



Verwandte Empfehlungen: „vscode-Tutorial“
Wollten Sie schon immer reguläre Ausdrücke lernen, wurden aber wegen ihrer Komplexität abgeschreckt? In diesem Artikel zeige ich Ihnen fünf leicht zu erlernende Regex-Tipps, die Sie sofort in Ihrem bevorzugten Texteditor verwenden können.
Obwohl mittlerweile fast alle Texteditoren reguläre Ausdrücke unterstützen, verwende ich in diesem Tutorial Visual Studio Code, Sie können jedoch jeden beliebigen Editor verwenden. Beachten Sie außerdem, dass Sie den RegEx-Schalter normalerweise irgendwo in der Nähe des Sucheingabefelds aktivieren müssen. So machen Sie es in VSCode:
Sie müssen RegEx aktivieren, indem Sie diese Option
aktivieren. Das Punktsymbol <code>. wird verwendet, um ein beliebiges Zeichen zu finden: . — 匹配任何字符让我们开始吧。点符号 . 用来匹配任何字符:
b.t

上面的正则匹配 "bot",`"bat"和任何以b开头、t结尾的三个字符的单词。但是如果你想搜索点符号,则需要用 来对它进行转义,所以下面这个正则只匹配确切的文本 "b.t":
b\.t
.* — 匹配任何东西这里 . 表示“任何字符”, * 表示“此符号重复前面那个内容任何次数。” 把它们放在一起(.*)表示“任何符号重复任意次数。” 例如,你可以用它来查找以某些文本开头或结尾的匹配项。假设我们有一个这样的 javascript 方法:
loadScript(scriptName: string, pathToFile: string)
我们想找到这个方法的所有调用,其中 pathToFile 指向文件夹“lua” 中的任何文件。可以使用以下正则表达式:
loadScript.*lua
这意味着,“匹配所有以 "loadScript" 开始同时以"lua"结束的字符串。”
? — 非贪婪的匹配.* 之后的 ? 符号和其他一些匹配规则意味着“尽可能少的匹配”。 在上一张图中,每次匹配都会得到两次 "lua"字符串,直到第二个 "lua" 所有东西才能全部匹配完毕。如果你想匹配第一次出现的"lua",可以使用以下正则:
loadScript.*?lua
这意味着,“匹配所有以 "loadScript"开头,后面为任意字符,直到第一次出现"lua"
loadScript.*?lua:匹配以 loadScript 开头的所有内容,直到第一次出现"lua"
好的,现在我们可以匹配一些文字了。但是如果想要修改我们发现的部分文本呢?这时候就要用到捕获组。
假设我们修改了 loadScript 方法,现在需要在它原来的两个参数之间插入另外一个参数。让我们把这个新参数命名为 id,这时新的函数原型应如下所示:loadScript(scriptName,id,pathToFile)。我们在这里不能用文本编辑器的常规替换功能,不过正则表达式能够帮助我们。

