

Ich glaube, dass viele Freunde bereits die Master-Slave-Replikation konfiguriert haben, aber sie haben kein tiefes Verständnis für den Workflow und die häufigen Probleme der Redis-Master-Slave-Replikation. Kaka verbrachte dieses Mal zwei Tage damit, alle Wissenspunkte zur Redis-Master-Slave-Replikation zusammenzustellen.
Die zur Implementierung dieses Artikels erforderliche Umgebung
centos7.0
redis4.0
Master-Slave-Replikation bedeutet, dass es jetzt zwei Redis-Server gibt und die Daten eines Redis mit der anderen Redis-Datenbank synchronisiert werden. Ersterer wird als Master-Knoten bezeichnet, letzterer als Slave-Knoten. Daten können nur in einer Richtung vom Master zum Slave synchronisiert werden.
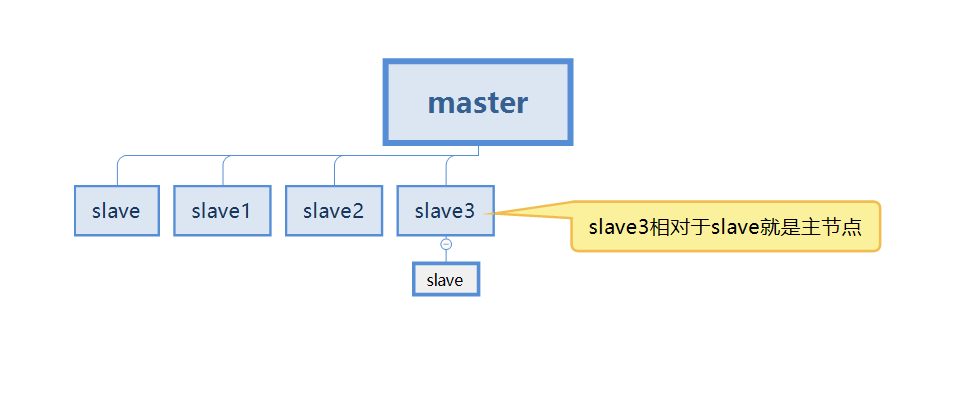
Aber im tatsächlichen Prozess ist es unmöglich, nur zwei Redis-Server für die Master-Slave-Replikation zu haben, was bedeutet, dass jeder Redis-Server als Master-Knoten (Master) bezeichnet werden kann )
Im folgenden Fall ist unser Slave3 sowohl der Slave-Knoten des Masters als auch der Master-Knoten des Slaves.
Verstehen Sie zunächst dieses Konzept und lesen Sie weiter unten weiter, um weitere Einzelheiten zu erfahren.
Angenommen, wir haben jetzt einen Redis-Server, der sich in einem eigenständigen Zustand befindet.
Das erste Problem, das in diesem Fall auftritt, ist, dass der Server ausfällt, was direkt zu Datenverlust führt. Wenn das Projekt mit RMB zusammenhängt, kann man sich die Konsequenzen vorstellen.
Die zweite Situation ist das Speicherproblem. Wenn nur ein Server vorhanden ist, wird der Speicher definitiv seinen Höhepunkt erreichen. Es ist unmöglich, einen Server unendlich zu aktualisieren.
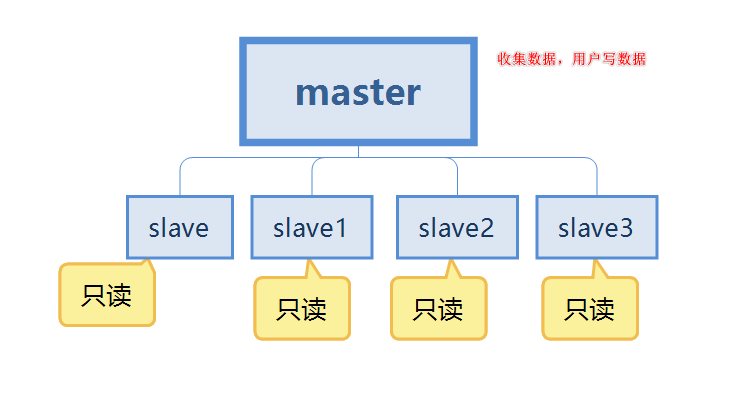
Als Reaktion auf die beiden oben genannten Probleme werden wir einige weitere Server vorbereiten und die Master-Slave-Replikation konfigurieren. Speichern Sie Daten auf mehreren Servern. Und stellen Sie sicher, dass die Daten jedes Servers synchronisiert sind. Selbst wenn ein Server ausfällt, hat dies keine Auswirkungen auf die Nutzung durch die Benutzer. Redis kann weiterhin eine hohe Verfügbarkeit und redundante Datensicherung erreichen.
An dieser Stelle sollten sich viele Fragen stellen: Wie verbindet man Master und Slave? Wie synchronisiere ich Daten? Was passiert, wenn der Master-Server ausfällt? Machen Sie sich keine Sorgen, lösen Sie Ihre Probleme Stück für Stück.
Wir haben oben darüber gesprochen, warum wir die Master-Slave-Replikation von Redis verwenden. Die Rolle der Master-Slave-Replikation besteht also darin, zu erklären, warum sie verwendet wird.
Sagt So viel: Lassen Sie uns zunächst einfach einen Master-Slave-Replikationsfall konfigurieren und dann über die Implementierungsprinzipien sprechen.
Der Redis-Speicherpfad lautet: usr/local/redis
Die Protokoll- und Konfigurationsdateien werden gespeichert in: usr/local /redis/data
Zuerst konfigurieren wir zwei Konfigurationsdateien, nämlich redis6379.conf und redis6380.conf
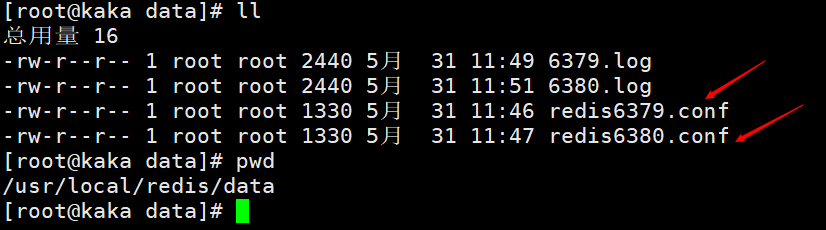
Ändern Sie die Konfigurationsdatei, hauptsächlich um den Port zu ändern. Um die Anzeige zu erleichtern, sind die Namen von Protokolldateien und persistenten Dateien mit ihren jeweiligen Ports gekennzeichnet.
