

 Datenbank
MySQL-Tutorial
Detaillierte Einführung in die Transaktionsisolationsstufe von MySQL (mit Code)
Datenbank
MySQL-Tutorial
Detaillierte Einführung in die Transaktionsisolationsstufe von MySQL (mit Code)
Detaillierte Einführung in die Transaktionsisolationsstufe von MySQL (mit Code)

Dieser Artikel bietet Ihnen eine detaillierte Einführung in die Transaktionsisolationsstufe von MySQL (mit Code). Ich hoffe, dass er für Sie hilfreich ist . Hilft.
1. Die vier Merkmale von Transaktionen (ACID)
Die vier Merkmale von Transaktionen, die Sie verstehen müssen, bevor Sie die Transaktionsisolationsstufe verstehen.
1. Atomizität
Nachdem die Transaktion gestartet ist, sind alle Vorgänge entweder abgeschlossen oder nicht abgeschlossen. Eine Transaktion ist ein unteilbares Ganzes. Wenn während der Ausführung der Transaktion ein Fehler auftritt, wird sie auf den Zustand vor Beginn der Transaktion zurückgesetzt, um die Integrität der Transaktion sicherzustellen. Ähnlich wie bei der physikalischen Erklärung von Atomen: Es handelt sich um Grundteilchen, die bei chemischen Reaktionen nicht weiter geteilt werden können. Atome sind bei chemischen Reaktionen unteilbar.
2. Konsistenz
Nachdem die Transaktion gestartet und beendet wurde, kann die Richtigkeit der Datenbankintegritätsbeschränkungen, also der Integrität der Daten, sichergestellt werden. Wenn A beispielsweise im klassischen Transferfall Geld an B überweist, müssen wir sicherstellen, dass A das Geld abzieht und B das Geld definitiv erhält. Mein persönliches Verständnis ähnelt der Energieerhaltung in der Physik.
3. Isolation
Vollständige Isolation zwischen Transaktionen. Beispielsweise überweist A Geld auf eine Bankkarte, um zu vermeiden, dass zu viele Vorgänge gleichzeitig zu einem Verlust des Kontobetrags führen. Daher sind keine weiteren Vorgänge auf dieser Karte zulässig, bevor die Überweisung von A abgeschlossen ist.
4. Haltbarkeit
Die Auswirkungen von Transaktionen auf Daten sind dauerhaft. Die gängige Erklärung ist, dass die Datenoperationen nach Abschluss der Transaktion auf der Festplatte gespeichert werden müssen (Persistenz). Sobald eine Transaktion abgeschlossen ist, ist sie im Hinblick auf Datenbankoperationen nicht rückgängig zu machen.
2. Probleme mit der Parallelität von Transaktionen
Im Zeitalter des Internets besteht der Wert von Programmen nicht mehr darin, Menschen bei der Lösung komplexer Geschäftslogiken in traditionellen Branchen zu helfen. Im Zeitalter des Internets, in dem die Benutzererfahrung an erster Stelle steht, ist Code wie die Schritte der Programmierer an der U-Bahn-Station Xierqi: Geschwindigkeit, Geschwindigkeit, Geschwindigkeit. Natürlich kann man nicht in die falsche Richtung sitzen. Ich wollte ursprünglich nach Xizhimen und landete in Dongzhimen (nehmen wir das vorerst als richtig an). Im Vergleich zur komplexen Geschäftslogik traditioneller Branchen legt das Internet mehr Wert auf die Geschwindigkeit und Leidenschaft, die die Parallelität den Programmen verleiht. Natürlich hat Geschwindigkeitsüberschreitung ihren Preis. Bei gleichzeitigen Transaktionen wird der arme Programmierer davonlaufen, wenn er nicht aufpasst.
1. Schmutziges Lesen
wird auch als ungültiges Datenlesen bezeichnet. Eine Transaktion, die Daten liest, die noch nicht von einer anderen Transaktion festgeschrieben wurden, wird als Dirty Read bezeichnet.
