


Batch-, Mini-Batch- und stochastischer Gradientenabstieg

Kauf mir einen Kaffee☕
*Memos:
- Mein Beitrag erklärt Batch, Mini-Batch und stochastischen Gradientenabstieg mit DataLoader() in PyTorch.
- Mein Beitrag erklärt Batch Gradient Descent ohne DataLoader() in PyTorch.
- Mein Beitrag erklärt Optimierer in PyTorch.
Es gibt Batch Gradient Descent (BGD), Mini-Batch Gradient Descent (MBGD) und Stochastic Gradient Descent (SGD), die Möglichkeiten sind, Daten aus einem Datensatz zu entnehmen, um einen Gradientenabstieg mit dem durchzuführen Optimierer wie Adam(), SGD(), RMSprop(), Adadelta(), Adagrad() usw. in PyTorch.
*Memos:
- SGD() in PyTorch ist nur der grundlegende Gradientenabstieg ohne besondere Funktionen (klassischer Gradientenabstieg (CGD)), aber kein stochastischer Gradientenabstieg (SGD).
- Mit den folgenden Möglichkeiten können Sie beispielsweise flexibel BGD, MBGD oder SGD Adam mit Adam(), CGD mit SGD(), RMSprop mit RMSprop(), Adadelta mit Adadelta(), Adagrad mit Adagrad(), usw. in PyTorch.
- Grundsätzlich erfolgt BGD, MBGD oder SGD mit gemischten Datensätzen mit DataLoader():
*Memos:
- Das Mischen von Datensätzen verringert die Überanpassung. *Grundsätzlich werden nur Zugdaten gemischt, Testdaten werden also nicht gemischt.
- Mein Beitrag erklärt Overfitting und Underfitting.
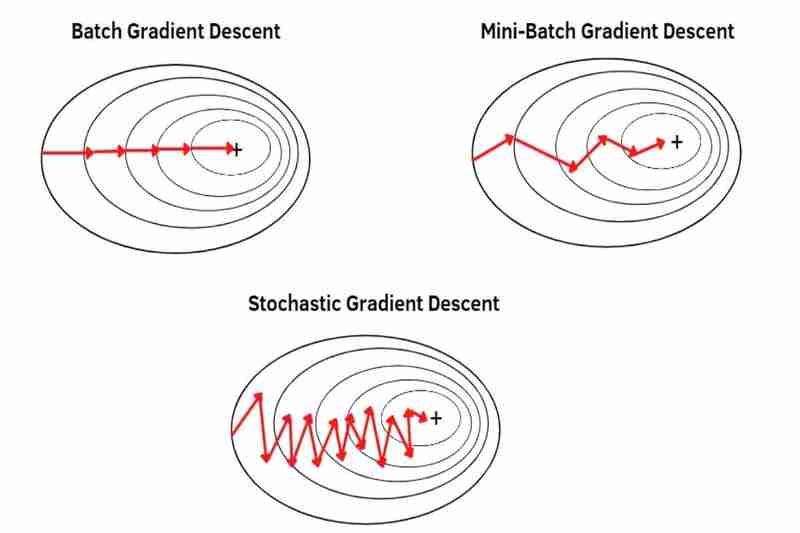
(1) Batch-Gradientenabstieg (BGD):
- kann einen Gradientenabstieg mit einem gesamten Datensatz durchführen und dabei nur einen Schritt in einer Epoche ausführen. Wenn beispielsweise ein ganzer Datensatz 100 Stichproben (1x100) hat, erfolgt der Gradientenabstieg nur einmal in einer Epoche, was bedeutet, dass die Parameter des Modells nur einmal in einer Epoche aktualisiert werden.
- verwendet den Durchschnitt eines gesamten Datensatzes, sodass jede Stichprobe weniger hervorsticht (weniger hervorgehoben) als MBGD und SGD. Infolgedessen ist die Konvergenz stabiler (weniger schwankend) als bei MBGD und SGD und auch stärker im Rauschen (verrauschte Daten) als bei MBGD und SGD, was weniger Überschwingungen als bei MBGD und SGD verursacht und ein genaueres Modell als bei MBGD und SGD erzeugt blieb nicht in lokalen Minima stecken, aber BGD entgeht lokalen Minima oder Sattelpunkten weniger leicht als MBGD und SGD, da die Konvergenz stabiler (weniger schwankend) ist als bei MBGD und SGD Wie ich bereits sagte, verursacht BGD leichter eine Überanpassung als MBGD und SGD, da jede Stichprobe weniger hervorsticht (weniger betont) als MBGD und SGD, wie ich bereits sagte.
*Memos:
- Konvergenz bedeutet, dass sich ein Anfangsgewicht durch Gradientenabstieg in Richtung des globalen Minimums einer Funktion bewegt.
