

Daten hinzufügen/ändern: set key value
Daten abrufen: get key
Daten löschen: del key
Mehrere Daten hinzufügen/ändern: mset key value key1 value1
Mehrere Daten abrufen: mget key key1
Informationen anhängen Ende der Originaldaten (fügen Sie sie hinzu, wenn sie nicht vorhanden sind): append key value
Stellen Sie den Wert ein, um den Wert im angegebenen Bereich zu erhöhen: incr key 默认每次加1 | incrby key value 每次新增value
Stellen Sie die Daten ein, um den angegebenen Bereich zu verringern: decr key | decrby key value 跟新增是一回事
Anwendungsszenario
steuert die Primärschlüssel-ID der Datenbanktabelle, stellt eine Primärschlüsselgenerierungsstrategie für die Datenbanktabelle bereit und stellt die Konsistenz des Primärschlüssels der Daten sicher Tisch.
Ablaufzeit festlegen: setex key seconds value
Anwendungsszenarien
Implementieren Sie eine zeitlich begrenzte Abstimmungsfunktion: Beispielsweise kann ein WeChat-Konto einmal pro Stunde abstimmen
Implementieren Sie Hot Information : zum Beispiel E-Commerce Beliebte Produkte in der Branche, beliebte Nachrichten auf Nachrichten-Websites
Weibo Big V-Homepage Für häufige Besuche muss die Anzahl der Fans, Follower und Weibo von Zeit zu Zeit aktualisiert werden. Dies sind Hochfrequenzinformationen, um sie zu lösen. 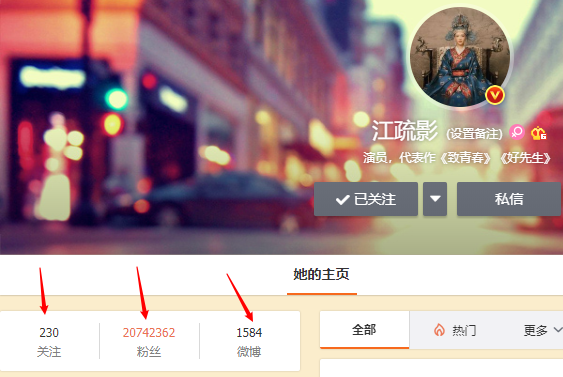
Legen Sie Benutzerinformationen für Big V in Redis fest, indem Sie den Benutzerprimärschlüssel und die Attribute wie folgt verwenden Der Umsetzungsfall. 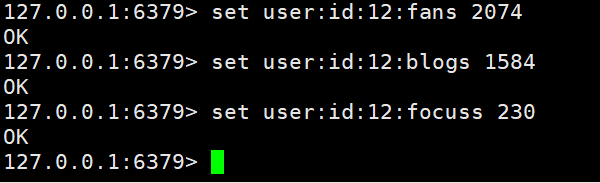
Hier müssen wir kurz über die Benennungsregeln des Schlüssels sprechen: Tabellenname + Primärschlüssel + Primärschlüsselwert + Feld: Feldwert. Die Benennung nach solchen Regeln kann unsere Schlüsselwerte sehr gut verwalten.
Wir können dies auch auf andere Weise erreichen, indem wir dem Schlüssel direkt eine Struktur folgen, z. B. 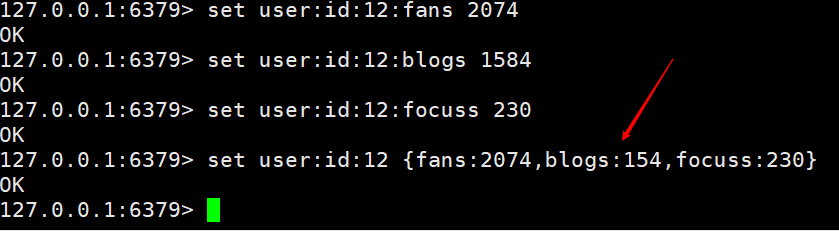
Beide oben genannten Methoden können Ja, es ist nur so, dass der erste Wert problemlos verwaltet werden kann, während der zweite Wert jedes Mal geändert werden muss und je nach Geschäftsszenario regelmäßig aktualisiert werden kann.
