

 Backend-Entwicklung
Python-Tutorial
Ausführliche Erklärung, wie man mit PyTorch schnell ein neuronales Netzwerk aufbaut und speichert und extrahiert
Backend-Entwicklung
Python-Tutorial
Ausführliche Erklärung, wie man mit PyTorch schnell ein neuronales Netzwerk aufbaut und speichert und extrahiert
Ausführliche Erklärung, wie man mit PyTorch schnell ein neuronales Netzwerk aufbaut und speichert und extrahiert

In diesem Artikel wird hauptsächlich der schnelle Aufbau eines neuronalen Netzwerks mit PyTorch vorgestellt und die Speicher- und Extraktionsmethoden ausführlich erläutert. Jetzt teile ich es mit Ihnen und gebe Ihnen eine Referenz. Werfen wir gemeinsam einen Blick darauf
Manchmal haben wir ein Modell trainiert und möchten es für die direkte Verwendung beim nächsten Mal speichern, ohne es beim nächsten Mal erneut trainieren zu müssen. In diesem Abschnitt erklären wir, wie wir schnell ein neuronales Netzwerk aufbauen können PyTorch und seine detaillierte Erklärung der Speicher- und Extraktionsmethode
1. PyTorch-Methode zum schnellen Aufbau eines neuronalen Netzwerks
Schauen Sie sich an Zuerst der experimentelle Code:
import torch
import torch.nn.functional as F
# 方法1,通过定义一个Net类来建立神经网络
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net1 = Net(2, 10, 2)
print('方法1:\n', net1)
# 方法2 通过torch.nn.Sequential快速建立神经网络结构
net2 = torch.nn.Sequential(
torch.nn.Linear(2, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 2),
)
print('方法2:\n', net2)
# 经验证,两种方法构建的神经网络功能相同,结构细节稍有不同
'''''
方法1:
Net (
(hidden): Linear (2 -> 10)
(predict): Linear (10 -> 2)
)
方法2:
Sequential (
(0): Linear (2 -> 10)
(1): ReLU ()
(2): Linear (10 -> 2)
)
'''Zuvor habe ich gelernt, wie man ein neuronales Netzwerk aufbaut, indem man in classNet zunächst die Konstruktionsmethode erbt Erstellen Sie die Strukturinformationen jeder Schicht des neuronalen Netzwerks durch Hinzufügen von Attributen, verbessern Sie die Verbindungsinformationen zwischen jeder Schicht des neuronalen Netzwerks in der Vorwärtsmethode und schließen Sie sie dann ab der Aufbau der neuronalen Netzwerkstruktur durch Definition von Net-Klassenobjekten.
Eine andere Möglichkeit zum Aufbau eines neuronalen Netzwerks, die auch als schnelle Konstruktionsmethode bezeichnet werden kann, besteht darin, den Aufbau des neuronalen Netzwerks direkt über Torch.nn.Sequential abzuschließen.
Die durch die beiden Methoden aufgebauten neuronalen Netzwerkstrukturen sind genau gleich, und die Netzwerkinformationen können über die Druckfunktion ausgedruckt werden, die Druckergebnisse unterscheiden sich jedoch geringfügig.
2. Erhaltung und Extraktion des neuronalen Netzwerks von PyTorch
Wenn wir tiefes Lernen lernen und erforschen, wenn wir eine bestimmte Trainingsphase durchlaufen, wann Wir erhalten ein besseres Modell. Natürlich möchten wir das Modell und die Modellparameter für die spätere Verwendung speichern. Daher ist es erforderlich, das neuronale Netzwerk zu speichern und die Modellparameter zu extrahieren und neu zu laden.
Zuerst müssen wir die Netzwerkstruktur und die Modellparameter über Torch.save() speichern, nachdem der Definitions- und Trainingsteil des neuronalen Netzwerks abgeschlossen ist, der die Netzwerkstruktur und seine Modellparameter speichern muss. Es gibt zwei Speichermethoden: Eine besteht darin, die Strukturinformationen und Modellparameterinformationen des gesamten neuronalen Netzwerks zu speichern, und die andere besteht darin, nur die Trainingsmodellparameter des neuronalen Netzwerks zu speichern Das Objekt des Speicherns ist net.state_dict(). Die gespeicherten Ergebnisse werden in Form von .pkl-Dateien gespeichert.
entspricht den beiden oben genannten Speichermethoden, und es gibt auch zwei Nachlademethoden. Entsprechend den ersten vollständigen Netzwerkstrukturinformationen können Sie das neue neuronale Netzwerkobjekt beim Neuladen direkt über Torch.load(‘.pkl’) initialisieren. Entsprechend der zweiten Methode, bei der nur Modellparameterinformationen gespeichert werden, müssen Sie zunächst dieselbe neuronale Netzwerkstruktur aufbauen und das Neuladen der Modellparameter über net.load_state_dict (torch.load ('.pkl')) abschließen. Wenn das Netzwerk relativ groß ist, dauert die erste Methode länger.
