch auf den Slave-Knoten übertragen.
Konfigurationscenter: Wenn ein Failover auftritt, benachrichtigen Sie den Client über die neue Master-Adresse.
Sentinel wird verwendet, um eine hohe Verfügbarkeit des Redis-Clusters zu erreichen. Er wird auch als Sentinel-Cluster verteilt und arbeitet zusammen.
1. Während des Failovers erfordert die Feststellung, ob ein Masterknoten ausgefallen ist, die Zustimmung der meisten Sentinels, was das Problem der verteilten Wahl beinhaltet. 2. Selbst wenn einige Sentinel-Knoten ausfallen, kann der Sentinel-Cluster weiterhin normal funktionieren, denn wenn ein Failover-System selbst, das ein wichtiger Teil des Hochverfügbarkeitsmechanismus ist, ein einzelner Punkt ist, wird es sehr frustrierend sein.
Kernkenntnisse von Sentinel
1. Um seine Robustheit sicherzustellen, sind mindestens 3 Instanzen erforderlich. 2. Die Master-Slave-Bereitstellungsarchitektur von Sentinel + Redis garantiert keinen Datenverlust, sondern nur die hohe Verfügbarkeit des Redis-Clusters. 3. Versuchen Sie für die komplexe Bereitstellungsarchitektur von Sentinel + Redis Master-Slave, ausreichende Tests und Übungen sowohl in der Testumgebung als auch in der Produktionsumgebung durchzuführen. Offizielle Redis-Cluster-Lösung (serverseitige Routing-Abfrage)
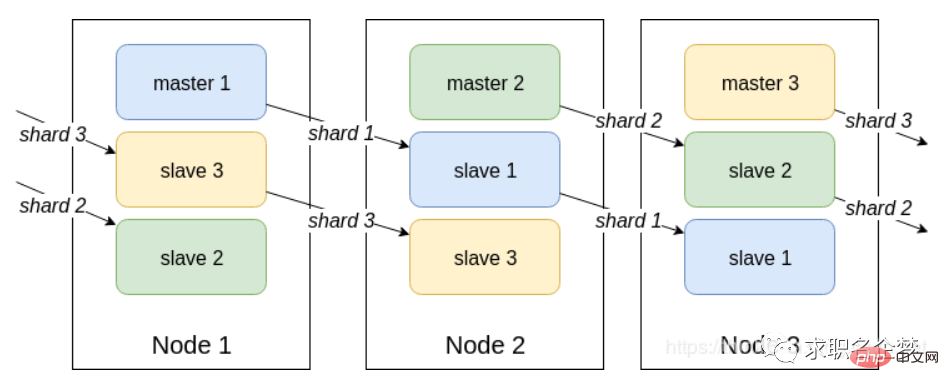
Können Sie das Funktionsprinzip des Redis-Cluster-Modus erklären? Wie wird im Cluster-Modus der Schlüssel von Redis angesprochen? Welche Algorithmen gibt es für die verteilte Adressierung? Kennen Sie den konsistenten Hash-Algorithmus?
Einführung
Redis Cluster ist eine serverseitige Sharding-Technologie, offiziell in Version 3.0 verfügbar. Redis Cluster verwendet kein konsistentes Hashing, sondern das Slot-Konzept, das insgesamt in 16384 Slots unterteilt ist. Senden Sie die Anfrage an einen beliebigen Knoten, und der Knoten, der die Anfrage empfängt, sendet die Abfrageanforderung zur Ausführung an den richtigen Knoten
Projektbeschreibung
1 Teilen Sie die Daten durch Hashing auf und speichern Sie sie gleichmäßig auf jedem Knoten Standardmäßig werden einem bestimmten Hash-Slot-Bereich (Hash-Wert) 16384 Slots zugewiesen. 2 Jedes Datenfragment wird auf mehreren Knoten gespeichert, die gegenseitig Master- und Slave-Knoten sind. Die Daten werden zuerst auf den Master-Knoten geschrieben und dann synchronisiert zum Slave-Knoten (unterstützt die Konfiguration der Blockierungssynchronisation)4. Die Datenkonsistenz zwischen mehreren Knoten im selben Shard wird nicht aufrechterhalten. Beim Lesen von Daten wird der vom Client betriebene Schlüssel nicht zugewiesen gibt den Steuerungsbefehl zurück und zeigt auf den richtigen Knoten Die Portnummer ist beispielsweise 6379 und die andere ist die Portnummer plus 1 W, z. B. 16379. Die Portnummer 16379 wird für die Kommunikation zwischen Knoten verwendet, d. h. Cluster-Bus-Kommunikation, Cluster-Bus-Kommunikation, zur Fehlererkennung, Konfigurationsaktualisierungen und Failover-Autorisierung. Der Cluster-Bus verwendet ein weiteres Binärprotokoll, das Gossip-Protokoll, für einen effizienten Datenaustausch zwischen Knoten, der weniger Netzwerkbandbreite und Verarbeitungszeit beansprucht.
Interner Kommunikationsmechanismus zwischen Knoten
Grundlegende Kommunikationsprinzipien
Es gibt zwei Möglichkeiten, Cluster-Metadaten zu verwalten: zentralisiert und Klatschprotokoll. Das Gossip-Protokoll wird für die Kommunikation zwischen Redis-Clusterknoten verwendet.
Verteilter Adressierungsalgorithmus
Hash-Algorithmus (Massen-Cache-Rekonstruktion)
Konsistenter Hash-Algorithmus (automatische Cache-Migration) + virtueller Knoten (automatischer Lastausgleich)
4 Hohe Leistung, der Client ist direkt mit dem Redis-Dienst verbunden, wodurch der Verlust des Proxy-Agenten vermieden wird
Nachteile
1 ist ein manueller Eingriff erforderlich
2. Nur Datenbank Nr. 0 kann verwendet werden
3. Verteilte Logik und Speichermodulkopplung usw.
Basierend auf der Client-Zuordnung
Einführung
Redis Sharding ist eine Clustering-Methode mit mehreren Redis-Instanzen, die in der Branche häufig verwendet wurde, bevor Redis Cluster auf den Markt kam. Die Hauptidee besteht darin, einen Hash-Algorithmus zu verwenden, um den Schlüssel von Redis-Daten zu hashen. Durch die Hash-Funktion wird ein bestimmter Schlüssel einem bestimmten Redis-Knoten zugeordnet. Der Java-Redis-Client steuert Jedis und unterstützt die Redis-Sharding-Funktion, d Jede Redis-Instanz ist wie ein einzelner Server und lässt sich sehr einfach linear erweitern. Nachteile: 1. Da die Sharding-Verarbeitung auf dem Client erfolgt Die Erweiterung des Maßstabs wird Herausforderungen für Betrieb und Wartung mit sich bringen.
