


Ollama ist in erster Linie ein Wrapper um llama.cpp, der für lokale Inferenzaufgaben entwickelt wurde. Es ist normalerweise nicht Ihre erste Wahl, wenn Sie auf der Suche nach modernster Leistung oder Funktionen sind, aber es hat seinen Nutzen, insbesondere in Umgebungen, in denen externe Abhängigkeiten ein Problem darstellen.
Wenn Sie Ollama für die lokale KI-Entwicklung verwenden, ist die Einrichtung unkompliziert, aber effektiv. Entwickler nutzen Ollama normalerweise, um Inferenzaufgaben direkt auf ihren lokalen Computern auszuführen. Hier ist eine visuelle Darstellung eines typischen lokalen Entwicklungsaufbaus mit Ollama:

Diese Konfiguration ermöglicht es Entwicklern, schnell zu testen und zu iterieren, ohne die Komplexität der Remote-Server-Kommunikation. Es ist ideal für erste Prototyping- und Entwicklungsphasen, in denen eine schnelle Abwicklung entscheidend ist.
Der Übergang von einem lokalen Setup zu einer skalierbaren Cloud-Umgebung erfordert die Entwicklung von einem einfachen 1:1-Setup (eine Benutzeranfrage an einen Inferenzhost) zu einer komplexeren Many-to-Many-Konfiguration (mehrere Benutzeranfragen an mehrere Inferenzhosts). . Dieser Wandel ist notwendig, um die Effizienz und Reaktionsfähigkeit bei steigender Nachfrage aufrechtzuerhalten.
So sieht diese Skalierung beim Übergang von der lokalen Entwicklung zur Produktion aus:
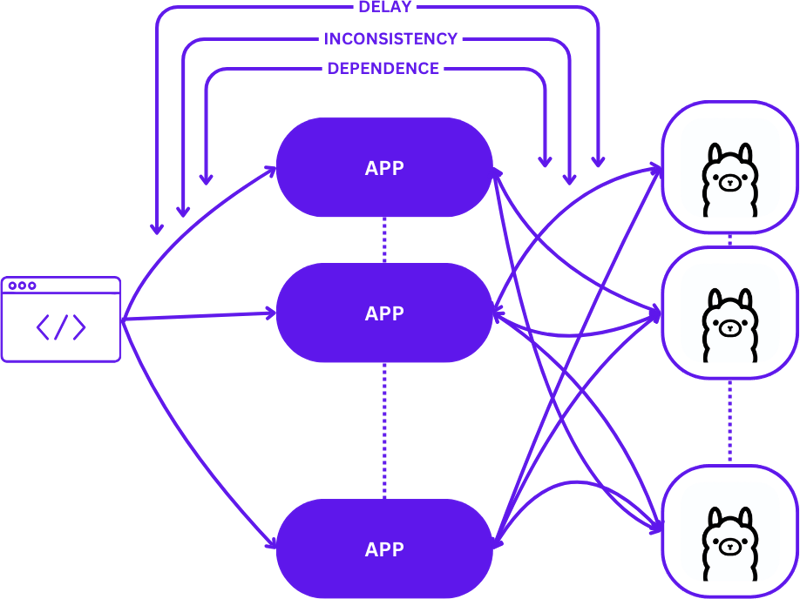
Ein unkomplizierter Ansatz während dieses Übergangs kann die Komplexität von Anwendungen erheblich erhöhen, insbesondere da Sitzungen die Konsistenz über verschiedene Zustände hinweg aufrechterhalten müssen. Es kann zu Verzögerungen und Ineffizienzen kommen, wenn Anfragen nicht optimal an den besten verfügbaren Inferenzhost weitergeleitet werden.
Darüber hinaus macht es die Komplexität verteilter Anwendungen schwierig, sie lokal zu testen, was den Entwicklungsprozess verlangsamen und das Risiko von Fehlern in Produktionsumgebungen erhöhen kann.
Serverless Computing abstrahiert Serververwaltungs- und Infrastrukturdetails, sodass sich Entwickler ausschließlich auf Code und Geschäftslogik konzentrieren können. Durch die Entkopplung der Anforderungsbearbeitung und der Konsistenzpflege von der Anwendung vereinfacht die serverlose Architektur die Skalierung.
Dieser Ansatz ermöglicht es der Anwendung, sich weiterhin auf die Wertschöpfung zu konzentrieren und viele häufige Skalierungsherausforderungen zu lösen, ohne Entwickler mit Infrastrukturkomplexitäten zu belasten.
WebAssembly (Wasm) begegnet der Herausforderung des Abhängigkeitsmanagements, indem es die Kompilierung von Anwendungen in eigenständige Module ermöglicht. Dadurch können Apps sowohl lokal als auch in der Cloud einfacher orchestriert und getestet werden, wodurch die Konsistenz in verschiedenen Umgebungen gewährleistet wird.
