


Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert, in denen sie große Mengen an realem Wissen erwerben. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen.

Richten Sie das Modell aus oder führen Sie eine Anweisungsoptimierung durch, damit das Modell lernen kann, dieses Wissen voll auszunutzen und natürlicher auf die Fragen des Benutzers zu reagieren. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung wird mithilfe von Eingaben durchgeführt, die von menschlichen Annotatoren oder anderen LLMs erstellt wurden, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und es in die Parameter integriert.
Auf mechanistischer Ebene wissen wir nicht wirklich, wie diese Interaktion abläuft. Einigen zufolge kann der Kontakt mit diesem neuen Wissen dazu führen, dass das Modell halluziniert. Dies liegt daran, dass das Modell darauf trainiert ist, Fakten zu generieren, die nicht auf seinem bereits vorhandenen Wissen basieren (oder möglicherweise im Widerspruch zum vorherigen Wissen des Modells stehen). Es besteht auch Kenntnis darüber, welche Erscheinungen das Modell voraussichtlich antreffen wird (z. B. Entitäten, die im Korpus vor dem Training seltener vorkommen).
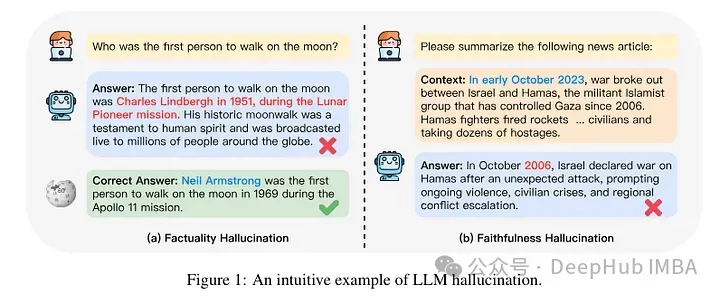
Eine kürzlich veröffentlichte Studie konzentrierte sich also auf die Analyse, was passiert, wenn einem Modell durch Feinabstimmung neues Wissen verliehen wird. Die Autoren untersuchen detailliert, was mit einem fein abgestimmten Modell passiert und wie es nach dem Erwerb neuer Erkenntnisse reagiert.
Sie versuchen, die Beispiele nach der Feinabstimmung auf der Wissensebene einzuordnen. Das einem neuen Beispiel innewohnende Wissen stimmt möglicherweise nicht vollständig mit dem Wissen des Modells überein. Beispiele können bekannt oder unbekannt sein. Selbst wenn es bekannt ist, kann es sehr bekannt sein, es kann bekannt sein oder es kann weniger bekanntes Wissen sein.
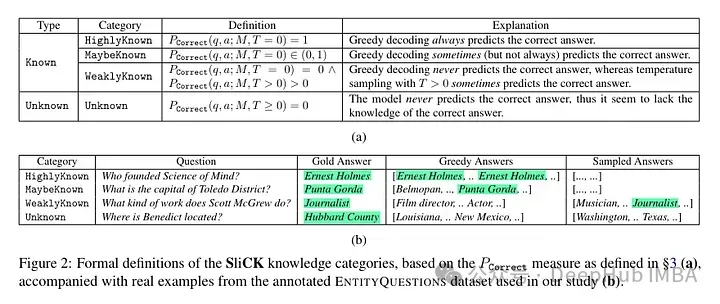
Dann verwendete der Autor ein Modell (PaLM 2-M) zur Feinabstimmung. Jedes Nudge-Beispiel besteht aus Faktenwissen (Subjekte, Beziehungen, Objekte). Dies soll es dem Modell ermöglichen, dieses Wissen mit spezifischen Fragen, spezifischen Tripeln (z. B. „Wo liegt Paris?“) und Ground-Truth-Antworten (z. B. „Frankreich“) abzufragen. Mit anderen Worten: Sie versorgen das Modell mit neuem Wissen und rekonstruieren diese Tripel dann in Fragen (Frage-Antwort-Paare), um sein Wissen zu testen. Sie gruppieren alle diese Beispiele in die oben besprochenen Kategorien und bewerten dann die Antworten.
Testergebnisse nach der Feinabstimmung des Modells: Ein hoher Anteil unbekannter Fakten führt zu Leistungseinbußen (die nicht durch eine längere Feinabstimmungszeit ausgeglichen werden).
