


Als Student habe ich aus erster Hand die Frustration miterlebt, die durch das ineffiziente Fundbürosystem unserer Universität verursacht wurde. Der aktuelle Prozess, der auf individuellen E-Mails für jeden gefundenen Gegenstand beruht, führt oft zu Verzögerungen und fehlenden Verbindungen zwischen verlorenen Gegenständen und ihren Besitzern.
Angetrieben von dem Wunsch, diese Erfahrung für mich und meine Kommilitonen zu verbessern, habe ich ein Projekt gestartet, um das Potenzial von Deep Learning für die Revolutionierung unseres Fundbüros zu erkunden. In diesem Blogbeitrag teile ich meine Erfahrung mit der Evaluierung vorab trainierter Modelle – ResNet, EfficientNet, VGG und NasNet – zur Automatisierung der Identifizierung und Kategorisierung verlorener Gegenstände.
Durch eine vergleichende Analyse möchte ich das am besten geeignete Modell für die Integration in unser System ermitteln, um letztendlich ein schnelleres, genaueres und benutzerfreundlicheres Fundraising-Erlebnis für alle auf dem Campus zu schaffen.
Inception-ResNet V2 ist eine leistungsstarke Faltungs-Neuronale Netzwerkarchitektur, die in Keras verfügbar ist und die Stärken der Inception-Architektur mit Restverbindungen von ResNet kombiniert. Dieses Hybridmodell zielt darauf ab, eine hohe Genauigkeit bei Bildklassifizierungsaufgaben zu erreichen und gleichzeitig die Recheneffizienz beizubehalten.
Trainingsdatensatz: ImageNet
Bildformat: 299 x 299
def readyForResNet(fileName):
pic = load_img(fileName, target_size=(299, 299))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_resnet(expanded)
data1 = readyForResNet(test_file) prediction = inception_model_resnet.predict(data1) res1 = decode_predictions_resnet(prediction, top=2)
VGG (Visual Geometry Group) ist eine Familie tiefer Faltungs-Neuronaler Netzwerkarchitekturen, die für ihre Einfachheit und Effektivität bei Bildklassifizierungsaufgaben bekannt sind. Diese Modelle, insbesondere VGG16 und VGG19, gewannen aufgrund ihrer starken Leistung bei der ImageNet Large Scale Visual Recognition Challenge (ILSVRC) im Jahr 2014 an Popularität.
Trainingsdatensatz: ImageNet
Bildformat: 224 x 224
def readyForVGG(fileName):
pic = load_img(fileName, target_size=(224, 224))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_vgg19(expanded)
data2 = readyForVGG(test_file) prediction = inception_model_vgg19.predict(data2) res2 = decode_predictions_vgg19(prediction, top=2)
EfficientNet ist eine Familie faltender neuronaler Netzwerkarchitekturen, die bei Bildklassifizierungsaufgaben modernste Genauigkeit erreichen und dabei deutlich kleiner und schneller als frühere Modelle sind. Diese Effizienz wird durch eine neuartige zusammengesetzte Skalierungsmethode erreicht, die Netzwerktiefe, -breite und -auflösung ausbalanciert.
Trainingsdatensatz: ImageNet
Bildformat: 480 x 480
def readyForEF(fileName):
pic = load_img(fileName, target_size=(480, 480))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_EF(expanded)
data3 = readyForEF(test_file) prediction = inception_model_EF.predict(data3) res3 = decode_predictions_EF(prediction, top=2)
NasNet (Neural Architecture Search Network) stellt einen bahnbrechenden Ansatz im Deep Learning dar, bei dem die Architektur des neuronalen Netzwerks selbst durch einen automatisierten Suchprozess entdeckt wird. Dieser Suchprozess zielt darauf ab, die optimale Kombination von Schichten und Verbindungen zu finden, um bei einer bestimmten Aufgabe eine hohe Leistung zu erzielen.