2. Clientseitiges Sharding unterstützt kein dynamisches Hinzufügen und Löschen von Knoten. Wenn sich die Topologie der Redis-Instanzgruppe des Servers ändert, muss jeder Client aktualisiert und angepasst werden. Verbindungen können nicht gemeinsam genutzt werden. Ressourcenverschwendung schränkt die Optimierung ein. Leiten Sie die Anfrage an den richtigen Knoten weiter. Das Geschäftsprogramm muss sich nicht um die Back-End-Redis-Instanz kümmern, und die Umstellungskosten sind gering verloren
Branchen-Open-Source-Lösungen
1. Twtters Open-Source-Twemproxy2, Wandoujias Open-Source-Codis
Redis-Master-Slave-Architektur
Ein Einzelmaschinen-Redis kann Zehntausende QPS übertragen auf Zehntausende. Für Caches werden sie im Allgemeinen verwendet, um eine hohe Lesegleichzeitigkeit zu unterstützen. Daher ist die Architektur eine Master-Slave-Architektur mit einem Master und mehreren Slaves. Der Master ist für das Schreiben und Kopieren von Daten auf andere Slave-Knoten verantwortlich, und die Slave-Knoten sind für das Lesen verantwortlich. Alle Leseanfragen gehen an die Slave-Knoten. Dadurch kann auch problemlos eine horizontale Erweiterung erreicht und eine hohe Leseparallelität unterstützt werden.
Redis-Replikation –> Lese- und Schreibtrennung –> Horizontale Erweiterung unterstützt hohe Lese-Parallelität1 Kopieren Sie Daten auf den Slave-Knoten, aber ab redis2.8 bestätigt der Slave-Knoten regelmäßig die Datenmenge, die er kopiert.
2 Ein Master-Knoten kann mit mehreren Slave-Knoten konfiguriert werden kann sich auch mit anderen Slave-Knoten verbinden.
4. Wenn der Slave-Knoten repliziert, blockiert er nicht die normale Arbeit des Master-Knotens Der alte Datensatz wird zum Bereitstellen von Diensten verwendet. Wenn der Kopiervorgang abgeschlossen ist, muss der neue Datensatz gelöscht werden 6. Der Slave-Knoten wird hauptsächlich zur horizontalen Erweiterung und Trennung von Lesen und Schreiben verwendet. Der erweiterte Slave-Knoten kann den Lesedurchsatz verbessern. Beachten Sie, dass bei Verwendung einer Master-Slave-Architektur empfohlen wird, die Persistenz des Master-Knotens zu aktivieren. Es wird nicht empfohlen, den Slave-Knoten als Daten-Hot-Backup des Master-Knotens zu verwenden Wenn Sie in diesem Fall die Persistenz des Masters deaktivieren, kann der Master-Knoten beschädigt werden. Wenn die Maschine abstürzt und neu startet, sind die Daten leer und die Daten des Slave-Knotens gehen möglicherweise verloren, sobald sie repliziert werden.
Darüber hinaus müssen auch verschiedene Backup-Pläne für den Master erstellt werden. Falls alle lokalen Dateien verloren gehen, wählen Sie eine RDB aus der Sicherung aus, um den Master wiederherzustellen. Dadurch wird sichergestellt, dass beim Start Daten vorhanden sind. Auch wenn der später erläuterte Hochverfügbarkeitsmechanismus übernommen wird, kann der Slave-Knoten automatisch den Master übernehmen Es ist jedoch auch möglich, dass der Master-Knoten automatisch neu gestartet wurde, bevor Sentinel den Master-Fehler erkennt, oder dass alle oben genannten Slave-Knotendaten gelöscht werden.
Das Kernprinzip der Redis-Master-Slave-Replikation
Wenn ein Slave-Knoten gestartet wird, sendet er einen PSYNC-Befehl an den Master-Knoten. Wenn dies das erste Mal ist, dass der Slave-Knoten eine Verbindung zum Master-Knoten herstellt, wird eine vollständige Neusynchronisierung und vollständige Kopie ausgelöst. Zu diesem Zeitpunkt startet der Master einen Hintergrundthread und beginnt mit der Generierung einer RDB-Snapshot-Datei. Gleichzeitig werden alle vom Client neu empfangenen Schreibbefehle im Speicher zwischengespeichert. Nachdem die RDB-Datei generiert wurde, sendet der Master die RDB zunächst auf die lokale Festplatte und lädt sie dann von der lokalen Festplatte in den Speicher. Anschließend sendet der Master den zwischengespeicherten Schreibbefehl Der Speicher des Slaves wird ebenfalls synchronisiert.
Wenn ein Netzwerkfehler zwischen dem Slave-Knoten und dem Master-Knoten auftritt und die Verbindung getrennt wird, wird die Verbindung automatisch wiederhergestellt. Nach dem Herstellen der Verbindung kopiert der Master-Knoten nur die fehlenden Daten auf den Slave.
Prozessprinzip
1. Wenn die MS-Beziehung zwischen der Slave-Bibliothek und der Hauptbibliothek hergestellt ist, wird der SYNC-Befehl an die Hauptdatenbank gesendet
2 Nach dem Empfang des SYNC-Befehls beginnt die Hauptbibliothek, Snapshots im Hintergrund zu speichern (RDB-Persistenzprozess) und empfängt die Schreibbefehle zwischengespeichert
3. Wenn der Snapshot abgeschlossen ist, sendet der Master-Redis die Snapshot-Datei und alle zwischengespeicherten Schreibbefehle an den Slave-Redis
4 Redis lädt die Snapshot-Datei und führt die empfangenen zwischengespeicherten Befehle aus Die gesamte Datenreplikation und -synchronisierung des Slave-Knotens erfolgt durch die Verarbeitung des Master-Knotens. Dies führt dazu, dass der Master-Knoten zu stark belastet wird. Verwenden Sie die Master-Slave-Struktur, um das Problem zu lösen Cluster?
Um den Cluster weiterhin verfügbar zu machen, wenn einige Knoten ausfallen oder die meisten Knoten nicht kommunizieren können, verwendet der Cluster ein Master-Slave-Replikationsmodell und jeder Knoten verfügt über N-1-Replikate. Redis in der Produktionsumgebung Wie ist das? es eingesetzt?