- Rauschen (verrauschte Daten) bedeutet Ausreißer, Anomalien oder manchmal doppelte Daten.
- Überschießen bedeutet das Überspringen des globalen Minimums einer Funktion.
- s Vorteile:
- Die Konvergenz ist stabiler (weniger schwankend) als MBGD und SGD.
- Es ist stärker im Rauschen (verrauschte Daten) als MBGD und SGD.
- Es verursacht weniger Überschwingungen als MBGD und SGD.
- Es erstellt ein genaueres Modell als MBGD und SGD, wenn es nicht in lokalen Minima hängen bleibt.
- s Nachteile:
- Bei einem großen Datensatz wie Online-Lernen ist dies nicht gut, da es viel Speicher beansprucht und die Konvergenz verlangsamt. *Online-Lernen ist die Art und Weise, wie ein Modell schrittweise in Echtzeit aus einem Datensatz lernt.
- Wenn Sie ein Modell aktualisieren möchten, ist die Neuvorbereitung eines gesamten Datensatzes erforderlich.
- Es entgeht lokalen Minima oder Sattelpunkten weniger leicht als MBGD und SGD.
- Es verursacht leichter eine Überanpassung als MBGD und SGD.
(2) Mini-Batch-Gradientenabstieg (MBGD):
- kann einen Gradientenabstieg mit geteilten Datensätzen (den kleinen Stapeln eines gesamten Datensatzes) durchführen, einen kleinen Stapel nach dem anderen, wobei die gleiche Anzahl von Schritten erforderlich ist wie bei den kleinen Stapeln eines gesamten Datensatzes in einer Epoche. Beispielsweise wird der gesamte Datensatz mit 100 Stichproben (1x100) in 5 kleine Stapel (5x20) aufgeteilt, dann erfolgt der Gradientenabstieg fünfmal in einer Epoche, was bedeutet, dass die Parameter des Modells fünfmal in einer Epoche aktualisiert werden.
verwendet den Durchschnitt jeder kleinen Charge, aufgeteilt aus einem gesamten Datensatz, sodass jede Probe stärker hervorgehoben (hervorgehoben) wird als BDG. *Durch die Aufteilung eines gesamten Datensatzes in kleinere Chargen kann jede Probe immer stärker hervorstechen (immer mehr hervorgehoben werden). Infolgedessen ist die Konvergenz weniger stabil (schwankender) als BGD und auch weniger stark im Rauschen (verrauschte Daten) als BGD, was mehr zu Überschwingern als BGD führt und ein weniger genaues Modell als BGD erzeugt, selbst wenn es nicht in lokalen Minima hängen bleibt, sondern MBGD entgeht lokalen Minima oder Sattelpunkten leichter als BGD, weil die Konvergenz weniger stabil ist (stärker schwankt) als BGD, wie ich bereits sagte, und MBGD aufgrund jeder Stichprobe weniger leicht zu einer Überanpassung führt als BGD ist stärker hervorgehoben (betonter) als BGD, wie ich bereits sagte.
-
s Vorteile:
- Bei einem großen Datensatz wie Online-Lernen ist es besser als BGD, da es weniger Speicher benötigt als BGD und die Konvergenz weniger verlangsamt als BGD.
- Es ist nicht die Neuvorbereitung eines gesamten Datensatzes erforderlich, wenn Sie ein Modell aktualisieren möchten.
- Es entgeht lokalen Minima oder Sattelpunkten leichter als BGD.
- Es verursacht weniger leicht eine Überanpassung als BGD.
-
s Nachteile:
- Die Konvergenz ist weniger stabil (schwankender) als BGD.
- Es ist weniger stark im Rauschen (verrauschte Daten) als BGD.
- Es verursacht mehr Überschwingungen als BGD.
- Es erstellt ein weniger genaues Modell als BGD, selbst wenn es nicht in lokalen Minima hängen bleibt.
(3) Stochastischer Gradientenabstieg (SGD):
- kann einen Gradientenabstieg mit jeder einzelnen Stichprobe eines gesamten Datensatzes Stichprobe für Stichprobe durchführen, wobei die gleiche Anzahl von Schritten wie bei den Stichproben eines gesamten Datensatzes in einer Epoche erforderlich ist. Ein ganzer Datensatz hat beispielsweise 100 Stichproben (1x100), dann erfolgt der Gradientenabstieg 100 Mal in einer Epoche, was bedeutet, dass die Parameter des Modells 100 Mal in einer Epoche aktualisiert werden.