Daten hinzufügen/ändern: hset key field value
Daten abrufen: hget key field |. hgetall key
Mehrere Daten hinzufügen/ändern: hmset key field value field1 value1
Mehrere Daten abrufen: hmget key field field1
Tabellennummer abrufen Felder: hlen key
Ermittelt, ob ein Feld in der Tabelle vorhanden ist: hexists key field
Alle Feldwerte in der Hash-Tabelle abrufen: hkeys key
Alle Feldwerte in der Hash-Tabelle abrufen: hvals key
Legen Sie den Wert des angegebenen Felds fest und erhöhen Sie den Wert des angegebenen Bereichs: hincrby key field increment | >2-3 Hash-Geschäftsszenario-Warenkorbhincrbyfloat key field increment
Dieses Bild ist nicht selbstgemacht aus dem Internet, es simuliert nur die Warenkorbszene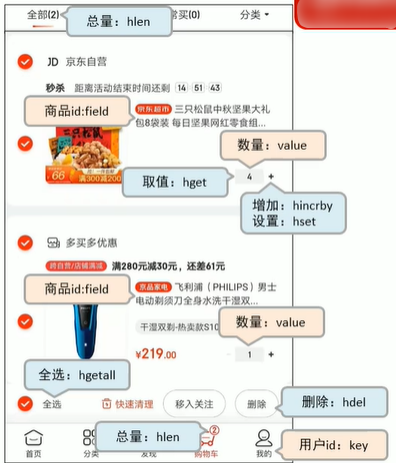
Im Bild oben können wir die Informationen im Warenkorb sehen. Als nächstes verwenden wir redis, um diese Warenkorb-Implementierung zu verarbeiten.
Hier implementieren wir das Hinzufügen eines Warenkorbs und das Abrufen eines Warenkorbs. Die Schlüssel heißen Tabellenname + Primärschlüssel + Primärschlüsselwert 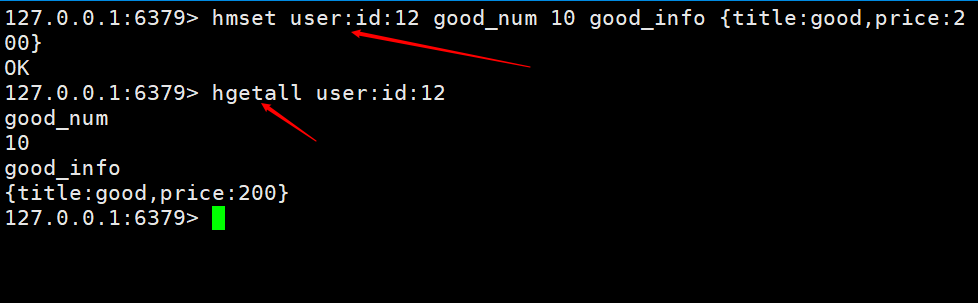
Oben Bild: Ein Problem, das wir haben, besteht darin, dass es bei der Speicherung von Produktinformationen zu einer großen Menge an Duplikaten kommt, sodass wir die Produkte auch einzeln hashen müssen. Wie unten gezeigt, wird nur die Produkt-ID gespeichert 
