


mysql主从同步的意思为备份,主库(Master)将自己库中的写入同时同步给自己的从库(Slave),当主库发生某些不可预知的状况,导致整个服务器无法使用时,由于从库中也有一份数据,所以数据可以做到快速恢复,不造成或者减少造成数据的损失。

当master(主)库的数据发生变化的时候,变化会实时的同步到slave(从)库。
数据是一个应用至关重要的一部分。从目的出发,主从同步有那么点备份的意思,主库(Master)将自己库中的写入同时同步给自己的从库(Slave),当主库发生某些不可预知的状况,导致整个服务器无法使用时,由于从库中也有一份数据,所以数据可以做到快速恢复,不造成或者减少造成数据的损失。
当然,这只是第一个层面,如果主从库的作用仅限于此,那么我个人认为没有必要分为两个数据库,只需要定期将数据库内容作为快照发送到另一台服务器,或者每次写入时将写入内容实时发送到另一台服务器不就好了吗,这样不但可以节约资源,也可以起到容灾备份的目的。
当然主从同步的作用绝不可能仅限于此,一旦我们配置了主从结构,我们通常不会让从节点仅仅只作为备份数据库,我们应该还会相应地配置上读写分离(可以使用MyCat或者其它中间件,可以自己了解一下,关于MyCat我在下一篇博客中会说这个,篇幅可能会有点长,所以就再写一篇吧)。
在实际环境下,对于数据库的读操作数目远大于对数据库的写操作,所以我们可以让Master只提供写的功能,然后将所有的读操作都移到从库,这就是我们平时常说的读写分离,这样不但可以减轻Master的压力,还可以做容灾备份,一举两得。
水平扩展数据库的负载能力。
容错,高可用。Failover(失败切换)/High Availability
数据备份。
说完了主从同步的概念,下面来说说主从同步的原理,其实原理也非常简单,没有Redis集群那么多的概念。
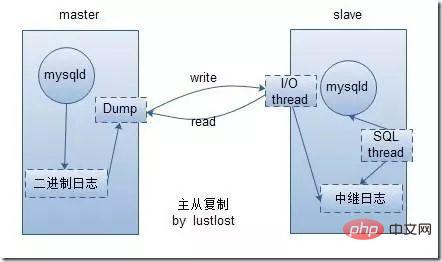
实际上当我们在MySQL中配置了主从之后,只要我们对Master节点进行了写操作,这个操作将会被保存到MySQL的binary-log(bin-log)日志当中,当slave连接到master的时候,master机器会为slave开启binlog dump线程。当master 的 binlog发生变化的时候,Master的dump线程会通知slave,并将相应的binlog内容发送给Slave。而Slave节点在主从同步开启的时候,会创建两个线程,一个I/O线程,一个SQL线程,这在我们后面的搭建中可以亲眼看到。
I/0线程:该线程链接到master机器,master机器的binlog发送到slave的时候,IO线程会将该日志内容写在本地的中继日志(Relay log)中。
SQL线程:该线程读取中继日志中的内容,并且根据中继日志中的内容对Slave数据库做相应的操作。
可能造成的问题:在写请求相当多的情况下,可能会造成Slave数据和Master数据不一致的情况,这是因为日志传输过程中的短暂延迟、或者写命令较多,系统速度不匹配造成的。
这大致就是MySQL主从同步的原理,真正在其中起到作用的实际上就是这两个日志文件,binlog和中继日志。
本次搭建主从同步的环境:CentOS 7 ,MySQL 8.0.18(使用二进制包安装)。
本次将会搭建MySQL的主从同步,其中一台Master,两台Slave。
Master:IP :192.168.43.201 Port:3306 Slave1:IP:192.168.43.202 Port:3306 Slave2:IP:192.168.43.203 Port:3306
修改配置文件
当我们安装好MySQL之后,在/etc/目录下会有一个my.cnf文件,打开文件,加入如下内容(别忘了修改之前做好备份):
x
#该配置为Master的配置 server-id=201 #Server id 每台MySQL的必须不同 log-bin=/var/lib/mysql/mysql-bin.log #代表开启binlog日志 expire_logs_days=10 #日志过期时间 max_binlog_size=200M #日志最大容量 binlog_ignore_db=mysql #忽略mysql库,表示不同步此库
y
#该配置为Slave的配置,第二台Slave也是这么配置,不过要修改一下server-id server-id=202 expire_logs_days=10 #日志的缓存时间 max_binlog_size=200M #日志的最大大小 replicate_ignore_db=mysql #忽略同步的数据库
新增Slave用户
打开Master节点的客户端 ,mysql -u root -p 密码
创建用户create user 'Slave'@'%' identified by '123456';
给新创建的用户赋权:grant replication slave on '*.*' to 'Slave'@'%';
查看Master节点状态
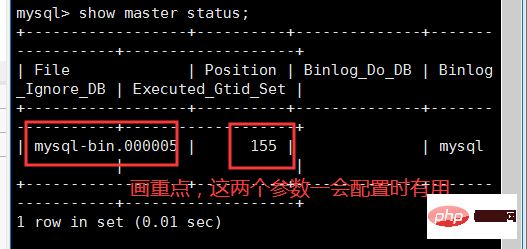
以上操作都没有问题后,我们在客户端中输入show master status查看master的binlog日志。
配置两个Slave节点
打开两个Slave节点客户端,在我们的另外两个Slave节点中输入如下命令:
change master to master_user='Slave',master_password='123456',master_host='192.168.43.201',master_log_file='mysql-bin.000005',master_log_pos=155,get_master_public_key=1; #注意,这里的master_log_file,就是binlog的文件名,输入上图中的mysql-bin.000005,每个人的都可能不一样。 #注意,这里的master_log_pos是binlog偏移量,输入上图中的155,每个人的都可能不一样。
配置完成后,输入start slave;开启从节点,然后输入show slave status\G;查看从节点状态
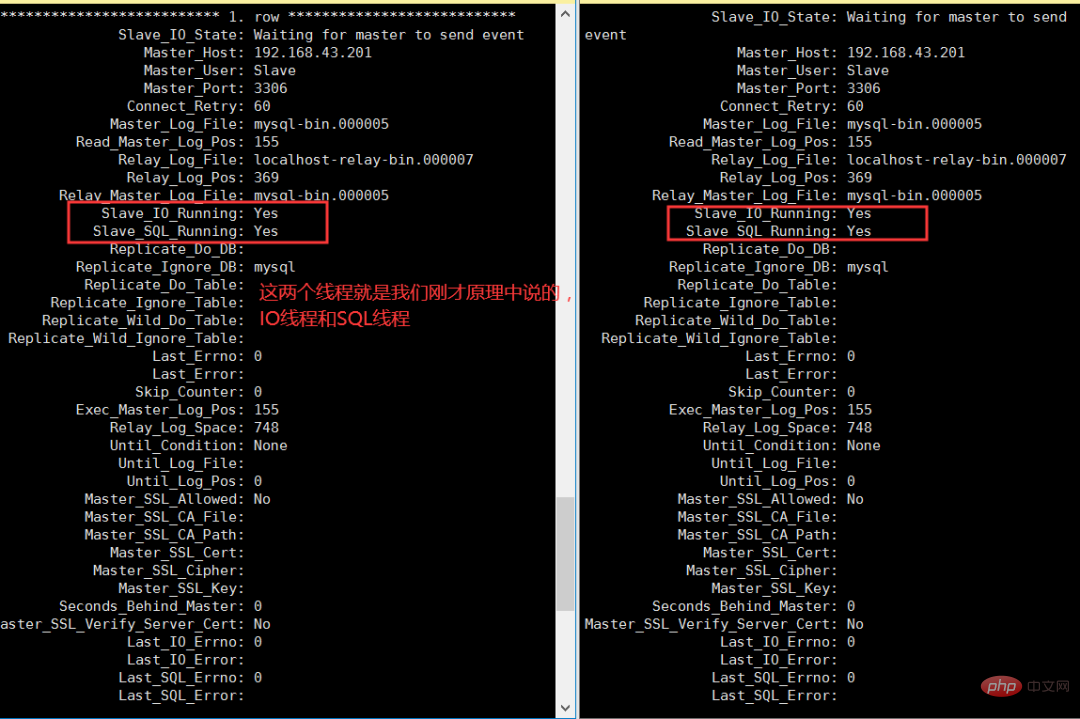
可以看到,在两台Slave的状态中,我们能亲眼看到IO线程和SQL线程的运行状态,这两个线程必须都是yes,才算配置搭建完成。
通过上述步骤,就完成了MySQL主从同步的搭建,相对Redis而言MySQL配置相当简单。下面我们可以进行测试。
先看看三个MySQL的数据库状态:SHOW DATABASES;

