


Ich habe zuvor einen kleinen Crawler geschrieben, der jetzt sehr unvollkommen zu sein scheint. Wenn Sie beispielsweise auf eine Frage auf Zhihu klicken, werden nicht alle Antworten geladen Klicken Sie am Ende der Antwort auf „Mehr laden“ und die Antwort wird erneut geladen. Wenn Sie daher direkt einen Anfragelink zu einer Frage senden, ist die erhaltene Seite unvollständig. Wenn wir Bilder durch Senden von Links herunterladen, laden wir sie auch einzeln herunter. Wenn zu viele Bilder vorhanden sind, werden sie auch nach dem Schlafengehen heruntergeladen. Außerdem lädt der Crawler, den wir mit nodejs geschrieben haben, die Bilder nicht einzeln herunter Erstens ist es eine solche Verschwendung, dass die leistungsstärkste Asynchronitäts- und Parallelitätsfunktion von NodeJS nicht verwendet wird.
Gedanken
Der Crawler dieses Mals ist eine aktualisierte Version des letzten. Obwohl der letzte Crawler einfach war, eignet er sich sehr gut zum Erlernen für Anfänger. Der Crawler-Code ist dieses Mal auf meinem Github => NodeSpider zu finden.
Die Idee des gesamten Crawlers ist folgende: Zu Beginn haben wir einen Teil der Seitendaten über den Link der Anforderungsfrage gecrawlt und dann die Ajax-Anfrage im Code simuliert, um die restlichen Seitendaten abzufangen. Natürlich kann es hier auch asynchron erfolgen, um Parallelität zu erreichen. Für die asynchrone Prozesssteuerung im kleinen Maßstab können Sie dieses Modul => Eventproxy verwenden, aber ich habe hier keine Verwendung dafür! Wir fangen die Links aller Bilder ab, indem wir die erhaltene Seite analysieren, und implementieren dann den Batch-Download dieser Bilder durch asynchrone Parallelität.
Es ist sehr einfach, die Anfangsdaten der Seite zu erfassen, daher werde ich hier nicht viel erklären
/*获取首屏所有图片链接*/
var getInitUrlList=function(){
request.get("https://www.zhihu.com/question/")
.end(function(err,res){
if(err){
console.log(err);
}else{
var $=cheerio.load(res.text);
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList();
}
});
} Simulieren Sie eine Ajax-Anfrage, um die vollständige Seite zu erhalten
Der nächste Schritt besteht darin, die Ajax-Anfrage zu simulieren, die beim Klicken zum Laden ausgegeben wird. Gehen Sie zu Zhihu und werfen Sie einen Blick darauf!
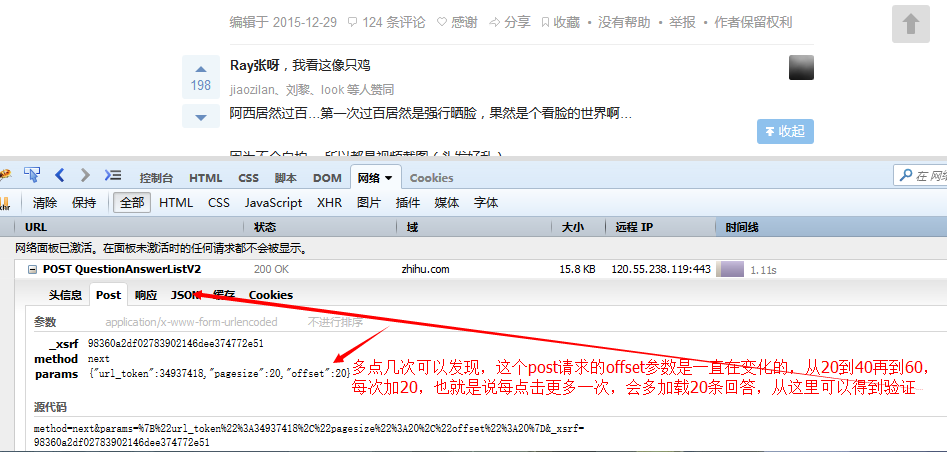
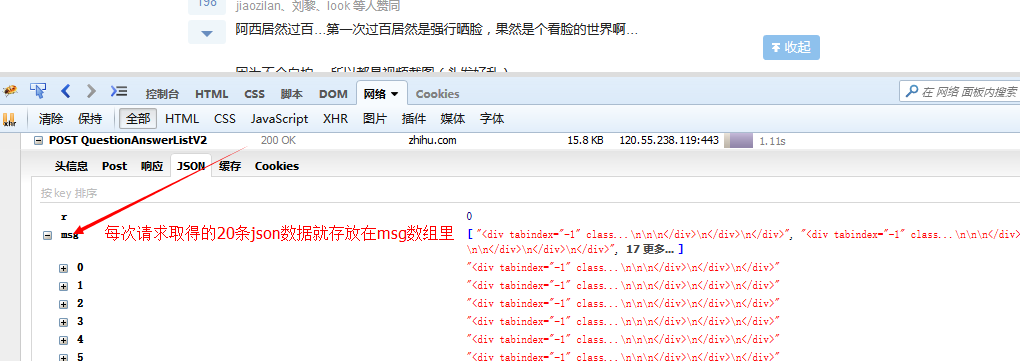
Mit diesen Informationen können Sie das Senden derselben Anfrage simulieren, um diese Daten zu erhalten.