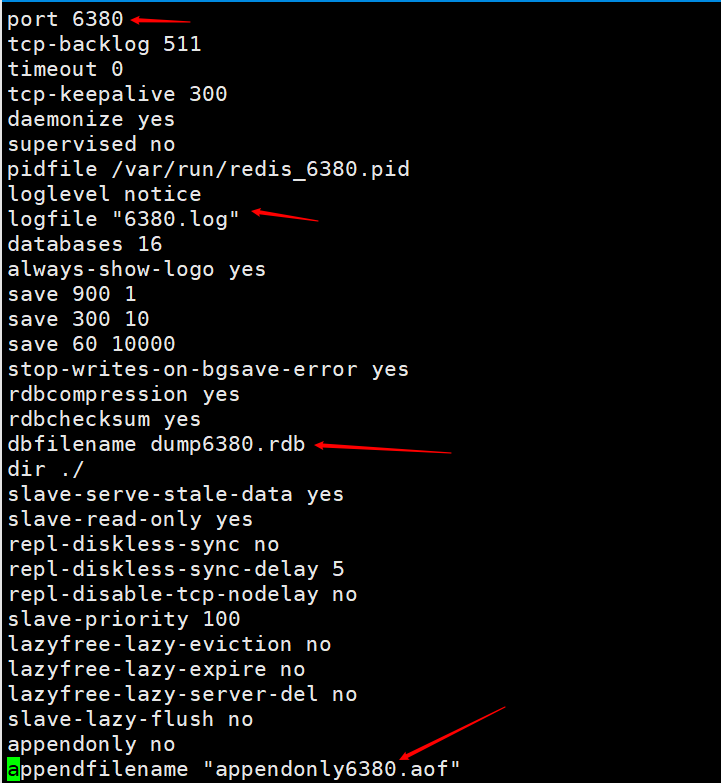
Öffnen Sie dann zwei Redis-Dienste, einen mit Port 6379 und einen mit Port 6380. Führen Sie den Befehl redis-server redis6380.conf aus und verwenden Sie dann redis-cli -p 6380, um eine Verbindung herzustellen. Da der Standardport von Redis 6379 ist, können wir einen anderen Redis-Server starten und redis-server redis6379.conf direkt verwenden und dann redis-cli verwenden, um eine direkte Verbindung herzustellen.

Zu diesem Zeitpunkt haben wir erfolgreich zwei Redis-Dienste konfiguriert, einer ist 6380 und der andere ist 6379. Dies dient nur zur Demonstration. In der tatsächlichen Arbeit muss es auf zwei verschiedenen Servern konfiguriert werden.
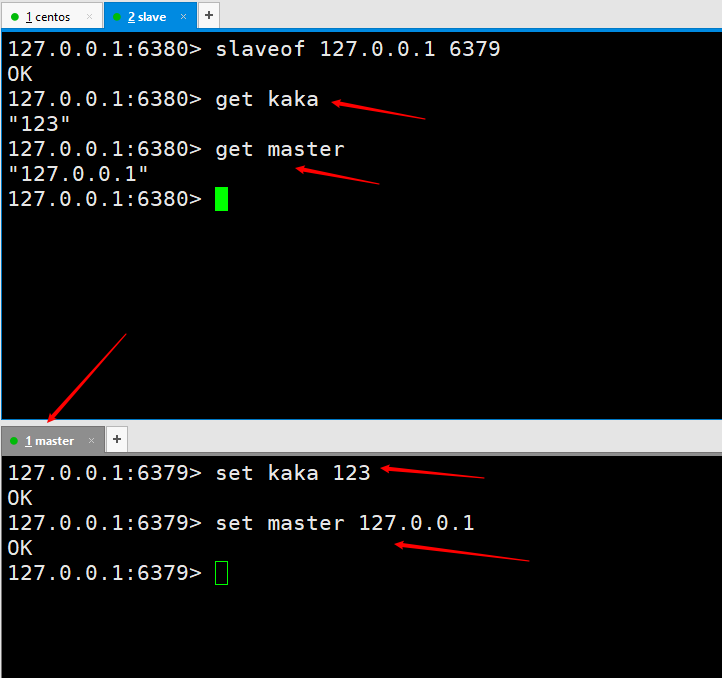
Wir müssen zunächst ein Konzept haben, das heißt, bei der Konfiguration der Master-Slave-Replikation werden alle Vorgänge auf dem Slave-Knoten, also dem Slave, ausgeführt.
