Machen Sie Ihre GPU bereit!
Llama 3.1 ist endlich erschienen, aber die Quelle ist nicht Meta-offiziell.
Heute ging die Nachricht vom Leak des neuen Llama-Großmodells auf Reddit viral.
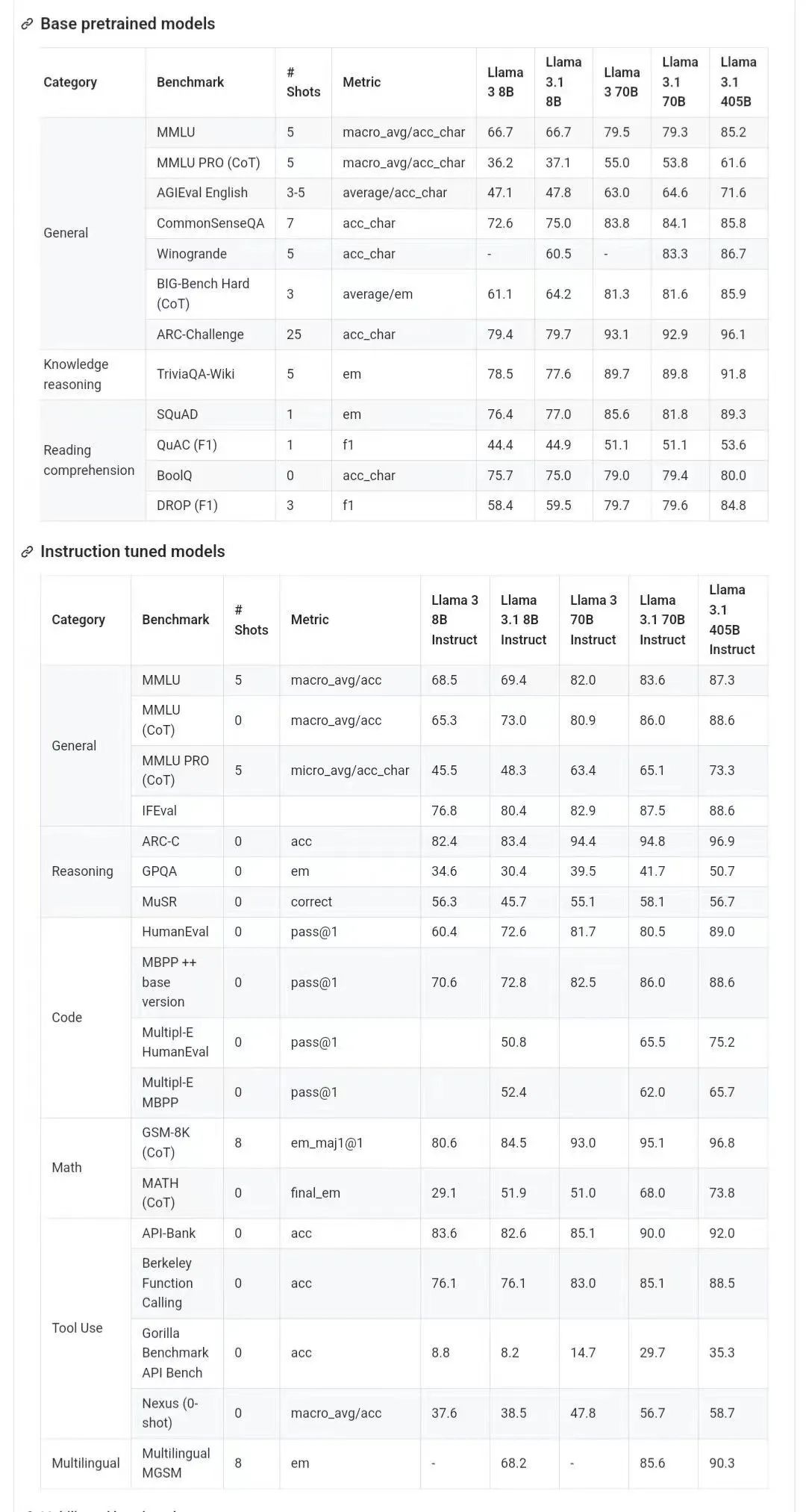
Zusätzlich zum Basismodell enthält es auch Benchmark-Ergebnisse von 8B, 70B und den maximalen Parameter von 405B.