Tau ist ein Framework zum Aufbau wartungsarmer und hoch skalierbarer Cloud-Computing-Plattformen. Es zeichnet sich durch Einfachheit und Erweiterbarkeit aus. Tau vereinfacht die Bereitstellung und unterstützt den Betrieb einer lokalen Cloud für die Entwicklung, was End-to-End-Tests (E2E) sowohl der Cloud-Infrastruktur als auch der darauf ausgeführten Anwendungen ermöglicht.
Dieser von Taubyte als „Local Coding Equals Global Production“ bezeichnete Ansatz stellt sicher, dass das, was lokal funktioniert, auch global funktioniert, was die Entwicklungs- und Bereitstellungsprozesse erheblich vereinfacht.
Das Plugin-System von Tau, bekannt als Orbit, vereinfacht die Umwandlung von Diensten in verwaltbare Komponenten erheblich, indem es sie in WebAssembly-Hostmodule verpackt. Dieser Ansatz ermöglicht es Tau, die Orchestrierungsaufgaben zu übernehmen und so den Bereitstellungs- und Verwaltungsprozess zu optimieren.
Um Ollama-Funktionen innerhalb des Ökosystems von Tau zugänglich zu machen, nutzen wir das Orbit-System, um die Fähigkeiten von Ollama als aufrufbare Endpunkte zu exportieren. So können Sie einen Endpunkt in Go exportieren:
func (s *ollama) W_pull(ctx context.Context, module satellite.Module, modelNamePtr uint32, modelNameSize uint32, pullIdptr uint32) Error {
model, err := module.ReadString(modelNamePtr, modelNameSize)
if err != nil {
return ErrorReadMemory
}
id, updateFunc := s.getPullId(model)
if updateFunc != nil {
go func() {
err = server.PullModel(s.ctx, model, &server.RegistryOptions{}, updateFunc)
s.pullLock.Lock()
defer s.pullLock.Unlock()
s.pulls[id].err = err
}()
}
module.WriteUint64(pullIdptr, id)
return ErrorNone
}
Ein einfaches Beispiel für den Export von Funktionen finden Sie im hello_world-Beispiel.
Einmal definiert, ermöglichen diese Funktionen, die jetzt über Satellit.Export aufgerufen werden, die nahtlose Integration von Ollama in die Umgebung von Tau:
func main() {
server := new(context.TODO(), "/tmp/ollama-wasm")
server.init()
satellite.Export("ollama", server)
}
Das Testen des Plugins ist rationalisiert und unkompliziert. So können Sie einen serverlosen Funktionstest in Go schreiben:
//export pull
func pull() {
var id uint64
err := Pull("gemma:2b-instruct", &id)
if err != 0 {
panic("failed to call pull")
}
}
Mit der Testsuite von Tau und den Go-Builder-Tools können Sie Ihr Plugin erstellen, es in einer Testumgebung bereitstellen und die serverlosen Funktionen ausführen, um die Funktionalität zu überprüfen:
func TestPull(t *testing.T) {
ctx := context.Background()
// Create a testing suite to test the plugin
ts, err := suite.New(ctx)
assert.NilError(t, err)
// Use a Go builder to build plugins and wasm
gob := builder.New()
// Build the plugin from the directory
wd, _ := os.Getwd()
pluginPath, err := gob.Plugin(path.Join(wd, "."), "ollama")
assert.NilError(t, err)
// Attach plugin to the testing suite
err = ts.AttachPluginFromPath(pluginPath)
assert.NilError(t, err)
// Build a wasm file from serverless function
wasmPath, err := gob.Wasm(ctx, path.Join(wd, "fixtures", "pull.go"), path.Join(wd, "fixtures", "common.go"))
assert.NilError(t, err)
// Load the wasm module and call the function
module, err := ts.WasmModule(wasmPath)
assert.NilError(t, err)
// Call the "pull" function from our wasm module
_, err = module.Call(ctx, "pull")
assert.NilError(t, err)
}
You can find the complete code here https://github.com/ollama-cloud/ollama-as-wasm-plugin/tree/main/Aufbau einer Ollama Cloud – Skalierung lokaler Inferenz auf die Cloud
You can now build LLM applications with ease. Here are the steps to get started:
Das obige ist der detaillierte Inhalt vonAufbau einer Ollama Cloud – Skalierung lokaler Inferenz auf die Cloud. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist Lawine?
Was ist Lawine?
 So knacken Sie die Verschlüsselung von Zip-Dateien
So knacken Sie die Verschlüsselung von Zip-Dateien
 bootmgr fehlt und kann nicht booten
bootmgr fehlt und kann nicht booten
 Methoden zur Reparatur von Datenbankschwachstellen
Methoden zur Reparatur von Datenbankschwachstellen
 So verwenden Sie die Notnull-Annotation
So verwenden Sie die Notnull-Annotation
 Warum der Computer immer wieder automatisch neu startet
Warum der Computer immer wieder automatisch neu startet
 So sehen Sie Live-Wiedergabeaufzeichnungen auf Douyin
So sehen Sie Live-Wiedergabeaufzeichnungen auf Douyin
 Zu welcher Marke gehört das OnePlus-Handy?
Zu welcher Marke gehört das OnePlus-Handy?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