Redis-Cluster, 10 Maschinen, 5 Maschinen werden mit Redis-Master-Instanzen bereitgestellt, und die anderen 5 Maschinen werden mit Redis-Slave-Instanzen bereitgestellt, und 5 Knoten stellen externe Lese- und Schreibdienste bereit Die Schreibspitzen-QPS eines Knotens kann 50.000 pro Sekunde erreichen, und die maximale Lese- und Schreibanfrage/s für 5 Maschinen beträgt 250.000. Wie ist die Konfiguration der Maschine? 32G Speicher + 8-Kern-CPU + 1T-Festplatte, aber der dem Redis-Prozess zugewiesene Speicher beträgt 10 g. In allgemeinen Online-Produktionsumgebungen sollte der Speicher von Redis 10 g nicht überschreiten. 5 Maschinen ermöglichen externes Lesen und Schreiben mit insgesamt 50 g Speicher.
Da jede Master-Instanz über eine Slave-Instanz verfügt, ist sie hochverfügbar. Wenn eine Master-Instanz ausfällt, erfolgt automatisch ein Failover und die Redis-Slave-Instanz wird automatisch zur Master-Instanz und stellt weiterhin Lese- und Schreibdienste bereit.
Welche Daten schreibst du in den Speicher? Wie groß ist jedes Datenelement? Produktdaten, jedes Datenelement ist 10 KB groß. 100 Daten sind 1 MB und 100.000 Daten sind 1 g. Im Speicher befinden sich 2 Millionen Produktdaten, und der belegte Speicher beträgt 20 g, was nur weniger als 50 % des gesamten Speichers ausmacht. Die aktuelle Spitzenzeit liegt bei etwa 3.500 Anfragen pro Sekunde.
Tatsächlich verfügen große Unternehmen über ein Infrastrukturteam, das für den Betrieb und die Wartung des Cache-Clusters verantwortlich ist.
Sprechen Sie über das Konzept des Redis-Hash-Slots?
Der Redis-Cluster verwendet kein konsistentes Hashing, sondern führt das Konzept der Hash-Slots ein. Jeder Schlüssel wird von CRC16 überprüft und Modulo 16384 wird verwendet, um zu bestimmen, welcher Slot verantwortlich ist für einen Teil des Hash-Slots.
Wird der Redis-Cluster Schreibvorgänge verlieren? Warum?
Redis garantiert keine starke Datenkonsistenz, was bedeutet, dass der Cluster in der Praxis unter bestimmten Bedingungen Schreibvorgänge verlieren kann.
Wie werden Redis-Cluster repliziert?
Asynchrone Replikation
Was ist die maximale Anzahl von Knoten in einem Redis-Cluster?
16384
Wie wähle ich eine Datenbank für den Redis-Cluster aus?
Der Redis-Cluster kann derzeit keine Datenbank auswählen und ist standardmäßig auf Datenbank 0 eingestellt.
Redis ist Single-Threaded. Wie kann die Auslastung der Multi-Core-CPU verbessert werden?
Sie können mehrere Redis-Instanzen auf demselben Server bereitstellen und diese als unterschiedliche Server verwenden. Irgendwann reicht ein Server ohnehin nicht aus. Wenn Sie also mehrere CPUs verwenden möchten, können Sie Sharding in Betracht ziehen.
Warum benötigen Sie eine Redis-Partitionierung?
Partitionierung ermöglicht es Redis, größeren Speicher zu verwalten, und Redis kann den Speicher aller Maschinen nutzen. Ohne Partitionen können Sie nur den Arbeitsspeicher einer Maschine nutzen. Durch die Partitionierung lässt sich die Rechenleistung von Redis durch einfaches Hinzufügen von Computern verdoppeln, und auch die Netzwerkbandbreite von Redis erhöht sich durch das Hinzufügen von Computern und Netzwerkkarten exponentiell.
Wissen Sie, welche Redis-Partitionsimplementierungslösungen verfügbar sind?
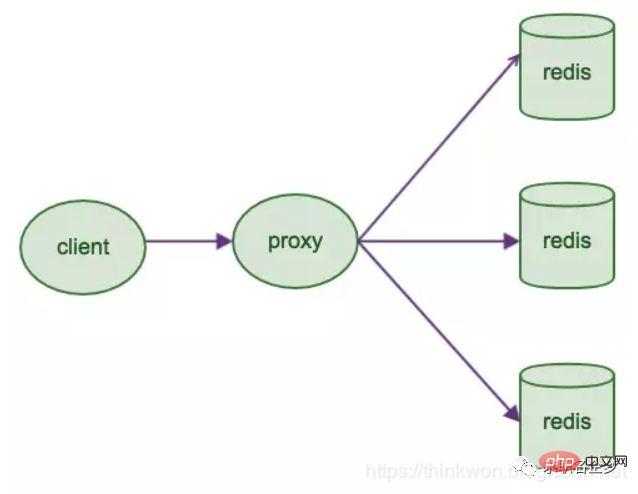
1. Clientseitige Partitionierung bedeutet, dass der Client bereits entschieden hat, in welchem Redis-Knoten die Daten gespeichert oder von diesem gelesen werden. Die meisten Clients implementieren bereits eine clientseitige Partitionierung.
2. Agent-Partitionierung bedeutet, dass der Client die Anfrage an den Agenten sendet und der Agent dann entscheidet, auf welchen Knoten er Daten schreibt oder liest. Der Agent entscheidet anhand der Partitionsregeln, welche Redis-Instanzen angefordert werden sollen, und gibt sie dann basierend auf den Redis-Antwortergebnissen an den Client zurück. Eine Proxy-Implementierung für Redis und Memcached ist Twemproxy.
3. Abfragerouting bedeutet, dass der Client zufällig eine beliebige Redis-Instanz anfordert und Redis die Anfrage dann an den richtigen Redis-Knoten weiterleitet. Redis Cluster implementiert eine Hybridform des Abfrageroutings, aber anstatt Anforderungen direkt von einem Redis-Knoten an einen anderen Redis-Knoten weiterzuleiten, leitet es mit Hilfe des Clients direkt an den richtigen Redis-Knoten weiter.
Was sind die Nachteile der Redis-Partitionierung?
1. Operationen mit mehreren Schlüsseln werden normalerweise nicht unterstützt. Beispielsweise können Sie zwei Sammlungen nicht überschneiden, da sie möglicherweise in verschiedenen Redis-Instanzen gespeichert sind (eigentlich gibt es für diese Situation eine Möglichkeit, aber der Schnittbefehl kann nicht direkt verwendet werden).
2. Wenn Sie mehrere Schlüssel gleichzeitig bedienen, können Sie keine Redis-Transaktionen verwenden.
3. Die Partitionierungsgranularität ist der Schlüssel, daher ist es nicht möglich, einen Datensatz wie einen sehr großen sortierten Satz zu fragmentieren.