Das Bild unten zeigt die Vergleichsergebnisse jeder Version von Llama 3.1 mit OpenAI GPT-4o und Llama 3 8B/70B. Wie Sie sehen können, übertrifft „selbst die 70B-Version GPT-4o“ bei mehreren Benchmarks.
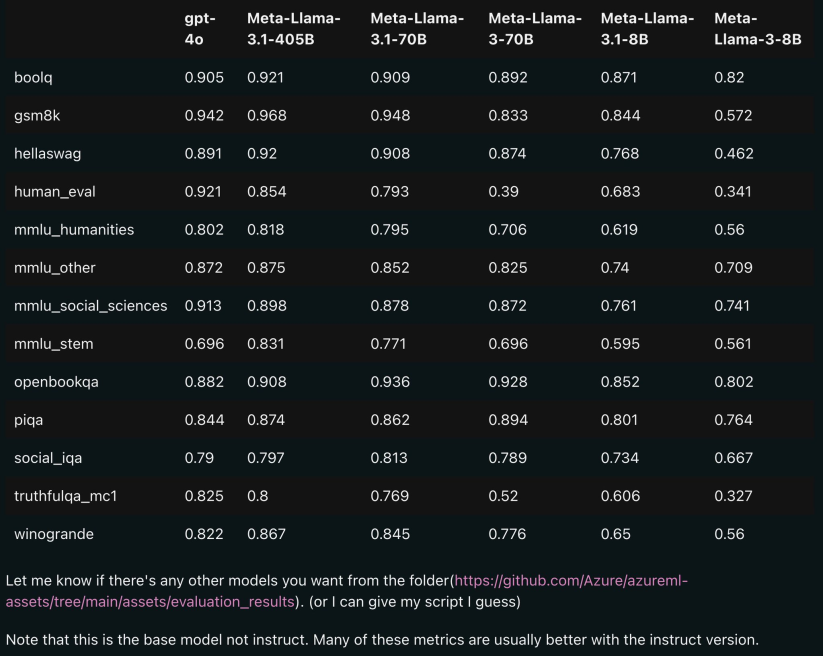
Die 8B- und 70B-Modelle der Version 3.1 sind aus 405B destilliert und weisen daher im Vergleich zur vorherigen Generation erhebliche Leistungsverbesserungen auf.
Einige Internetnutzer sagten, dass dies das erste Mal sei, dass ein Open-Source-Modell Closed-Source-Modelle wie GPT4o und Claude Sonnet 3.5 übertroffen und bei mehreren Benchmarks SOTA
Gleichzeitig ist die Modellkarte von Llama 3.1 durchgesickert und die Details wurden durchgesickert (das in der Modellkarte markierte Datum weist darauf hin, dass sie auf der Veröffentlichung vom 23. Juli basiert).
Jemand hat die folgenden Highlights zusammengefasst:
Das Modell verwendet 15T+ Token aus öffentlichen Quellen für das Training, und die Datenfrist vor dem Training endet im Dezember 2023;
Die Feinabstimmungsdaten umfassen öffentliche Verfügbarer Datensatz zur Feinabstimmung von Anweisungen (im Gegensatz zu Llama 3) und 15 Millionen synthetischen Beispielen.
Das Modell unterstützt mehrere Sprachen, darunter Englisch, Französisch, Deutsch, Hindi, Italienisch, Portugiesisch, Spanisch und Thailändisch.