verwendet jede einzelne Stichprobe eines gesamten Datensatzes Stichprobe für Stichprobe, jedoch nicht den Durchschnitt, sodass jede Stichprobe stärker hervorgehoben (hervorgehoben) wird als MBGD. Infolgedessen ist die Konvergenz weniger stabil (schwankender) als bei MBGD und auch weniger stark im Rauschen (verrauschte Daten) als bei MBGD, was mehr zu Überschwingern als bei MBGD führt und ein weniger genaues Modell als bei MBGD erzeugt, selbst wenn sie nicht in lokalen Minima hängen bleibt, sondern SGD entgeht lokalen Minima oder Sattelpunkten leichter als MBGD, da die Konvergenz weniger stabil ist (stärker schwankt) als MBGD, wie ich bereits sagte, und SGD aufgrund jeder Stichprobe weniger leicht zu einer Überanpassung führt als MBGD ist, wie ich bereits sagte, auffälliger (hervorgehobener) als MBGD.
-
s Vorteile:
- Bei einem großen Datensatz wie Online-Lernen ist es besser als MBGD, da es weniger Speicher benötigt als MBGD und die Konvergenz weniger verlangsamt als MBGD.
- Es ist nicht die Neuvorbereitung eines gesamten Datensatzes erforderlich, wenn Sie ein Modell aktualisieren möchten.
- Es entgeht lokalen Minima oder Sattelpunkten leichter als MBGD.
- Es verursacht weniger leicht eine Überanpassung als MBGD.
-
s Nachteile:
- Die Konvergenz ist weniger stabil (schwankender) als MBGD.
- Es ist weniger stark im Rauschen (verrauschte Daten) als MBGD.
- Es verursacht mehr Überschwingungen als MBGD.
- Es erstellt ein weniger genaues Modell als MBGD, wenn es nicht in lokalen Minima hängen bleibt.
Das obige ist der detaillierte Inhalt vonBatch-, Mini-Batch- und stochastischer Gradientenabstieg. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Kann eine Python -Klasse mehrere Konstruktoren haben?
Jul 15, 2025 am 02:54 AM
Kann eine Python -Klasse mehrere Konstruktoren haben?
Jul 15, 2025 am 02:54 AM
Ja, ApythonCanhavemultipleConstructorToHalternativetechnik.1.UTEFAULTARGUMENTETHED__INIT__METHODTOALLIBLEINIGIALISIALISIONISCHE Withvaryingnumbersofparameter
 Python für die Reichweite des Schleifens
Jul 14, 2025 am 02:47 AM
Python für die Reichweite des Schleifens
Jul 14, 2025 am 02:47 AM
In Python ist die Verwendung von A for Loop mit der Funktion von range () eine häufige Möglichkeit, die Anzahl der Schleifen zu steuern. 1. Verwenden Sie, wenn Sie die Anzahl der Schleifen kennen oder nach Index zugreifen müssen. 2. Bereich (Stopp) von 0 bis Stopp-1, Bereich (Start, Stopp) von Start bis Stopp-1, Bereich (Start, Stopp) fügt die Schrittgröße hinzu; 3.. Beachten Sie, dass der Bereich nicht den Endwert enthält und iterable Objekte anstelle von Listen in Python 3 zurückgibt. 4.. Sie können überlist (range ()) in eine Liste konvertieren und negative Schrittgröße in umgekehrter Reihenfolge verwenden.
 Jul 21, 2025 am 02:48 AM
Jul 21, 2025 am 02:48 AM
Um mit Quantum Machine Learning (QML) zu beginnen, ist das bevorzugte Tool Python und Bibliotheken wie Pennylane, Qiskit, TensorFlowquantum oder Pytorchquantum müssen installiert werden. Machen Sie sich dann mit dem Prozess vertraut, indem Sie Beispiele ausführen, z. B. Pennylane zum Aufbau eines Quanten neuronalen Netzwerks. Implementieren Sie das Modell dann gemäß den Schritten der Datensatzvorbereitung, der Datencodierung, der Erstellung parametrischer Quantenschaltungen, klassisches Optimierer -Training usw.; Im tatsächlichen Kampf sollten Sie es vermeiden, komplexe Modelle von Anfang an zu verfolgen, Hardwarebeschränkungen zu beachten, hybride Modellstrukturen einzusetzen und kontinuierlich auf die neuesten Dokumente und offiziellen Dokumente zu verweisen, um die Entwicklung zu verfolgen.