4. Bei der Verwendung von Partitionen ist die Datenverarbeitung sehr kompliziert. Für die Sicherung müssen Sie gleichzeitig RDB/AOF-Dateien von verschiedenen Redis-Instanzen und Hosts sammeln.
5. Die dynamische Expansion oder Kontraktion während der Partitionierung kann sehr kompliziert sein. Der Redis-Cluster fügt zur Laufzeit Redis-Knoten hinzu oder löscht sie, wodurch eine für Benutzer weitgehend transparente Datenverteilung erreicht werden kann. Einige andere Client-Partitionierungs- oder Proxy-Partitionierungsmethoden unterstützen diese Funktion jedoch nicht. Allerdings gibt es eine Pre-Sharding-Technologie, die dieses Problem ebenfalls besser lösen kann.
Redis implementiert verteilte Sperren
Redis ist ein Einzelprozess-Single-Thread-Modus. Es verwendet den Warteschlangenmodus, um den gleichzeitigen Zugriff in seriellen Zugriff umzuwandeln, und es kann keine Konkurrenz zwischen den Verbindungen mehrerer Clients zu Redis geben Wird im Redis-Befehl zur Implementierung einer verteilten Sperre verwendet.
Wenn und nur wenn der Schlüssel nicht vorhanden ist, setzen Sie den Wert des Schlüssels auf „Wert“. Wenn der angegebene Schlüssel bereits existiert, ergreift SETNX keine Aktion
SETNX ist die Abkürzung für „SET if Not eXists“ (wenn er nicht existiert, dann SET).
Rückgabewert: Erfolgreich gesetzt, Rückgabe 1. Das Setup schlägt fehl und gibt 0 zurück.
Der Prozess und die Dinge bei der Verwendung von SETNX zum Abschließen der Synchronisationssperre sind wie folgt:
Verwenden Sie den SETNX-Befehl, um die Sperre zu erhalten. Wenn 0 zurückgegeben wird (der Schlüssel ist bereits vorhanden, ist die Sperre bereits vorhanden), andernfalls schlägt die Erfassung fehl Der Erwerb ist erfolgreich.
Um Programmausnahmen nach dem Erwerb der Sperre zu verhindern, die dazu führen, dass andere Threads/Prozesse beim Aufrufen des SETNX-Befehls immer 0 zurückgeben und in einen Deadlock-Zustand gelangen, müssen Sie eine „angemessene“ Ablaufzeit dafür festlegen Schlüssel
Entfernen Sie die Sperre und löschen Sie die Sperrdaten mit dem Befehl DEL
So lösen Sie das Problem des gleichzeitigen Wettbewerbs um Schlüssel in Redis.
Das sogenannte Problem des gleichzeitigen Wettbewerbs um Schlüssel in Redis besteht darin, dass mehrere Systeme vorhanden sind Betreiben Sie gleichzeitig eine Taste, aber die endgültige Ausführungsreihenfolge unterscheidet sich von der erwarteten Reihenfolge, was zu unterschiedlichen Ergebnissen führt!
Empfehlen Sie eine Lösung: verteilte Sperre (sowohl Zookeeper als auch Redis können verteilte Sperren implementieren). (Wenn es in Redis keine gleichzeitige Konkurrenz für Key gibt, verwenden Sie keine verteilten Sperren, da dies die Leistung beeinträchtigt.)
Verteilte Sperren basierend auf den vorübergehend geordneten Knoten des Zookeepers. Die allgemeine Idee ist: Wenn jeder Client eine bestimmte Methode sperrt, wird im Verzeichnis des angegebenen Knotens, der der Methode auf zookeeper entspricht, ein eindeutiger, sofort geordneter Knoten generiert. Die Bestimmung, ob eine Sperre erworben werden soll, ist sehr einfach. Sie müssen lediglich die kleinste Sequenznummer unter den geordneten Knoten ermitteln. Wenn die Sperre aufgehoben wird, löschen Sie einfach den Übergangsknoten. Gleichzeitig können Deadlock-Probleme vermieden werden, die durch Sperren verursacht werden, die aufgrund von Dienstausfallzeiten nicht freigegeben werden können. Löschen Sie nach Abschluss des Geschäftsprozesses den entsprechenden untergeordneten Knoten, um die Sperre aufzuheben.
In der Praxis steht natürlich die Zuverlässigkeit an erster Stelle. Daher wird zunächst Zookeeper empfohlen.
Sollte verteiltes Redis in der frühen Phase oder in der späteren Phase erfolgen, wenn der Umfang erhöht wird? Warum?
Da Redis so leichtgewichtig ist (eine einzelne Instanz benötigt nur 1 MB Speicher), besteht der beste Weg, zukünftige Erweiterungen zu verhindern, darin, weitere Instanzen von Anfang an zu starten. Selbst wenn Sie nur einen Server haben, können Sie Redis von Anfang an verteilt ausführen und dabei Partitionen verwenden, um mehrere Instanzen auf demselben Server zu starten.
Richten Sie zu Beginn ein paar weitere Redis-Instanzen ein, beispielsweise 32 oder 64 Instanzen. Dies mag für die meisten Benutzer mühsam sein, aber auf lange Sicht lohnt es sich.
In diesem Fall, wenn Ihre Daten weiter wachsen und Sie mehr Redis-Server benötigen, müssen Sie lediglich die Redis-Instanz von einem Dienst auf einen anderen Server migrieren (ohne das Problem der Neupartitionierung zu berücksichtigen). Sobald Sie einen weiteren Server hinzufügen, müssen Sie die Hälfte Ihrer Redis-Instanzen von der ersten Maschine auf die zweite Maschine migrieren.
Was ist RedLock
Die offizielle Redis-Website hat eine maßgebliche Methode zur Implementierung verteilter Sperren basierend auf Redlock namens Redlock vorgeschlagen. Diese Methode ist sicherer als die ursprüngliche Einzelknotenmethode. Es kann die folgenden Funktionen garantieren:
1. Sicherheitsfunktionen: sich gegenseitig ausschließender Zugriff, d. h. nur ein Client kann immer die Sperre erhalten.
2 Deadlock vermeiden: Am Ende können alle Clients die Sperre erhalten Es kommt zu keinem Deadlock, auch wenn der Client, der ursprünglich eine Ressource gesperrt hat, abstürzt oder eine Netzwerkpartition auftritt. Fehlertoleranz: Solange die meisten Redis-Knoten bestehen, können Dienste normal bereitgestellt werden
Cache-Lawine
Cache-Lawine bezieht sich auf den gleichzeitigen großflächigen Ausfall des Caches. Daher fallen nachfolgende Anfragen auf die Datenbank, was dazu führt, dass die Datenbank einer großen Anzahl von Anfragen in kurzer Zeit standhält von Zeit und Zusammenbruch.
