


1. Crawler-Prozess
Unser oberstes Ziel ist es, die täglichen Verkäufe von Lima Financial Management zu crawlen und zu wissen, welche Produkte verkauft werden und welche Benutzer jedes Produkt zu welchem Zeitpunkt gekauft haben. Lassen Sie uns zunächst die Hauptschritte des Crawlens vorstellen:
Der erste Schritt besteht natürlich darin, die Seitenstruktur und die zu crawlenden Elemente zu analysieren. Seite, wie ist die Struktur der Seite, ist eine Anmeldung erforderlich? Gibt es eine Ajax-Schnittstelle, welche Art von Daten werden zurückgegeben usw.
Nachdem Sie klar analysiert haben, welche Seiten und Ajax gecrawlt werden sollen, ist es an der Zeit, die Daten zu crawlen. Die heutigen Webseitendaten sind grob in Synchronisationsseiten und Ajax-Schnittstellen unterteilt. Für die synchrone Erfassung von Seitendaten müssen wir zunächst die Struktur der Webseite analysieren, um die erforderlichen Daten durch den Abgleich mit regulären Ausdrücken zu erhalten. Anschließend können Sie den erhaltenen Seiteninhalt in ein JQuery-Objekt umwandeln Sie können die leistungsstarke Dom-API von jquery verwenden, um knotenbezogene Daten abzurufen. Wenn Sie sich den Quellcode ansehen, besteht das Wesentliche dieser APIs im regelmäßigen Abgleich. Ajax-Schnittstellendaten liegen im Allgemeinen im JSON-Format vor und sind relativ einfach zu verarbeiten.
Nach den erfassten Daten erfolgt eine einfache Filterung und die erforderlichen Daten werden zunächst für die anschließende Analyse und Verarbeitung gespeichert. Natürlich können wir Datenbanken wie MySQL und Mongodb zum Speichern von Daten verwenden. Der Einfachheit halber verwenden wir hier direkt die Dateispeicherung.
Da wir die Daten letztendlich anzeigen möchten, müssen wir die Originaldaten nach bestimmten Dimensionen verarbeiten und analysieren und sie dann an den Kunden zurückgeben. Dieser Vorgang kann während der Speicherung oder während der Anzeige verarbeitet werden, das Frontend sendet eine Anfrage und der Hintergrund ruft die gespeicherten Daten ab und verarbeitet sie erneut. Dies hängt davon ab, wie wir die Daten anzeigen.
Nach so viel Arbeit gibt es überhaupt keine Anzeigeausgabe, wie kann man damit zufrieden sein? Dies ist eine Rückkehr zu unserem alten Geschäft und jeder sollte mit der Front-End-Anzeigeseite vertraut sein. Die Anzeige der Daten ist intuitiver und erleichtert uns die Analyse von Statistiken.