Dann führen wir einen Befehl als
slaveof 127.0.0.1 6379
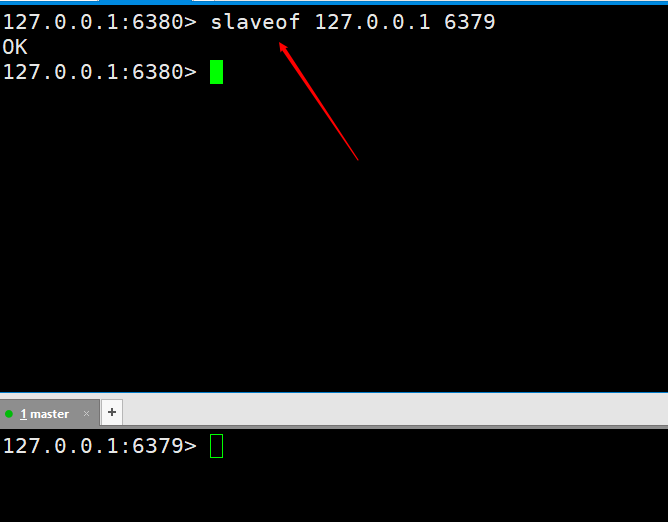 Testen wir zunächst, ob die Master-Slave-Replikation implementiert ist. Führen Sie zwei
Testen wir zunächst, ob die Master-Slave-Replikation implementiert ist. Führen Sie zwei
auf dem Slave-Host ausführen, um die Master-Slave-Replikation zu trennen. slaveof no one
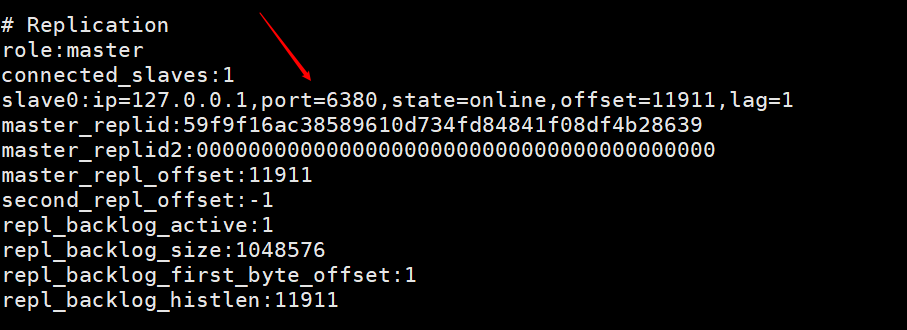
auf dem Client des Masterknotens ein, um info
anzuzeigen
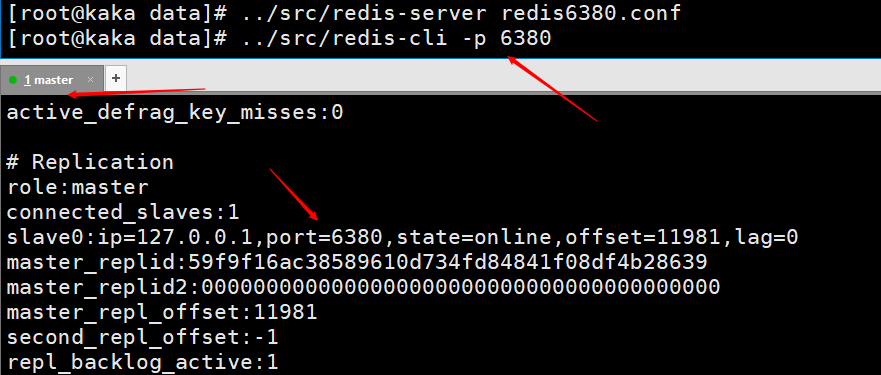
Dieses Bild zeigt die Informationen, die durch Eingabe von info auf dem Client des Master-Knotens gedruckt werden, nachdem der Slave-Knoten verwendet wurde, um über die Client-Befehlszeile eine Verbindung zum Master-Knoten herzustellen. Sie können sehen, dass es eine Information über Slave0 gibt .
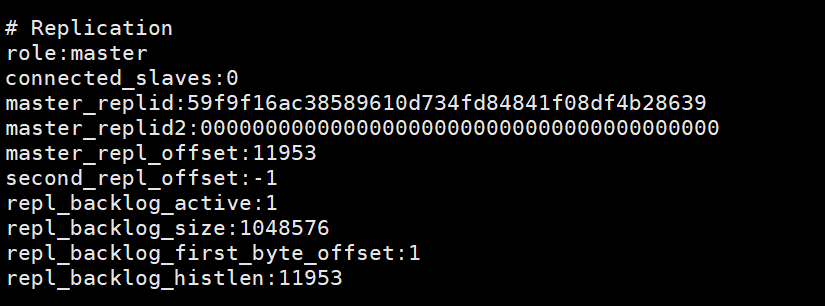
Dieses Bild wird auf dem Masterknoten gedruckt, nachdem slaveof no one auf dem Slaveknoten ausgeführt wurde, was anzeigt, dass der Slaveknoten mit dem Master kommuniziert hat Knoten Getrennt. info
redis-server redis6380.conf
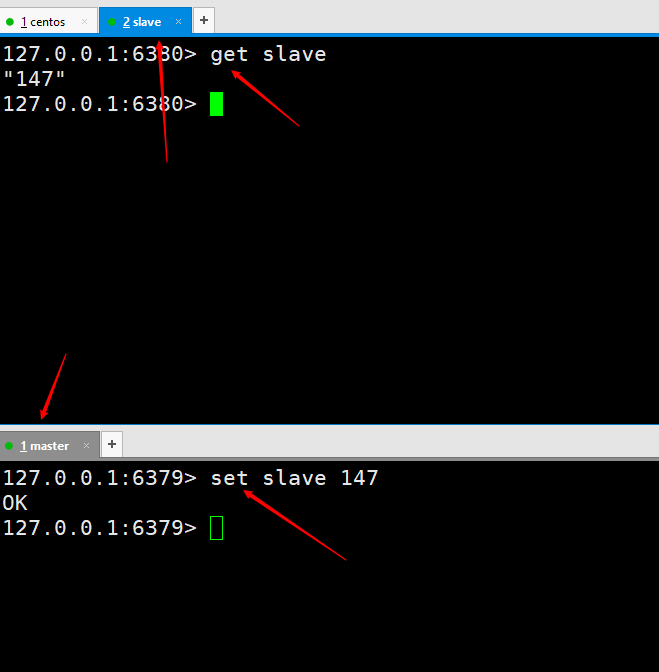
Testdaten, vom Masterknoten geschriebene Dinge werden weiterhin automatisch vom Slaveknoten synchronisiert.
Diese Konfigurationsmethode ist ebenfalls sehr einfach. Starten Sie beim Starten des Redis-Servers direkt die Master-Slave-Replikation und führen Sie den Befehl aus: redis-server --slaveof host port.
