


In diesem Artikel wird hauptsächlich die Methodenanalyse von Python vorgestellt, die den JQuery-Kurs von w3shcool crawlt und lokal speichert. Hat einen sehr guten Referenzwert. Werfen wir einen Blick mit dem Redakteur unten
Ich war in letzter Zeit damit beschäftigt, nach einem Job zu suchen. In meiner Freizeit habe ich auch einige Crawler-Projekte gefunden, um meine Fähigkeiten zu üben und Code zu schreiben , aber ich muss mehr üben. Straßenarbeit ist der Weg. Wenn Sie Testgruben haben, können Sie mir diese vorstellen. Automatisierung, Funktionen und Schnittstellen können durchgeführt werden.
Zuallererst haben wir unsere Bedürfnisse klar definiert. Viele Studenten möchten einige Technologien sehen, wenn sie beispielsweise nichts zu tun haben Internet jetzt, und ich habe keine E-Books auf meinem Handy Es ist wirklich unangenehm, also machen Sie sich keine Sorgen, ich bin hier, um Ihre Bedürfnisse zu erfüllen. Zunächst einmal ist es Ihr Bedürfnis, die Syntax zu erhalten JQuery, dann sehe ich diesen Bedarf, ich habe eine Website, die reagiert, also lasst uns weitermachen und diese Website analysieren. www.w3school.com.cn/jquery/jquery_syntax.asp Dies ist die Syntax-URL, http://www.w3school.com.cn/jquery/jquery_intro.asp Dies ist die Einführungs-URL, dann haben wir eine Menge URL-Analyse durchgeführt , unsere www.w3school.com.cn/jquery ist die gleiche, also analysieren wir, wie wir diese in die Benutzeroberfläche bekommen. Wir können sehen, dass es rechts eine entsprechende Zielleiste gibt, also analysieren wir sie
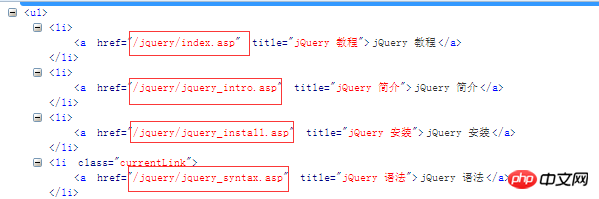
Werfen wir einen Blick auf diese Links. Wir können diese Links mit http://www.w3school.com.cn verbinden. Dann bilden Sie unsere neue URL
und fügen Sie den Code
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_texthinzu, damit wir die Funktion url_s verwenden können, um alle unsere Links abzurufen.
['/jquery/index.asp', '/jquery/jquery_intro.asp', '/jquery/jquery_install.asp', '/jquery/jquery_syntax.asp', '/jquery/jquery_selectors.asp', '/jquery/jquery_events.asp', '/jquery/jquery_hide_show.asp', '/jquery/jquery_fade.asp', '/jquery/jquery_slide.asp', '/jquery/jquery_animate.asp', '/jquery/jquery_stop.asp', '/jquery/jquery_callback.asp', '/jquery/jquery_chaining.asp', '/jquery/jquery_dom_get.asp', '/jquery/jquery_dom_set.asp', '/jquery/jquery_dom_add.asp', '/jquery/jquery_dom_remove.asp', '/jquery/jquery_css_classes.asp', '/jquery/jquery_css.asp', '/jquery/jquery_dimensions.asp', '/jquery/jquery_traversing.asp', '/jquery/jquery_traversing_ancestors.asp', '/jquery/jquery_traversing_descendants.asp', '/jquery/jquery_traversing_siblings.asp', '/jquery/jquery_traversing_filtering.asp', '/jquery/jquery_ajax_intro.asp', '/jquery/jquery_ajax_load.asp', '/jquery/jquery_ajax_get_post.asp', '/jquery/jquery_noconflict.asp', '/jquery/jquery_examples.asp', '/jquery/jquery_quiz.asp', '/jquery/jquery_reference.asp', '/jquery/jquery_ref_selectors.asp', '/jquery/jquery_ref_events.asp', '/jquery/jquery_ref_effects.asp', '/jquery/jquery_ref_manipulation.asp', '/jquery/jquery_ref_attributes.asp', '/jquery/jquery_ref_css.asp', '/jquery/jquery_ref_ajax.asp', '/jquery/jquery_ref_traversing.asp', '/jquery/jquery_ref_data.asp', '/jquery/jquery_ref_dom_element_methods.asp', '/jquery/jquery_ref_core.asp', '/jquery/jquery_ref_prop.asp'], ['jQuery 教程', '', 'jQuery 教程', 'jQuery 简介', 'jQuery 安装', 'jQuery 语法', 'jQuery 选择器', 'jQuery 事件', '', 'jQuery 效果', '', 'jQuery 隐藏/显示', 'jQuery 淡入淡出', 