


Dieser Artikel befasst sich hauptsächlich mit dem Parsen von PHP-Wörtern und dem Abrufen der Bilder im Dokument. Jetzt kann ich ihn mit allen teilen, die ihn benötigen
1. Verstehen Sie die Grundlagen von XML
XML ist ein erweiterbares Markup Sprache ist ein wichtiges Werkzeug für die Internet-Datenübertragung. XML kann ohne Einschränkung durch Programmiersprachen und Betriebssysteme als Datenträger mit dem höchsten Level im Internet bezeichnet werden. XML ist die aktuelle Technologie zur Verarbeitung strukturierter Dokumentinformationen, die dabei hilft, die strukturierte Ausgabe zwischen Servern zu verschieben, sodass Entwickler die Speicherung und Übertragung von Daten bequemer steuern können. XML ist eine Auszeichnungssprache, die verwendet wird Markieren Sie elektronische Dokumente, um sie strukturell zu gestalten. Sie kann zum Markieren von Daten und zum Definieren von Datentypen verwendet werden. Es handelt sich um eine Quellsprache, die es Benutzern ermöglicht, ihre eigene Auszeichnungssprache zu definieren. Es handelt sich um eine Teilmenge der Standard-Allzwecksprache und eignet sich gut für die Webübertragung.Zwei verschiedene Speichermethoden für Word
Zwei Speicherformate für Word-Dokumente: doc und docxdoc: Traditionell Word genannt, verwendet es Binärdateien zum Speichern von Datendocx: Das heißt, Word2007 verwendet XML zum Speichern von DatenDann ist das Suffix offensichtlich im docx-Format, warum ist es im XML-Format ? Wählen Sie eine test.docx aus, ändern Sie den Suffixnamen in .zip und entpacken Sie sie dann, um die folgende Verzeichnisstruktur zu erhalten:
test.xml:test.php:<?xml version="1.0" encoding="utf-8"?><teststore><test>
<name>php dom test</name>
<author>test-one</author></test><test>
<title>php dom test 2</title>
<author>test-two</author></test></teststore>
Nach dem Login kopieren
<?php $doc = new DOMDocument();
$doc->load("test.xml"); //获取标签对象
$book=$doc->getElementsByTagName("test"); //输出第一个中的值
echo $book->item(0)->nodeValue;
echo "<br>----------------<br>";
$title=$doc->getElementsByTagName("name");
echo $title->item(0)->nodeValue;
echo "<br>----------------<br>"; //遍历所有book标签中的内容
foreach ($book as $note)
{
echo $note->nodeValue;
echo "<br>";
}Das Definitionsformat von XML in Word
Wie werden die Daten in Word definiert? ? 
Eine Datei ist word/document.xml, die den Inhalt des gesamten Word-Dokuments definiert. Ein weiterer Ordner ist Word/Media. In diesem Ordner werden die Multimedia-Inhalte des Dokuments gespeichert.