通过上图你可以看到运行以下正则表达式的结果:
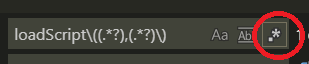
loadScript\(.*?,.*?\)
这意味着:“匹配以 "loadScript(" 开头的, 后面跟任意内容,直到遇到第一个, ,然后是任意内容,直到第一个)”
对你来说,可能看唯一起来比较奇怪的是 符号。它们用于对括号进行转义。
因为符号 (和)
loadScript\((.*?),(.*?)\)
🎜🎜Der obige reguläre Ausdruck passt zu "bot", `"bat" und allem, was mit < endet code>b< Ein dreistelliges Wort, das mit /code> beginnt und mit t endet. Wenn Sie jedoch nach dem Punktsymbol suchen möchten, müssen Sie es mit "b.t" übereinstimmt: 🎜loadScript\((.*?),(.*?)\)
 🎜🎜🎜2)
🎜🎜🎜2) .* – Entspricht allem 🎜🎜🎜hier . bedeutet „beliebiges Zeichen“, * bedeutet „dieses Zeichen“. Das Symbol wiederholt den vorherigen Inhalt beliebig oft. „ Wenn man sie zusammenfügt (.*), bedeutet das: „Jedes Symbol wiederholt sich beliebig oft“ Zum Beispiel Sie Kann verwendet werden. Es werden Übereinstimmungen gefunden, die mit Text beginnen oder enden. Nehmen wir an, wir haben eine Javascript-Methode wie diese: 🎜loadScript(,id,)
pathToFile auf eine beliebige Datei im Ordner "lua" verweist. Der folgende reguläre Ausdruck kann verwendet werden: 🎜rrreee🎜Das bedeutet: „passt zu jeder Zeichenfolge, die mit „loadScript“ beginnt und mit „lua“ endet.“ /em>🎜🎜 🎜🎜🎜3)
🎜🎜🎜3) ? – Non-Greedy-Matching 🎜🎜🎜.* gefolgt vom Symbol ? und einigen anderen Matching-Regeln bedeutet „as möglichst wenige Spiele". Im vorherigen Bild erhält jede Übereinstimmung die Zeichenfolge "lua" zweimal, und erst beim zweiten "lua" wird alles abgeglichen. Wenn Sie das erste Vorkommen von "lua" abgleichen möchten, können Sie den folgenden regulären Ausdruck verwenden: 🎜rrreee🎜Das bedeutet, dass " mit allem übereinstimmt, das mit "loadScript" , gefolgt von beliebigen Zeichen bis zum ersten Auftreten von "lua"🎜🎜 🎜🎜
🎜🎜loadScript.*?lua: Entspricht allem, beginnend mit loadScript bis zum ersten Vorkommen „lua“🎜 🎜🎜4) `( ) ### – Erfassungsgruppen und Rückverweise🎜🎜🎜Okay, jetzt können wir etwas Text abgleichen, aber was ist, wenn wir einen Teil des gefundenen Textes ändern möchten? 🎜🎜Angenommen, wir Ändern Sie die Methode loadScript und fügen Sie nun einen weiteren Parameter zwischen den beiden ursprünglichen Parametern ein. Benennen Sie diesen neuen Parameter id. Dann sollte der neue Funktionsprototyp wie folgt aussehen: < code>loadScript(scriptName, id, pathToFile) Wir können hier nicht die reguläre Ersetzungsfunktion des Texteditors verwenden, aber reguläre Ausdrücke können uns helfen 🎜🎜 🎜🎜Mit dem Bild oben können Sie das Ergebnis der Ausführung des folgenden regulären Ausdrucks sehen: 🎜rrreee🎜Das bedeutet: "trifft alles zu, was mit
🎜🎜Mit dem Bild oben können Sie das Ergebnis der Ausführung des folgenden regulären Ausdrucks sehen: 🎜rrreee🎜Das bedeutet: "trifft alles zu, was mit "loadScript(" beginnt, gefolgt von allem, bis der erste , und dann jeder Inhalt bis zum ersten < code>)"🎜🎜Für Sie sieht es vielleicht seltsam aus. sind (</code > und <code>) werden verwendet, um übereinstimmende Textteile zu erfassen, aber wir müssen mit tatsächlichen Klammerzeichen übereinstimmen, daher müssen sie maskiert werden 🎜.在前面的表达式中,我们使用.*?符号定义了方法调用的两个参数。要使每个参数作为单独的捕获组,需要在它们的前后分别添加(和)符号:
loadScript\((.*?),(.*?)\)
如果你运行这段正则,你将看到没有任何变化。这是因为它匹配的是相同的文本。但现在我们可以将第一个参数称为\$1,将第二个参数称为\$2。这称为反向引用,它将帮助我们做自己想要的事情:在两个参数中间添加另一个参数:
搜索输入:
loadScript\((.*?),(.*?)\)
这与之前的正则相同,但分别将参数映射到倒了捕获组1和2。
替换输入:
loadScript($1,id,$2)
这意味着“用文本"loadScript("、捕获组1、"id"、捕获组2和 ) 替换每个匹配的文本 ”。请注意,你不需要在替换输入中转义括号。

[ ] — 字符类你可以在 [ 和 ] 符号内来列出要在特定位置匹配的字符。例如,[0-9]匹配从0到9的所有数字。你还可以明确列出所有数字:[0123456789] —— 与前面的含义相同。你也可以使用带字母的破折号,[a-z] 将匹配所有小写拉丁字符,[A-Z] 将匹配所有大写拉丁字符,[a-zA-Z] 将会匹配两者。
你也可以在字符类之后使用 *,就像在 . 之后一样,在这种情况下意味着:“匹配此类中任意数量的字符”

你应该知道有几种正则表达式的写法。我在这里讨论的是 javascript RegEx 引擎。大多数现代引擎都很相似,但也可能会存在一些差异。通常这些差异包括转义字符和反向引用标记。
你现在就可以打开文本编辑器,立即开始使用其中的一些技巧。你将看到可以比以前更快地完成许多重构任务。一旦你掌握了这些技巧,就可以开始研究更多的正则表达式了。
英文原文地址:https://medium.freecodecamp.org/simple-regex-tricks-for-beginners-3acb3fa257cb
译文地址:https://segmentfault.com/a/1190000019171886?utm_source=sf-related
更多编程相关知识,请访问:编程学习!!
Das obige ist der detaillierte Inhalt von5 leicht zu erlernende Tipps für reguläre Ausdrücke in VSCode. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