Zum Beispiel: Transaktion T1 hat eine Datenzeile geändert, die jedoch noch nicht übermittelt wurde. Zu diesem Zeitpunkt hat Transaktion T2 die von Transaktion T1 geänderten Daten gelesen. Später wurde die Transaktion T1 aus irgendeinem Grund zurückgesetzt Beim Lesen von Transaktion T2 handelt es sich um schmutzige Daten.
2. Nicht wiederholbares Lesen
In derselben Transaktion sind die gleichen Daten, die mehrmals gelesen werden, inkonsistent.
Zum Beispiel: Transaktion T1 liest bestimmte Daten, Transaktion T2 liest und ändert die Daten und T1 liest die Daten erneut, um den gelesenen Wert zu überprüfen, und erhält unterschiedliche Ergebnisse.
3. Phantomlesung
Es ist schwer zu erklären, geben wir einfach ein Beispiel:
In der Lagerverwaltung muss der Administrator eine Charge angeben Wenn Waren in die Lagerverwaltung gelangen, müssen Sie vor dem Eingang in das Lager natürlich prüfen, ob ein früherer Eingangsdatensatz vorhanden ist, um die Richtigkeit sicherzustellen. Administrator A stellt sicher, dass das Produkt nicht im Lager vorhanden ist, und lagert das Produkt dann ein, wenn Administrator B das Produkt aufgrund seiner schnellen Hände bereits eingelagert hat. Zu diesem Zeitpunkt stellte Administrator A fest, dass sich das Produkt bereits im Inventar befand. Es war, als wäre gerade eine Phantomlesung passiert, etwas, das vorher nicht existierte, und plötzlich hatte er es.
Hinweis: Die drei Arten von Fragen scheinen schwer zu verstehen zu sein. Der Fokus liegt auf der Richtigkeit der Daten. Die Nichtwiederholbarkeit konzentriert sich auf die Änderung von Daten, während sich das Phantomlesen auf das Hinzufügen und Löschen von Daten konzentriert.
3. Die vier Transaktionsisolationsstufen von MySQL
Im vorherigen Kapitel haben wir etwas über die Auswirkungen auf Transaktionen bei hoher Parallelität gelernt. Die vier Isolationsstufen von Transaktionen sind Lösungen für die oben genannten drei Probleme.
| 隔离级别 | 脏读 | 不可重复度 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 可串行化(serializable) | 否 | 否 | 否 |
4. SQL demonstriert vier Isolationsstufen
MySQL-Version: 5.6
Speicher-Engine: InnoDB
Tool: navicat
Anweisung zur Tabellenerstellung:
CREATE TABLE `tb_bank` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(16) COLLATE utf8_bin DEFAULT NULL, `account` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (1, '小明', 1000);
1. Demonstrieren Sie durch SQL------read-uncommitted Dirty Reading
(2) Dirty Reading durch Read-Uncommit
Das sogenannte Dirty Reading Bei zwei Transaktionen kann eine Transaktion die nicht festgeschriebenen Daten der anderen Transaktion lesen.
Szenario: Sitzung1 möchte 200 Yuan überweisen, Sitzung2 überweist 100 Yuan. Die Basis ist 1000. Das korrekte Ergebnis für einen erfolgreichen Abschluss sollte 900 Yuan betragen. Wir gehen jedoch davon aus, dass Sitzung2 aus irgendeinem Grund in ein Transaktions-Rollback überführt wird. Das korrekte Ergebnis sollte zu diesem Zeitpunkt 800 Yuan betragen.
Demonstrationsschritte:
① Erstellen Sie zwei neue Sitzungen (Sitzungen erscheinen als zwei Abfragefenster in Navicat und sind auch zwei Fenster in der MySQL-Befehlszeile) und führen Sie jeweils
select @@tx_isolation;//查询当前事务隔离级别 set session transaction isolation level read uncommitted;//将事务隔离级别设置为 读未提交
aus ② Beide Sitzungen eröffnen Transaktionen
start transaction;//开启事务
③ Sitzung1 und Sitzung2: Beweisen Sie, dass der Kontostand vor der Ausführung der beiden Vorgänge 1000 beträgt
select * from tb_bank where id=1;//查询结果为1000
④ Sitzung2: Zu diesem Zeitpunkt wird davon ausgegangen, dass die Aktualisierung von session2 wird zuerst ausgeführt.
