


Angesichts der Beliebtheit von JavaScript, einer Skriptsprache für Webbrowser, ist es für Sie von Vorteil, ein grundlegendes Verständnis ihres ereignisgesteuerten Interaktionsmodells und seiner Unterschiede zum gängigen Anforderungs-Antwort-Modell in Ruby, Python und Java zu haben . In diesem Beitrag erkläre ich einige der Kernkonzepte des Parallelitätsmodells von JavaScript, einschließlich der Ereignisschleife und der Nachrichtenwarteschlangen, in der Hoffnung, Ihr Verständnis einer Sprache zu verbessern, die Sie möglicherweise bereits verwenden, aber möglicherweise nicht vollständig verstehen.
Für wen ist dieser Artikel geschrieben?
Dieser Artikel richtet sich an Webentwickler, die JavaScript auf der Client- oder Serverseite verwenden oder dies planen. Wenn Sie sich bereits gut mit Ereignisschleifen auskennen, werden Ihnen die meisten Teile dieses Artikels bekannt sein. Für diejenigen, die noch nicht ganz so kompetent sind, hoffe ich, Ihnen ein grundlegendes Verständnis zu vermitteln, das Ihnen beim täglichen Lesen und Schreiben von Code besser hilft.
Nicht blockierende E/A
In JavaScript sind fast alle E/A nicht blockierend. Dazu gehören HTTP-Anfragen, Datenbankoperationen sowie Lese- und Schreibvorgänge auf der Festplatte. Bei der Ausführung einer Operation zur Laufzeit muss eine Rückruffunktion bereitgestellt werden, die dann andere Aufgaben ausführt. Wenn der Vorgang abgeschlossen ist, wird die Nachricht zusammen mit der bereitgestellten Rückruffunktion in die Warteschlange eingefügt. Irgendwann in der Zukunft wird die Nachricht aus der Warteschlange entfernt und die Rückruffunktion wird ausgelöst.
Während dieses Interaktionsmodell möglicherweise Entwicklern vertraut ist, die bereits daran gewöhnt sind, mit Benutzeroberflächen zu arbeiten, wie z. B. „Mousedown“- und „Klick“-Ereignisse, die irgendwann ausgelöst werden. Dies unterscheidet sich vom synchronen Anforderungs-Antwort-Modell, das normalerweise in serverseitigen Anwendungen durchgeführt wird.
Vergleichen wir zwei kleine Codeteile, die eine HTTP-Anfrage an www.google.com stellen und die Antwort an die Konsole ausgeben. Werfen wir zunächst einen Blick auf Ruby und verwenden es mit Faraday (einer Ruby-HTTP-Client-Entwicklungsbibliothek):
response = Faraday.get 'http://www.google.com' puts response puts 'Done!'
Der Ausführungspfad ist leicht nachzuvollziehen:
1. Führen Sie die get-Methode aus und der ausführende Thread wartet, bis eine Antwort empfangen wird
2. Die Antwort wird von Google empfangen und an den Anrufer zurückgegeben. Sie wird in einer Variablen
gespeichert
3. Der Wert der Variablen (in diesem Fall unsere Antwort) wird an die Konsole
ausgegeben
4. Der Wert „Fertig!“ wird an die Konsole ausgegeben
Machen wir dasselbe in JavaScript mit Node.js und der Request-Bibliothek:
request('http://www.google.com', function(error, response, body) {
console.log(body);
});
console.log('Done!');Oberflächlich betrachtet sieht es etwas anders aus, aber das tatsächliche Verhalten ist völlig anders:
1. Führen Sie die Anforderungsfunktion aus, übergeben Sie eine anonyme Funktion als Rückruf und führen Sie den Rückruf aus, wenn die Antwort irgendwann in der Zukunft verfügbar ist.