 Zugriff auf Daten von einer Web -API in Python zu Daten
Jul 16, 2025 am 04:52 AM
Zugriff auf Daten von einer Web -API in Python zu Daten
Jul 16, 2025 am 04:52 AM
Der Schlüssel zur Verwendung von Python zum Aufrufen von Webapi, um Daten zu erhalten, liegt darin, die grundlegenden Prozesse und gemeinsamen Tools zu beherrschen. 1. Die Verwendung von Anfragen zum Einlösen von HTTP -Anforderungen ist der direkteste Weg. Verwenden Sie die GET -Methode, um die Antwort zu erhalten und JSON () zu verwenden, um die Daten zu analysieren. 2. Für APIs, die Authentifizierung benötigen, können Sie Token oder Schlüssel über Header hinzufügen. 3.. Sie müssen den Antwortstatuscode überprüfen. Es wird empfohlen, die Antwort zu verwenden. 4. Mit Blick auf die Paging -Schnittstelle können Sie nacheinander verschiedene Seiten anfordern und Verzögerungen hinzufügen, um Frequenzbeschränkungen zu vermeiden. 5. Bei der Verarbeitung der zurückgegebenen JSON -Daten müssen Sie Informationen gemäß der Struktur extrahieren, und komplexe Daten können in Daten konvertiert werden
 Python eine Zeile wenn noch
Jul 15, 2025 am 01:38 AM
Python eine Zeile wenn noch
Jul 15, 2025 am 01:38 AM
Python's OnelineIgelse ist ein ternärer Operator, der als Xifconditionelsey geschrieben wurde und zur Vereinfachung des einfachen bedingten Urteils verwendet wird. Es kann für die variable Zuordnung verwendet werden, wie z. B. Status = "Erwachsener" iFage> = 18LSE "minor"; Es kann auch verwendet werden, um Ergebnisse direkt in Funktionen wie Defget_Status (Alter) zurückzugeben: Rückgabe "Erwachsener" iFage> = 18LSE "Minor"; Obwohl eine verschachtelte Verwendung unterstützt wird, wie z. B. Ergebnis = "a" i i
 Abgeschlossener Python Blockbuster Online -Eingang Python Free Fertig -Website -Sammlung
Jul 23, 2025 pm 12:36 PM
Abgeschlossener Python Blockbuster Online -Eingang Python Free Fertig -Website -Sammlung
Jul 23, 2025 pm 12:36 PM
Dieser Artikel hat mehrere "Fertig" -Projekt-Websites von Python und "Blockbuster" -Portalen "Blockbuster" für Sie ausgewählt. Egal, ob Sie nach Entwicklungsinspiration suchen, den Quellcode auf Master-Ebene beobachten und lernen oder Ihre praktischen Fähigkeiten systematisch verbessern, diese Plattformen sind nicht zu übersehen und können Ihnen helfen, schnell zu einem Python-Meister zu werden.
 Python, wenn sonst Beispiel
Jul 15, 2025 am 02:55 AM
Python, wenn sonst Beispiel
Jul 15, 2025 am 02:55 AM
Der Schlüssel zum Schreiben von Pythons IFelse -Anweisungen liegt darin, die logische Struktur und Details zu verstehen. 1. Die Infrastruktur besteht darin, einen Code auszuführen, wenn die Bedingungen festgelegt werden. Andernfalls ist der Anliesiger ausgeführt, sonst ist optional. 2. Multi-Konditionsurteil wird mit ELIF umgesetzt und nacheinander ausgeführt und gestoppt, sobald es erfüllt ist. 3.. Verschachtelt, wenn es für ein weiteres Unterteilungsurteil verwendet wird, wird empfohlen, zwei Schichten nicht zu überschreiten. 4. Ein ternärer Ausdruck kann verwendet werden, um einfache IFelse in einem einfachen Szenario zu ersetzen. Nur wenn wir auf Einklebung, bedingte Reihenfolge und logische Integrität achten können, können wir klare und stabile Beurteilungscodes schreiben.
 Python für Loop zum Lesen der Dateizeile nach Zeile
Jul 14, 2025 am 02:47 AM
Python für Loop zum Lesen der Dateizeile nach Zeile
Jul 14, 2025 am 02:47 AM
Die Verwendung von A for Loop zum Lesen von Dateien für Zeile ist eine effiziente Möglichkeit, große Dateien zu verarbeiten. 1. Die grundlegende Nutzung besteht darin, die Datei mit Open () zu öffnen und das Schließen automatisch zu verwalten. Kombiniert mit ForlineInfile, um jede Zeile zu überqueren. Line.strip () kann Linienbrüche und Räume entfernen; 2. Wenn Sie die Zeilennummer aufzeichnen müssen, können Sie die Aufzählung (Datei, Start = 1) verwenden, um die Zeilennummer ab 1 zu starten. 3. Bei der Verarbeitung von Nicht-ASCII-Dateien sollten Sie Codierungsparameter wie UTF-8 angeben, um Codierungsfehler zu vermeiden. Diese Methoden sind prägnant und praktisch und für die meisten Textverarbeitungsszenarien geeignet.