Lösung
1. Stellen Sie die Ablaufzeit der zwischengespeicherten Daten zufällig ein, um zu verhindern, dass eine große Anzahl von Daten gleichzeitig abläuft.
2. Wenn der Umfang der Parallelität nicht besonders groß ist, ist Sperren und Warteschlangen die am häufigsten verwendete Lösung.
3. Fügen Sie zu allen zwischengespeicherten Daten ein entsprechendes Cache-Tag hinzu und notieren Sie, ob der Cache ungültig ist. Aktualisieren Sie den Datencache.
Cache-Penetration
Cache-Penetration bezieht sich auf Daten, die sich weder im Cache noch in der Datenbank befinden, wodurch alle Anforderungen auf die Datenbank fallen, wodurch die Datenbank in kurzer Zeit einer großen Anzahl von Anforderungen standhalten kann Zeit und Zusammenbruch.
Lösung
1. Fügen Sie die Überprüfung auf der Schnittstellenebene hinzu, z. B. die Überprüfung der Benutzerauthentifizierung, das direkte Abfangen der ID.
2 Zu diesem Zeitpunkt kann das Schlüssel-Wert-Paar auch als Schlüssel-Null geschrieben werden. Die Cache-Gültigkeitszeit kann kürzer eingestellt werden, z. B. 30 Sekunden (eine zu lange Einstellung führt dazu, dass sie im Normalfall unbrauchbar ist). Umstände). Dies kann verhindern, dass angreifende Benutzer wiederholt dieselbe ID für Brute-Force-Angriffe verwenden.
3 Um alle möglichen Daten in eine ausreichend große Bitmap umzuwandeln, werden diese abgefangen Vermeidung von Abfragedruck auf das zugrunde liegende Speichersystem.
Zusätzlich
hat ein extremes Maß an Raumausnutzung erreicht, nämlich Bitmap und Bloom-Filter.
Bitmap: Das typische ist die Hash-Tabelle
Der Nachteil ist, dass Bitmap nur 1 Bit an Informationen für jedes Element aufzeichnen kann. Wenn Sie zusätzliche Funktionen ausführen möchten, können Sie dies leider nur erreichen, indem Sie mehr opfern Raum und Zeit.
Bloom-Filter (empfohlen)
führt k(k>1)k(k>1) unabhängige Hash-Funktionen ein, um sicherzustellen, dass die Elemente innerhalb eines bestimmten Raums und einer bestimmten Fehleinschätzungsrate vervollständigt werden. Der Prozess der Beurteilung.
Sein Vorteil besteht darin, dass die Speicherplatzeffizienz und die Abfragezeit weitaus höher sind als beim allgemeinen Algorithmus. Sein Nachteil besteht darin, dass er eine gewisse Fehlerkennungsrate und Schwierigkeiten beim Löschen aufweist.
Die Kernidee des Bloom-Filter-Algorithmus besteht darin, mehrere verschiedene Hash-Funktionen zu verwenden, um „Konflikte“ zu lösen.
Hash hat ein Konfliktproblem (Kollisionsproblem), und die Werte zweier URLs, die unter Verwendung desselben Hashs erhalten werden, können gleich sein. Um Konflikte zu reduzieren, können wir mehrere weitere Hashes einführen. Wenn wir anhand eines der Hashwerte schließen, dass ein Element nicht in der Menge ist, dann ist das Element definitiv nicht in der Menge. Nur wenn alle Hash-Funktionen uns mitteilen, dass das Element in der Menge vorhanden ist, können wir sicher sein, dass das Element in der Menge vorhanden ist. Dies ist die Grundidee von Bloom-Filter.
Bloom-Filter wird im Allgemeinen verwendet, um festzustellen, ob ein Element in einem großen Datensatz vorhanden ist.
Cache-Aufschlüsselung
Cache-Aufschlüsselung bezieht sich auf Daten, die sich nicht im Cache, sondern in der Datenbank befinden (normalerweise, wenn die Cache-Zeit zu diesem Zeitpunkt abläuft, da die Anzahl der gleichzeitigen Benutzer groß ist). wird nicht gleichzeitig in den Cache gelesen. Gleichzeitig wird die Datenbank zum Abrufen von Daten aufgerufen, was dazu führt, dass der Druck auf die Datenbank sofort zunimmt, was zu übermäßigem Druck führt. Im Gegensatz zur Cache-Lawine bezieht sich die Cache-Aufschlüsselung auf die gleichzeitige Abfrage derselben Daten. Cache-Lawine bedeutet, dass unterschiedliche Daten abgelaufen sind und viele Daten nicht gefunden werden können, sodass die Datenbank durchsucht wird.
Lösung
1. Stellen Sie die Hotspot-Daten so ein, dass sie nie ablaufen direkt in das Cache-System geladen. Auf diese Weise können Sie das Problem vermeiden, zuerst die Datenbank abzufragen und dann die Daten zwischenzuspeichern, wenn der Benutzer sie anfordert! Benutzer fragen direkt zwischengespeicherte Daten ab, die vorgewärmt wurden!
Lösung1. Schreiben Sie direkt eine Cache-Aktualisierungsseite und führen Sie diese manuell durch. 2. Die Datenmenge ist nicht groß und kann automatisch geladen werden regelmäßig zwischenspeichern;
Cache-Downgrade
Wenn der Datenverkehr stark ansteigt, Dienstprobleme auftreten (z. B. langsame Reaktionszeit oder keine Antwort) oder nicht zum Kerngeschäft gehörende Dienste die Leistung von Kernprozessen beeinträchtigen, müssen Sie dennoch sicherstellen dass der Dienst auch bei Beeinträchtigung des Dienstes weiterhin verfügbar ist. Das System kann basierend auf einigen Schlüsseldaten automatisch ein Downgrade durchführen oder Switches konfigurieren, um ein manuelles Downgrade durchzuführen.
Das ultimative Ziel des Cache-Downgrades besteht darin, sicherzustellen, dass Kerndienste verfügbar sind, auch wenn sie verlustbehaftet sind. Und einige Dienste können nicht herabgestuft werden (z. B. Hinzufügen zum Warenkorb, Bezahlen).
