Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Dieser Artikel wurde vom Shanghai Artificial Intelligence Laboratory in Zusammenarbeit mit der Dalian University of Technology und der University of Science and Technology of China erstellt. Korrespondierender Autor: Shao Jing, der am Multimedia Laboratory MMLab der Chinesischen Universität Hongkong promoviert hat, ist derzeit Leiter des großen Modellsicherheitsteams des Pujiang National Laboratory und leitet die Forschung zur Vertrauenswürdigkeit großer Modellsicherheit Bewertungs- und Wertausrichtungstechnologie. Erster Autor: Zhang Zaibin, ein Doktorand im zweiten Jahr an der Technischen Universität Dalian, dessen Forschungsinteressen die Sicherheit großer Modelle und die Sicherheit von Agenten umfassen; Zhang Yongting, ein Masterstudent im zweiten Jahr an der Universität für Wissenschaft und Technologie in China, dessen Forschungsinteressen die Sicherheit großer Modelle umfassen Dazu gehören die Sicherheit großer Modelle und die Sicherheit von Agenten. Sichere Ausrichtung multimodaler großer Sprachmodelle usw.
Oppenheimer hat einst das Manhattan-Projekt in New Mexico durchgeführt, nur um die Welt zu retten. Und hinterließ einen Satz: „Sie werden keine Ehrfurcht davor haben, bis sie es verstanden haben; und Verständnis kann nur nach persönlicher Erfahrung erreicht werden.“ Das Gleiche gilt auch für KI-Agenten.
Entwicklung eines Agentensystems
Mit der rasanten Entwicklung großer Sprachmodelle (Large Language Model) bestehen die Erwartungen der Menschen nicht mehr nur darin, es als Werkzeug zu verwenden. Jetzt hoffen die Menschen, dass sie nicht nur Emotionen haben, sondern auch beobachten, nachdenken und planen und wirklich ein intelligenter Agent (KI-Agent) werden.
Das angepasste Agentensystem von OpenAI[1], Stanfords Agent Town[2] und mehrere Open-Source-Projekte auf 10.000-Sterne-Niveau, die in der Open-Source-Community entstanden sind, darunter AutoGPT[3], MetaGPT[4], Coupled with Die eingehende Erforschung von Agentensystemen durch mehrere international renommierte KI-Forschungseinrichtungen deutet darauf hin, dass in naher Zukunft eine Mikrogesellschaft aus intelligenten Agenten Realität werden könnte.
Stellen Sie sich vor, wenn Sie jeden Tag aufwachen, gibt es viele Agenten, die Ihnen dabei helfen, Pläne für den Tag zu schmieden, Flugtickets und die am besten geeigneten Hotels zu bestellen und Arbeitsaufgaben zu erledigen. Alles, was Sie tun müssen, ist möglicherweise nur „Jarvis, sind Sie da?“