-
-
-
Obwohl der durchgesickerte Github-Link derzeit 404 ist, haben einige Internetnutzer Download-Links angegeben (Aus Sicherheitsgründen wird jedoch empfohlen, heute Abend auf die offizielle Kanalankündigung zu warten):

Aber das ist schließlich ein 100-Milliarden-Level-Modell. Bitte bereiten Sie vor dem Herunterladen genügend Festplattenspeicher vor:
Das Folgende ist das Llama 3.1-Modell. Wichtiger Inhalt der Karte:
Basic Modellinformationen
 Die Meta Llama 3.1 Multilingual Large Language Model (LLM)-Sammlung besteht aus einer Reihe vorab trainierter und durch Anweisungen fein abgestimmter generativer Modelle mit den Größen 8B, 70B und 405B (Texteingabe/Textausgabe). Die auf Befehle von Llama 3.1 optimierten Nur-Text-Modelle (8B, 70B, 405B) sind für mehrsprachige Konversationsanwendungsfälle optimiert und übertreffen viele verfügbare Open- und Closed-Source-Chat-Modelle bei gängigen Branchen-Benchmarks.
Die Meta Llama 3.1 Multilingual Large Language Model (LLM)-Sammlung besteht aus einer Reihe vorab trainierter und durch Anweisungen fein abgestimmter generativer Modelle mit den Größen 8B, 70B und 405B (Texteingabe/Textausgabe). Die auf Befehle von Llama 3.1 optimierten Nur-Text-Modelle (8B, 70B, 405B) sind für mehrsprachige Konversationsanwendungsfälle optimiert und übertreffen viele verfügbare Open- und Closed-Source-Chat-Modelle bei gängigen Branchen-Benchmarks.
Modellarchitektur: Llama 3.1 ist ein optimiertes autoregressives Sprachmodell für die Transformer-Architektur. Die optimierte Version verwendet SFT und RLHF, um Benutzerfreundlichkeit und Sicherheitspräferenzen aufeinander abzustimmen.
Unterstützte Sprachen: Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch.
Aus den Modellkarteninformationen lässt sich ableiten, dass die Kontextlänge des
Llama 3.1-Serienmodells 128k
beträgt. Alle Modellversionen verwenden Grouped Query Attention (GQA), um die Skalierbarkeit der Inferenz zu verbessern.

BESTIMMTER VERWENDUNGSFALL. Llama 3.1 ist für mehrsprachige Geschäftsanwendungen und Forschung gedacht. Auf Anweisungen abgestimmte Nur-Text-Modelle eignen sich für assistentenähnliche Chats, während vorab trainierte Modelle an eine Vielzahl von Aufgaben zur Erzeugung natürlicher Sprache angepasst werden können.
Der Llama 3.1-Modellsatz unterstützt auch die Möglichkeit, seine Modellausgabe zu nutzen, um andere Modelle zu verbessern, einschließlich der Generierung und Destillation synthetischer Daten. Die Llama 3.1 Community-Lizenz ermöglicht diese Anwendungsfälle.
Llama 3.1 trainiert auf einer größeren Anzahl von Sprachen als den 8 unterstützten Sprachen. Entwickler können Llama 3.1-Modelle für andere Sprachen als die 8 unterstützten Sprachen verfeinern, sofern sie der Llama 3.1 Community-Lizenzvereinbarung und der Richtlinie zur akzeptablen Nutzung entsprechen, und sind in solchen Fällen dafür verantwortlich, sicherzustellen, dass andere Sprachen verwendet werden eine sichere und verantwortungsvolle Art und Weise Sprache Lama 3.1.
Software- und Hardware-Infrastruktur
Das erste ist das Trainingselement. Llama 3.1 verwendet eine benutzerdefinierte Trainingsbibliothek, einen Meta-angepassten GPU-Cluster und eine Produktionsinfrastruktur für das Vortraining und ist auch darauf abgestimmt der Produktionsinfrastruktur, Annotation und Auswertung.
Der zweite Punkt ist der Energieverbrauch des Trainings. Beim Llama 3.1-Training werden auf Hardware vom Typ H100-80 GB (TDP 700 W) insgesamt 39,3 Mio. GPU-Stunden benötigt. Hier ist die Trainingszeit die gesamte GPU-Zeit, die zum Trainieren jedes Modells erforderlich ist, und der Stromverbrauch ist die Spitzenleistungskapazität jedes GPU-Geräts, angepasst an die Energieeffizienz.