2. „Fertig!“ wird sofort auf der Konsole ausgegeben
3. Irgendwann in der Zukunft, wenn die Antwort zurückkommt und der Rückruf ausgeführt wird, geben Sie seinen Inhalt an die Konsole aus
Ereignisschleife
Entkoppeln Sie den Aufrufer und die Antwort, sodass JavaScript andere Dinge tun kann, während es darauf wartet, dass der asynchrone Vorgang abgeschlossen ist und der Rückruf während der Laufzeit ausgelöst wird. Aber wie sind diese Rückrufe im Speicher organisiert und in welcher Reihenfolge werden sie ausgeführt? Was führt dazu, dass sie aufgerufen werden?
Die JavaScript-Laufzeit enthält eine Nachrichtenwarteschlange, die eine Liste der zu verarbeitenden Nachrichten und zugehörige Rückruffunktionen speichert. Diese Nachrichten werden als Reaktion auf externe Ereignisse, die an der Rückruffunktion beteiligt sind (z. B. Mausklicks oder Antworten auf HTTP-Anfragen), in die Warteschlange gestellt. Wenn der Benutzer beispielsweise auf eine Schaltfläche klickt und keine Rückruffunktion bereitgestellt wird, wird keine Nachricht in die Warteschlange gestellt.
In einer Schleife ruft die Warteschlange die nächste Nachricht ab (jeder Abruf wird als „Tick“ bezeichnet) und wenn ein Ereignis auftritt, wird der Rückruf der Nachricht ausgeführt.
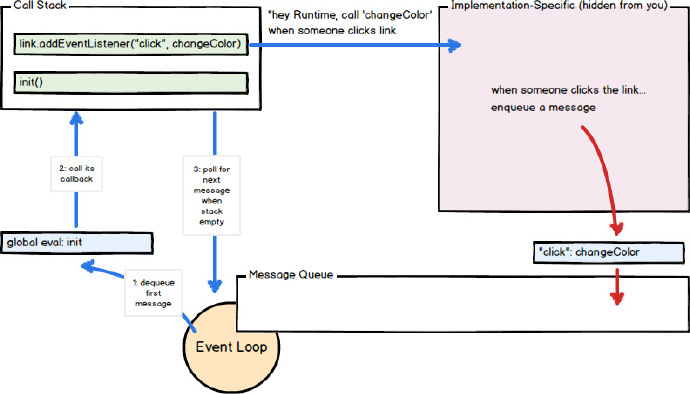
Der Aufruf der Rückruffunktion fungiert als Initialisierungsrahmen (Fragment) im Aufrufstapel. Da JavaScript Single-Threaded ist, werden zukünftige Nachrichtenextraktion und -verarbeitung gestoppt, während auf die Rückkehr aller Aufrufe im Stapel gewartet wird. Nachfolgende (synchrone) Funktionsaufrufe fügen dem Stapel neue Aufrufrahmen hinzu (z. B. ruft die Funktion init die Funktion changeColor auf).
function init() {
var link = document.getElementById("foo");
link.addEventListener("click", function changeColor() {
this.style.color = "burlywood";
});
}
init();
Wenn der Benutzer in diesem Beispiel auf das Element „foo“ klickt, wird eine Nachricht (und ihre Rückruffunktion „changeColor“) in die Warteschlange eingefügt und das Ereignis „onclick“ ausgelöst. Wenn eine Nachricht die Warteschlange verlässt, wird ihre Rückruffunktion changeColor aufgerufen. Wenn changeColor zurückkehrt (oder einen Fehler auslöst), wird die Ereignisschleife fortgesetzt. Solange die Funktion „changeColor“ existiert und als Callback für die onclick-Methode des „foo“-Elements angegeben ist, führt ein Klick auf dieses Element dazu, dass weitere Nachrichten (und der zugehörige Callback „changeColor“) in die Warteschlange eingefügt werden.