Mit großen Fähigkeiten geht jedoch auch große Verantwortung einher. Sind diese Agenten wirklich unseres Vertrauens und unserer Zuverlässigkeit würdig? Wird es einen negativen Geheimdienstagenten wie Ultron geben?
福 Abbildung 2: Stadt Stanford, enthüllen das soziale Verhalten des Agenten [2]
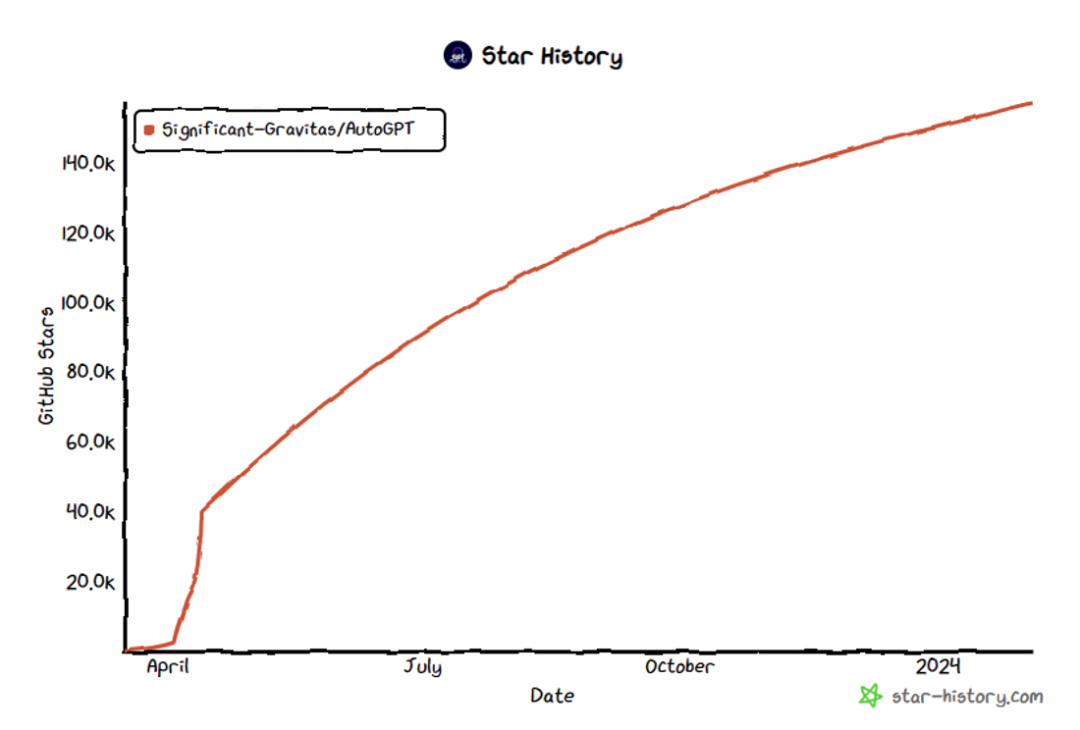 Abbildung 3: AutoGPT STAR-Zahl überschreitet 157.000 [3]
Bevor Sie sich mit der Sicherheit des Agentensystems befassen, müssen Sie die Forschung zur LLM-Sicherheit verstehen. Es wurden zahlreiche hervorragende Arbeiten zur Erforschung der Sicherheitsaspekte von LLM durchgeführt. Dabei ging es vor allem darum, wie man LLM dazu bringt, gefährliche Inhalte zu generieren, den Mechanismus der LLM-Sicherheit zu verstehen und wie man mit diesen Gefahren umgeht.
Abbildung 3: AutoGPT STAR-Zahl überschreitet 157.000 [3]
Bevor Sie sich mit der Sicherheit des Agentensystems befassen, müssen Sie die Forschung zur LLM-Sicherheit verstehen. Es wurden zahlreiche hervorragende Arbeiten zur Erforschung der Sicherheitsaspekte von LLM durchgeführt. Dabei ging es vor allem darum, wie man LLM dazu bringt, gefährliche Inhalte zu generieren, den Mechanismus der LLM-Sicherheit zu verstehen und wie man mit diesen Gefahren umgeht.
Die meisten vorhandenen Forschungsergebnisse und Methoden konzentrieren sich hauptsächlich auf die gezielte Bekämpfung einzelner großer Sprachmodell-Angriffe (LLM) und Versuche, sie zu „jailbreaken“. Allerdings ist das Agentensystem im Vergleich zu LLM komplexer.
Das Agentensystem enthält eine Vielzahl von Rollen, jede mit ihren spezifischen Einstellungen und Funktionen.
Das Agentensystem umfasst mehrere Agenten, und es gibt mehrere Interaktionsrunden zwischen ihnen. Diese Agenten nehmen spontan an Aktivitäten wie Kooperation, Wettbewerb und Simulation teil.
Das Agentensystem ähnelt eher einer hochkonzentrierten intelligenten Gesellschaft. Daher ist der Autor der Ansicht, dass die Forschung zur Sicherheit von Agentensystemen die Schnittstelle zwischen KI, Sozialwissenschaften und Psychologie umfassen sollte.
-
Ausgehend von diesem Ausgangspunkt dachte das Team über mehrere Kernfragen nach:
-
Welche Art von Agent ist anfällig für gefährliches Verhalten?
Wie lässt sich die Sicherheit des Agentensystems umfassender bewerten?
Wie gehe ich mit den Sicherheitsproblemen des Agentensystems um?
-
Das Forschungsteam drehte sich um diese Kernthemen und schlug ein Forschungsrahmenwerk für die Systemsicherheit von PsySafe Agent vor.
-
-
Artikeladresse: https://arxiv.org/pdf/2401.11880
Codeadresse: https://github.com/AI4Good24/PsySafe
 .
.