Es gibt zwei Einstellungsmethoden: Eine besteht darin, mehrere Felder festzulegen, und die andere darin, sie direkt als JSON zu speichern. Wenn sich die Informationen nicht häufig ändern, können Sie json 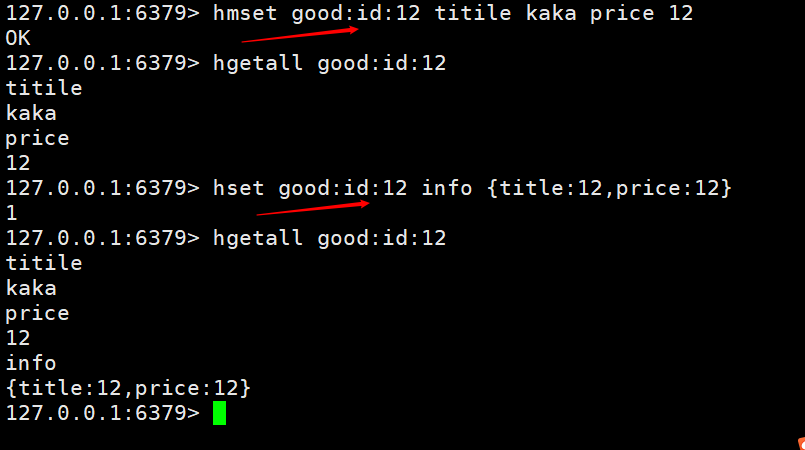
verwenden, um eine Methode bereitzustellen hsetnx key field value. Wenn sie vorhanden ist, wird sie nicht hinzugefügt, andernfalls wird sie hinzugefügt. Diese Funktion wird verwendet, um Überschreibungen und unnötige Vorgänge zu vermeiden, wenn verschiedene Benutzer dasselbe Produkt hinzufügen 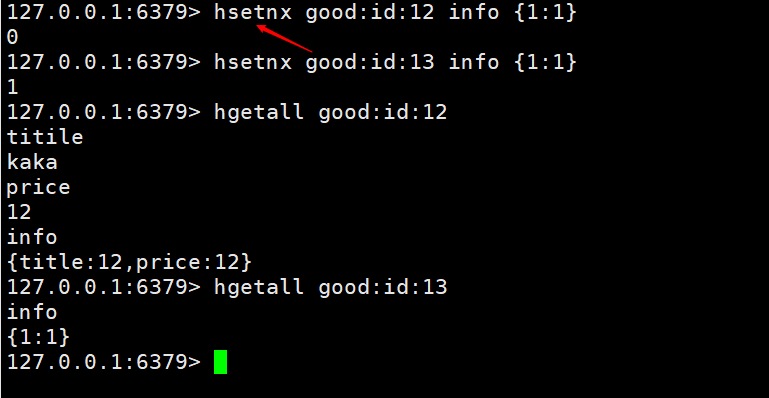
Datenspeicheranforderungen: Speichern Sie mehrere Daten und unterscheiden Sie die Reihenfolge der Datenspeicherplätze.
Erforderliche Datenstruktur: Ein Speicherplatz speichert mehrere Daten. Die Eingabereihenfolge kann durch die Daten widergespiegelt werden.
Liste Typ: Speichern Sie mehrere Daten. Die unterste Ebene verwendet eine doppelt verknüpfte Listenspeicherstruktur, um
|
Daten abrufen:lrange key start end |. lindex key indexllen key
rpop keylpop key
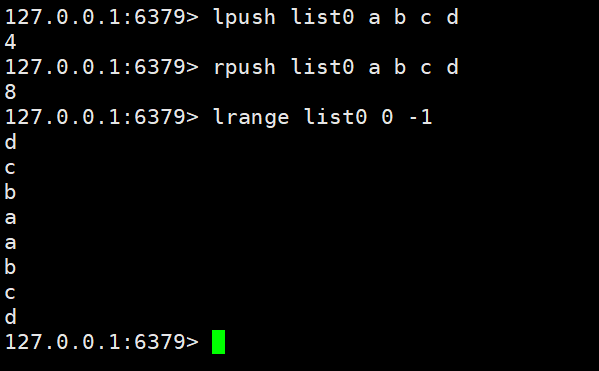 3-2 Erweiterte Operationen für Listentypdaten
3-2 Erweiterte Operationen für Listentypdaten
Daten innerhalb der angegebenen Zeit abrufen und entfernen: blpop key1 key2 timeout | brpop key1 key2 timeout
Diese Funktion ist einfach, einen Fall zu schreiben und leicht zu verstehen
Nachdem der Terminalbefehl auf der linken Seite ausgeführt wurde, wird 30 Sekunden gewartet, um die gelöschten Daten zurückzugeben.