Code-Implementierung:
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 设定随机数种子
# 创建数据
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y = x.pow(2) + 0.2*torch.rand(x.size())
x, y = Variable(x, requires_grad=False), Variable(y, requires_grad=False)
# 将待保存的神经网络定义在一个函数中
def save():
# 神经网络结构
net1 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1),
)
optimizer = torch.optim.SGD(net1.parameters(), lr=0.5)
loss_function = torch.nn.MSELoss()
# 训练部分
for i in range(300):
prediction = net1(x)
loss = loss_function(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 绘图部分
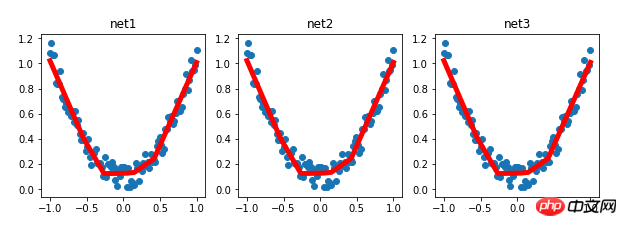
plt.figure(1, figsize=(10, 3))
plt.subplot(131)
plt.title('net1')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
# 保存神经网络
torch.save(net1, '7-net.pkl') # 保存整个神经网络的结构和模型参数
torch.save(net1.state_dict(), '7-net_params.pkl') # 只保存神经网络的模型参数
# 载入整个神经网络的结构及其模型参数
def reload_net():
net2 = torch.load('7-net.pkl')
prediction = net2(x)
plt.subplot(132)
plt.title('net2')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
# 只载入神经网络的模型参数,神经网络的结构需要与保存的神经网络相同的结构
def reload_params():
# 首先搭建相同的神经网络结构
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1),
)
# 载入神经网络的模型参数
net3.load_state_dict(torch.load('7-net_params.pkl'))
prediction = net3(x)
plt.subplot(133)
plt.title('net3')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
# 运行测试
save()
reload_net()
reload_params()
Experimentelle Ergebnisse:
Verwandte Empfehlungen:
So implementieren Sie das Faltungs-Neuronale Netzwerk CNN auf PyTorch
Detaillierte Erläuterung des PyTorch-Batch-Trainings und des Optimierervergleichs
Mnist-Klassifizierungsbeispiel für den Einstieg in Pytorch
Das obige ist der detaillierte Inhalt vonAusführliche Erklärung, wie man mit PyTorch schnell ein neuronales Netzwerk aufbaut und speichert und extrahiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 iFlytek: Die Fähigkeiten des Ascend 910B von Huawei sind grundsätzlich mit denen des A100 von Nvidia vergleichbar, und sie arbeiten zusammen, um eine neue Basis für die allgemeine künstliche Intelligenz meines Landes zu schaffen
Oct 22, 2023 pm 06:13 PM
iFlytek: Die Fähigkeiten des Ascend 910B von Huawei sind grundsätzlich mit denen des A100 von Nvidia vergleichbar, und sie arbeiten zusammen, um eine neue Basis für die allgemeine künstliche Intelligenz meines Landes zu schaffen
Oct 22, 2023 pm 06:13 PM
Diese Website berichtete am 22. Oktober, dass iFlytek im dritten Quartal dieses Jahres einen Nettogewinn von 25,79 Millionen Yuan erzielte, was einem Rückgang von 81,86 % gegenüber dem Vorjahr entspricht; der Nettogewinn in den ersten drei Quartalen betrug 99,36 Millionen Yuan Rückgang um 76,36 % gegenüber dem Vorjahr. Jiang Tao, Vizepräsident von iFlytek, gab bei der Leistungsbesprechung im dritten Quartal bekannt, dass iFlytek Anfang 2023 ein spezielles Forschungsprojekt mit Huawei Shengteng gestartet und gemeinsam mit Huawei eine leistungsstarke Betreiberbibliothek entwickelt hat, um gemeinsam eine neue Basis für Chinas allgemeine künstliche Intelligenz zu schaffen Intelligenz, die den Einsatz inländischer Großmodelle ermöglicht. Die Architektur basiert auf unabhängig innovativer Soft- und Hardware. Er wies darauf hin, dass die aktuellen Fähigkeiten des Huawei Ascend 910B grundsätzlich mit dem A100 von Nvidia vergleichbar seien. Auf dem bevorstehenden iFlytek 1024 Global Developer Festival werden iFlytek und Huawei weitere gemeinsame Ankündigungen zur Rechenleistungsbasis für künstliche Intelligenz machen. Er erwähnte auch,
 Die perfekte Kombination aus PyCharm und PyTorch: detaillierte Installations- und Konfigurationsschritte
Feb 21, 2024 pm 12:00 PM
Die perfekte Kombination aus PyCharm und PyTorch: detaillierte Installations- und Konfigurationsschritte
Feb 21, 2024 pm 12:00 PM