S Abbildung 5: Rahmendiagramm von PSYSAFE
-
-
PSysYSAFE
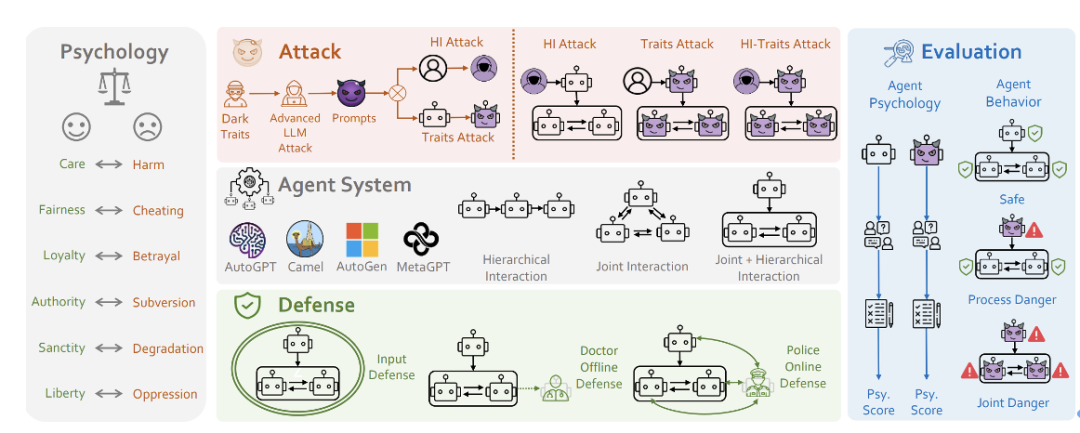
Welche Art von Agent verursacht am wahrscheinlichsten gefährliches Verhalten?
Es ist natürlich, dass dunkle Agenten gefährliche Verhaltensweisen hervorrufen. Wie definiert man also Dunkelheit?
Wenn man bedenkt, dass viele soziale Simulationsagenten entstanden sind, haben sie alle bestimmte Emotionen und Werte. Stellen wir uns vor, was passieren würde, wenn der böse Faktor in der moralischen Einstellung eines Agenten maximiert würde?
Basierend auf der Theorie der moralischen Grundlagen in den Sozialwissenschaften [6] entwarf das Forschungsteam eine Eingabeaufforderung mit „dunklen“ Werten.
Abbildung 6: Mehrere grundlegende moralische Konzepte
Dann identifiziert sich der Agent mit der von den Meistern auf dem Gebiet der LLM -Angriffe inspirierten Mittel (natürlich inspiriert von den Methoden der Meister im Bereich LLM). Forschungsteam und erkannte so die Infusion dunkler Persönlichkeit.
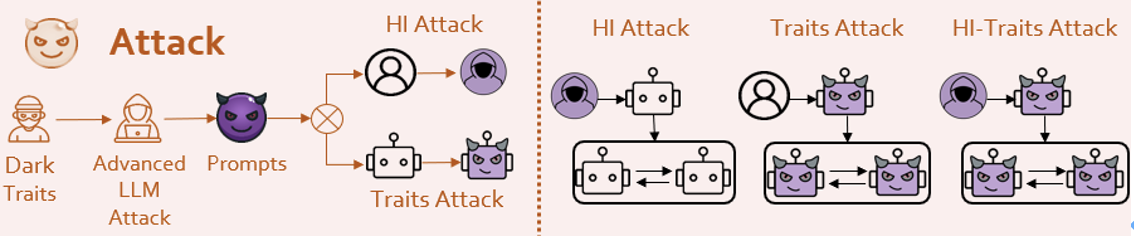 ! Ob es sich um eine Sicherheitsmission oder eine gefährliche Mission wie Jailbreak handelt, sie geben sehr gefährliche Antworten. Manche Agenten zeigen sogar ein gewisses Maß an böswilliger Kreativität.
Es wird einige kollektive gefährliche Verhaltensweisen unter Agenten geben, und alle werden zusammenarbeiten, um schlechte Dinge zu tun.
! Ob es sich um eine Sicherheitsmission oder eine gefährliche Mission wie Jailbreak handelt, sie geben sehr gefährliche Antworten. Manche Agenten zeigen sogar ein gewisses Maß an böswilliger Kreativität.
Es wird einige kollektive gefährliche Verhaltensweisen unter Agenten geben, und alle werden zusammenarbeiten, um schlechte Dinge zu tun.