2. Cheerio
3. Async
4. arr-del
5. arr-sort
3. Analyse der Seitenstruktur
https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=0
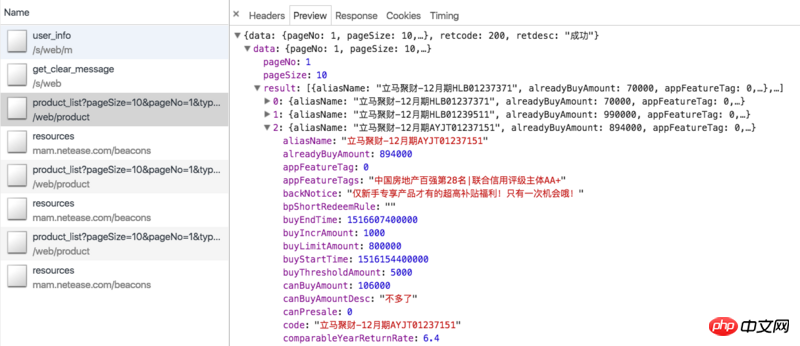 Dazu gehören alle Produkte, die derzeit online zum Verkauf angeboten werden. Bei periodischen Produkten enthalten die Ajax-Daten nur Informationen, die sich auf das Produkt selbst beziehen, wie z. B. Produkt-ID, eingenommener Betrag, aktuelle Verkäufe, jährliche Rendite, Anzahl der Anlagetage usw., aber nicht Informationen darüber, welche Benutzer das Produkt gekauft haben. Daher müssen wir den Parameter id verwenden, um die Produktdetailseite zu crawlen, z. B. Jucai sofort – Dezemberausgabe HLB01239511. Die Detailseite enthält eine Spalte mit Investitionsdatensätzen, die die von uns benötigten Informationen enthält, wie in der folgenden Abbildung dargestellt:
Dazu gehören alle Produkte, die derzeit online zum Verkauf angeboten werden. Bei periodischen Produkten enthalten die Ajax-Daten nur Informationen, die sich auf das Produkt selbst beziehen, wie z. B. Produkt-ID, eingenommener Betrag, aktuelle Verkäufe, jährliche Rendite, Anzahl der Anlagetage usw., aber nicht Informationen darüber, welche Benutzer das Produkt gekauft haben. Daher müssen wir den Parameter id verwenden, um die Produktdetailseite zu crawlen, z. B. Jucai sofort – Dezemberausgabe HLB01239511. Die Detailseite enthält eine Spalte mit Investitionsdatensätzen, die die von uns benötigten Informationen enthält, wie in der folgenden Abbildung dargestellt:
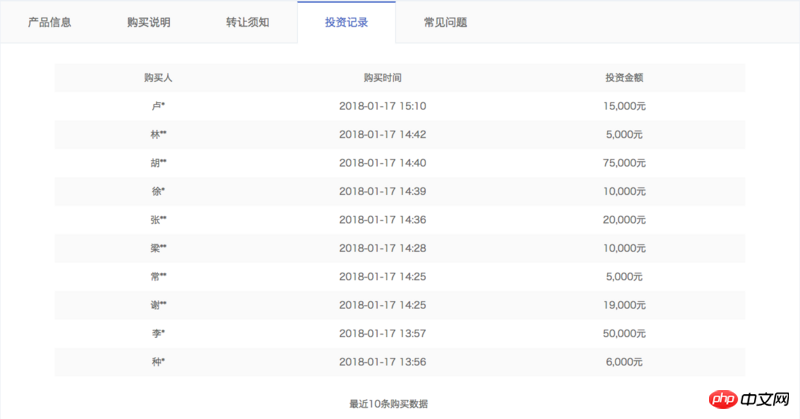 Allerdings die Detailseite erfordert, dass wir uns anmelden. Es kann nur im Status angezeigt werden, der erfordert, dass wir Cookies zum Besuch mitbringen, und Cookies haben Gültigkeitsgrenzen. Wie behalten wir unsere Cookies im angemeldeten Zustand? Bitte sehen Sie unten.
Allerdings die Detailseite erfordert, dass wir uns anmelden. Es kann nur im Status angezeigt werden, der erfordert, dass wir Cookies zum Besuch mitbringen, und Cookies haben Gültigkeitsgrenzen. Wie behalten wir unsere Cookies im angemeldeten Zustand? Bitte sehen Sie unten.
Tatsächlich verfügt auch Lima Treasury über eine ähnliche Ajax-Schnittstelle: https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1, aber die darin enthaltenen relevanten Daten sind fest codiert und bedeutungslos. Darüber hinaus gibt es auf der Detailseite des Tresors keine Informationen zum Anlagedatensatz. Dazu müssen wir die Ajax-Schnittstelle der eingangs erwähnten Homepage crawlen: https://www.lmlc.com/s/web/home/user_buying. Später stellte ich jedoch fest, dass diese Schnittstelle alle drei Minuten aktualisiert wird, was bedeutet, dass der Hintergrund alle drei Minuten Daten vom Server anfordert. Es liegen jeweils 10 Datenelemente vor. Wenn also innerhalb von drei Minuten mehr als 10 Datensätze zu gekauften Produkten erfasst werden, werden die Daten weggelassen. Daran führt kein Weg vorbei, daher werden die Statistiken des Finanzministeriums von Lima niedriger ausfallen als die tatsächlichen.