Trainingsdatensatz: ImageNet
Bildformat: 224 x 224
def readyForNN(fileName):
pic = load_img(fileName, target_size=(224, 224))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_NN(expanded)
data4 = readyForNN(test_file) prediction = inception_model_NN.predict(data4) res4 = decode_predictions_NN(prediction, top=2)

Die Tabelle fasst die behaupteten Genauigkeitswerte der oben genannten Modelle zusammen. EfficientNet B7 führt mit der höchsten Genauigkeit, dicht gefolgt von NasNet-Large und Inception-ResNet V2. VGG-Modelle weisen geringere Genauigkeiten auf. Für meine Anwendung möchte ich ein Modell wählen, das ein Gleichgewicht zwischen Bearbeitungszeit und Genauigkeit bietet.
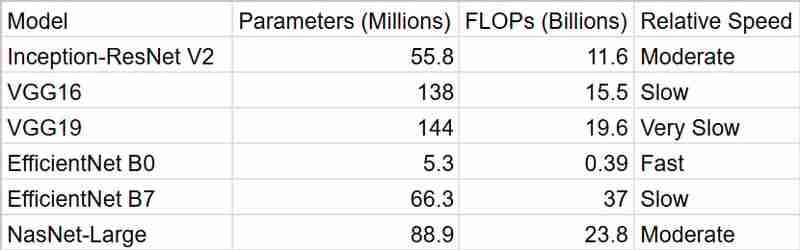
Wie wir sehen können, liefert uns EfficientNetB0 die schnellsten Ergebnisse, aber InceptionResNetV2 ist ein besseres Paket, wenn man die Genauigkeit berücksichtigt
Für mein intelligentes Fundbüro-System habe ich mich für InceptionResNetV2 entschieden. Während EfficientNet B7 mit seiner erstklassigen Genauigkeit verlockend aussah, machte ich mir Sorgen wegen seines Rechenaufwands. In einem universitären Umfeld, in dem die Ressourcen möglicherweise begrenzt sind und Echtzeitleistung oft wünschenswert ist, hielt ich es für wichtig, ein Gleichgewicht zwischen Genauigkeit und Effizienz zu finden. InceptionResNetV2 schien die perfekte Lösung zu sein – es bietet eine starke Leistung, ohne übermäßig rechenintensiv zu sein.
Außerdem gibt mir die Tatsache, dass es auf ImageNet vorab trainiert wurde, die Gewissheit, dass es mit der Vielfalt an Objekten umgehen kann, die Menschen verlieren könnten. Und vergessen wir nicht, wie einfach die Arbeit mit Keras ist! Das hat mir die Entscheidung auf jeden Fall erleichtert.
Insgesamt glaube ich, dass InceptionResNetV2 die richtige Mischung aus Genauigkeit, Effizienz und Praktikabilität für mein Projekt bietet. Ich bin gespannt, wie es dabei hilft, verlorene Gegenstände wieder ihren Besitzern zuzuführen!
Das obige ist der detaillierte Inhalt vonResNet vs. EfficientNet vs. VGG vs. NN. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Der Apple Store kann keine Verbindung herstellen
Der Apple Store kann keine Verbindung herstellen
 So richten Sie einen FTP-Server ein
So richten Sie einen FTP-Server ein
 Kernelutil.dll-Fehlerreparaturmethode
Kernelutil.dll-Fehlerreparaturmethode
 Lösung für den Computer-Anzeigefehlercode 651
Lösung für den Computer-Anzeigefehlercode 651
 Windows kann die Formatierung der Festplatte nicht abschließen
Windows kann die Formatierung der Festplatte nicht abschließen
 So definieren Sie ein Array
So definieren Sie ein Array
 Was ist besser, vivox100 oder vivox100pro?
Was ist besser, vivox100 oder vivox100pro?
 Welche Funktion hat der Frequenzteiler?
Welche Funktion hat der Frequenzteiler?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



