


Vorwort
In den letzten Jahren war die webbasierte Multi-Terminal-Anpassung verschiedener Websites in vollem Gange, und die Branche hat auch Lösungen entwickelt, die auf verschiedenen Technologien basieren. Zum Beispiel Responsive Design basierend auf der nativen CSS3 Media Query des Browsers, „Cloud Adaption“-Lösungen basierend auf Cloud Intelligent Reflow usw. In diesem Artikel werden hauptsächlich Multi-Terminal-Anpassungslösungen besprochen, die auf der Front-End- und Back-End-Trennung basieren.
Über Front-End- und Back-End-Trennung
Bezüglich der Lösung der Front-End- und Back-End-Trennung gibt es eine sehr klare Erklärung in „Denken und Praktizieren der Front-End- und Front-End-Trennung basierend auf NodeJS (1)“. Wir führen NodeJS als Rendering-Schicht zwischen der Serverschnittstelle und dem Browser ein. Da die NodeJS-Schicht vollständig von den Daten getrennt ist und sich nicht um viel Geschäftslogik kümmern muss, eignet sie sich sehr gut für Multi-Terminal-Anpassungsarbeiten Schicht.
UA-Erkennung
Das erste, was für die Multi-Terminal-Anpassung gelöst werden muss, ist das UA-Erkennungsproblem. Bei einer eingehenden Anfrage müssen wir den Typ des Geräts kennen, um den entsprechenden Inhalt dafür auszugeben. Es gibt bereits sehr ausgereifte User Agent-Signaturbibliotheken und Erkennungstools auf dem Markt, die mit einer großen Anzahl von Geräten kompatibel sind. Hier ist eine von Mozilla zusammengestellte Liste. Einige davon laufen auf der Browserseite und andere auf der serverseitigen Codeebene. Einige Tools stellen sogar Nginx/Apache-Module bereit, die für das Parsen der UA-Informationen jeder Anfrage verantwortlich sind.
Wir empfehlen eigentlich den letzten Weg. Die auf der Trennung von Front-End und Back-End basierende Lösung stellt fest, dass die UA-Erkennung nur auf der Serverseite ausgeführt werden kann, die Kopplung des Erkennungscodes und der Funktionsbibliothek im Geschäftscode jedoch keine benutzerfreundliche Lösung darstellt. Wir verschieben dieses Verhalten weiter und hängen es an Nginx/Apache. Sie sind dafür verantwortlich, die UA-Informationen jeder Anfrage zu analysieren und sie dann über Methoden wie den HTTP-Header an den Geschäftscode weiterzuleiten.
Dies hat mehrere Vorteile:
In unserem Code müssen wir nicht mehr darauf achten, wie UA analysiert wird, wir können die analysierten Informationen direkt aus der oberen Ebene abrufen. Wenn sich mehrere Anwendungen auf demselben Server befinden, können sie gemeinsam dieselben von Nginx analysierten UA-Informationen verwenden, wodurch der Analyseverlust zwischen verschiedenen Anwendungen vermieden wird.
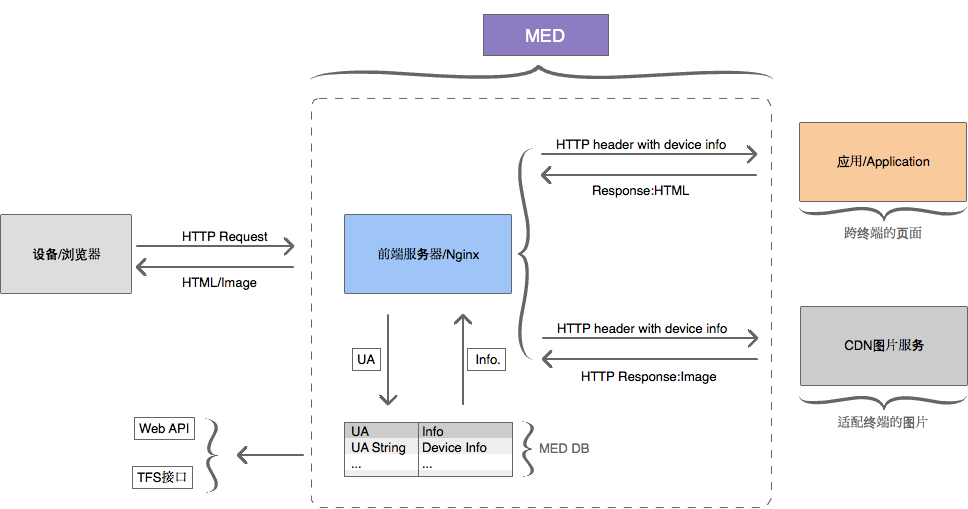
Nginx-basierte UA-Erkennungslösung, geteilt von Tmall
Der Tengine-Webserver von Taobao bietet auch ein ähnliches Modul ngx_http_user_agent_module.