Schulung zum Thema Treibhausgasemissionen. Die gesamten Treibhausgasemissionen basierend auf geografischen Benchmarks werden während der Llama 3.1-Trainingsphase auf 11.390 Tonnen CO2e geschätzt. Seit 2020 hält Meta in seinen weltweiten Betrieben Netto-Treibhausgasemissionen von Null aufrecht und deckt 100 % seines Stromverbrauchs mit erneuerbarer Energie ab, was während des Schulungszeitraums zu marktbezogenen Treibhausgasemissionen von insgesamt 0 Tonnen CO2e führt.
Die Methoden zur Ermittlung des Trainingsenergieverbrauchs und der Treibhausgasemissionen finden Sie im folgenden Dokument. Da Meta diese Modelle öffentlich veröffentlicht, müssen andere nicht die Last der Schulung des Energieverbrauchs und der Treibhausgasemissionen tragen.
Papieradresse: https://arxiv.org/pdf/2204.05149
Übersicht: Llama 3.1 wurde mit etwa 1,5 Billionen Token-Daten aus öffentlichen Quellen durchgeführt. Ausbildung. Zu den Feinabstimmungsdaten gehören öffentlich verfügbare Befehlsdatensätze und über 25 Millionen synthetisch generierte Beispiele.
Datenaktualität: Die Frist für die Daten vor dem Training endet im Dezember 2023.
In diesem Abschnitt berichtet Meta über die Bewertungsergebnisse des Llama 3.1-Modells im Annotations-Benchmark. Für alle Auswertungen nutzt Meta interne Auswertungsbibliotheken.
Überlegungen zu Sicherheitsrisiken
Das Llama-Forschungsteam ist bestrebt, der Forschungsgemeinschaft wertvolle Ressourcen zur Verfügung zu stellen, um die Robustheit der Sicherheitsfeinabstimmung zu untersuchen und Entwicklern sichere und robuste Standardmodelle für eine Vielzahl bereitzustellen von Anwendungen, um die Arbeitsbelastung von Entwicklern zu reduzieren, die sichere KI-Systeme bereitstellen.
Das Forschungsteam verwendet einen vielschichtigen Datenerfassungsansatz und kombiniert von Menschen generierte Daten von Anbietern mit synthetischen Daten, um potenzielle Sicherheitsrisiken zu mindern. Das Forschungsteam entwickelte eine Reihe von Klassifikatoren, die auf einem großen Sprachmodell (LLM) basieren, um qualitativ hochwertige Eingabeaufforderungen und Antworten sorgfältig auszuwählen und so die Datenqualitätskontrolle zu verbessern.
Erwähnenswert ist, dass Llama 3.1 großen Wert auf die vorbildliche Ablehnung harmloser Aufforderungen und den Ablehnungston legt. Das Forschungsteam führte Grenzaufforderungen und kontradiktorische Aufforderungen in die Richtlinie für sichere Daten ein und änderte die Antworten auf sichere Daten, um den Tonrichtlinien zu folgen.
Das Modell Llama 3.1 ist nicht für den alleinigen Einsatz konzipiert, sondern sollte als Teil des Gesamtsystems der künstlichen Intelligenz eingesetzt werden, wobei bei Bedarf zusätzliche „Sicherheitsleitplanken“ bereitgestellt werden. Entwickler sollten beim Aufbau von Agentensystemen Systemsicherheitsmaßnahmen ergreifen.