PyCharm ist eine leistungsstarke integrierte Entwicklungsumgebung (IDE) und PyTorch ist ein beliebtes Open-Source-Framework im Bereich Deep Learning. Im Bereich maschinelles Lernen und Deep Learning kann die Verwendung von PyCharm und PyTorch für die Entwicklung die Entwicklungseffizienz und Codequalität erheblich verbessern. In diesem Artikel wird detailliert beschrieben, wie PyTorch in PyCharm installiert und konfiguriert wird, und es werden spezifische Codebeispiele angehängt, um den Lesern zu helfen, die leistungsstarken Funktionen dieser beiden besser zu nutzen. Schritt 1: Installieren Sie PyCharm und Python
 so schnell! Erkennen Sie Videosprache in nur wenigen Minuten mit weniger als 10 Codezeilen in Text
Feb 27, 2024 pm 01:55 PM
so schnell! Erkennen Sie Videosprache in nur wenigen Minuten mit weniger als 10 Codezeilen in Text
Feb 27, 2024 pm 01:55 PM
Hallo zusammen, ich bin Kite. Die Notwendigkeit, Audio- und Videodateien in Textinhalte umzuwandeln, war vor zwei Jahren schwierig, aber jetzt kann dies problemlos in nur wenigen Minuten gelöst werden. Es heißt, dass einige Unternehmen, um Trainingsdaten zu erhalten, Videos auf Kurzvideoplattformen wie Douyin und Kuaishou vollständig gecrawlt haben, dann den Ton aus den Videos extrahiert und sie in Textform umgewandelt haben, um sie als Trainingskorpus für Big-Data-Modelle zu verwenden . Wenn Sie eine Video- oder Audiodatei in Text konvertieren müssen, können Sie diese heute verfügbare Open-Source-Lösung ausprobieren. Sie können beispielsweise nach bestimmten Zeitpunkten suchen, zu denen Dialoge in Film- und Fernsehsendungen erscheinen. Kommen wir ohne weitere Umschweife zum Punkt. Whisper ist OpenAIs Open-Source-Whisper. Es ist natürlich in Python geschrieben und erfordert nur ein paar einfache Installationspakete.
 Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Bei Aufgaben zur Generierung natürlicher Sprache ist die Stichprobenmethode eine Technik, um eine Textausgabe aus einem generativen Modell zu erhalten. In diesem Artikel werden fünf gängige Methoden erläutert und mit PyTorch implementiert. 1. GreedyDecoding Bei der Greedy-Decodierung sagt das generative Modell die Wörter der Ausgabesequenz basierend auf der Eingabesequenz Zeit Schritt für Zeit voraus. In jedem Zeitschritt berechnet das Modell die bedingte Wahrscheinlichkeitsverteilung jedes Wortes und wählt dann das Wort mit der höchsten bedingten Wahrscheinlichkeit als Ausgabe des aktuellen Zeitschritts aus. Dieses Wort wird zur Eingabe für den nächsten Zeitschritt und der Generierungsprozess wird fortgesetzt, bis eine Abschlussbedingung erfüllt ist, beispielsweise eine Sequenz mit einer bestimmten Länge oder eine spezielle Endmarkierung. Das Merkmal von GreedyDecoding besteht darin, dass die aktuelle bedingte Wahrscheinlichkeit jedes Mal die beste ist
 YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
Heutige Deep-Learning-Methoden konzentrieren sich darauf, die am besten geeignete Zielfunktion zu entwerfen, damit die Vorhersageergebnisse des Modells der tatsächlichen Situation am nächsten kommen. Gleichzeitig muss eine geeignete Architektur entworfen werden, um ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht. Dieser Artikel befasst sich mit wichtigen Themen bei der Datenübertragung über tiefe Netzwerke, nämlich Informationsengpässen und umkehrbaren Funktionen. Darauf aufbauend wird das Konzept der programmierbaren Gradienteninformation (PGI) vorgeschlagen, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zur Erreichung mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus wird ein neues, leichtgewichtiges Netzwerk-Framework entworfen
 „Der Eigentümer von Bilibili UP hat erfolgreich das weltweit erste Redstone-basierte neuronale Netzwerk geschaffen, das in den sozialen Medien für Aufsehen sorgte und von Yann LeCun gelobt wurde.'