Es ist erwähnenswert, dass Sie bei der Auswahl eines UA-Erkennungstools die Wartbarkeit der Signaturdatenbank berücksichtigen müssen, da immer mehr neue Gerätetypen auf dem Markt sind und jedes Gerät über einen unabhängigen Benutzeragenten verfügt Feature-Bibliotheken müssen gute Aktualisierungs- und Wartungsstrategien bereitstellen, um sich an sich ändernde Geräte anzupassen.
Mehrere Anpassungslösungen, die im MVC-Muster erstellt wurden
Nachdem wir die UA-Informationen erhalten haben, müssen wir überlegen, wie wir die Terminalanpassung gemäß der angegebenen UA durchführen. Selbst in der NodeJS-Schicht unterteilen wir das Innere immer noch in drei Modelle, obwohl der größte Teil der Geschäftslogik weg ist: Modell / Controller / Ansicht.
Anhand der obigen Abbildung analysieren wir zunächst einige vorhandene Multi-Terminal-Anpassungslösungen.
Anpassungslösung basierend auf Controller
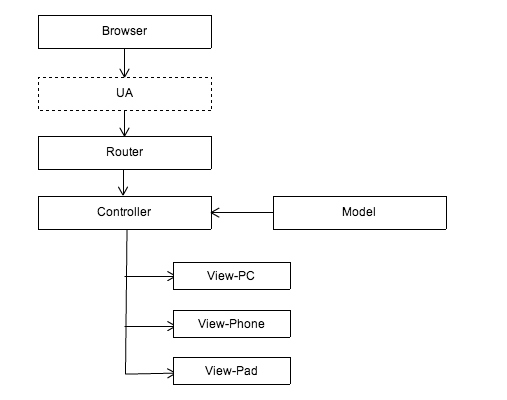
Diese Lösung sollte der einfachste und gröbste Weg sein, damit umzugehen. Übergeben Sie dieselbe URL über Routing (Router) an dieselbe Steuerungsschicht (Controller). Die Steuerungsschicht verwendet dann die UA-Informationen, um die Daten und die Modelllogik zum Rendern an die entsprechende Anzeige (Ansicht) zu senden. Die Rendering-Schicht stellt Vorlagen bereit, die gemäß der vorab vereinbarten Vereinbarung an mehrere Terminals angepasst sind.
Der Vorteil dieser Lösung besteht darin, dass die Einheit der Daten- und Steuerungsebenen erhalten bleibt und die Geschäftslogik nur einmal verarbeitet werden muss und auf alle Terminals angewendet werden kann. Dieses Szenario eignet sich jedoch nur für Anwendungen mit geringer Interaktion, z. B. Anzeigeseiten. Sobald das Geschäft komplexer ist, verfügt der Controller möglicherweise über eine eigene Verarbeitungslogik. Wenn ein Controller weiterhin gemeinsam genutzt wird, ist der Controller sehr aufgebläht schwierig aufrechtzuerhalten. Zweifellos eine falsche Wahl.
Auf dem Router basierende Anpassungslösung
Um die oben genannten Probleme zu lösen, können wir die Geräte auf dem Router unterscheiden und sie auf verschiedene Controller für verschiedene Terminals verteilen:
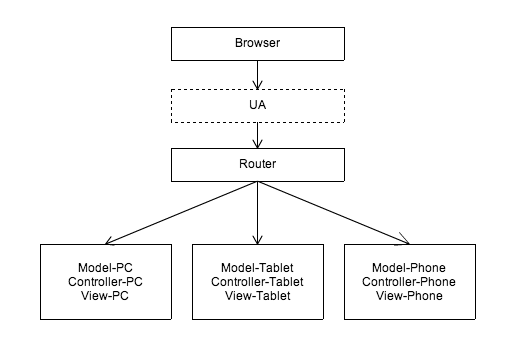
Dies ist auch eine der häufigsten Lösungen, die sich meist in der Verwendung separater Anwendungssätze für verschiedene Terminals äußert. Zum Beispiel die PC-Taobao-Homepage und die WAP-Version der Taobao-Homepage. Wenn verschiedene Geräte auf www.taobao.com zugreifen, wird der Server durch die Steuerung des Routers zur WAP-Version der Taobao-Homepage oder zur PC-Version der Taobao-Homepage umgeleitet. Es handelt sich um zwei völlig unabhängige Anwendungssätze.