Vor dem Herabstufen müssen Sie das System sortieren, um zu sehen, ob das System Soldaten verlieren und Kommandeure behalten kann. Dabei können Sie herausfinden, was bis zum Tod geschützt werden muss und was herabgestuft werden kann Einstellungsplan:
1. Allgemein: Einige Dienste treten aufgrund von Netzwerkschwankungen gelegentlich auf und werden automatisch heruntergestuft. 2. B. zwischen 95 und 100 % und kann automatisch oder manuell herabgestuft werden und einen Alarm senden. 3 Fehler: Beispielsweise liegt die Verfügbarkeitsrate unter 90 % oder der Datenbankverbindungspool ist aufgelöst. oder die Anzahl der Besuche steigt plötzlich auf den maximalen Schwellenwert, den das System ertragen kann. Dies kann je nach Situation automatisch oder manuell herabgestuft werden
4. Schwerwiegender Fehler: Wenn die Daten beispielsweise aus besonderen Gründen falsch sind, ist ein manuelles Notfall-Downgrade erforderlich.
Der Zweck des Dienst-Downgrades besteht darin, zu verhindern, dass ein Ausfall des Redis-Dienstes Lawinenprobleme in der Datenbank verursacht. Daher kann für unwichtige zwischengespeicherte Daten eine Service-Downgrade-Strategie angewendet werden. Ein gängiger Ansatz besteht beispielsweise darin, dass bei einem Problem mit Redis die Datenbank nicht abgefragt wird, sondern direkt der Standardwert an den Benutzer zurückgegeben wird. „Heiße Daten und kalte Daten“ hat aber auch einen Wert, der nicht groß ist. Bei häufig geänderten Daten sollten Sie je nach Situation die Verwendung eines Caches in Betracht ziehen.
Bei wichtigen Daten wie einem unserer IM-Produkte, einem Geburtstagsgrußmodul und einer Geburtstagsliste des Tages kann der Cache Hunderttausende Male gelesen werden. Ein weiteres Beispiel: In einem Navigationsprodukt speichern wir Navigationsinformationen zwischen und lesen sie möglicherweise in Zukunft millionenfach. Cache macht nur dann Sinn, wenn die Daten vor der Aktualisierung mindestens zweimal gelesen werden. Dies ist die grundlegendste Strategie, wenn der Cache ausfällt, bevor er wirksam wird. Was ist mit dem Szenario, in dem der Cache nicht vorhanden ist und die Änderungshäufigkeit sehr hoch ist, aber Caching in Betracht gezogen werden muss? haben! Diese Leseschnittstelle übt beispielsweise großen Druck auf die Datenbank aus, es handelt sich jedoch auch um heiße Daten. Zu diesem Zeitpunkt müssen Caching-Methoden in Betracht gezogen werden, um den Druck auf die Datenbank zu verringern, z. B. die Anzahl der Likes, Sammlungen usw Anteile eines unserer Assistentenprodukte sind sehr typische Hot-Daten, die sich jedoch ständig ändern. Zu diesem Zeitpunkt müssen die Daten synchron im Redis-Cache gespeichert werden, um den Druck auf die Datenbank zu verringern.
Cache-Hotspot-Schlüssel
Ein Schlüssel im Cache (z. B. ein Werbeartikel) läuft zu einem bestimmten Zeitpunkt ab und es gibt zu diesem Zeitpunkt eine große Anzahl gleichzeitiger Anfragen für diesen Schlüssel Anfragen finden Wenn der Cache abläuft, werden die Daten normalerweise aus der Back-End-Datenbank geladen und in den Cache zurückgesetzt. Zu diesem Zeitpunkt können große gleichzeitige Anforderungen die Back-End-Datenbank sofort überlasten.
Lösung Sperren Sie die Cache-Abfrage, sperren Sie sie, überprüfen Sie die Datenbank im Cache und entsperren Sie sie. Warten Sie, ob sie eine Sperre finden, und geben Sie dann die Daten zurück Geben Sie nach dem Entsperren von Query die Datenbank ein
Gemeinsame Tools
Welche Java-Clients werden von Redis unterstützt? Welches wird offiziell empfohlen?
Redisson, Jedis, Salat usw., die offizielle Empfehlung ist die Verwendung von Redisson.
Welche Beziehung besteht zwischen Redis und Redisson?
Redisson ist ein erweiterter Redis-Client für verteilte Koordination, der Benutzern dabei helfen kann, einige Java-Objekte (Bloom-Filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap), Queue, BlockingQueue einfach in einer verteilten Umgebung zu implementieren , Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish/Subscribe, HyperLogLog).
Was sind die Vor- und Nachteile von Jedis und Redisson?
Jedis ist ein in Java implementierter Client für Redis. Seine API implementiert eine verteilte und skalierbare Java-Datenstruktur, seine Funktionen sind einfacher und unterstützen keine Zeichenkettenoperationen Unterstützt keine Redis-Funktionen wie Sortierung, Transaktionen, Pipelines und Partitionen. Der Zweck von Redisson besteht darin, die Trennung der Benutzeranliegen von Redis zu fördern, sodass sich Benutzer mehr auf die Verarbeitung der Geschäftslogik konzentrieren können.