Gesamtstrukturdefinition in document.ml:
<w:document mc:ignorable="w14 w15 wp14" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpscustomdata="http://www.wps.cn/officeDocument/2013/wpsCustomData">
<w:body>
<w:p>
<w:ppr>
<w:pstyle w:val="2">
</w:pstyle>
<w:keepnext w:val="0">
</w:keepnext>
<w:keeplines w:val="0">
</w:keeplines>
<w:widowcontrol>
</w:widowcontrol>
<w:suppresslinenumbers w:val="0">
</w:suppresslinenumbers>
<w:pbdr>
<w:top w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:top>
<w:left w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:left>
<w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bottom>
<w:right w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:right>
</w:pbdr>Dokumentabsatzinhalt:
<w:p>
<w:ppr>
<w:pstyle w:val="2">
</w:pstyle>
<w:keepnext w:val="0">
</w:keepnext>
<w:keeplines w:val="0">
</w:keeplines>
<w:widowcontrol>
</w:widowcontrol>
<w:suppresslinenumbers w:val="0">
</w:suppresslinenumbers>
<w:pbdr>
<w:top w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:top>
<w:left w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:left>
<w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bottom>
<w:right w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:right>
</w:pbdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
<w:spacing w:after="150" w:afterautospacing="0" w:before="150" w:beforeautospacing="0" w:line="378" w:linerule="atLeast">
</w:spacing>
<w:ind w:firstline="0" w:left="0" w:right="0">
</w:ind>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
</w:rpr>
</w:ppr>
<w:r>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
<w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
</w:rpr>
<w:t>
作者: Test </w:t>
</w:r>
</w:p>Bildinhaltsdefinition:
<w:r>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
<w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
</w:rpr>
<w:drawing>
<wp:inline distb="0" distl="114300" distr="114300" distt="0">
<wp:extent cx="5543550" cy="5543550">
</wp:extent>
<wp:effectextent b="0" l="0" r="0" t="0">
</wp:effectextent>
<wp:docpr descr="IMG_256" id="1" name="Picture 1">
</wp:docpr>
<wp:cnvgraphicframepr>
<a:graphicframelocks nochangeaspect="1" xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
</a:graphicframelocks>
</wp:cnvgraphicframepr>
<a:graphic xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
<a:graphicdata uri="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:pic xmlns:pic="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:nvpicpr>
<pic:cnvpr descr="IMG_256" id="1" name="Picture 1">
</pic:cnvpr>
<pic:cnvpicpr>
<a:piclocks nochangeaspect="1">
</a:piclocks>
</pic:cnvpicpr>
</pic:nvpicpr>
<pic:blipfill>
<a:blip r:embed="rId4">
</a:blip>
<a:stretch>
<a:fillrect>
</a:fillrect>
</a:stretch>
</pic:blipfill>
<pic:sppr>
<a:xfrm>
<a:off x="0" y="0">
</a:off>
<a:ext cx="5543550" cy="5543550">
</a:ext>
</a:xfrm>
<a:prstgeom prst="rect">
<a:avlst>
</a:avlst>
</a:prstgeom>
<a:nofill>
</a:nofill>
<a:ln w="9525">
<a:nofill>
</a:nofill>
</a:ln>
</pic:sppr>
</pic:pic>
</a:graphicdata>
</a:graphic>
</wp:inline>
</w:drawing>
</w:r>Fazit: 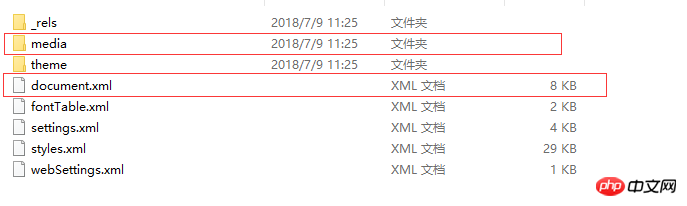
<w:document> 定义整个文档的开始 <w:body> document的子节点,文档的主体内容 <w:p> body的子节点,一个段落,就是word文档中的段落 <w:r> p元素的子节点,一个Run定义了段落中具有相同格式的一段内容 <w:t> Run元素节点的子节点,就是文档的内容 <w:drawing> run元素的子节点,定义了一张图片 <w:inline> drawing子节点,具体应用没有研究 <a:graphic> 定义了图片内容 <pic:blipfill> graphic文档的子节点,定义了图片内容的索引.
Aber leider verwende ich PHP~~~, daher müssen wir das Bild manuell über die entsprechende PHP-Schnittstelle abrufen.