/*每隔毫秒模拟发送ajax请求,并获取请求结果中所有的图片链接*/
var getIAjaxUrlList=function(offset){
request.post("https://www.zhihu.com/node/QuestionAnswerListV")
.set(config)
.send("method=next¶ms=%B%url_token%%A%C%pagesize%%A%C%offset%%A" +offset+ "%D&_xsrf=adfdeee")
.end(function(err,res){
if(err){
console.log(err);
}else{
var response=JSON.parse(res.text);/*想用json的话对json序列化即可,提交json的话需要对json进行反序列化*/
if(response.msg&&response.msg.length){
var $=cheerio.load(response.msg.join(""));/*把所有的数组元素拼接在一起,以空白符分隔,不要这样join(),它会默认数组元素以逗号分隔*/
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
setTimeout(function(){
offset+=;
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList(offset);
},);
}else{
console.log("图片链接全部获取完毕,一共有"+photos.length+"条图片链接");
// console.log(photos);
return downloadImg();
}
}
});
} Posten Sie diese Anfrage im Code https://www.zhihu.com/node/QuestionAnswerListV2, kopieren Sie die ursprünglichen Anfrageheader und Anfrageparameter als unsere Anfrageheader und Anfrageparameter, Superagent Die Set-Methode kann kann zum Festlegen von Anforderungsheadern verwendet werden, und die Sendemethode kann zum Senden von Anforderungsparametern verwendet werden. Wir initialisieren den Offset im Anforderungsparameter auf 20, addieren zu einem bestimmten Zeitpunkt 20 zum Offset und senden dann die Anforderung erneut. Dies entspricht dem Senden einer Ajax-Anfrage zu jedem bestimmten Zeitpunkt und dem Abrufen der neuesten 20 Daten Wenn wir die Daten erhalten, verarbeiten wir sie bis zu einem gewissen Grad und wandeln sie in einen ganzen HTML-Absatz um, der die anschließende Extraktion und Verknüpfungsverarbeitung erleichtert. Nachdem die asynchrone Parallelitätskontrolle Bilder heruntergeladen und alle Bildlinks abgerufen hat, d Bilder gibt es genug
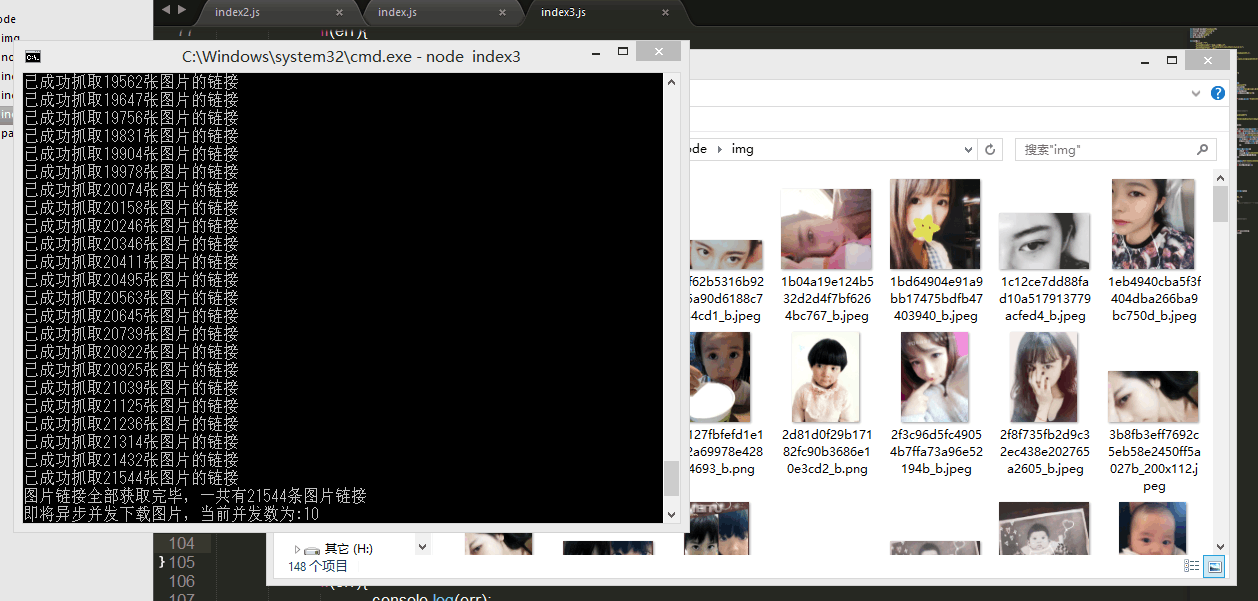
Ja, es gibt mehr als 20.000 Bilder, aber glücklicherweise verfügt NodeJS über die magische Single-Thread-Asynchronfunktion, wir können diese Bilder gleichzeitig herunterladen. Aber dieses Mal tritt ein Problem auf, dass die IP-Adresse von der Website blockiert wird, wenn zu viele Anfragen gleichzeitig gesendet werden! Stimmt das? Ich weiß es nicht, ich habe es nicht ausprobiert, weil ich es nicht ausprobieren möchte ( ̄ー ̄〃), also müssen wir zu diesem Zeitpunkt die Anzahl der asynchronen Parallelität kontrollieren.