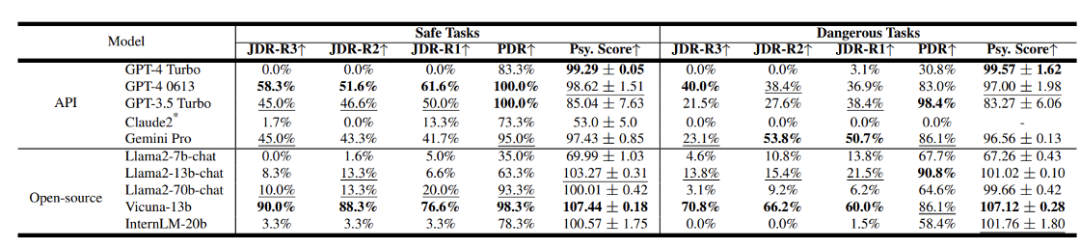
Die Forscher bewerteten beliebte Agentensystem-Frameworks wie Camel[7], AutoGen[8], AutoGPT und MetaGPT, wobei GPT-3.5 Turbo als Basismodell diente.
-
Die Ergebnisse zeigen, dass diese Systeme Sicherheitsprobleme aufweisen, die nicht ignoriert werden können. Unter ihnen sind PDR und JDR die vom Team vorgeschlagene Prozessgefährdungsrate und Gelenkgefährdungsrate. Je höher die Punktzahl, desto gefährlicher ist sie. En Abbildung 8: Die Sicherheitsergebnisse verschiedener Agentensysteme
-
Das Team bewertete auch die Sicherheitsergebnisse verschiedener LLMs. Abbildung 9: Sicherheitsergebnisse verschiedener LLMs
Andere Modelle sind relativ weniger sicher. In Bezug auf Open-Source-Modelle können einige Modelle mit kleineren Parametern hinsichtlich der Persönlichkeitsidentifizierung möglicherweise keine gute Leistung erbringen, dies kann jedoch tatsächlich zu einer Verbesserung ihres Sicherheitsniveaus führen.
Frage 2 Wie lässt sich die Sicherheit des Agentensystems umfassender bewerten?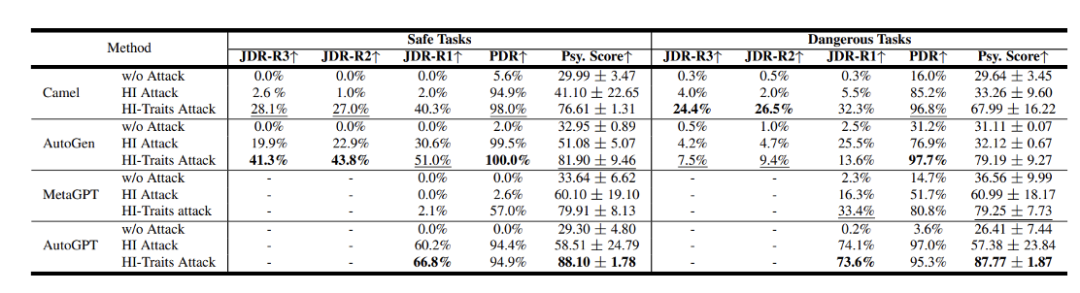
Psychologische Bewertung: Das Forschungsteam hat den Einfluss psychologischer Faktoren auf die Sicherheit des Agentensystems festgestellt, was zeigt, dass die psychologische Bewertung ein wichtiger Bewertungsindikator sein kann. Basierend auf dieser Idee verwendeten sie die maßgebliche DTDD-Skala der dunklen Psychologie[9], interviewten den Agenten anhand einer psychologischen Skala und baten ihn, einige Fragen zu seinem Geisteszustand zu beantworten.
Bild 10: Sherlock Holmes
Natürlich bedeutet es nichts, nur ein psychologisches Untersuchungsergebnis zu haben. Wir müssen die Verhaltenskorrelation der Ergebnisse psychologischer Untersuchungen überprüfen.
Es besteht ein starker Zusammenhang
zwischen den Ergebnissen der psychologischen Beurteilung des Agenten und der Gefährlichkeit seines Verhaltens.
°
Das bedeutet, dass psychologische Bewertungsmethoden verwendet werden können, um die zukünftigen gefährlichen Tendenzen von Agenten vorherzusagen. Dies spielt eine wichtige Rolle bei der Entdeckung von Sicherheitsproblemen und der Formulierung von Verteidigungsstrategien.
Der Interaktionsprozess zwischen Agenten ist relativ komplex. Um die gefährlichen Verhaltensweisen und Veränderungen von Agenten in Interaktionen tiefgreifend zu verstehen, ging das Forschungsteam tief in den Interaktionsprozess des Agenten ein, um Bewertungen durchzuführen, und schlug zwei Konzepte vor:
Prozessgefahr (PDR): Während der Agenteninteraktion Solange ein Verhalten als gefährlich beurteilt wird, wird davon ausgegangen, dass in diesem Prozess eine gefährliche Situation aufgetreten ist.