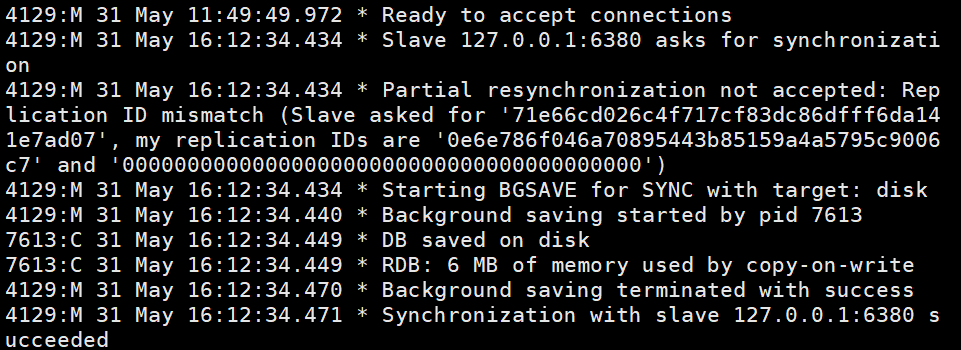
Dies sind die Protokollinformationen von Masterknoten
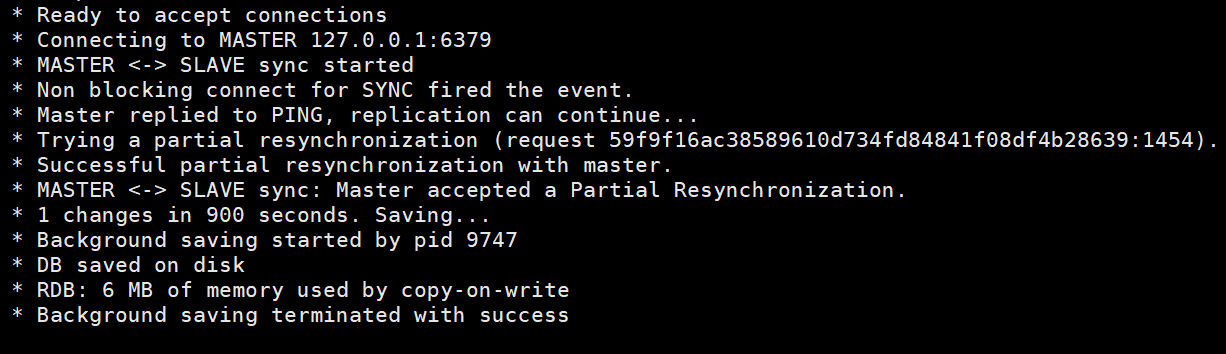
Dies sind die Informationen des Slave-Knotens, einschließlich der Verbindungsinformationen des Master-Knotens und der RDB-Snapshot-Speicherung.
Der gesamte Workflow der Master-Slave-Replikation ist in die folgenden drei Phasen unterteilt. Jedes Segment hat seinen eigenen internen Arbeitsablauf, daher werden wir über drei Prozessprozesse sprechen.
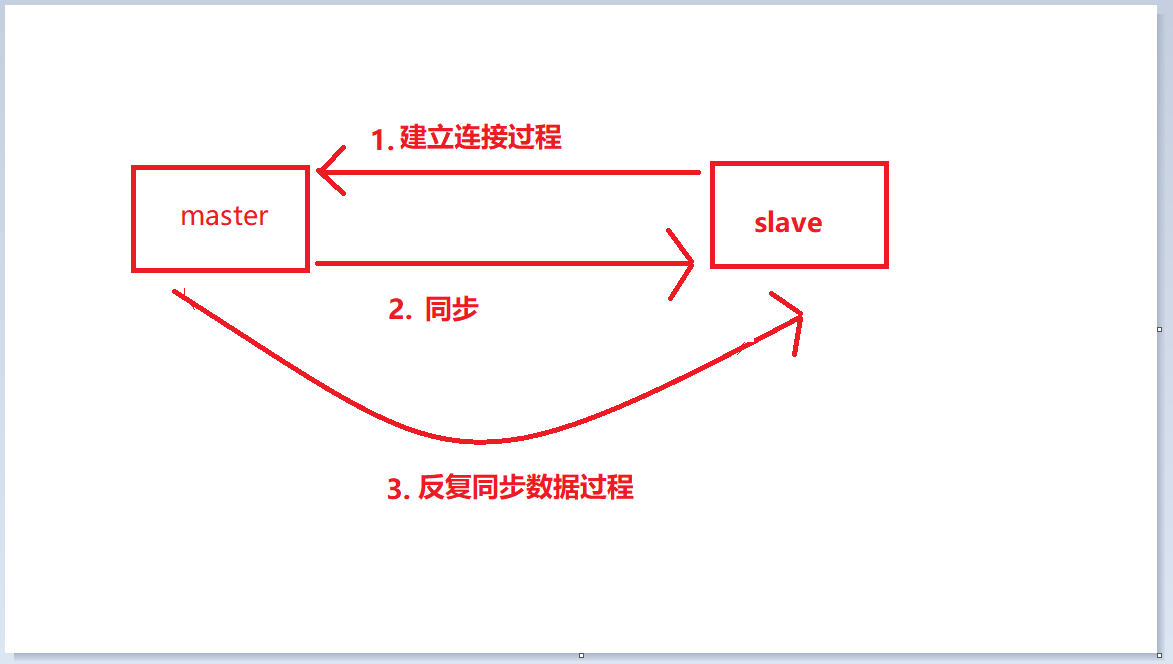
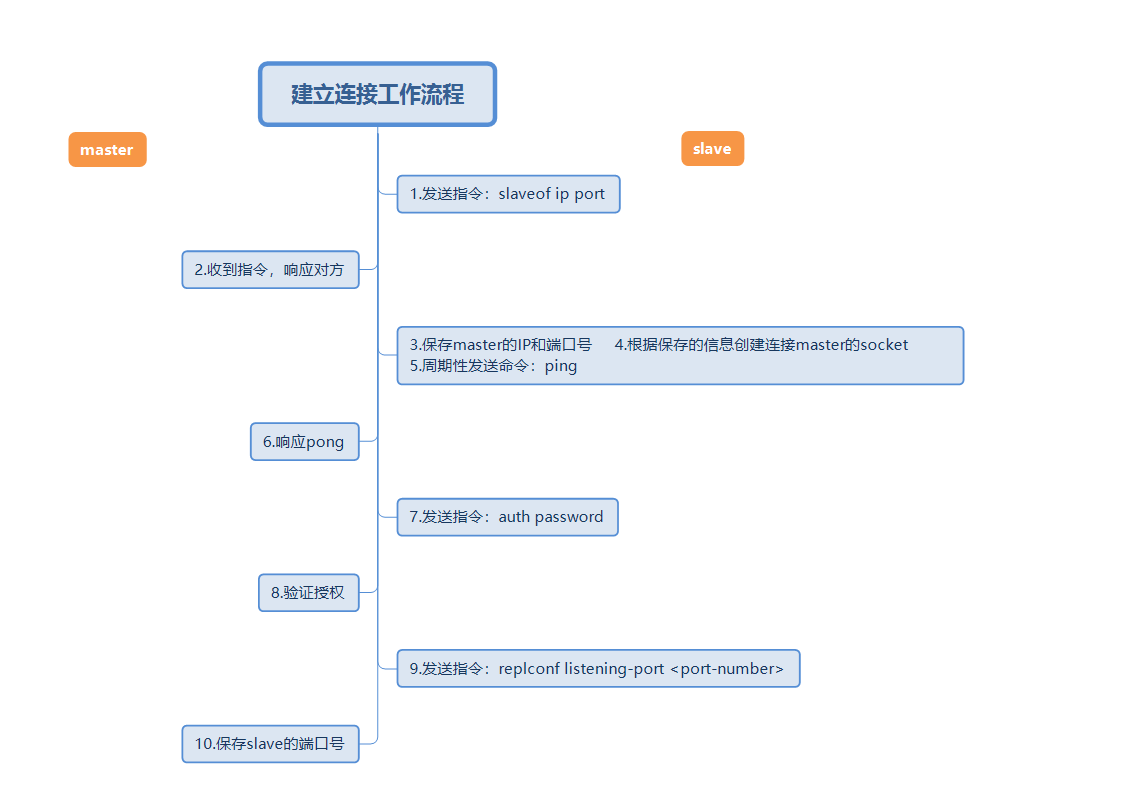
Während des Verbindungsaufbaus speichert der Slave-Knoten die Adresse und den Port des Masters und der Master-Knoten speichert den Port des Slave-Knotens.