Lassen Sie mich darüber sprechen es unten Die spezifische Idee von
: Rufen Sie den XML-Knoten des docx-Dokuments über die in PHP integrierte 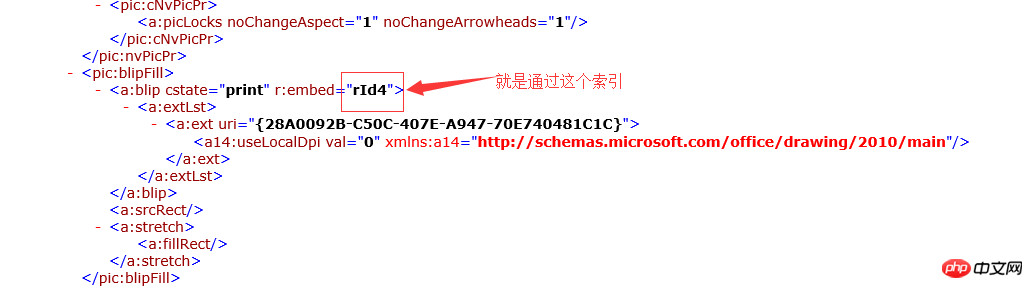 DOMDocument
DOMDocument
ZipArchive
durchlaufen (im Wesentlichen über das komprimierte .zip-Paket), das entsprechende Bild wird über den Index gefunden und konvertiert in Binärdaten umgewandelt und gespleißt. Das img-Tag zeigt Bilddaten im Base64-Format an. In XML konvertieren: Bestimmen Sie, ob es sich um einen Bildknoten handelt: private $rels_xml;
private $doc_xml;
private function readZipPart($filename) {
$zip = new ZipArchive();
$_xml = 'word/document.xml';
$_xml_rels = 'word/_rels/document.xml.rels';
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml)) !== false) {
$xml = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml_rels)) !== false) {
$xml_rels = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
$this->doc_xml = new DOMDocument();
$this->doc_xml->encoding = mb_detect_encoding($xml);
$this->doc_xml->preserveWhiteSpace = false;
$this->doc_xml->formatOutput = true;
$this->doc_xml->loadXML($xml);
$this->doc_xml->saveXML();
$this->rels_xml = new DOMDocument();
$this->rels_xml->encoding = mb_detect_encoding($xml);
$this->rels_xml->preserveWhiteSpace = false;
$this->rels_xml->formatOutput = true;
$this->rels_xml->loadXML($xml_rels);
$this->rels_xml->saveXML();
}Nach dem Login kopieren
if($paragraph->name === 'w:drawing') {
(strstr($ts,'…封…') != false || strstr($ts,'…线…') != false) ? $t .= '' : $t .= $this->analysisDrawing($paragraph);
} private function analysisDrawing(&$drawingXml) {
while($drawingXml->read()) {
if ($drawingXml->nodeType == XMLREADER::ELEMENT && $drawingXml->name === 'a:blip') {
$rId = $drawingXml->getAttribute('r:embed');
$rIdIndex = substr($rId,3);
return $this->checkImageFormating($rIdIndex);
}
}
} private function checkImageFormating($rIdIndex) {
$imgname = 'word/media/image'.($rIdIndex-8);
$zipfileName = __DIR__.DIRECTORY_SEPARATOR.'b'.DIRECTORY_SEPARATOR.'test.docx';
$zip=zip_open($zipfileName);
while($zip_entry = zip_read($zip)) {//读依次读取包中的文件
$file_name=zip_entry_name($zip_entry);//获取zip中的文件名
if(strstr($file_name,$imgname) != '' ) {
$a = ($rIdIndex-8 < 10) ? mb_substr($file_name,mb_strlen($imgname,"utf-8"),1, 'utf-8') : '';
if($rIdIndex-8 < 10 && $a != '.') continue;
if ($enter_zp = zip_entry_open($zip, $zip_entry, "r")) { //读取包中文件
$ext = pathinfo(zip_entry_name ($zip_entry),PATHINFO_EXTENSION);//获取图片文件扩展名
$content = zip_entry_read($zip_entry,zip_entry_filesize($zip_entry));//读取文件二进制数据
return sprintf('<img src="data:image/%s;base64,%s">', $ext, base64_encode($content));//利用base64_encode函数转换读取到的二进制数据并输入输出到页面中
}
zip_entry_close($zip_entry); //关闭zip中打开的项目
}
}
zip_close($zip);//关闭zip文件
}以上就是本文的全部内容,希望对大家的学习有所帮助,更多相关内容请关注PHP中文网!
相关推荐:
Das obige ist der detaillierte Inhalt vonSo verwenden Sie PHP, um Bilder in Dokumenten zu analysieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