update tb_bank set account = account + 100 where id=1;
⑤ Sitzung1: Sitzung1 beginnt mit der Ausführung, bevor Sitzung2 festgeschrieben wird.
select * from tb_bank where id=1;//查询结果:1100
⑥ Sitzung2: Aus irgendeinem Grund ist die Übertragung fehlgeschlagen und die Transaktion wurde zurückgesetzt.
rollback;//事务回滚 commit;//提交事务
⑦ Zu diesem Zeitpunkt beginnt Sitzung1 mit der Übertragung und Sitzung1 geht davon aus, dass das Abfrageergebnis 1100 in ⑤ die richtigen Daten sind.
update tb_bank set account=1100-200 where id=1; commit;
⑧ Sitzung1- und Sitzung2-Abfrageergebnisse
select * from tb_bank where id=1;//查询结果:900
Zu diesem Zeitpunkt stellten wir fest, dass die endgültigen Daten aufgrund fehlerhafter Lesevorgänge in Sitzung1 inkonsistent waren. Das korrekte Ergebnis sollte 800 sein;
Wie können wir an dieser Stelle Dirty Reads vermeiden? Erhöhen Sie die Isolationsstufe der Transaktion für Read-Commit
(2) Read-Commit löst Dirty Reads
Setzen Sie die Daten zurück und stellen Sie die Daten auf Konto=1000 wieder her
① Erstellen Sie zwei neue Sitzungen und legen Sie fest
set session transaction isolation level read committed;//将隔离级别设置为 不可重复读
Wiederholen Sie die Schritte ②③④ in (1)
⑤ Sitzung1 führt die aus query
select * from tb_bank where id=1;//查询结果为1000,这说明 不可重复读 隔离级别有效的隔离了两个会话的事务。
Zu diesem Zeitpunkt stellten wir fest, dass die Aktualisierung der Transaktionsisolation auf „Read-Committed“ die beiden Transaktionen effektiv isolierte, wodurch es für die Transaktion in Sitzung1 unmöglich wurde, die von der Transaktion in Sitzung2 vorgenommenen Datenänderungen abzufragen. Dirty Reads werden effektiv vermieden.
2. Demonstrieren Sie durch SQL ----- Nicht wiederholbares Lesen mit Lese-Commit
(1) Nicht wiederholbares Lesen mit Lese-Commit
Setzen Sie die Daten so zurück, dass Die Daten werden auf Konto = 1000 wiederhergestellt
Der sogenannte nicht wiederholbare Lesevorgang bedeutet, dass eine Transaktion die Daten einer anderen nicht festgeschriebenen Transaktion nicht lesen kann, aber die übermittelten Daten. Zu diesem Zeitpunkt sind die Ergebnisse der beiden Messungen inkonsistent. Es handelt sich also um eine nicht wiederholbare Lektüre.
Unter der Isolationsstufe READ COMMITTED wird für jeden Lesevorgang ein Snapshot neu generiert, sodass jeder Snapshot der neueste ist. Daher kann jedes SELECT in der Transaktion auch die von anderen festgeschriebenen Transaktionen vorgenommenen Änderungen sehen.
Szenario: Sitzung1 wird ausgeführt Kontoabfrage und Sitzung2 führt eine Kontoübertragung von 100 durch.
Sitzung1 öffnet eine Transaktion, um das Konto abzufragen und zu aktualisieren. Zu diesem Zeitpunkt öffnet Sitzung2 auch eine Transaktion für das Konto und aktualisiert es. Das richtige Ergebnis sollte sein, dass die von der Abfrage nach dem Start der Transaktion durch Sitzung1 gelesenen Ergebnisse dieselben sein sollten.