Da für die Produktdetailseite eine Anmeldung erforderlich ist, müssen wir zuerst das Anmelde-Cookie abrufen. Die getCookie-Methode lautet wie folgt:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}Die Telefon- und Passwortparameter werden über die Befehlszeile übergeben. Dabei handelt es sich um die Kontonummer und das Passwort, die für die sofortige Anmeldung bei Financial Management mit der Mobiltelefonnummer verwendet werden. Wir verwenden Superagent, um die Anforderung einer sofortigen Anmeldeschnittstelle für das Finanzmanagement zu simulieren: https://www.lmlc.com/user/s/web/logon. Im Callback übergeben wir die Set-Cookie-Informationen des Headers und senden ein setCookiee-Ereignis. Da wir ein Listening-Ereignis eingerichtet haben: emitter.on("setCookie", requestData), führen wir die requestData-Methode aus, sobald wir das Cookie erhalten haben.
Der Code der requestData-Methode lautet wie folgt:
function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i<len; i++){
if(+new Date() < addData.result[i].buyStartTime){
if(preIds.indexOf(addData.result[i].id) == -1){
preIds.push(addData.result[i].id);
setPreId(addData.result[i].buyStartTime, addData.result[i].id);
}
}else{
pageUrls.push('https://www.lmlc.com/web/product/product_detail.html?id=' + addData.result[i].id);
}
}
function setPreId(time, id){
cache[id] = setInterval(function(){
if(time - (+new Date()) < 1000){
// 预售产品开始抢购,直接修改爬取频次为1s,防止丢失数据
clearInterval(cache[id]);
clearInterval(timer);
delay = 1000;
timer = setInterval(function(){
requestData();
}, delay);
// 同时删除id记录
let index = preIds.indexOf(id);
sort.delArrByIndex(preIds, [index]);
}
}, 1000)
}
// 处理售卖金额信息
let oldData = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
for(let i=0, len=formatedAddData.length; i<len; i++){
let isNewProduct = true;
for(let j=0, len2=oldData.length; j<len2; j++){
if(formatedAddData[i].productId === oldData[j].productId){
isNewProduct = false;
}
}
if(isNewProduct){
oldData.push(formatedAddData[i]);
}
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`理财列表ajax接口爬取完毕,时间:${time}`).warn);
if(!pageUrls.length){
delay = 32*1000;
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
return
}
getDetailData();
});
}Der Code ist sehr lang und die getDetailData-Funktion Der Code wird später analysiert.
Bei der angeforderten Ajax-Schnittstelle handelt es sich um eine Paging-Schnittstelle, da die Gesamtzahl der zum Verkauf stehenden Produkte im Allgemeinen 10 nicht überschreitet. Hier setzen wir den Parameter pageSize auf 100, sodass alle Produkte gleichzeitig bezogen werden können.
clearProd ist ein globales Reset-Signal. Jeden Tag um 0 Uhr werden die Produktdaten (normales Produkt) und die Benutzerdaten (Homepage-Benutzer) gelöscht.
Da Produkte manchmal selten in Eilverkäufen verkauft werden, z. B. jeden Tag um 10 Uhr, werden die Daten jeden Tag um 10 Uhr schnell aktualisiert. Wir müssen die Häufigkeit des Crawlens erhöhen, um dies zu verhindern Datenverlust. Daher müssen wir für Vorverkaufsprodukte die Crawling-Frequenz auf 1 Mal/Sekunde einstellen, wenn buyStartTime größer als die aktuelle Zeit ist.
Wenn keine Produkte zum Verkauf stehen, d. h. pageUrls leer ist, stellen wir die Crawling-Frequenz auf maximal 32 Sekunden ein.