Nachricht zum Anhängen in die Warteschlange stellen
Wenn eine Funktion asynchron im Code aufgerufen wird (z. B. setTimeout), wird der bereitgestellte Rückruf schließlich als Teil einer anderen Nachrichtenwarteschlange ausgeführt, die bei einer zukünftigen Aktion in der Ereignisschleife auftritt. Zum Beispiel:
function f() {
console.log("foo");
setTimeout(g, 0);
console.log("baz");
h();
}
function g() {
console.log("bar");
}
function h() {
console.log("blix");
}
f();由于setTimeout的非阻塞特性,它的回调将在至少0毫秒后触发,而不是作为消息的一部分被处理。在这个示例中,setTimeout被调用, 传入了一个回调函数g且延时0毫秒后执行。当我们指定时间到达(当前情况是,几乎立即执行),一个单独的消息将被加入队列(g作为回调函数)。控制台打印的结果会是像这样:“foo”,“baz”,“blix”,然后是事件循环的下一个动作:“bar”。如果在同一个调用片段中,两个调用都设置为setTimeout -传递给第二个参数的值也相同-则它们的回调将按照调用顺序插入队列。
Web Workers
使用Web Workers允许您能够将一项费时的操作在一个单独的线程中执行,从而可以释放主线程去做别的事情。worker(工作线程)包括一个独立的消息队列,事件循 环,内存空间独立于实例化它的原始线程。worker和主线程之间的通信通过消息传递,看起来很像我们往常常见的传统事件代码示例。

首先,我们的worker:
// our worker, which does some CPU-intensive operation
var reportResult = function(e) {
pi = SomeLib.computePiToSpecifiedDecimals(e.data);
postMessage(pi);
};
onmessage = reportResult;然后,主要的代码块在我们的HTML中以script-标签存在:
// our main code, in a <script>-tag in our HTML page
var piWorker = new Worker("pi_calculator.js");
var logResult = function(e) {
console.log("PI: " + e.data);
};
piWorker.addEventListener("message", logResult, false);
piWorker.postMessage(100000);在这个例子中,主线程创建一个worker,同时注册logResult回调函数到其“消息”事件。在worker里,reportResult函数注册到自己的“消息”事件中。当worker线程接收到主线程的消息,worker入队一条消息同时带上reportResult回调函数。消息出队时,一条新消息发送回主线程,新消息入队主线程队列(带上logResult回调函数)。这样,开发人员可以将cpu密集型操作委托给一个单独的线程,使主线程解放出来继续处理消息和事件。
关于闭包的
JavaScript对闭包的支持,允许你这样注册回调函数,当回调函数执行时,保持了对他们被创建的环境的访问(即使回调的执行时创建了一个全新的调用栈)。理解我们的回调作为一个不同的消息的一部分被执行,而不是创建它的那个会很有意思。看看下面的例子:
function changeHeaderDeferred() {
var header = document.getElementById("header");
setTimeout(function changeHeader() {
header.style.color = "red";
return false;
}, 100);
return false;
}
changeHeaderDeferred();
在这个例子中,changeHeaderDeferred函数被执行时包含了变量header。函数 setTimeout被调用,导致消息(带上changeHeader回调)被添加到消息队列,在大约100毫秒后执行。然后 changeHeaderDeferred函数返回false,结束第一个消息的处理,但header变量仍然可以通过闭包被引用,而不是被垃圾回收。当 第二个消息被处理(changeHeader函数),它保持了对在外部函数作用域中声明的header变量的访问。一旦第二个消息 (changeHeader函数)执行结束,header变量可以被垃圾回收。
提醒
JavaScript 事件驱动的交互模型不同于许多程序员习惯的请求-响应模型,但如你所见,它并不复杂。使用简单的消息队列和事件循环,JavaScript使得开发人员在构建他们的系统时使用大量asynchronously-fired(异步-触发)回调函数,让运行时环境能在等待外部事件触发的同时处理并发操作。然而,这不过是并发的一种方法。
以上就是本文的全部内容,希望对大家的学习有所帮助。
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