Diese Lösung bringt jedoch zweifellos das Problem mit sich, dass Daten und Teile der Logik nicht gemeinsam genutzt werden können. Verschiedene Terminals können nicht dieselben Daten und Geschäftslogiken gemeinsam nutzen, was zu viel repetitiver Arbeit und geringer Effizienz führt.
Um dieses Problem zu lindern, hat jemand eine optimierte Lösung vorgeschlagen: Immer noch in derselben Reihe von Anwendungen wird jede Datenquelle in jedes Modell abstrahiert, das den Controllern verschiedener Terminals zur kombinierten Verwendung bereitgestellt wird:
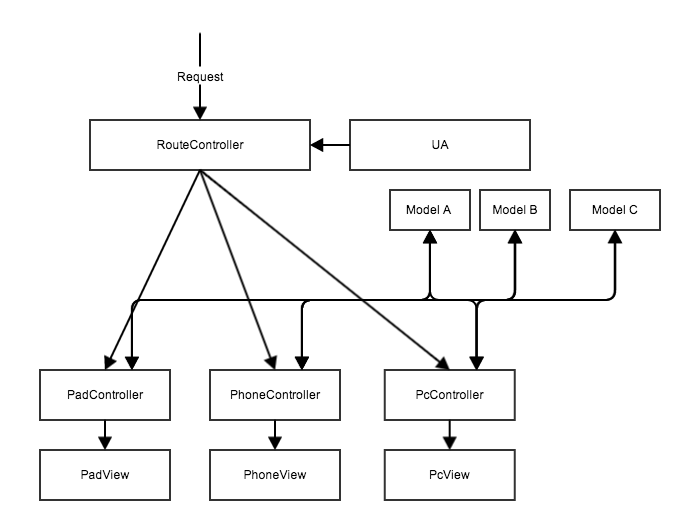
Diese Lösung löst das bisherige Problem, dass Daten nicht weitergegeben werden konnten. Jedes Terminal auf dem Controller ist immer noch unabhängig voneinander, aber sie können gemeinsam denselben Stapel von Datenquellen verwenden. Zumindest in Bezug auf Daten besteht keine Notwendigkeit, unabhängige Schnittstellen für Terminaltypen zu entwickeln.
Bei den beiden oben genannten Router-basierten Lösungen kann jedes Terminal aufgrund der Unabhängigkeit des Controllers eine unterschiedliche Interaktionslogik für seine eigene Seite implementieren, wodurch eine ausreichende Flexibilität jedes Terminals selbst gewährleistet wird. Aus diesem Grund übernehmen die meisten Anwendungen diese Lösung Grund.
Anpassungsschema basierend auf der Ansichtsebene
Dies ist die von der Bestellseite von Taobao verwendete Lösung. Der Unterschied besteht jedoch darin, dass die Bestellseite die gesamte Rendering-Ebene auf der Browserseite anstelle der NodeJS-Ebene platziert. Unabhängig davon, ob es sich um einen Browser oder NodeJS handelt, ist die allgemeine Designidee immer noch dieselbe:
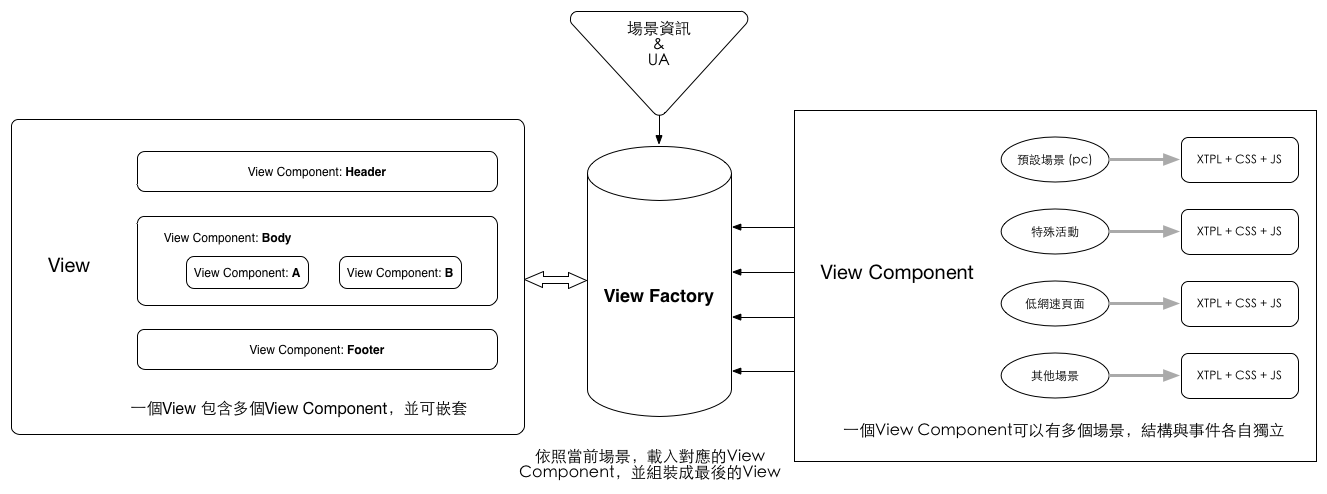
Bei dieser Lösung müssen Router, Controller und Modell nicht auf Geräteinformationen achten und die Beurteilung des Terminaltyps wird vollständig der Präsentationsschicht überlassen. Das Hauptmodul in der Abbildung ist „View Factory“. Nachdem das Modell und der Controller die Daten- und Rendering-Logik übergeben haben, verwendet die View Factory die Geräteinformationen und andere Statusinformationen (nicht nur UA-Informationen, sondern auch die Netzwerkumgebung, den Benutzerbereich usw.). .) Holen Sie sich bestimmte Komponenten aus einer Reihe voreingestellter Komponenten (Komponenten anzeigen) und kombinieren Sie sie auf der endgültigen Seite.