May 07, 2023 pm 10:58 PM
„Der Eigentümer von Bilibili UP hat erfolgreich das weltweit erste Redstone-basierte neuronale Netzwerk geschaffen, das in den sozialen Medien für Aufsehen sorgte und von Yann LeCun gelobt wurde.'
May 07, 2023 pm 10:58 PM
In Minecraft ist Redstone ein sehr wichtiger Gegenstand. Es ist ein einzigartiges Material im Spiel. Schalter, Redstone-Fackeln und Redstone-Blöcke können Drähten oder Objekten stromähnliche Energie verleihen. Mithilfe von Redstone-Schaltkreisen können Sie Strukturen aufbauen, mit denen Sie andere Maschinen steuern oder aktivieren können. Sie können selbst so gestaltet sein, dass sie auf die manuelle Aktivierung durch Spieler reagieren, oder sie können wiederholt Signale ausgeben oder auf Änderungen reagieren, die von Nicht-Spielern verursacht werden, beispielsweise auf Bewegungen von Kreaturen und Gegenstände. Fallen, Pflanzenwachstum, Tag und Nacht und mehr. Daher kann Redstone in meiner Welt extrem viele Arten von Maschinen steuern, von einfachen Maschinen wie automatischen Türen, Lichtschaltern und Blitzstromversorgungen bis hin zu riesigen Aufzügen, automatischen Farmen, kleinen Spielplattformen und sogar in Spielcomputern gebauten Maschinen . Kürzlich, B-Station UP main @
 Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
Apr 12, 2023 pm 12:07 PM
Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
Apr 12, 2023 pm 12:07 PM
Die aktuellen Mainstream-KI-Chips sind hauptsächlich in drei Kategorien unterteilt: GPU, FPGA und ASIC. Sowohl GPU als auch FPGA sind im Frühstadium relativ ausgereifte Chiparchitekturen und Allzweckchips. ASIC ist ein Chip, der für bestimmte KI-Szenarien angepasst ist. Die Industrie hat bestätigt, dass CPUs nicht für KI-Computing geeignet sind, sie aber auch für KI-Anwendungen unerlässlich sind. Vergleich der GPU-Lösungsarchitektur zwischen GPU und CPU Die CPU folgt der von Neumann-Architektur, deren Kern die Speicherung von Programmen/Daten und die serielle sequentielle Ausführung ist. Daher benötigt die CPU-Architektur viel Platz zum Platzieren der Speichereinheit (Cache) und der Steuereinheit (Steuerung). Im Gegensatz dazu nimmt die Recheneinheit (ALU) nur einen kleinen Teil ein, sodass die CPU eine große Leistung erbringt Paralleles Rechnen.
 Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Als leistungsstarkes Deep-Learning-Framework wird PyTorch häufig in verschiedenen maschinellen Lernprojekten eingesetzt. Als leistungsstarke integrierte Python-Entwicklungsumgebung kann PyCharm auch bei der Umsetzung von Deep-Learning-Aufgaben eine gute Unterstützung bieten. In diesem Artikel wird die Installation von PyTorch in PyCharm ausführlich vorgestellt und spezifische Codebeispiele bereitgestellt, um den Lesern den schnellen Einstieg in die Verwendung von PyTorch für Deep-Learning-Aufgaben zu erleichtern. Schritt 1: Installieren Sie PyCharm. Zuerst müssen wir sicherstellen, dass wir es haben