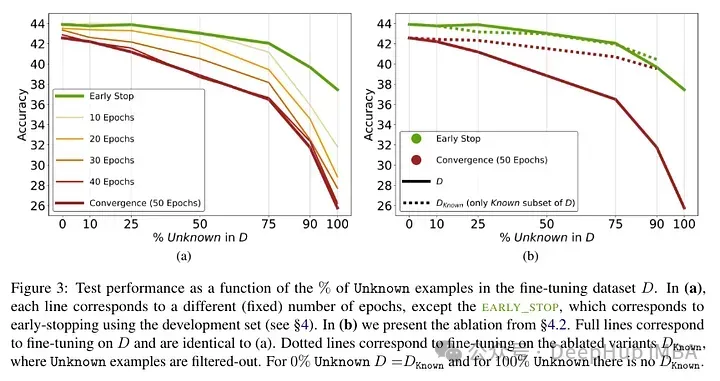
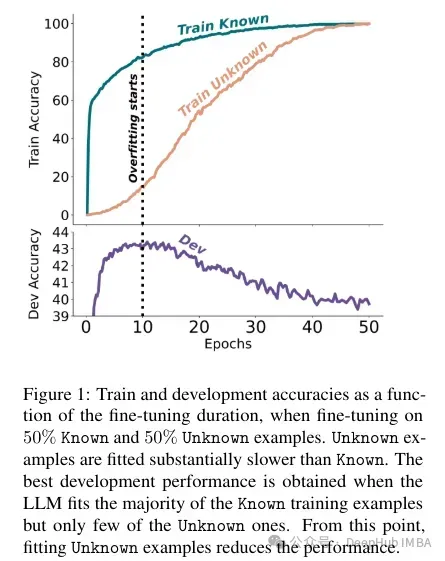
Unbekannte Fakten wirken sich bei niedrigeren Epochenzahlen nahezu neutral aus, beeinträchtigen jedoch die Leistung bei höheren Epochenzahlen. Unbekannte Beispiele scheinen also schädlich zu sein, ihre negativen Auswirkungen zeigen sich jedoch hauptsächlich in den späteren Phasen der Ausbildung. Die folgende Grafik zeigt die Trainingsgenauigkeit als Funktion der Feinabstimmungsdauer für bekannte und unbekannte Teilmengen des Beispieldatensatzes. Es ist ersichtlich, dass das Modell zu einem späteren Zeitpunkt unbekannte Beispiele lernt.
Da schließlich unbekannte Beispiele diejenigen sind, die wahrscheinlich neues Faktenwissen einführen, deutet ihre deutlich langsame Anpassungsrate darauf hin, dass LLMs Schwierigkeiten haben, sich durch Feinabstimmung neues Faktenwissen anzueignen, sondern dass sie lernen, ihr bereits vorhandenes Wissen mithilfe der Verwendung offenzulegen die bekannten Beispiele.
Die Autoren versuchen zu quantifizieren, wie sich diese Genauigkeit auf bekannte und unbekannte Beispiele bezieht und ob sie linear ist. Die Ergebnisse zeigen, dass zwischen unbekannten Beispielen, die die Leistung beeinträchtigen, und bekannten Beispielen, die die Leistung verbessern, eine starke lineare Beziehung besteht, die fast ebenso stark ist (die Korrelationskoeffizienten in dieser linearen Regression liegen sehr nahe beieinander).
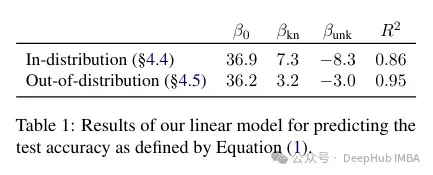
Diese Art der Feinabstimmung wirkt sich nicht nur auf die Leistung im Einzelfall aus, sondern hat auch weitreichende Auswirkungen auf das Modellwissen. Die Autoren verwenden einen Out-of-Distribution-Testsatz (OOD), um zu zeigen, dass unbekannte Proben die OOD-Leistung beeinträchtigen. Laut den Autoren hängt dies auch mit dem Auftreten von Halluzinationen zusammen:
Insgesamt übertragen sich unsere Erkenntnisse über Beziehungen hinweg. Dies zeigt im Wesentlichen, dass die Feinabstimmung auf unbekannte Beispiele wie „Wo befindet sich [E1]?“ zurückzuführen ist. kann Halluzinationen bei scheinbar nicht zusammenhängenden Fragen wie „Wer hat [E2] gegründet?“ fördern.
Ein weiteres interessantes Ergebnis ist, dass die besten Ergebnisse nicht mit bekannten, sondern mit potenziell bekannten Beispielen erzielt werden. Mit anderen Worten: Diese Beispiele ermöglichen es dem Modell, sein Vorwissen besser zu nutzen (zu bekannte Fakten haben keinen nützlichen Einfluss auf das Modell).