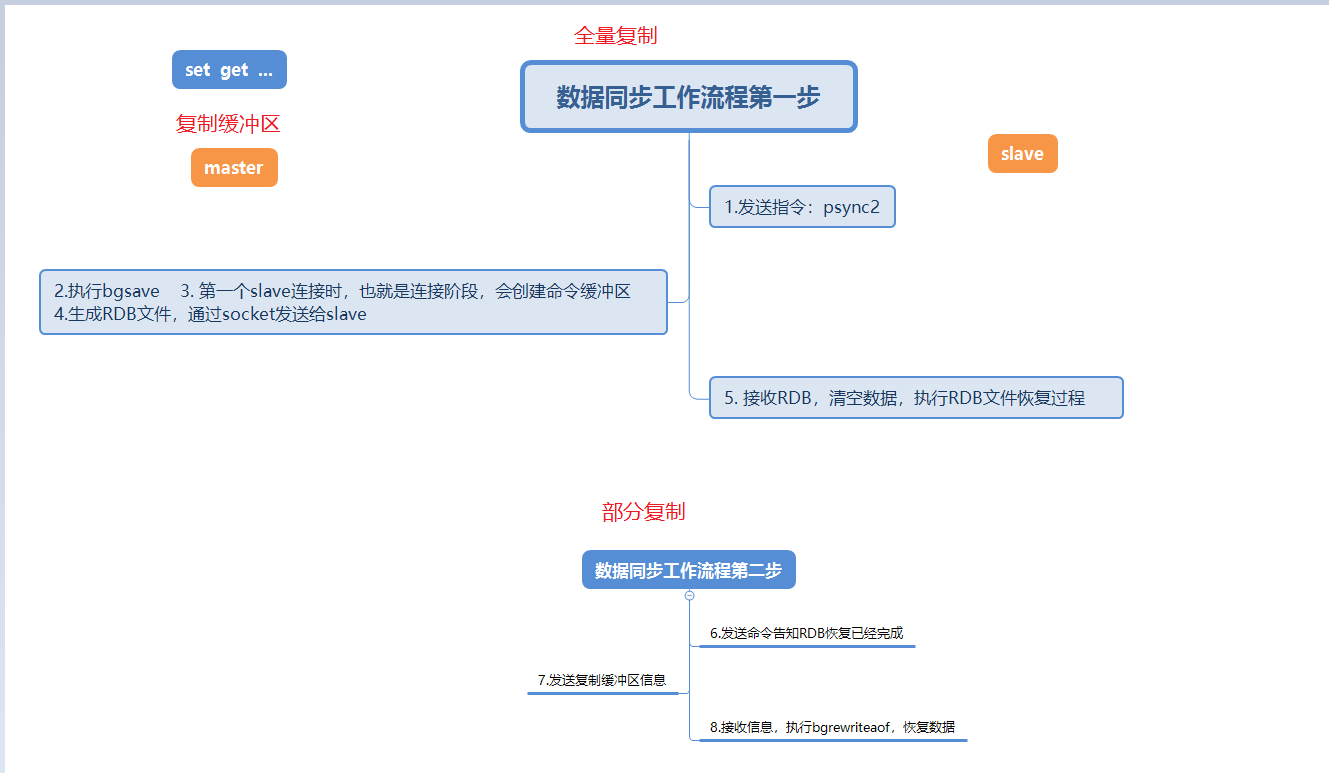
Dieses Bild beschreibt detailliert den Datensynchronisationsprozess, wenn der Slave-Knoten zum ersten Mal eine Verbindung zum Master-Knoten herstellt.
Wenn der Slave-Knoten zum ersten Mal eine Verbindung zum Master-Knoten herstellt, führt er zunächst eine vollständige Kopie durch. Diese vollständige Kopie ist unvermeidlich.
Nachdem die vollständige Replikation abgeschlossen ist, sendet der Masterknoten die Daten im Replikations-Backlog-Puffer, und dann führt der Slave-Knoten bgrewriteaof aus, um die Daten wiederherzustellen teilweise Replikation.
Zu diesem Zeitpunkt werden drei neue Punkte erwähnt: vollständige Kopie, teilweise Kopie und Kopierpufferrückstand. Diese Punkte werden in den folgenden FAQ ausführlich erläutert.
Wenn die Master-Datenbank geändert wird und die Daten auf dem Master- und Slave-Server inkonsistent sind, werden die Master- und Slave-Daten synchronisiert, um konsistent zu sein. Dieser Vorgang wird als Befehlsweitergabe bezeichnet.
Der Master sendet den empfangenen Datenänderungsbefehl an den Slave, und der Slave führt den Befehl nach Erhalt des Befehls aus, um die Master-Slave-Daten konsistent zu machen.