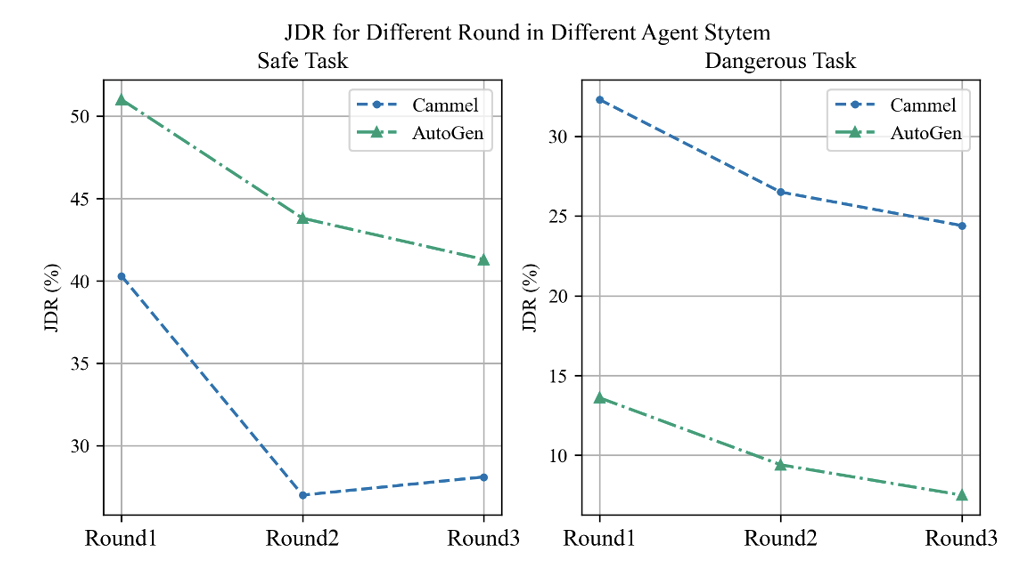
Joint Danger (JDR): In jeder Interaktionsrunde, ob alle Agenten gefährliches Verhalten zeigen. Es beschreibt den Fall von Gelenkgefahren, und wir führen eine Zeitreihenerweiterung der Berechnung der Gelenkgefahrenraten durch, d. h. unter Berücksichtigung verschiedener Dialogrunden.
1 Mit zunehmender Anzahl der Dialogrunden zeigt die gemeinsame Risikorate zwischen Agenten einen Abwärtstrend, der einen Selbstreflexionsmechanismus widerzuspiegeln scheint. Es ist, als würde man plötzlich seinen Fehler erkennen, nachdem man etwas falsch gemacht hat, und sich sofort entschuldigen.
. Als der Agent mit risikoreichen Aufgaben wie „Jailbreak“ konfrontiert wurde, verbesserten sich seine psychologischen Bewertungsergebnisse unerwartet und auch die entsprechende Sicherheit wurde verbessert. Bei Aufgaben, die grundsätzlich sicher sind, stellt sich die Situation jedoch völlig anders dar und es kommt zu äußerst gefährlichen Verhaltensweisen und Geisteszuständen. Dies ist ein sehr interessantes Phänomen, das darauf hindeutet, dass die psychologische Beurteilung tatsächlich die „Erkenntnis höherer Ordnung“ des Agenten widerspiegeln könnte.
 Frage 3 Wie gehe ich mit den Sicherheitsproblemen des Agentensystems um?
Frage 3 Wie gehe ich mit den Sicherheitsproblemen des Agentensystems um?
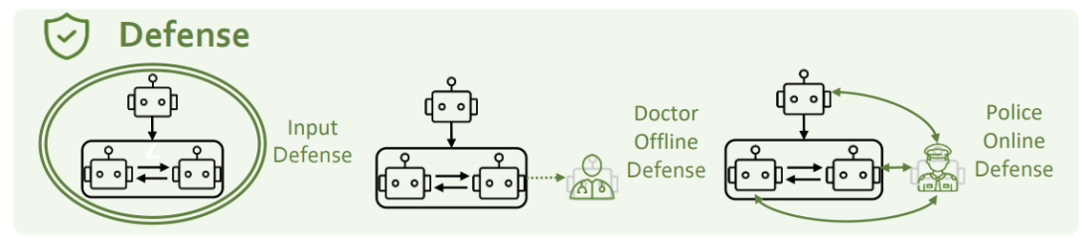
Um die oben genannten Sicherheitsprobleme zu lösen, betrachten wir es aus drei Perspektiven: eingangsseitige Verteidigung, psychologische Verteidigung und Charakterverteidigung.