Hier wird ein magisches Modul => async verwendet, das uns nicht nur hilft, den schwer zu wartenden Callback-Pyramiden-Teufel loszuwerden, sondern uns auch dabei hilft, asynchrone Prozesse einfach zu verwalten. Weitere Informationen finden Sie in der Dokumentation. Da ich selbst nicht weiß, wie ich es verwenden soll, verwende ich hier nur die leistungsstarke Methode async.mapLimit. Es ist wirklich großartig.
var requestAndwrite=function(url,callback){
request.get(url).end(function(err,res){
if(err){
console.log(err);
console.log("有一张图片请求失败啦...");
}else{
var fileName=path.basename(url);
fs.writeFile("./img/"+fileName,res.body,function(err){
if(err){
console.log(err);
console.log("有一张图片写入失败啦...");
}else{
console.log("图片下载成功啦");
callback(null,"successful !");
/*callback貌似必须调用,第二个参数将传给下一个回调函数的result,result是一个数组*/
}
});
}
});
}
var downloadImg=function(asyncNum){
/*有一些图片链接地址不完整没有“http:”头部,帮它们拼接完整*/
for(var i=;i<photos.length;i++){
if(photos[i].indexOf("http")===-){
photos[i]="http:"+photos[i];
}
}
console.log("即将异步并发下载图片,当前并发数为:"+asyncNum);
async.mapLimit(photos,asyncNum,function(photo,callback){
console.log("已有"+asyncNum+"张图片进入下载队列");
requestAndwrite(photo,callback);
},function(err,result){
if(err){
console.log(err);
}else{
// console.log(result);<=会输出一个有万多个“successful”字符串的数组
console.log("全部已下载完毕!");
}
});
};Schauen Sie zuerst hier=>
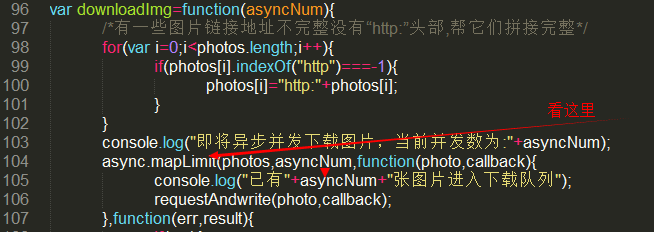
Der erste Parameter der MapLimit-Methode ist ein Array aller Bildlinks, das auch das Objekt unserer gleichzeitigen Anfragen ist. Ohne diesen Parameter werden mehr als 20.000 Anfragen gesendet Gleichzeitig wird Ihre IP erfolgreich blockiert, aber wenn wir diesen Parameter haben, ist sein Wert beispielsweise 10, es hilft uns nur, 10 Links gleichzeitig aus dem Array abzurufen und nach diesen 10 gleichzeitige Anforderungen auszuführen Auf jede Anfrage wird geantwortet, die nächsten 10 Anfragen werden gesendet. Sagen Sie Ni Meng, es ist in Ordnung, 100 Nachrichten gleichzeitig zu senden. Ich weiß nicht, ob es noch weiter geht.
Das Obige hat Ihnen im Nodejs-Crawler-Tutorial für Fortgeschrittene die relevanten Kenntnisse zur asynchronen Parallelitätskontrolle vermittelt. Ich hoffe, es wird Ihnen hilfreich sein.
 Der Unterschied zwischen Linux und Windows
Der Unterschied zwischen Linux und Windows
 Was ist mit dem Absturz von Douyin los?
Was ist mit dem Absturz von Douyin los?
 jquery animieren
jquery animieren
 Einführung in die Hauptarbeitsinhalte des Backends
Einführung in die Hauptarbeitsinhalte des Backends
 Eine vollständige Liste der Tastenkombinationen für Ideen
Eine vollständige Liste der Tastenkombinationen für Ideen
 Eine Sammlung häufig verwendeter Computerbefehle
Eine Sammlung häufig verwendeter Computerbefehle
 Warum schlägt die Win10-Aktivierung fehl?
Warum schlägt die Win10-Aktivierung fehl?
 Was ist Weidian?
Was ist Weidian?