Andere Fragen
Der Unterschied zwischen Redis und Memcached
Beide sind nicht relationale Speicher-Schlüsselwertdatenbanken. Heutzutage verwenden Unternehmen im Allgemeinen Redis, um Caching zu implementieren, und Redis selbst wird immer leistungsfähiger . ! Die Hauptunterschiede zwischen Redis und Memcached sind wie folgt:
Vergleichsparameter
|
redis |
memcached |
| Speicher 2. Nicht relationale Datenbank |
1 2. Schlüssel-Wert-Paar Form 3. Cache-Formular |
|
Datenspeichertyp
| 1. Liste 3. Satz 4. Hash 5. Sortiersatz [allgemein bekannt als ZSet] |
1. Texttyp 2. Binärtyp |
|
Abfrage [Operation ] Typ
| 1. Stapelbetrieb 2. Transaktionsunterstützung 3. Unterschiedliches CRUD für jeden Typ |
1. Häufig verwendetes CRUD 2. Eine kleine Anzahl anderer Befehle |
1. Veröffentlichungs-/Abonnementmodus 2. Master-Slave-Partition 3. Serialisierungsunterstützung 4. Skriptunterstützung [Lua-Skript] |
1. Multithread-Dienstunterstützung
|
Netzwerk-IO-Modell |
Single-Threaded-Mehrkanal-IO-Wiederverwendungsmodell |
1. Threaded, nicht blockierender IO-Modus |
Event-Bibliothek |
| AeEvent
LibEvent
|
Persistenzunterstützung |
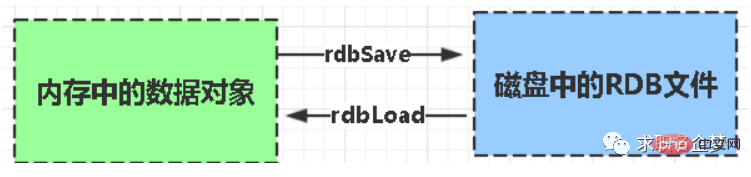
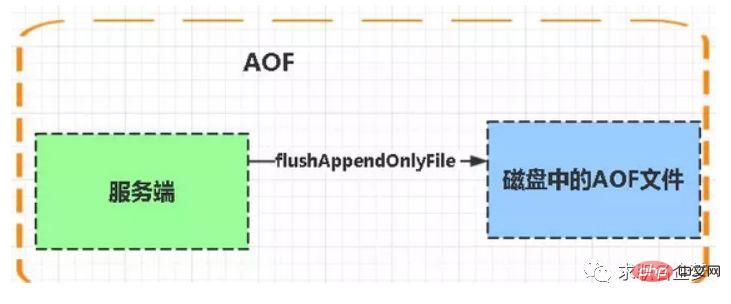
| 1. RDB 2. AOF
Nicht unterstützt
|
| Cluster-Modus
| Nativ Unterstützt den Cluster-Modus, Sie können Master-Slave-Replikation und Lese-/Schreib-Trennung realisieren
Es gibt keinen nativen Cluster-Modus, Sie müssen sich darauf verlassen, dass der Client Daten in Shards im Cluster schreibt
|
Speicherverwaltungsmechanismus |
| In Redis werden nicht alle Daten immer im Speicher gespeichert, und einige Werte, die längere Zeit nicht verwendet wurden, können auf der Festplatte ausgetauscht werden. Memcached-Daten werden immer im Speicher gespeichert in Blöcke bestimmter Längen zum Speichern von Daten, um das Problem der Speicherfragmentierung vollständig zu lösen. Diese Methode führt jedoch zu einer geringen Speicherauslastung. Wenn die Blockgröße beispielsweise 128 Byte beträgt und nur 100 Byte Daten gespeichert werden, werden die restlichen 28 Byte verschwendet.
Anwendbare Szenarien |
| Komplexe Datenstruktur, Persistenz, hohe Verfügbarkeitsanforderungen, großer Speicherinhalt |
Reiner Schlüsselwert, sehr große Datenmenge, sehr großes Parallelitätsgeschäft
|
(1) Alle Werte in Memcached sind einfache Zeichenfolgen. Als Ersatz unterstützt Redis umfangreichere Datentypen. (2) Redis ist viel schneller als Memcached. (3) Redis kann seine Daten beibehalten. So stellen Sie die Datenkonsistenz beim doppelten Schreiben sicher zwischen Cache und Datenbank?
|
Solange Sie den Cache verwenden, kann es zu doppelter Speicherung und doppeltem Schreiben von Cache und Datenbank kommen. Solange Sie doppeltes Schreiben verwenden, wird es definitiv Probleme mit der Datenkonsistenz geben. |
Wenn Ihr System nicht unbedingt eine Konsistenz des Caches und der Datenbank erfordert, ist es am besten, diese Lösung nicht zu serialisieren In eine Speicherwarteschlange gestellt, um sicherzustellen, dass es nach der Serialisierung nicht zu Inkonsistenzen kommt, wird der Durchsatz des Systems erheblich reduziert und es werden um ein Vielfaches mehr Maschinen verwendet als unter normalen Umständen.
Es gibt eine andere Möglichkeit, bei der vorübergehende Inkonsistenzen auftreten können, aber die Wahrscheinlichkeit des Auftretens ist sehr gering: Aktualisieren Sie zuerst die Datenbank und löschen Sie dann den Cache
.
Problem -Szenario
Description
Solution
First den Cache schreiben und dann in die Datenbank schreiben, der Cache -Schreiben ist erfolgreich, die Datenbankschreibfehler fehl , aber das Schreiben in die Datenbank schlägt fehl oder wenn die Antwort verzögert wird, erfolgt beim nächsten Lesen des Caches ein Dirty Read (gleichzeitiges Lesen). Diese Methode zum Schreiben des Caches ist an sich falsch Zuerst in die Datenbank schreiben und den alten Cache ungültig machen. Wenn der Cache zu diesem Zeitpunkt nicht vorhanden ist, lesen Sie die Datenbank und schreiben Sie dann in den Cache. Schreiben Sie zuerst in die Datenbank und dann in den Cache erfolgreich, aber das Schreiben in den Cache schlägt fehl
Der Schreibvorgang in die Datenbank ist erfolgreich, aber das Schreiben in den Cache schlägt fehl. Lesen Sie dann das nächste Mal (beim gleichzeitigen Lesen) den Cache, die Daten können nicht gelesen werden
Wenn der Cache verwendet wird, Wenn der Lesecache fehlschlägt, wird die Datenbank zuerst gelesen und dann in den Cache zurückgeschrieben. Die Implementierung erfordert eine asynchrone Cache-Aktualisierung.
| bezieht sich auf den Datenbankvorgang und den Schreibcache Der Cache kann nicht gleichzeitig geschrieben werden oder es ist eine asynchrone Aktualisierung erforderlich (Abhilfemaßnahmen). Bestimmen Sie, welche Daten für solche Szenarien geeignet sind. Bestimmen Sie eine angemessene Dateninkonsistenzzeit basierend auf Erfahrungswerten und aktualisieren Sie die Benutzerdaten im Zeitintervall |
Redis häufige Leistungsprobleme und Lösungen?
1. Master sollte am besten keine Persistenzarbeiten durchführen, einschließlich Speicher-Snapshots und AOF-Protokolldateien, insbesondere keine Speicher-Snapshots für die Persistenz aktivieren.
2. Wenn die Daten kritisch sind, aktiviert ein Slave die AOF-Datensicherung und die Strategie besteht darin, einmal pro Sekunde zu synchronisieren.
3. Für die Geschwindigkeit der Master-Slave-Replikation und die Stabilität der Verbindung ist es am besten, wenn sich Slave und Master im selben LAN befinden.
4. Vermeiden Sie das Hinzufügen von Slave-Bibliotheken zur überlasteten Hauptbibliothek.
5. Der Master-Aufruf zum Neuschreiben der AOF-Datei führt zu einer hohen Auslastung des Dienstes hoch. Es kommt zu einer kurzen Dienstunterbrechung.
6. Um die Stabilität des Masters zu gewährleisten, verwenden Sie keine Diagrammstruktur für die Master-Slave-Replikation. Es ist stabiler, eine einseitig verknüpfte Listenstruktur zu verwenden, das heißt, die Master-Slave-Beziehung ist: Master<–. Slave1<–Slave2<–Slave3…. Diese Struktur ist auch praktisch, um das Single-Point-of-Failure-Problem zu lösen und den Master durch den Slave zu ersetzen. alles andere unverändert lassen.