Bitte beachten Sie, dass diese Version neue Funktionen einführt, darunter längere Kontextfenster, mehrsprachige Eingabe und Ausgabe sowie eine mögliche Entwicklerintegration mit Tools von Drittanbietern. Beim Erstellen mit diesen neuen Funktionen müssen Sie neben der Berücksichtigung der Best Practices, die im Allgemeinen für alle generativen KI-Anwendungsfälle gelten, auch besondere Aufmerksamkeit auf die folgenden Punkte richten:
Werkzeugverwendung: Wie bei der Standardsoftwareentwicklung Der Entwickler ist dafür verantwortlich, LLM mit den Tools und Diensten seiner Wahl zu integrieren. Sie sollten klare Richtlinien für ihre Anwendungsfälle entwickeln und die Integrität der von ihnen genutzten Drittanbieterdienste bewerten, um die Sicherheitseinschränkungen bei der Nutzung dieser Funktionalität zu verstehen.
Mehrsprachig: Lama 3.1 unterstützt neben Englisch 7 Sprachen: Französisch, Deutsch, Hindi, Italienisch, Portugiesisch, Spanisch und Thailändisch. Llama kann möglicherweise Text in anderen Sprachen ausgeben, dieser Text erfüllt jedoch möglicherweise nicht die Sicherheits- und Hilfsleistungsschwellenwerte.
Die Grundwerte von Lama 3.1 sind Offenheit, Inklusivität und Hilfsbereitschaft. Es ist so konzipiert, dass es jedem dient und für eine Vielzahl von Anwendungsfällen geeignet ist. Daher ist Llama 3.1 so konzipiert, dass es für Menschen aller Hintergründe, Erfahrungen und Perspektiven zugänglich ist. Bei Llama 3.1 stehen die Benutzer und ihre Bedürfnisse im Mittelpunkt, ohne unnötige Urteile oder Normen einzubauen, und es spiegelt gleichzeitig die Erkenntnis wider, dass selbst Inhalte, die in manchen Kontexten problematisch erscheinen, in anderen nützlich sein können. Llama 3.1 respektiert die Würde und Autonomie aller Benutzer und respektiert insbesondere die Werte des freien Denkens und der freien Meinungsäußerung, die Innovation und Fortschritt vorantreiben.
Aber Llama 3.1 ist eine neue Technologie, und wie jede neue Technologie birgt ihre Verwendung Risiken. Bisher durchgeführte Tests können und können nicht alle Situationen abdecken. Daher können die potenziellen Ergebnisse von Llama 3.1, wie bei allen LLMs, nicht im Voraus vorhergesagt werden, und in einigen Fällen reagiert das Modell möglicherweise ungenau, voreingenommen oder auf andere Weise anstößig auf Benutzereingaben. Daher sollten Entwickler vor der Bereitstellung einer Anwendung des Llama 3.1-Modells Sicherheitstests und Feinabstimmungen für die spezifische Anwendung des Modells durchführen.
Modellkartenquelle: https://pastebin.com/9jGkYbXY
Referenzinformationen: https://x.com/op7418/status/1815340034717069728
https: //x.com/iScienceLuvr/status/1815519917715730702
https://x.com/mattshumer_/status/1815444612414087294
Das obige ist der detaillierte Inhalt vonDas erste Open-Source-Modell, das das GPT4o-Niveau übertrifft! Llama 3.1 durchgesickert: 405 Milliarden Parameter, Download-Links und Modellkarten sind verfügbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 Offsetbreite
Offsetbreite Drei Methoden der GPU-Virtualisierung
Drei Methoden der GPU-Virtualisierung Was tun, wenn das Installationssystem die Festplatte nicht findet?
Was tun, wenn das Installationssystem die Festplatte nicht findet? Was tun, wenn Linux beim Ausführen einer Datei „Keine solche Datei oder kein solches Verzeichnis' anzeigt?
Was tun, wenn Linux beim Ausführen einer Datei „Keine solche Datei oder kein solches Verzeichnis' anzeigt? Top Ten der Rangliste der digitalen Geldwechsel
Top Ten der Rangliste der digitalen Geldwechsel GameProtectNet-Lösung
GameProtectNet-Lösung Linux fügt die Update-Quellenmethode hinzu
Linux fügt die Update-Quellenmethode hinzu Häufig verwendete Linux-Befehle
Häufig verwendete Linux-Befehle
