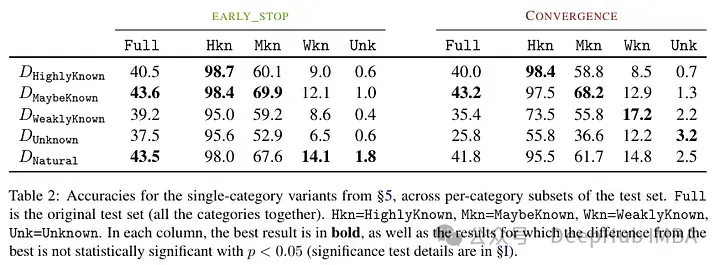
Im Gegensatz dazu beeinträchtigen unbekannte und weniger klare Fakten die Leistung des Modells, und dieser Rückgang ist auf eine Zunahme von Halluzinationen zurückzuführen.
Diese Arbeit verdeutlicht das Risiko der Verwendung überwachter Feinabstimmung zur Aktualisierung des Wissens von LLMs, da wir empirische Beweise dafür vorlegen, dass der Erwerb neuen Wissens durch Feinabstimmung mit Halluzinationen in Bezug auf bereits vorhandenes Wissen korreliert.
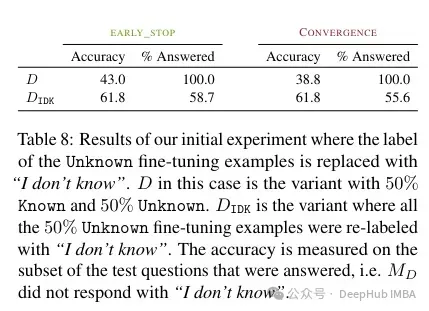
Laut dem Autor , kann dieses unbekannte Wissen die Leistung beeinträchtigen (was eine Feinabstimmung nahezu nutzlos macht). Und die Kennzeichnung dieses unbekannten Wissens mit „Ich weiß nicht“ kann dazu beitragen, diesen Schmerz zu lindern.
Der Erwerb neuen Wissens durch überwachte Feinabstimmung ist mit Halluzinationen verbunden, da LLMs Schwierigkeiten haben, neues Wissen durch Feinabstimmung zu integrieren, und meist lernen, ihr bereits vorhandenes Wissen zu nutzen.
Zusammenfassend gilt: Wenn bei der Feinabstimmung unbekanntes Wissen auftaucht, führt dies zu Schäden am Modell. Dieser Leistungsabfall war mit einer Zunahme von Halluzinationen verbunden. Im Gegensatz dazu kann es sein, dass bekannte Beispiele positive Auswirkungen haben. Dies deutet darauf hin, dass das Modell Schwierigkeiten hat, neues Wissen zu integrieren. Das heißt, es besteht ein Konflikt zwischen dem, was das Modell gelernt hat, und der Art und Weise, wie es das neue Wissen nutzt. Dies hängt möglicherweise mit der Ausrichtung und der Befehlsoptimierung zusammen (in diesem Artikel wurde dies jedoch nicht untersucht).
Wenn Sie also ein Modell mit spezifischem Domänenwissen verwenden möchten, empfiehlt das Papier, dass es am besten ist, RAG zu verwenden. Und mit „Ich weiß nicht“ gekennzeichnete Ergebnisse können andere Strategien finden, um die Einschränkungen dieser Feinabstimmungen zu überwinden.
Diese Studie ist sehr interessant, sie zeigt, dass die Faktoren der Feinabstimmung und wie der Konflikt zwischen altem und neuem Wissen gelöst werden kann, noch unklar sind. Deshalb testen wir die Ergebnisse vor und nach der Feinabstimmung.
Das obige ist der detaillierte Inhalt vonKann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Welche Arten von Systemarchitekturen gibt es?
Welche Arten von Systemarchitekturen gibt es?
 Der Unterschied zwischen verteilten und Microservices
Der Unterschied zwischen verteilten und Microservices
 Windows Boot Manager
Windows Boot Manager
 Was ist der Python-Bereich?
Was ist der Python-Bereich?
 Die Webseite kann nicht geöffnet werden
Die Webseite kann nicht geöffnet werden
 Der Unterschied zwischen Header-Dateien und Quelldateien
Der Unterschied zwischen Header-Dateien und Quelldateien

