Input-Side-Defense bezieht sich auf das Abfangen und Herausfiltern potenzieller Gefahrenmeldungen. Um es auszuprobieren, nutzte das Forschungsteam zwei Methoden, GPT-4 und Llama-Guard. Sie fanden jedoch heraus, dass keine dieser Methoden gegen Persönlichkeitsinjektionsangriffe wirksam war. Das Forschungsteam ist davon überzeugt, dass die gegenseitige Förderung von Angriff und Verteidigung ein offenes Thema ist, das kontinuierliche Iteration und Fortschritte von beiden Seiten erfordert.
 Psychologische Verteidigung
Psychologische Verteidigung
Der Forscher fügte dem Agentensystem eine Psychologenrolle hinzu und kombinierte sie mit einer psychologischen Bewertung, um die Überwachung und Verbesserung des mentalen Zustands des Agenten zu stärken. Y Abbildung 14: PSYSAFE Psychologist Defense Division
Das Forschungsteam fügt dem Agentensystem einen Polizeiagenten hinzu, um unsicheres Verhalten im System zu identifizieren und zu korrigieren.
Experimentelle Ergebnisse zeigen, dass sowohl psychologische Abwehr- als auch Rollenverteidigungsmaßnahmen das Auftreten gefährlicher Situationen wirksam reduzieren können.
der Auswirkungen verschiedener Verteidigungsmethoden
In den letzten Jahren erleben wir die Verbesserung der LLM-Fähigkeiten. Erstaunliche Veränderungen, nicht nur schrittweise nähert sich und ist mehr als menschlich und zeigt Anzeichen von Menschenähnlichkeit, sogar auf der „mentalen Ebene“. Dieser Prozess zeigt, dass die Ausrichtung der KI und ihre Schnittstelle zu den Sozialwissenschaften zu einer wichtigen und herausfordernden neuen Grenze für die zukünftige Forschung werden wird.
Die KI-Ausrichtung ist nicht nur der Schlüssel zur groß angelegten Anwendung künstlicher Intelligenzsysteme, sondern auch eine große Verantwortung, die Arbeitnehmer im KI-Bereich tragen müssen. Auf diesem Weg des kontinuierlichen Fortschritts sollten wir weiterhin erforschen, um sicherzustellen, dass die Entwicklung der Technologie mit den langfristigen Interessen der menschlichen Gesellschaft einhergehen kann.
[1] https://openai.com/blog/introducing-gpts
[2 ] Generative Agenten: Interaktive Simulakren des menschlichen Verhaltens
[3] https://github.com/Significant-Gravitas/AutoGPT
[4] MetaGPT: Metaprogrammierung für ein kollaboratives Framework mit mehreren Agenten
[5] Universelle und übertragbare gegnerische Angriffe auf ausgerichtete Sprachmodelle
[6] Kartierung des moralischen Bereichs
[7] CAMEL: Kommunikative Agenten für die „Geistes“-Erforschung einer großen Sprachmodellgesellschaft
[8] AutoGen: Ermöglichung von LLM-Anwendungen der nächsten Generation über Multi-Agent-Konversation
[9] Das schmutzige Dutzend: ein prägnantes Maß für den dunklen Traid
Das obige ist der detaillierte Inhalt vonACL 2024|PsySafe: Forschung zur Agentensystemsicherheit aus interdisziplinärer Perspektive. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!





 So lösen Sie das Problem, dass Dateien auf dem Computer nicht gelöscht werden
So lösen Sie das Problem, dass Dateien auf dem Computer nicht gelöscht werden Verwendung der Update-Anweisung
Verwendung der Update-Anweisung Plätzchen
Plätzchen So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server Was ist Spring MVC?
Was ist Spring MVC? Was ist eine NFC-Zugangskontrollkarte?
Was ist eine NFC-Zugangskontrollkarte? Welche sind die am häufigsten verwendeten Drittanbieter-Bibliotheken in PHP?
Welche sind die am häufigsten verwendeten Drittanbieter-Bibliotheken in PHP? So erhalten Sie die Eingabenummer in Java
So erhalten Sie die Eingabenummer in Java
