Teilweises Kopieren während der Befehlsweitergabephase

Dieser Prozess ist die vollständigste Prozesserklärung der Master-Slave-Replikation. Lassen Sie uns jeden Schritt des Prozesses kurz vorstellen
psync ? 1 psync runid offset senden, um das entsprechende runid zum Anfordern von Daten zu finden. Hier können Sie jedoch berücksichtigen, dass der Slave-Knoten beim ersten Herstellen einer Verbindung das runid 和 offset des Master-Knotens überhaupt nicht kennt. Der zum ersten Mal gesendete Befehl lautet also psync ? 1, was bedeutet, dass ich alle Daten des Masterknotens haben möchte. psync runid offset
2 zurück, um mit der vollständigen Replikation fortzufahren. Die Runid-Nichtübereinstimmung ist hier möglicherweise nur auf den Neustart des Slave-Knotens zurückzuführen. Die Nichtübereinstimmung des Offsets (Offset) ist der Überlauf des Replikations-Backlogs. Wenn die Runid- oder Offset-Prüfung erfolgreich ist und der Offset des Slave-Knotens mit dem Offset des Master-Knotens übereinstimmt, wird er ignoriert. Wenn die Runid- oder Offset-Prüfung erfolgreich ist und sich der Offset des Slave-Knotens vom Offset unterscheidet, wird der +CONTINUE-Offset (dieser Offset gehört zum Master-Knoten) gesendet und die Daten vom Slave-Knoten-Offset zum Master-Knoten-Offset gesendet Der Replikationspuffer wird über den Socket gesendet. 1-4 sind Vollexemplare, 5-8 sind Teilexemplare
In Schritt 3 des Masterknotens hat der Masterknoten während des Master-Slave-Replikationszeitraums Clientdaten empfangen und der Offset des Masterknotens hat sich geändert. An jeden Slave werden nur Änderungen gesendet. Dieser Sendevorgang wird als Heartbeat-Mechanismus bezeichnet
Während der Befehlsweitergabephase müssen der Masterknoten und der Slaveknoten immer Informationen austauschen. Ändern und verwenden Sie den Heartbeat-Mechanismus für die Wartung, um die Verbindung zwischen dem Master-Knoten und dem Slave-Knoten online zu halten.
Vorsichtsmaßnahmen während der Heartbeat-Phase
Um die Datenstabilität zu gewährleisten, wird der Masterknoten wann Die Anzahl der Tropfen oder die Verzögerung ist zu hoch. Jegliche Informationssynchronisierung wird abgelehnt.
Es gibt zwei Parameter für die Konfigurationsanpassung:
min-slaves-to-write 2
min-slaves-max-lag 8
dies Die beiden Parameter zeigen an, dass nur noch 2 Slave-Knoten übrig sind. Wenn die Verzögerung des Slave-Knotens mehr als 8 Sekunden beträgt, schaltet der Master-Knoten die Master-Funktion zwangsweise aus und stoppt die Datensynchronisierung.
Was passiert dann, wenn der Master-Knoten die Daten und die Verzögerungszeit des hängenden Slave-Knotens kennt? Im Heartbeat-Mechanismus sendet der Slave jede Sekunde den Befehl perlconf ack. Dieser Befehl kann den Offset, die Verzögerungszeit des Slave-Knotens und die Anzahl der Slave-Knoten übertragen.
Schauen wir uns zunächst an, was diese Lauf-ID ist. Sie können sie sehen, indem Sie den Info-Befehl ausführen. Wir können dies auch sehen, wenn wir uns die Startprotokollinformationen oben ansehen.
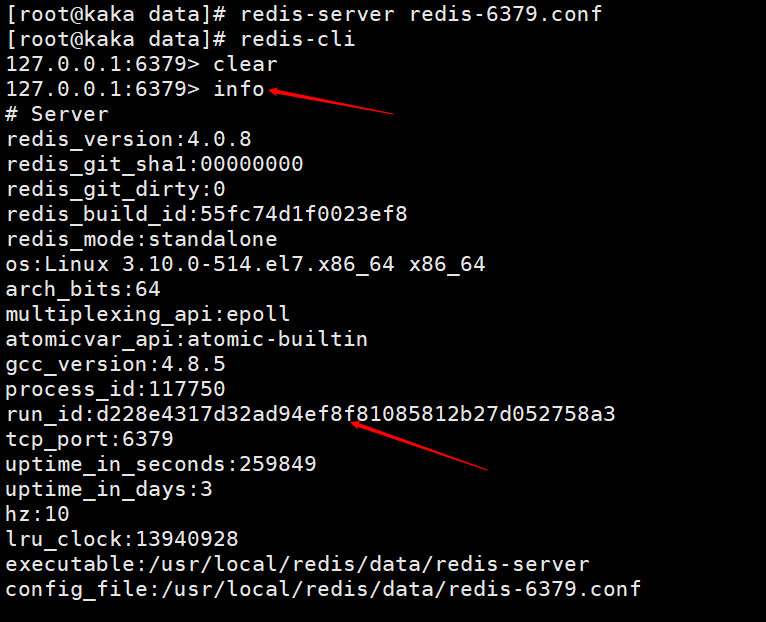
Redis generiert beim Start automatisch eine zufällige ID (hier ist zu beachten, dass die ID bei jedem Start anders ist), die aus 40 zufälligen Hexadezimalzeichenfolgen besteht und zur eindeutigen Identifizierung eines Redis-Knotens dient .