'jQuery 滑动', 'jQuery 动画', 'jQuery stop()', 'jQuery Callback', 'jQuery Chaining', '', 'jQuery HTML', '', 'jQuery 获取', 'jQuery 设置', 'jQuery 添加', 'jQuery 删除', 'jQuery CSS 类', 'jQuery css()', 'jQuery 尺寸', '', 'jQuery 遍历', '', 'jQuery 遍历', 'jQuery 祖先', 'jQuery 后代', 'jQuery 同胞', 'jQuery 过滤', '', 'jQuery AJAX', '', 'jQuery AJAX 简介', 'jQuery 加载', 'jQuery Get/Post', '', 'jQuery 杂项', '', 'jQuery noConflict()', '', 'jQuery 实例', '', 'jQuery 实例', 'jQuery 测验', '', 'jQuery 参考手册', '', 'jQuery 参考手册', 'jQuery 选择器', 'jQuery 事件', 'jQuery 效果', 'jQuery 文档操作', 'jQuery 属性操作', 'jQuery CSS 操作', 'jQuery Ajax', 'jQuery 遍历', 'jQuery 数据', 'jQuery DOM 元素', 'jQuery 核心', 'jQuery 属性', '', ''])
Dies ist der Name aller Links und die entsprechenden Grammatikmodule der entsprechenden Links. Dann besteht unser nächster Schritt darin, URLs mit str splicing
['http://www.w3school.com.cn//jquery/index.asp', 'http://www.w3school.com.cn//jquery/jquery_intro.asp', 'http://www.w3school.com.cn//jquery/jquery_install.asp', 'http://www.w3school.com.cn//jquery/jquery_syntax.asp', 'http://www.w3school.com.cn//jquery/jquery_selectors.asp', 'http://www.w3school.com.cn//jquery/jquery_events.asp', 'http://www.w3school.com.cn//jquery/jquery_hide_show.asp', 'http://www.w3school.com.cn//jquery/jquery_fade.asp', 'http://www.w3school.com.cn//jquery/jquery_slide.asp', 'http://www.w3school.com.cn//jquery/jquery_animate.asp', 'http://www.w3school.com.cn//jquery/jquery_stop.asp', 'http://www.w3school.com.cn//jquery/jquery_callback.asp', 'http://www.w3school.com.cn//jquery/jquery_chaining.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_get.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_set.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_add.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_remove.asp', 'http://www.w3school.com.cn//jquery/jquery_css_classes.asp', 'http://www.w3school.com.cn//jquery/jquery_css.asp', 'http://www.w3school.com.cn//jquery/jquery_dimensions.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_ancestors.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_descendants.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_siblings.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_filtering.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_intro.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_load.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_get_post.asp', 'http://www.w3school.com.cn//jquery/jquery_noconflict.asp', 'http://www.w3school.com.cn//jquery/jquery_examples.asp', 'http://www.w3school.com.cn//jquery/jquery_quiz.asp', 'http://www.w3school.com.cn//jquery/jquery_reference.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_selectors.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_events.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_effects.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_manipulation.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_attributes.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_css.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_ajax.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_traversing.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_data.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_dom_element_methods.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_core.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_prop.asp']
zu verbinden. Dann haben wir alle diese URLs, dann analysieren wir den Artikeltext.