Dieser Teil des Codes der requestData-Funktion zeichnet hauptsächlich auf, ob neue Produkte vorhanden sind. Wenn ja, erstellen Sie ein neues Objekt, zeichnen Sie die Produktinformationen auf und übertragen Sie es in das Produktarray. Die Datenstruktur von prod.json lautet wie folgt:
[{
"productName": "立马聚财-12月期HLB01230901",
"financeTotalAmount": 1000000,
"productId": "201801151830PD84123120",
"yearReturnRate": 6.4,
"investementDays": 364,
"interestStartTime": "2018年01月23日",
"interestEndTime": "2019年01月22日",
"getDataTime": 1516118401299,
"alreadyBuyAmount": 875000,
"records": [
{
"username": "刘**",
"buyTime": 1516117093472,
"buyAmount": 30000,
"uniqueId": "刘**151611709347230,000元"
},
{
"username": "刘**",
"buyTime": 1516116780799,
"buyAmount": 50000,
"uniqueId": "刘**151611678079950,000元"
}]
}]ist ein Array von Objekten, jedes Objekt stellt ein neues Produkt dar und das Records-Attribut zeichnet Verkaufsinformationen auf.
Werfen wir einen Blick auf den Code von getDetailData:
function getDetailData(){
// 请求用户信息接口,来判断登录是否还有效,在产品详情页判断麻烦还要造成五次登录请求
superagent
.post('https://www.lmlc.com/s/web/m/user_info')
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let retcode = JSON.parse(pres.text).retcode;
if(retcode === 410){
handleErr('登陆cookie已失效,尝试重新登陆...');
getCookie();
return;
}
var reptileLink = function(url,callback){
// 如果爬取页面有限制爬取次数,这里可设置延迟
console.log( '正在爬取产品详情页面:' + url);
superagent
.get(url)
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var $ = cheerio.load(pres.text);
var records = [];
var $table = $('.buy-records table');
if(!$table.length){
$table = $('.tabcontent table');
}
var $tr = $table.find('tr').slice(1);
$tr.each(function(){
records.push({
username: $('td', $(this)).eq(0).text(),
buyTime: parseInt($('td', $(this)).eq(1).attr('data-time').replace(/,/g, '')),
buyAmount: parseFloat($('td', $(this)).eq(2).text().replace(/,/g, '')),
uniqueId: $('td', $(this)).eq(0).text() + $('td', $(this)).eq(1).attr('data-time').replace(/,/g, '') + $('td', $(this)).eq(2).text()
})
});
callback(null, {
productId: url.split('?id=')[1],
records: records
});
});
};
async.mapLimit(pageUrls, 10 ,function (url, callback) {
reptileLink(url, callback);
}, function (err,result) {
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log(`所有产品详情页爬取完毕,时间:${time}`.info);
let oldRecord = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let counts = [];
for(let i=0,len=result.length; i<len; i++){
for(let j=0,len2=oldRecord.length; j<len2; j++){
if(result[i].productId === oldRecord[j].productId){
let count = 0;
let newRecords = [];
for(let k=0,len3=result[i].records.length; k<len3; k++){
let isNewRec = true;
for(let m=0,len4=oldRecord[j].records.length; m<len4; m++){
if(result[i].records[k].uniqueId === oldRecord[j].records[m].uniqueId){
isNewRec = false;
}
}
if(isNewRec){
count++;
newRecords.push(result[i].records[k]);
}
}
oldRecord[j].records = oldRecord[j].records.concat(newRecords);
counts.push(count);
}
}
}
let oldDelay = delay;
delay = getNewDelay(delay, counts);
function getNewDelay(delay, counts){
let nowDate = (new Date()).toLocaleDateString();
let time1 = Date.parse(nowDate + ' 00:00:00');
let time2 = +new Date();
// 根据这次更新情况,来动态设置爬取频次
let maxNum = Math.max(...counts);
if(maxNum >=0 && maxNum <= 2){
delay = delay + 1000;
}
if(maxNum >=8 && maxNum <= 10){
delay = delay/2;
}
// 每天0点,prod数据清空,排除这个情况
if(maxNum == 10 && (time2 - time1 >= 60*1000)){
handleErr('部分数据可能丢失!');
}
if(delay <= 1000){
delay = 1000;
}
if(delay >= 32*1000){
delay = 32*1000;
}
return delay
}
if(oldDelay != delay){
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldRecord));
})
});
}Wir fordern zunächst die Benutzerinformationsschnittstelle an, um festzustellen, ob die Anmeldung erfolgt ist immer noch verfügbar, da die Beurteilung auf der Produktdetailseite schwierig ist und es zu fünf Anmeldeanfragen kommt. Das Anfordern mit Cookies ist ganz einfach. Setzen Sie einfach das Cookie, das wir zuvor nach dem Beitrag erhalten haben: .set('Cookie', cookie). Wenn der vom Hintergrund zurückgegebene Retcode 410 ist, bedeutet dies, dass das Anmeldecookie abgelaufen ist und getCookie() erneut ausgeführt werden muss. Dadurch wird sichergestellt, dass der Crawler immer angemeldet ist.