Diese Lösung hat mehrere Vorteile:
Die obere Ebene muss nicht auf Geräteinformationen (UA) achten, sondern wird weiterhin von der Ansichtsebene verarbeitet, die nicht nur die größte Beziehung zur endgültigen Anzeige hat Laut UA-Informationen kann jede Ansichtskomponente auch auf dem Benutzerstatus basieren. Entscheiden Sie selbst, welche Vorlage ausgegeben werden soll, z. B. das standardmäßige Ausblenden von Bildern bei niedrigen Netzwerkgeschwindigkeiten und das Ausgeben von Ereignisbannern in bestimmten Bereichen. Verschiedene Vorlagen jeder Ansichtskomponente können entscheiden, ob dieselben Daten und dieselbe Geschäftslogik verwendet werden sollen, was eine sehr flexible Implementierungsmethode bietet.
Aber offensichtlich ist diese Lösung auch die komplexeste, insbesondere wenn man einige Anwendungsszenarien mit umfangreicher Interaktion berücksichtigt, bei denen Router und Controller möglicherweise nicht so rein bleiben können. Insbesondere für einige relativ integrierte Unternehmen, die nicht in Komponenten aufgeteilt werden können, ist diese Lösung möglicherweise nicht anwendbar, und für einige einfache Unternehmen ist die Verwendung dieser Architektur möglicherweise nicht die beste Wahl.
Zusammenfassung
Die oben genannten Lösungen spiegeln sich jeweils in einem oder mehreren Teilen des MVC-Modells wider. Wenn eine Lösung den Anforderungen nicht entspricht, können mehrere Lösungen gleichzeitig übernommen werden. Oder es kann verstanden werden, dass die Geschäftskomplexität und die Interaktionsattribute bestimmen, welche Multi-Terminal-Anpassungslösung für das Produkt besser geeignet ist.
Da der Großteil der Terminalerkennungs- und Rendering-Logik auf den Server migriert wurde, wird die Anpassung auf der NodeJS-Ebene im Vergleich zu browserbasierten Responsive-Design-Lösungen zweifellos zu einer besseren Leistung und Benutzererfahrung führen Probleme, die durch einige sogenannte „Cloud-Anpassungslösungen“ verursacht werden, treten bei „kundenspezifischen“ Lösungen, die auf der Front-End- und Back-End-Trennung basieren, nicht auf. Die Front-End- und Back-End-Trennungsanpassungslösung bietet in diesen Aspekten natürliche Vorteile.
Um sich schließlich an flexiblere und leistungsfähigere Anpassungsanforderungen anzupassen, stehen Anpassungslösungen, die auf der Front-End- und Back-End-Trennung basieren, vor größeren Herausforderungen!
 Was ist NodeJS?
Was ist NodeJS?
 Nodejs implementiert Crawler
Nodejs implementiert Crawler
 Welche Office-Software gibt es?
Welche Office-Software gibt es?
 Wie man mit Blockchain Geld verdient
Wie man mit Blockchain Geld verdient
 Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
 So öffnen Sie eine RAR-Datei
So öffnen Sie eine RAR-Datei
 Ein Speicher, der Informationen direkt mit der CPU austauschen kann, ist ein
Ein Speicher, der Informationen direkt mit der CPU austauschen kann, ist ein
 So deaktivieren Sie die ICS-Netzwerkfreigabe
So deaktivieren Sie die ICS-Netzwerkfreigabe








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