可以看到现在数据库都是初始默认状态,没有任何额外的库。
在Master节点中创建一个数据库,库名可以自己设置。
CREATE DATABASE testcluster;

可以看到,在Slave中也出现了Master中创建的数据库,说明我们的配置没有问题,主从搭建成功。这里就不再创建表了,大家可以自己试试,创建表再往表中插入数据,也是没有任何问题的。
如果出现IO线程一直在Connecting状态,可以看看是不是三台机器无法相互连接,如果可以相互连接,那么有可能是Slave账号密码写错了,重新关闭Slave然后输入上面的配置命令再打开Slave即可。
如果出现SQL线程为NO状态,那么有可能是从数据库和主数据库的数据不一致造成的,或者事务回滚,如果是后者,先关闭Slave,然后先查看master的binlog和position,然后输入配置命令,再输入set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;,再重新start slave;即可,如通过是前者,那么就排查一下是不是存在哪张表没有被同步,是否存在主库存在而从库不存在的表,自己同步一下再重新配置一遍即可。
在写这篇文章之前自己也被一些计算机领域的“名词”吓到过,相信有不少同学都有一样的体会,碰上某些高大上的名词总是先被吓到,例如像“分布式”、“集群”等等等等,甚至在没接触过nginx之前,连”负载均衡“、”反向代理“这样的词都让人觉得,这么高达上的词,肯定很难吧,但其实自己了解了nginx、ribbon等之后才发现,其实也就那么回事吧,没有想象中的那么难。
所以写这篇文章的初衷是想让大家对集群化或者分布式或者其他的一些技术或者解决方案不要有一种望而却步的感觉(感觉计算机领域的词都有这么一种特点,词汇高大上,但是其实思想是比较好理解的),其实自己手动配置出一个简单的集群并没有那么难。
如果学会docker之后再来配置就更加简单了,但是更希望不要只局限于会配置,配置出来的东西只能说你会配置了,但是在这层配置底下是前人做了相当多的工作,才能使我们通过简单配置就能实现一些功能,应该要深入底层,了解配置下面的工作原理,这个才是最重要的,也是体现一个程序员水平的地方。
推荐教程:mysql视频教程
Das obige ist der detaillierte Inhalt vonmysql主从同步是什么. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde MySQL-Datenbank erstellen
MySQL-Datenbank erstellen MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL mysqlPasswort vergessen
mysqlPasswort vergessen






