① Erstellen Sie zwei neue Sitzungen und legen Sie
set session transaction isolation level read committed;
② Sitzung1 und Sitzung2 fest, um jeweils Transaktionen zu öffnen
start transaction;
③ Die erste Abfrage von Sitzung1:
select * from tb_bank where id=1;//查询结果:1000
④ Sitzung2-Updates:
update tb_bank set account = account+100 where id=1; select * from tb_bank where id=1;//查询结果:1100
⑤ Zweite Abfrage von Sitzung1:
select * from tb_bank where id=1;//查询结果:1100。和③中查询结果对比,session1两次查询结果不一致。
Wenn man sich die Abfrageergebnisse ansieht, kann man erkennen, dass die wiederholten Leseergebnisse von Sitzung1 beim Öffnen der Transaktion inkonsistent sind Sie können die Isolationsstufe der Lese-Commit-Transaktion sehen. Sie kann nicht wiederholt gelesen werden. Offensichtlich ist dieses Ergebnis nicht das, was wir wollen.
(2) wiederholbares Lesen
Setzen Sie die Daten zurück und stellen Sie die Daten auf Konto=1000 wieder her
① Erstellen Sie zwei neue Sitzungen und legen Sie
set session transaction isolation level repeatable read;bzw.
fest Wiederholen Sie ②③④
⑤ session1 zweite Abfrage in (1):
select * from tb_bank where id=1;//查询结果为:1000
Aus den Ergebnissen ist ersichtlich, dass unter der Isolationsstufe von wiederholbarem Lesen die Ergebnisse mehrerer Lesevorgänge nicht von anderen Transaktionen beeinflusst werden von. Es kann wiederholt gelesen werden. Hier stellt sich eine Frage: Das von Sitzung1 gelesene Ergebnis ist immer noch das Ergebnis vor der Aktualisierung von Sitzung2. Kann das korrekte Ergebnis von 1200 erhalten werden, indem 100 in Sitzung1 weiter übertragen werden?
Vorgang fortsetzen:
⑥ Sitzung 1 auf 100 übertragen:
update tb_bank set account=account+100 where id=1;
Ich fühle mich hier betrogen, sperren, sperren, sperren. Die Update-Anweisung von Sitzung1 ist blockiert. Erst nachdem die Aktualisierungsanweisung in Sitzung2 festgeschrieben wurde, kann die Ausführung in Sitzung1 fortgesetzt werden. Das Ausführungsergebnis der Sitzung ist 1200. Zu diesem Zeitpunkt wird festgestellt, dass Sitzung 1 nicht mit 1000 + 100 berechnet wird, da der MVCC-Mechanismus unter der Isolationsstufe des wiederholbaren Lesens verwendet wird und der Auswahlvorgang die Versionsnummer nicht aktualisiert , ist aber eine Snapshot-Lesung (historische Version). Durch Einfügen, Aktualisieren und Löschen wird die Versionsnummer aktualisiert, bei der es sich um die aktuell gelesene Version (aktuelle Version) handelt.
3. Demonstrieren Sie durch SQL-Phantom-Lesen von wiederholbarem Lesen
在业务逻辑中,通常我们先获取数据库中的数据,然后在业务中判断该条件是否符合自己的业务逻辑,如果是的话,那么就可以插入一部分数据。但是mysql的快照读可能在这个过程中会产生意想不到的结果。
场景模拟:
session1开启事务,先查询有没有小张的账户信息,没有的话就插入一条。这是session2也执行和session1同样的操作。
准备工作:插入两条数据
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (2, '小红', 800); INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (3, '小磊', 6000);
(1)repeatable-read的幻读
① 新建两个session都执行
set session transaction isolation level repeatable read; start transaction; select * from tb_bank;//查询结果:(这一步很重要,直接决定了快照生成的时间)
结果都是:
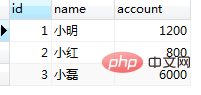
② session2插入数据
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000); select * from tb_bank;
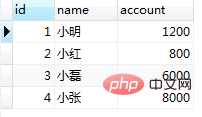
结果数据插入成功。此时session2提交事务
commit;
③ session1进行插入
插入之前我们先看一下当前session1是否有id=4的数据
select * from tb_bank;
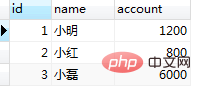
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。继续执行:
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000);

结果插入失败,提示该条已经存在,但是我们查询里面并没有这一条数据啊。为什么会插入失败呢?