Eine Analyse kann zeigen, dass sich alle unsere Texte in einem id=maincontent befinden. Dann analysieren wir direkt das id=maincontent-Tag in jeder Schnittstelle, rufen das Antworttextdokument ab und speichern es.
Unser gesamter Code lautet also wie folgt:
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text
def xml():
url,url_text=url_s()
url_jque=[]
for link in url:
url_jque.append('http://www.w3school.com.cn/'+link)
return url_jque
def xiazai():
urls=xml()
i=0
for url in urls:
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='maincontent')
with open(r'%s.txt'%i,'wb') as f:
for h in me:
f.write(h.text.encode('utf-8'))
print(i)
i+=1
if __name__ == '__main__':
xiazai()import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text
def xml():
url,url_text=url_s()
url_jque=[]
for link in url:
url_jque.append('http://www.w3school.com.cn/'+link)
return url_jque
def xiazai():
urls=xml()
i=0
for url in urls:
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='maincontent')
with open(r'%s.txt'%i,'wb') as f:
for h in me:
f.write(h.text.encode('utf-8'))
print(i)
i+=1
if __name__ == '__main__':
xiazai()Ergebnisse
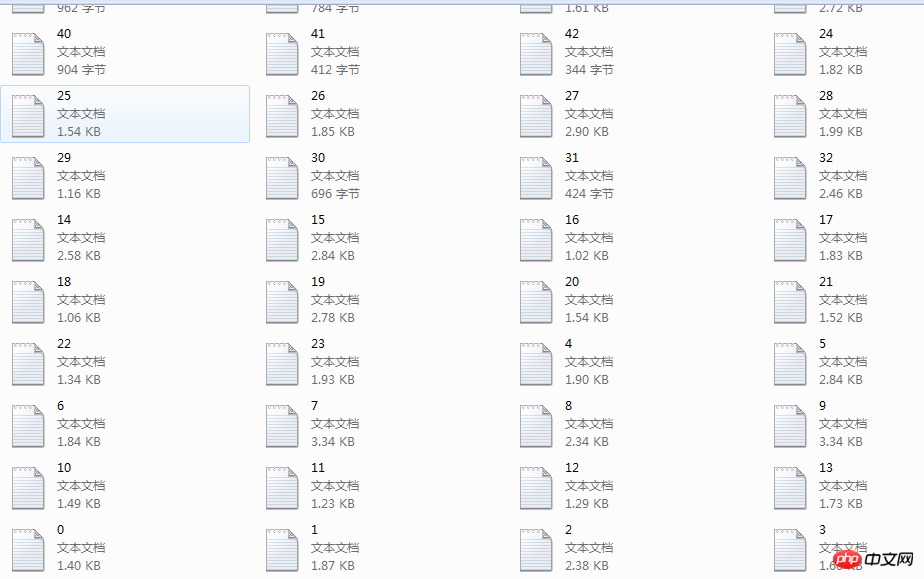
Das ist es, unsere Crawling-Arbeit. Sobald es soweit ist Fertig, es bleiben nur noch kleinere Reparaturen und kleinere Überarbeitungen, und wir sollten alle wichtigen Inhalte fertiggestellt haben.
Tatsächlich ist der Crawler von Python immer noch sehr einfach. Solange wir die Elemente der Website analysieren und die gemeinsamen Begriffe aller Elemente herausfinden können, können wir unsere Probleme sehr gut analysieren und lösen
Das obige ist der detaillierte Inhalt vonEin Kurs, der Ihnen beibringt, wie Sie mit Python w3shcool crawlen und in lokalen Codebeispielen speichern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