Wenn der Befehl zum Hinzufügen auf der rechten Seite ausgeführt wird, wird die linke Seite angezeigt gibt die gelöschten Daten direkt zurück
Oben wir Kennen Sie die grundlegenden Operationen zum Auflisten und Ausführen der lpop-Taste. Oder die rpop-Taste kann von der Seite oder von rechts gelöscht werden, aber jetzt gibt es ein Szenario, in dem der Freundeskreis wie ein Unternehmen verwendet wird und dann die Daten aus der Mitte gelöscht werden . Der Fall ist wie unten dargestellt
Wir fügen zuerst ein b c d
zu Liste5 hinzu und entfernen dann c
Nach der Überprüfung bleibt nur noch ein b d übrig 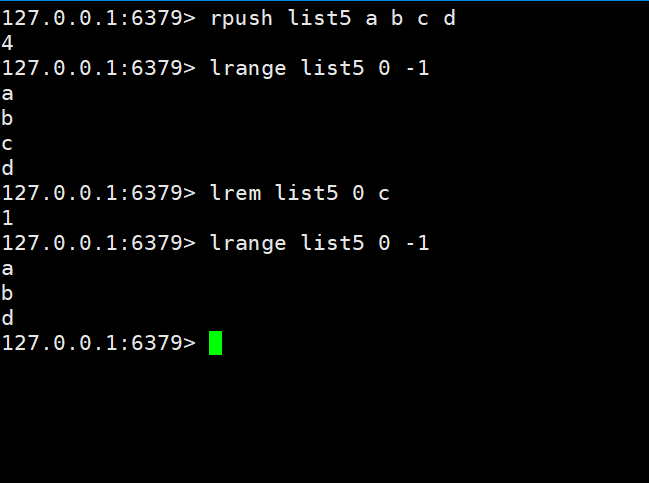
Neue Speicheranforderungen: Speichern einer großen Datenmenge und höhere Effizienz bei der Abfragefreundlichkeit
Erforderliche Speicherstruktur: Kann eine große Datenmenge speichern Daten Daten, effizienter interner Speichermechanismus, einfach abzufragen
Satztyp: genau wie die Hash-Speicherstruktur, speichert nur Schlüssel, keine Werte (Null), und Werte dürfen nicht wiederholt werden
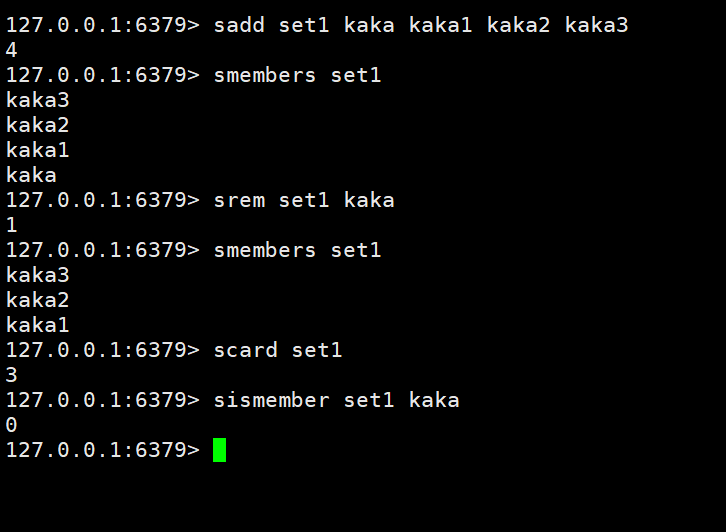
Daten hinzufügen/ändern: sadd key member member1
Daten abrufen: smembers key
Daten löschen: srem key member1
Gesamtmenge der Erfassungsdaten abrufen: scard key
Bestimmen Sie, ob die angegebenen Daten in der Sammlung enthalten sind: sismember key member
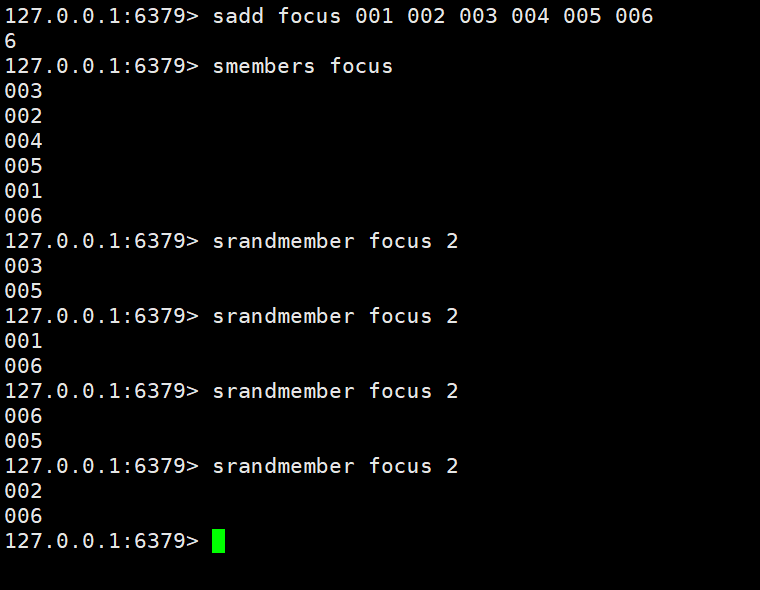
Erhalten Sie zufällig die angegebene Datenmenge im Satz: srandmember key count