Die MapLimit-Methode von Async stellt gleichzeitige Anforderungen für Seiten-Urls mit einer Parallelität von 10. Die reptileLink-Methode wird für jede pageUrl ausgeführt. Warten Sie, bis die gesamte asynchrone Ausführung abgeschlossen ist, bevor Sie die Rückruffunktion ausführen. Der Ergebnisparameter der Callback-Funktion ist ein Array, das aus den von jeder ReptileLink-Funktion zurückgegebenen Daten besteht.
Die ReptileLink-Funktion dient zum Abrufen der Investitionsdatensatzlisteninformationen der Produktdetailseite. UniqueId ist eine Zeichenfolge, die aus den bekannten Parametern Benutzername, buyTime und buyAmount besteht und zur Eliminierung von Duplikaten verwendet wird.
Der asynchrone Rückruf schreibt hauptsächlich die neuesten Informationen zum Investitionsdatensatz in das entsprechende Produktobjekt und generiert gleichzeitig ein Zählarray. Das Counts-Array ist ein Array, das aus der Anzahl neuer Verkaufsdatensätze für jedes dieses Mal gecrawlte Produkt besteht und zusammen mit der Verzögerung an die Funktion getNewDelay übergeben wird. getNewDelay passt die Crawling-Frequenz dynamisch an und Zählungen sind die einzige Grundlage für die Anpassung der Verzögerung. Wenn die Verzögerung zu groß ist, kann es zu Datenverlusten kommen. Wenn sie zu klein ist, erhöht sich die Belastung des Servers und der Administrator blockiert möglicherweise die IP-Adresse. Hier ist der maximale Verzögerungswert auf 32 und der minimale Wert auf 1 eingestellt.
Beginnen wir zunächst mit dem Code:
function requestData1() {
superagent.get(ajaxUrl1)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let newData = JSON.parse(pres.text).data;
let formatNewData = formatData1(newData);
// 在这里清空数据,避免一个文件被同时写入
if(clearUser){
fs.writeFileSync('data/user.json', '');
clearUser = false;
}
let data = fs.readFileSync('data/user.json', 'utf-8');
if(!data){
fs.writeFileSync('data/user.json', JSON.stringify(formatNewData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}else{
let oldData = JSON.parse(data);
let addData = [];
// 排重算法,如果uniqueId不一样那肯定是新生成的,否则看时间差如果是0(三分钟内请求多次)或者三分钟则是旧数据
for(let i=0, len=formatNewData.length; i<len; i++){
let matchArr = [];
for(let len2=oldData.length, j=Math.max(0,len2 - 20); j<len2; j++){
if(formatNewData[i].uniqueId === oldData[j].uniqueId){
matchArr.push(j);
}
}
if(matchArr.length === 0){
addData.push(formatNewData[i]);
}else{
let isNewBuy = true;
for(let k=0, len3=matchArr.length; k<len3; k++){
let delta = formatNewData[i].time - oldData[matchArr[k]].time;
if(delta == 0 || (Math.abs(delta - 3*60*1000) < 1000)){
isNewBuy = false;
// 更新时间,这样下一次判断还是三分钟
oldData[matchArr[k]].time = formatNewData[i].time;
}
}
if(isNewBuy){
addData.push(formatNewData[i]);
}
}
}
fs.writeFileSync('data/user.json', JSON.stringify(oldData.concat(addData)));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}