Wenn die Master-Slave-Replikation zum ersten Mal gestartet wird, sendet der Master seine Runid an den Slave und der Slave speichert die ID des Masters. Wir können den Info-Befehl verwenden um es anzuzeigen
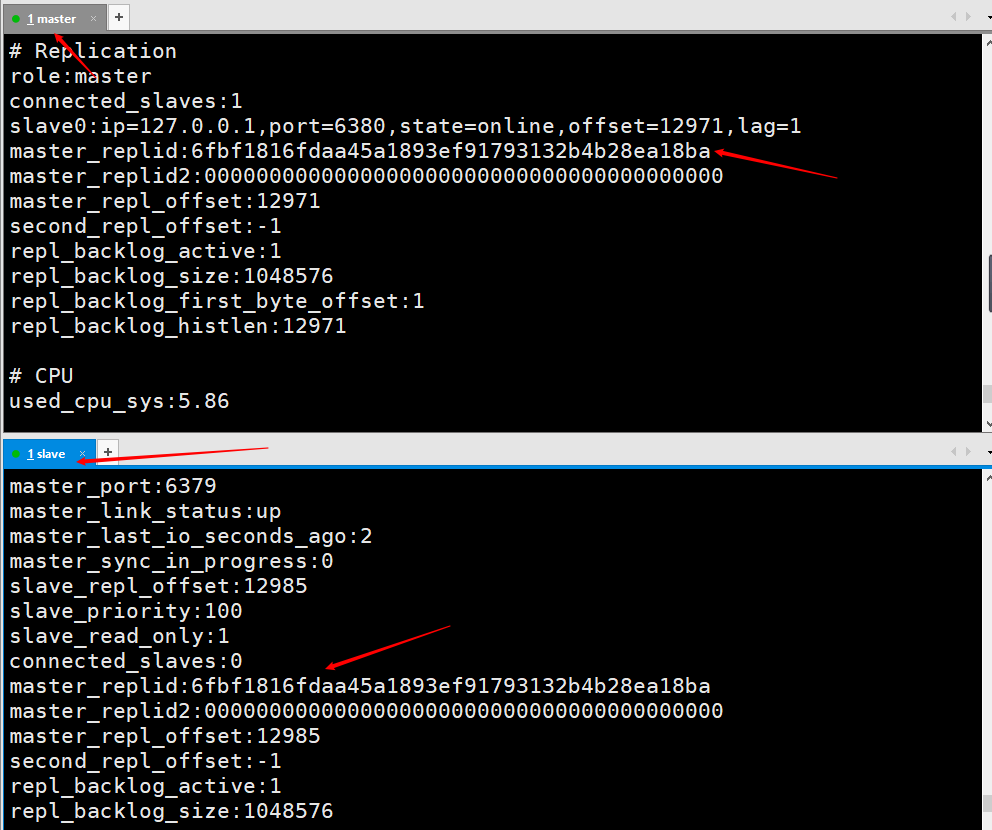
Bei Trennung und erneuter Verbindung sendet der Slave Diese ID wird an den Master gesendet. Wenn die vom Slave gespeicherte Runid mit der aktuellen Runid des Masters übereinstimmt, versucht der Master, eine teilweise Replikation zu verwenden (ein weiterer Faktor dafür, ob dieser Block erfolgreich kopiert werden kann, ist der Offset). Wenn sich die vom Slave gespeicherte Runid von der aktuellen Runid des Masters unterscheidet, wird die vollständige Kopie direkt durchgeführt.
Der Kopierpufferrückstand ist eine First-In-First-Out-Warteschlange. Benutzerspeicher Master-Befehlsdatensätze zum Sammeln von Daten. Der Standardspeicherplatz des Kopierpuffers beträgt 1 MB.
Sie können repl-backlog-size 1mb in der Konfigurationsdatei ändern, um die Puffergröße entsprechend Ihrem eigenen Serverspeicher zu steuern.
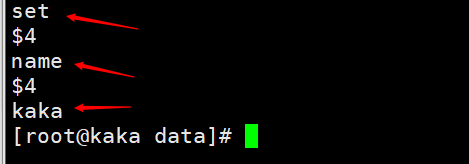
Was genau speichert der Kopierpuffer?
Wenn wir einen Befehl als set name kaka ausführen, können wir die Persistenzdatei anzeigen, um
 anzuzeigen
anzuzeigen
Dann ist der Kopierrückstandspuffer die gespeicherte Menge persistenter Daten, getrennt durch Bytes, und jedes Byte hat seinen eigenen Offset. Dieser Versatz ist auch der Kopierversatz (Offset)

Warum heißt es dann, dass der Rückstand des Kopierpuffers zu einer vollständigen Kopie führen kann? 🎜>
In der Befehlsweitergabephase speichert der Masterknoten die gesammelten Daten im Replikationspuffer und sendet sie dann an den Slaveknoten. Hier entsteht das Problem, wenn die Datenmenge auf dem Master-Knoten in einem Moment extrem groß ist und den Speicher des Replikationspuffers überschreitet, werden einige Daten verdrängt, was zu Dateninkonsistenzen zwischen dem Master-Knoten und dem Slave führt Knoten. Um eine vollständige Kopie zu erstellen. Wenn die Puffergröße nicht richtig eingestellt ist, kann es zu einer Endlosschleife kommen. Der Slave-Knoten kopiert immer vollständig, löscht die Daten und kopiert dann vollständig.
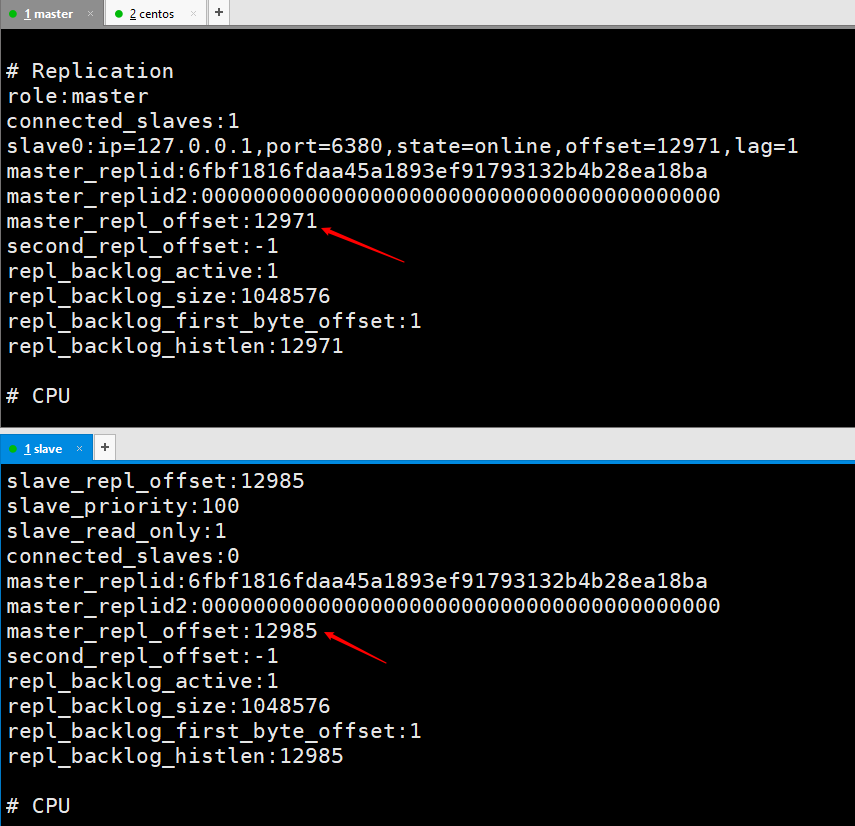
Der Master-Knoten-Replikationsoffset besteht darin, einen Datensatz einmal an den Slave-Knoten zu senden, und der Slave-Knoten soll einmal einen Datensatz empfangen.
wird verwendet, um Informationen zu synchronisieren, die Unterschiede zwischen dem Master-Knoten und dem Slave-Knoten zu vergleichen und die Datennutzung wiederherzustellen, wenn der Slave getrennt wird.