Rufen Sie nach dem Zufallsprinzip bestimmte Daten in der Sammlung ab und entfernen Sie den geänderten Datensatz aus der Sammlung: spop key
Pushen Sie nach dem Zufallsprinzip aktuelle Informationen, aktuelle Nachrichten, beliebte Reisen, Anwendungs-App-Empfehlungen, Folgeempfehlungen usw.
Da Kaka kürzlich Discuz schreibt, ist dieser Fall eine Empfehlung für Aufmerksamkeit.
Fall 1: Speichern Sie entsprechende Benutzer im Satz gemäß einem bestimmten Empfehlungsmechanismus und erhalten Sie dann nach dem Zufallsprinzip 2 Benutzer, die jedes Mal empfohlen werden müssen
Fall 2: Speichern Sie entsprechende Benutzer im Set gemäß einem bestimmten Empfehlungsmechanismus, und dann können die täglich basierend auf dem Datum empfohlenen Benutzer nicht wiederholt werden

Schnittpunkt, Fusions- und Differenzmenge
sinter key key1 sunion key key1 sdiff key key1
Die Schnittmenge, die Vereinigungsmenge und die Differenzmenge zweier Mengen werden in der angegebenen Menge gespeichert
sinterstore destination key1 key2 sunionstore destination key1 key2 sdiffstore destination key1 key2
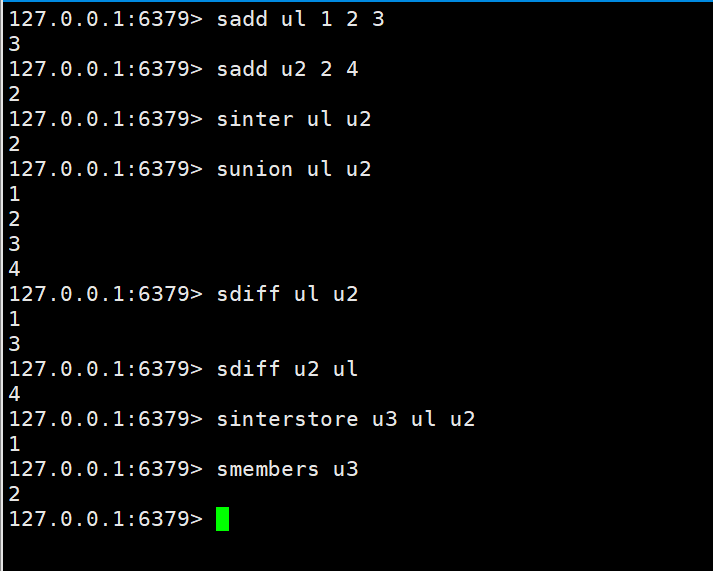
案例:我们需要挖掘一个信息的共同好友。例如微信公众号的共同关注好友数量、QQ添加新好友的推荐机制、深度挖掘用户直接的联系
就根据上述案例,我们可以使用差集来实现qq的有可能认识的好友。
PV直接使用string类型的incr统计即可
UV和IP都是独立不重复的,使用set来操作。
在上边我们知道set有一个特性就是不能重复,我们就可以根据这一点来轻松实现这个功能。然后使用scard key 来统计数量。
Was UV betrifft, können Sie als unabhängiger Besucher lokale Cookies verwenden, um dies zu erreichen. Auf die gleiche Weise können Sie das Cookie zur Aufzeichnung an Redis übergeben 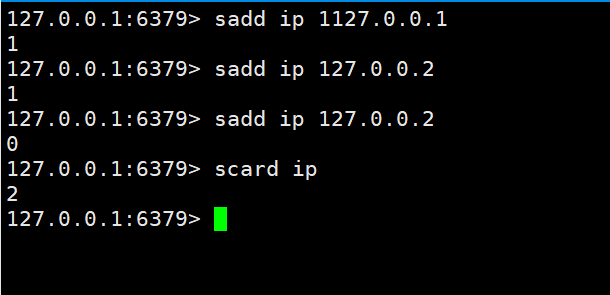