因为①中的select语句生成了快照,之后的读操作(未加读锁)都是进行的快照读,即在当前事务结束前,所有的读操作的结果都是第一次快照读产生的快照版本。疑问又来了,为什么②步骤中的select语句读到的不是快照版本呢?因为update语句会更新当前事务的快照版本。具体参阅第五章节。
(2)repeatable-read利用当前读解决幻读
重复(1)中的①②
③ session1进行插入
插入之前我们先看一下当前session1是否有id=4的数据
select * from tb_bank;
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。
select * from tb_bank lock in share mode;//采用当前读
结果:发现当前结果中已经有小张的账户信息了,按照业务逻辑,我们就不在继续执行插入操作了。
这时我们发现用当前读避免了repeatable-read隔离级别下的幻读现象。
4、serializable隔离级别
在此级别下我们就不再做serializable的避免幻读的sql演示了,毕竟是给整张表都加锁的。
五、当前读和快照读
本想把当前读和快照读单开一片博客,但是为了把幻读总结明白,暂且在本章节先简单解释下快照读和当前读。后期再追加一篇MVCC,next-key的博客吧。。。
1、快照读:即一致非锁定读。
① InnoDB存储引擎下,查询语句默认执行快照读。
② RR隔离级别下一个事务中的第一次读操作会产生数据的快照。
③ update,insert,delete操作会更新快照。
四种事务隔离级别下的快照读区别:
① read-uncommitted和read-committed级别:每次读都会产生一个新的快照,每次读取的都是最新的,因此RC级别下select结果能看到其他事务对当前数据的修改,RU级别甚至能读取到其他未提交事务的数据。也因此这两个级别下数据是不可重复读的。
② repeatable-read级别:基于MVCC的并发控制,并发性能极高。第一次读会产生读数据快照,之后在当前事务中未发生快照更新的情况下,读操作都会和第一次读结果保持一致。快照产生于事务中,不同事务中的快照是完全隔离的。
③ serializable级别:从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。Serializable隔离级别下,读写冲突,因此并发度急剧下降。(锁表,不建议使用)
2、当前读:即一致锁定读。
如何产生当前读
① select ... lock in share mode
② select ... for update
③ update,insert,delete操作都是当前读。
读取之后,还需要保证当前记录不能被其他并发事务修改,需要对当前记录加锁。①中对读取记录加S锁 (共享锁),②③X锁 (排它锁)。
3、疑问总结
① update,insert,delete操作为什么都是当前读?
简单来说,不执行当前读,数据的完整性约束就有可能遭到破坏。尤其在高并发的环境下。
分析update语句的执行步骤:update table set ... where ...;
Die InnoDB-Engine führt zuerst die Where-Abfrage durch. Die abgefragte Ergebnismenge beginnt mit der ersten und führt den aktuellen Lesevorgang durch, führt dann den Aktualisierungsvorgang durch, liest dann die aktuellen zweiten Daten und führt den Aktualisierungsvorgang aus ... Also alle Zeit Das Ausführen von Updates wird vom aktuellen Lesen begleitet. Dasselbe gilt auch für das Löschen. Schließlich müssen die Daten erst gefunden werden, bevor sie gelöscht werden können. Das Einfügen ist etwas anders. Vor der Ausführung des Einfügevorgangs muss eine eindeutige Schlüsselprüfung durchgeführt werden. [Verwandte Empfehlungen: MySQL-Tutorial]
Das obige ist der detaillierte Inhalt vonDetaillierte Einführung in die Transaktionsisolationsstufe von MySQL (mit Code). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Best Practices für die Verwaltung großer MySQL -Tische
Aug 05, 2025 am 03:55 AM
Best Practices für die Verwaltung großer MySQL -Tische
Aug 05, 2025 am 03:55 AM
MySQL Performance und Wartbarkeit stehen vor Herausforderungen mit großen Tabellen, und es ist notwendig, von der Strukturdesign, der Indexoptimierung, der Tabellen-Untertisch-Strategie usw. zu beginnen. 1. Ausgestaltet Primärschlüssel und -indizes: Es wird empfohlen, Selbstverlustzahlen als Primärschlüssel zu verwenden, um Seitenspaltungen zu reduzieren. Verwenden Sie Overlay -Indizes, um die Effizienz der Abfrage zu verbessern. Analysieren Sie regelmäßig langsame Abfrageprotokolle und löschen Sie ungültige Indizes. 2. Rationaler Nutzung von Partitionstabellen: Partition nach Zeitbereich und anderen Strategien zur Verbesserung der Abfrage- und Wartungseffizienz, aber der Aufteilung und dem Abschneiden von Problemen sollte die Aufmerksamkeit geschenkt werden. 3.. Überlegen Sie, wie Sie Lesen und Schreiben von Trennung und Bibliothekstrennung erwägen: Lesen und Schreiben von Trennung lindern den Druck auf die Hauptbibliothek. Die Bibliothekstrennung und die Tabellentrennung eignen sich für Szenarien mit einer großen Datenmenge. Es wird empfohlen, Middleware zu verwenden und Transaktions- und Cross-Store-Abfrageprobleme zu bewerten. Frühe Planung und kontinuierliche Optimierung sind der Schlüssel.