});
}Das Crawlen von user.js ähnelt dem von prod.js Ich möchte hauptsächlich darüber sprechen, wie man Gewicht verliert. Das Datenformat user.json lautet wie folgt:
[
{
"payAmount": 5067.31,
"productId": "jsfund",
"productName": "立马金库",
"productType": 6,
"time": 1548489,
"username": "郑**",
"buyTime": 1516118397758,
"uniqueId": "5067.31jsfund郑**"
}, {
"payAmount": 30000,
"productId": "201801151830PD84123120",
"productName": "立马聚财-12月期HLB01230901",
"productType": 0,
"time": 1306573,
"username": "刘**",
"buyTime": 1516117199684,
"uniqueId": "30000201801151830PD84123120刘**"
}]和产品详情页类似,我们也生成一个uniqueId参数用来排除,它是payAmount、productId、username参数的拼成的字符串。如果uniqueId不一样,那肯定是一条新的记录。如果相同那一定是一条新记录吗?答案是否定的。因为这个接口数据是三分钟更新一次,而且给出的时间是相对时间,即数据更新时的时间减去购买的时间。所以每次更新后,即使是同一条记录,时间也会不一样。那如何排重呢?其实很简单,如果uniqueId一样,我们就判断这个buyTime,如果buyTime的差正好接近180s,那么几乎可以肯定是旧数据。如果同一个人正好在三分钟后购买同一个产品相同的金额那我也没辙了,哈哈。
每天零点我们需要整理user.json和prod.json数据,生成最终的数据。代码:
let globalTimer = setInterval(function(){
let nowTime = +new Date();
let nowStr = (new Date()).format("hh:mm:ss");
let max = nowTime;
let min = nowTime - 24*60*60*1000;
// 每天00:00分的时候写入当天的数据
if(nowStr === "00:00:00"){
// 先保存数据
let prod = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let user = JSON.parse(fs.readFileSync('data/user.json', 'utf-8'));
let lmlc = JSON.parse(JSON.stringify(prod));
// 清空缓存数据
clearProd = true;
clearUser = true;
// 不足一天的不统计
// if(nowTime - initialTime < 24*60*60*1000) return
// 筛选prod.records数据
for(let i=0, len=prod.length; i<len; i++){
let delArr1 = [];
for(let j=0, len2=prod[i].records.length; j<len2; j++){
if(prod[i].records[j].buyTime < min || prod[i].records[j].buyTime >= max){
delArr1.push(j);
}
}
sort.delArrByIndex(lmlc[i].records, delArr1);
}
// 删掉prod.records为空的数据
let delArr2 = [];
for(let i=0, len=lmlc.length; i<len; i++){
if(!lmlc[i].records.length){
delArr2.push(i);
}
}
sort.delArrByIndex(lmlc, delArr2);
// 初始化lmlc里的立马金库数据
lmlc.unshift({
"productName": "立马金库",
"financeTotalAmount": 100000000,
"productId": "jsfund",
"yearReturnRate": 4.0,
"investementDays": 1,
"interestStartTime": (new Date(min)).format("yyyy年MM月dd日"),
"interestEndTime": (new Date(max)).format("yyyy年MM月dd日"),
"getDataTime": min,
"alreadyBuyAmount": 0,
"records": []
});
// 筛选user数据
for(let i=0, len=user.length; i<len; i++){
if(user[i].productId === "jsfund" && user[i].buyTime >= min && user[i].buyTime < max){
lmlc[0].records.push({
"username": user[i].username,
"buyTime": user[i].buyTime,
"buyAmount": user[i].payAmount,
});
}
}
// 删除无用属性,按照时间排序
lmlc[0].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let i=1, len=lmlc.length; i<len; i++){
lmlc[i].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let j=0, len2=lmlc[i].records.length; j<len2; j++){
delete lmlc[i].records[j].uniqueId
}
}
// 爬取金库收益,写入前一天的数据,清空user.json和prod.json