Keiner der vorherigen vier Typen unterstützt sowohl das Speichern von Big Data als auch die Sortierfunktion
Daten hinzufügen: zadd key score member
Daten abrufen: zrange key start stop | zrevrange key start stop
Daten löschen: zrem key member
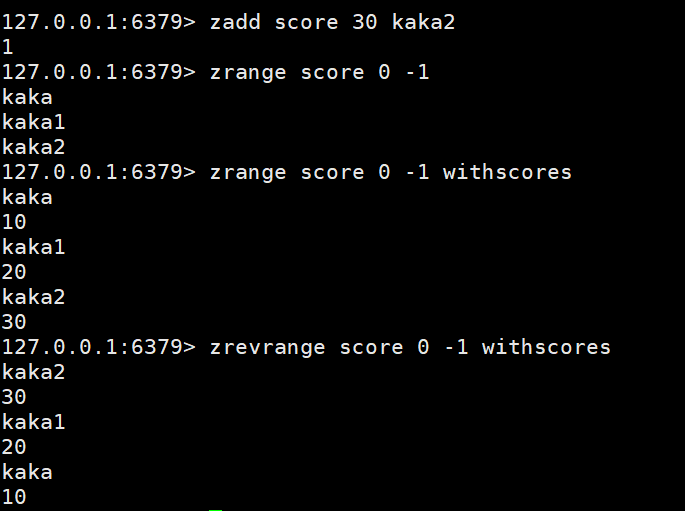
Daten nach Bedingung abrufen: zrangebyscore key min max limit | zrevrangescore key max min
Daten bedingt löschen: zremrangebyrank key start stop | zremrangebyscore key min max
Gesamtmenge der Erfassungsdaten abrufen: zcard key | zcount key min max
Schnittpunkt und Vereinigungsoperation festlegen: zinterstore destination numkeys key | zunionstore destination numkeys key(Dieser Befehl wird nicht demonstriert, Sie können die Dokumentation selbst überprüfen. Er ähnelt set, außer dass die Summe aller Schnittpunkte addiert wird. Dann hier ist Der Parameter numkeys ist die Gesamtzahl der für die Berechnung erforderlichen Schlüssel)
Erhalten Sie den Index, der den Daten entspricht: zrank key member | zrevrank key member
Socre Werterfassung und -änderung: zscore key member | zincrby key increment member
Das Obige ist eine kurze Einführung in Redis-Datentypen Spezifische Anwendungen werden in den folgenden Kapiteln basierend auf spezifischen Anforderungen durchgeführt.
Das obige ist der detaillierte Inhalt vonEin Artikel zum Verständnis der fünf wichtigsten Datentypen und Anwendungsszenarien von Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?










![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