Warum stellt Redis offiziell keine Windows-Version zur Verfügung?
Da die aktuelle Linux-Version recht stabil ist und eine große Anzahl von Benutzern hat, besteht keine Notwendigkeit, eine Windows-Version zu entwickeln, was zu Kompatibilitäts- und anderen Problemen führen würde.
Was ist die maximale Kapazität, die ein String-Typ-Wert speichern kann?
512M
Wie führt Redis große Datenmengen ein?
Ab Redis 2.6 unterstützt redis-cli einen neuen Modus namens Pipe-Modus für die Durchführung großer Datenmengen.
Angenommen, es gibt 100 Millionen Schlüssel in Redis und 100.000 davon beginnen mit einem festen, bekannten Präfix. Wie findet man sie alle?
Verwenden Sie den Befehl „keys“, um die Schlüsselliste des angegebenen Musters zu scannen.
Die andere Partei fragte dann: Wenn dieser Redis Dienste für Online-Unternehmen bereitstellt, welche Probleme gibt es bei der Verwendung des Tastenbefehls?
Zu diesem Zeitpunkt müssen Sie eine Schlüsselfunktion von Redis beantworten: das Single-Threading von Redis. Die Schlüsselanweisung führt dazu, dass der Thread für einen bestimmten Zeitraum blockiert wird und der Onlinedienst angehalten wird. Der Dienst kann erst wiederhergestellt werden, wenn die Anweisung ausgeführt wird. Zu diesem Zeitpunkt können Sie den Scan-Befehl verwenden, um die Schlüsselliste des angegebenen Modus zu extrahieren, es besteht jedoch eine gewisse Wahrscheinlichkeit einer Duplizierung. Führen Sie dies jedoch nur einmal auf dem Client aus, dies wird jedoch insgesamt der Fall sein länger sein als die direkte Verwendung. Der Tastenbefehl ist lang.
Haben Sie Redis jemals verwendet, um eine asynchrone Warteschlange zu erstellen?
Verwenden Sie den Listentyp, um Dateninformationen zu speichern. rpush erzeugt Nachrichten und lpop verbraucht Nachrichten. Wenn Sie keine Nachrichten haben, können Sie eine Zeit lang schlafen und dann prüfen, ob Informationen vorhanden sind Wenn Sie schlafen möchten, können Sie blpop verwenden. Wenn keine Informationen vorliegen, bleibt es blockiert, bis die Informationen eintreffen. Redis kann über das Pub/Sub-Topic-Abonnementmodell einen Produzenten und mehrere Konsumenten implementieren. Natürlich gibt es bestimmte Nachteile, wenn der Konsument offline geht.
Wie implementiert Redis die Verzögerungswarteschlange?
Verwenden Sie sortedset, verwenden Sie den Zeitstempel als Bewertung, den Nachrichteninhalt als Schlüssel, rufen Sie zadd auf, um Nachrichten zu erstellen, und der Verbraucher verwendet zrangbyscore, um Daten vor n Sekunden für die Abfrageverarbeitung abzurufen.
Wie funktioniert der Redis-Recyclingprozess?
1. Ein Client hat einen neuen Befehl ausgeführt und neue Daten hinzugefügt.
2. Redis überprüft die Speichernutzung, wenn sie größer als das Limit von maxmemory ist, wird sie gemäß der festgelegten Strategie recycelt.
3. Ein neuer Befehl wird ausgeführt usw.
4. Wir überschreiten also ständig die Grenze der Speichergrenze, indem wir ständig die Grenze erreichen und dann kontinuierlich unter die Grenze zurückkehren.
Wenn das Ergebnis eines Befehls dazu führt, dass viel Speicher beansprucht wird (z. B. das Speichern der Schnittmenge einer großen Menge in einem neuen Schlüssel), dauert es nicht lange, bis das Speicherlimit durch diese Speichernutzung überschritten wird .
Welcher Algorithmus wird für das Redis-Recycling verwendet?
LRU-Algorithmus
Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Programmierunterricht! !



 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
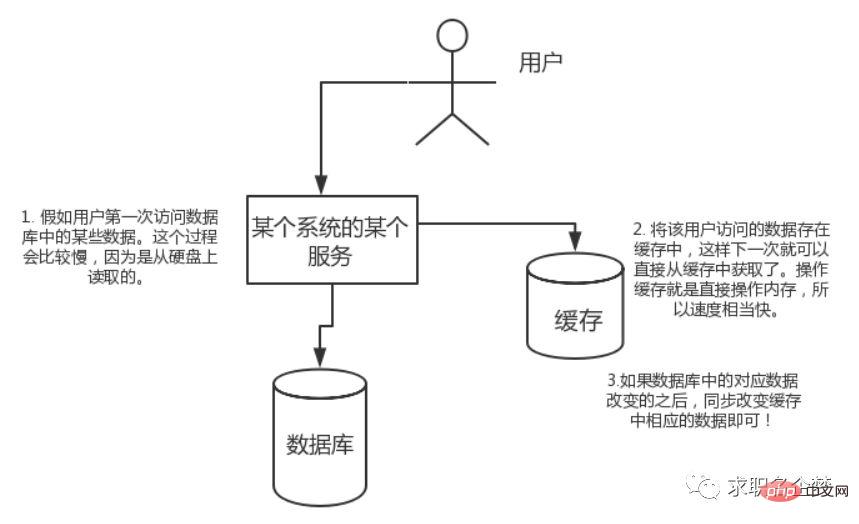
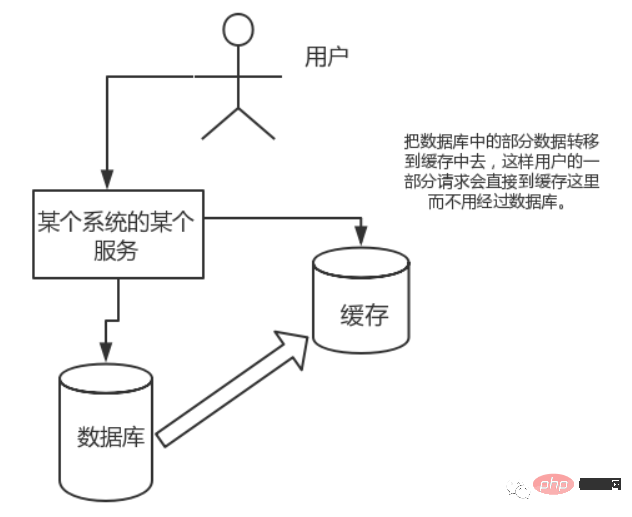
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