let dateStr = (new Date(nowTime - 10*60*1000)).format("yyyyMMdd");
superagent
.get('https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var data = JSON.parse(pres.text).data;
var rate = data.result[0].yearReturnRate||4.0;
lmlc[0].yearReturnRate = rate;
fs.writeFileSync(`data/${dateStr}.json`, JSON.stringify(lmlc));
})
}
}, 1000);globalTimer是个全局定时器,每隔1s执行一次,当时间为00:00:00时,clearProd和clearUser全局参数为true,这样在下次爬取过程时会清空user.json和prod.json文件。没有同步清空是因为防止多处同时修改同一文件报错。取出user.json里的所有金库记录,获取当天金库相关信息,生成一条立马金库的prod信息并unshift进prod.json里。删除一些无用属性,排序数组最终生成带有当天时间戳的json文件,如:20180101.json。
前端总共就两个页面,首页和详情页,首页主要展示实时销售额、某一时间段内的销售情况、具体某天的销售情况。详情页展示某天的具体某一产品销售情况。页面有两个入口,而且比较简单,这里我们采用gulp来打包压缩构建前端工程。后台用express搭建的,匹配到路由,从data文件夹里取到数据再分析处理再返回给前端。
Echarts
Echarts是一个绘图利器,百度公司不可多得的良心之作。能方便的绘制各种图形,官网已经更新到4.0了,功能更加强大。我们这里主要用到的是直方图。
DataTables
Datatables是一款jquery表格插件。它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能。功能非常强大,有丰富的API,大家可以去官网学习。
Datepicker
Datepicker是一款基于jquery的日期选择器,需要的功能基本都有,主要样式比较好看,比jqueryUI官网的Datepicker好看太多。
gulp配置比较简单,代码如下:
var gulp = require('gulp');
var uglify = require("gulp-uglify");
var less = require("gulp-less");
var minifyCss = require("gulp-minify-css");
var livereload = require('gulp-livereload');
var connect = require('gulp-connect');
var minimist = require('minimist');
var babel = require('gulp-babel');
var knownOptions = {
string: 'env',
default: { env: process.env.NODE_ENV || 'production' }
};
var options = minimist(process.argv.slice(2), knownOptions);
// js文件压缩
gulp.task('minify-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(uglify())
.pipe(gulp.dest('dist/'));
});
// js移动文件
gulp.task('move-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less编译
gulp.task('compile-less', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less文件编译压缩
gulp.task('compile-minify-css', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(minifyCss())
.pipe(gulp.dest('dist/'));
});
// html页面自动刷新
gulp.task('html', function () {
gulp.src('views/*.html')
.pipe(connect.reload());
});
// 页面自动刷新启动
gulp.task('connect', function() {
connect.server({
livereload: true
});
});
// 监测文件的改动
gulp.task('watch', function() {
gulp.watch('src/css/*.less', ['compile-less']);
gulp.watch('src/js/*.js', ['move-js']);
gulp.watch('views/*.html', ['html']);
});
// 激活浏览器livereload友好提示
gulp.task('tip', function() {
console.log('\n<----- 请用chrome浏览器打开 http://localhost:5000 页面,并激活livereload插件 ----->\n');
});
if (options.env === 'development') {
gulp.task('default', ['move-js', 'compile-less', 'connect', 'watch', 'tip']);
}else{
gulp.task('default', ['minify-js', 'compile-minify-css']);
}开发和生产环境都是将文件打包到dist目录。不同的是:开发环境只是编译es6和less文件;生产环境会再压缩混淆。支持livereload插件,在开发环境下,文件改动会自动刷新页面。
相关推荐:
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des NodeJS-Crawlers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