Dieser Wert ist der Offset vom Kopierpufferrückstand.
Wenn der Master-Knoten neu startet, ändert sich der Wert von runid, was dazu führt, dass alle Slave-Knoten eine vollständige Replikation durchführen.
Wir müssen dieses Problem nicht berücksichtigen, solange wir wissen, wie das System optimiert ist.
Nachdem die Master-Slave-Replikation eingerichtet ist, erstellt der Masterknoten die Master-Replid-Variable. Die generierte Strategie ist dieselbe wie die Runid, mit einer Länge von 41 Bits und eine Runid-Länge von 40 Bits werden dann an den Slave-Knoten gesendet.
Wenn der Befehl zum Speichern des Herunterfahrens auf dem Masterknoten ausgeführt wird, wird eine RDB-Persistenz durchgeführt und die Runid und der Offset werden in der RDB-Datei gespeichert. Sie können den Befehl redis-check-rdb verwenden, um diese Informationen anzuzeigen.
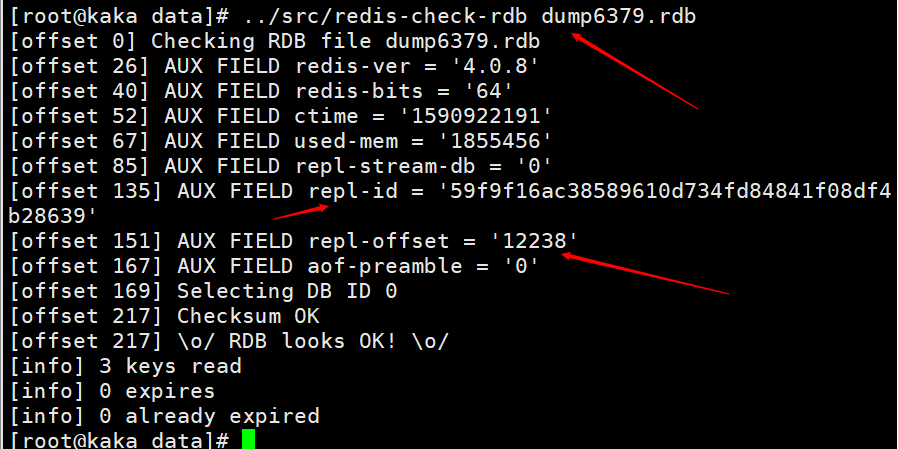
Laden Sie die RDB-Datei nach dem Neustart des Masterknotens und laden Sie die Repl-ID und den Repl-Offset in der Datei in den Speicher. Auch wenn alle Slave-Knoten als die vorherigen Master-Knoten betrachtet werden.
Aufgrund einer schlechten Netzwerkumgebung , der Slave-Knoten-Knoten-Netzwerkausfall. Der Replikations-Backlog-Pufferspeicher ist zu klein, was zu einem Datenüberlauf führt. Wenn der Slave-Knoten-Offset die Grenze überschreitet, erfolgt eine vollständige Replikation. Dadurch kann es zu wiederholten Vollkopien kommen.
Lösung: Ändern Sie die Größe des Replikations-Backlog-Puffers: repl-backlog-size
Setup-Empfehlung: Testen Sie die Master-Verbindung Zeit des Slave-Knotens, erhält die durchschnittliche Gesamtzahl der vom Master-Knoten pro Sekunde generierten Befehle write_size_per_second
Kopierpufferspeicherplatzeinstellung = 2 Master-Slave-Verbindungszeit Master Die Gesamtmenge der vom Knoten pro Sekunde generierten Daten
Aufgrund der CPU des Master-Knotens ist die Auslastung zu hoch oder der Slave-Knoten ist häufig verbunden. Das Ergebnis dieser Situation ist, dass verschiedene Ressourcen des Masterknotens stark belegt sind, einschließlich, aber nicht beschränkt auf Puffer, Bandbreite, Verbindungen usw.
Warum sind die Ressourcen des Masterknotens stark belegt?
Im Heartbeat-Mechanismus sendet der Slave-Knoten jede Sekunde einen Befehl replconf ack an den Master-Knoten.
Der Slave-Knoten hat eine langsame Abfrage ausgeführt, die viel CPU beansprucht
Der Master-Knoten hat jede Sekunde die Replikations-Timing-Funktion replicationCron aufgerufen, und dann hat der Slave-Knoten lange Zeit nicht geantwortet.
Lösung:
Slave-Knoten-Timeout-Freigabe festlegen
Parameter festlegen: repl-timeout
Dieser Parameter ist standardmäßig auf 60 Sekunden eingestellt . Lassen Sie den Slave nach 60 Sekunden los.
Aufgrund von Netzwerkfaktoren sind die Daten mehrerer Slave-Knoten inkonsistent. Es gibt keine Möglichkeit, diesen Faktor zu vermeiden.
Es gibt zwei Lösungen für dieses Problem:
Die ersten Daten erfordern eine hochkonsistente Konfiguration des Redis-Servers Verwendet einen Server sowohl zum Lesen als auch zum Schreiben. Diese Methode ist auf eine kleine Datenmenge beschränkt und die Daten müssen hochkonsistent sein.
Der zweite überwacht den Offset der Master- und Slave-Knoten. Wenn die Verzögerung des Slave-Knotens zu groß ist, wird der Zugriff des Clients auf den Slave-Knoten vorübergehend blockiert. Setzen Sie den Parameter auf „slave-serve-stale-data ja|nein“. Sobald dieser Parameter gesetzt ist, kann er nur auf einige wenige Befehle reagieren, wie z. B. „Info Slaveof“.
Dieser Artikel erklärt hauptsächlich, was Master-Slave-Replikation ist und die drei Hauptaspekte des Masters -Slave-Replikation. Phasen, Arbeitsabläufe und die drei Kernkomponenten der Teilreplikation. Heartbeat-Mechanismus während der Befehlsweitergabephase. Abschließend werden häufige Probleme bei der Master-Slave-Replikation erläutert.
Das obige ist der detaillierte Inhalt vonFunktionsprinzip der Redis-Master-Slave-Replikation und häufige Probleme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?


