 Wie kann ich Überprüfungsbeschränkungen verwenden, um Datenregeln in MySQL durchzusetzen?
Aug 06, 2025 pm 04:49 PM
Wie kann ich Überprüfungsbeschränkungen verwenden, um Datenregeln in MySQL durchzusetzen?
Aug 06, 2025 pm 04:49 PM
MySQL unterstützt die Einschränkungen der Domänenintegrität, die aus Version 8.0.16 wirksam sind. 1. Hinzufügen von Einschränkungen beim Erstellen einer Tabelle: Verwenden Sie CreateTable, um die Kontrollbedingungen wie das Alter ≥ 18, Gehalt> 0, Grenzwerte der Abteilung zu definieren. 2. Ändern Sie die Tabelle, um Einschränkungen hinzuzufügen: Verwenden Sie AlterTableLeaddConstraint, um die Feldwerte zu begrenzen, z. B. nicht leer; 3.. Verwenden Sie komplexe Bedingungen: Unterstützen Sie die Multi-Säulen-Logik und -ausdrücke, z. B. Enddatum ≥ Start-Datum und Abschlussstatus müssen ein Enddatum haben. 4. Einschränkungen löschen: Verwenden Sie die zum Löschen von Namen angeben Sie den Namen angeben. 5. Anmerkungen: MySQL8.0.16, InnoDB oder MyiSam müssen zitiert werden
 Wie implementieren Sie ein Tagging -System in einer MySQL -Datenbank?
Aug 05, 2025 am 05:41 AM
Wie implementieren Sie ein Tagging -System in einer MySQL -Datenbank?
Aug 05, 2025 am 05:41 AM
Useeamany-to-manyrelationship withajunctionTabletolinkiTemSandTagsviathreetables: Elemente, Tags und ITEM_TAGS.2.WhenaddingTags, CheckforexistingTagSinthetagStable, Insertifnitary.
 So zeigen Sie alle Datenbanken in MySQL
Aug 08, 2025 am 09:50 AM
So zeigen Sie alle Datenbanken in MySQL
Aug 08, 2025 am 09:50 AM
Um alle Datenbanken in MySQL anzuzeigen, müssen Sie den Befehl showDatabases verwenden. 1. Nachdem Sie sich auf dem MySQL -Server angemeldet haben, können Sie die ShowDatabasen ausführen. Befehl zur Auflistung aller Datenbanken, auf die der aktuelle Benutzer zugegriffen hat. 2. Systemdatenbanken wie Information_Schema, MySQL, Performance_schema und System existieren standardmäßig, Benutzer mit unzureichenden Berechtigungen können sie möglicherweise nicht sehen; 3.. Sie können die Datenbank auch durch selectSchema_nameFrominFormation_schema.schemata abfragen und filtern. Beispielsweise ohne die Systemdatenbank, um nur die von den Benutzern erstellte Datenbank anzuzeigen; Stellen Sie sicher
 Wie kann ich gemeinsame MySQL -Verbindungsfehler beheben?
Aug 08, 2025 am 06:44 AM
Wie kann ich gemeinsame MySQL -Verbindungsfehler beheben?
Aug 08, 2025 am 06:44 AM
Überprüfen Sie, ob der MySQL -Dienst ausgeführt wird. Verwenden Sie SudosystemctlstatUSmysql, um zu bestätigen und zu starten. 2. Stellen Sie sicher, dass die Bindungsadresse auf 0,0,0,0 eingestellt ist, um Remote-Verbindungen zu ermöglichen und den Dienst neu zu starten. 3. Überprüfen Sie, ob der 3306 -Port geöffnet ist, und konfigurieren Sie die Firewall -Regeln, um den Port zuzulassen. 4. Für den Fehler "AccessDenied" müssen Sie den Benutzernamen, den Kennwort und den Hostnamen überprüfen und sich dann bei MySQL anmelden und die Tabelle mySQL.User abfragen, um die Berechtigungen zu bestätigen. Erstellen oder aktualisieren Sie den Benutzer bei Bedarf und autorisieren Sie ihn, z. B. "Your_User"@'%". 5. Wenn die Authentifizierung aufgrund von caching_sha2_password verloren geht
 Wie füge ich einer vorhandenen Tabelle in MySQL einen Primärschlüssel hinzu?
Aug 12, 2025 am 04:11 AM
Wie füge ich einer vorhandenen Tabelle in MySQL einen Primärschlüssel hinzu?
Aug 12, 2025 am 04:11 AM
Um einer vorhandenen Tabelle einen Primärschlüssel hinzuzufügen, verwenden Sie die altertable Anweisung mit der AddPrimaryKey -Klausel. 1. Stellen Sie sicher, dass die Zielspalte keinen Nullwert, keine Duplikation hat und als Notnull definiert ist. 2. Die einspaltige Primärschlüsselsyntax ist ein altertierbarer Tabellenname AddPrimaryKey (Spaltenname); 3. Die Multi-Säulen-Kombination der Primärschlüsselsyntax ist der Namen AddPrimaryKey (Spalte 1, Spalte 2); 4. Wenn die Spalte NULL erlaubt, müssen Sie zuerst Änderungen ausführen, um Notnull zu setzen. 5. Jede Tabelle kann nur einen Primärschlüssel haben und der alte Primärschlüssel muss vor dem Hinzufügen gelöscht werden. 6. Wenn Sie es selbst erhöhen müssen, können Sie Modify verwenden, um auto_increment festzulegen. Stellen Sie vor dem Betrieb Daten sicher
 Was ist der Unterschied zwischen Kürzung, Löschen und Tropfen in MySQL?
Aug 05, 2025 am 09:39 AM
Was ist der Unterschied zwischen Kürzung, Löschen und Tropfen in MySQL?
Aug 05, 2025 am 09:39 AM
DeleterEmovesspezifikorallrows, KeepStablestructure, erlaubtRollbackAndtriggers und doesnotresetauto-Inkremente; 2.Truncatequicklyremovesallrows, ResetsAuto-Increment, kann nicht berberollt, die Mostcasen, die Notfiriggers und Keepstructure;
 So sichern Sie eine Datenbank in MySQL
Aug 11, 2025 am 10:40 AM
So sichern Sie eine Datenbank in MySQL
Aug 11, 2025 am 10:40 AM
Die Verwendung von MySQldump ist der häufigste und effektivste Weg, um MySQL -Datenbanken zu sichern. Es kann SQL -Skripte generieren, die Tabellenstruktur und Daten enthalten. 1. Die grundlegende Syntax ist: Mysqldump-U [Benutzername] -P [Datenbankname]> backup_file.sql. Geben Sie nach der Ausführung das Passwort ein, um eine Sicherungsdatei zu generieren. 2. Sicherung mehrere Datenbanken mit-Databasen Option: Mysqldump-uroot-p-databaseSdb1db2> multiple_dbs_backup.sql. 3.. BACKE ALLE Datenbanken mit-alle Daten: Mysqldump-uroot-P
