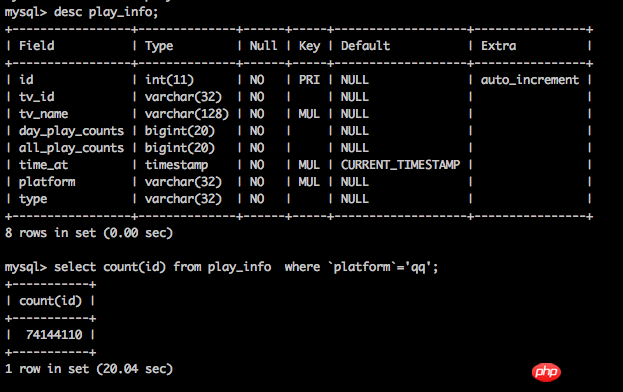
表结构如图所示。
目前数据量是8000W行。
请问有什么优化的方法和思路吗?
count(*)不会统计每一列的值(不管是否为null),而是直接统计行数,效率要高些;
另外也可以用排除法,比如platform是qq的数据很多,可以用总的数据减掉platform=other的数据;
从业务上来考虑,精确值获取成本很高,然而近似值成本较低,如果要求不严格,可以用近似值代替;
另外也可以考虑用redis等“内存数据库”来维护这种获取耗时的数据;
1.如果当我遇到这样的问题的话,我的解决办法是新建一个表,例如playfrom_count来统计. 框架中如果用after_insert以及after_delete这样的方法更好,如果没有的话就自己写一个.2.如果这样的查询业务量不是很大的话,或者不是很精确的话,可以做一个任务去跑.每隔一段时间更新一次.3.无论你是innodb还是myisam,因为你添加了where所以都会对全表进行扫描.所以可以通过添加主键来增加检索速度.
方案1. 对platform建立分区表方案2. 按platform分表方案3. 对platform建单独索引,不过考虑你platform的值集应该不会很大,这样做索引不合适
这个问题在经典的关系型数据库都会遇到,通用的解决方法是去访问系统表,里面有每一个表的数据行数,速度比你 COUNT(*) 快无数倍。
升级下机器吧,怎么简单的count都要20s,虽然有很多办法比如分区表,但是感觉投入得不偿失.
建议先考虑一下业务场景的需求,单纯从技术方面考虑的解决方案成本过高,很多时候基本上实施不了。可能的解决方案有:1、分表:按照platform分为多个表,存储引擎为MyISAM,查询语句改为count(*),MyISAM会保存表的总行数,因此查询效率很有极大的提升。需要考虑分表对系统改造的工作量、MyISAM不支持事务是否能满足系统要求。
2、建立冗余表或字段,把需要汇总的数据在变更时重新计算,需要考虑大量的更新操作是否加大系统的负载。
3、如果对查询结果不要求时完全精确的,可以定时计算结果并保存起来,查询的时候不在直接查询原表。
这种情况下可以按照月或者季度等分为多个统计表,比如你800万数据,新建一张表,每一行代表一个月的总记录。这样再统计就会快得多得多。





















count(*)不会统计每一列的值(不管是否为null),而是直接统计行数,效率要高些;
另外也可以用排除法,比如platform是qq的数据很多,可以用总的数据减掉platform=other的数据;
从业务上来考虑,精确值获取成本很高,然而近似值成本较低,如果要求不严格,可以用近似值代替;
另外也可以考虑用redis等“内存数据库”来维护这种获取耗时的数据;
1.如果当我遇到这样的问题的话,我的解决办法是新建一个表,例如playfrom_count来统计.
框架中如果用after_insert以及after_delete这样的方法更好,如果没有的话就自己写一个.
2.如果这样的查询业务量不是很大的话,或者不是很精确的话,可以做一个任务去跑.每隔一段时间更新一次.
3.无论你是innodb还是myisam,因为你添加了where所以都会对全表进行扫描.所以可以通过添加主键来增加检索速度.
方案1. 对platform建立分区表
方案2. 按platform分表
方案3. 对platform建单独索引,不过考虑你platform的值集应该不会很大,这样做索引不合适
这个问题在经典的关系型数据库都会遇到,通用的解决方法是去访问系统表,里面有每一个表的数据行数,速度比你 COUNT(*) 快无数倍。
升级下机器吧,怎么简单的count都要20s,虽然有很多办法比如分区表,但是感觉投入得不偿失.
建议先考虑一下业务场景的需求,单纯从技术方面考虑的解决方案成本过高,很多时候基本上实施不了。
可能的解决方案有:
1、分表:按照platform分为多个表,存储引擎为MyISAM,查询语句改为count(*),MyISAM会保存表的总行数,因此查询效率很有极大的提升。需要考虑分表对系统改造的工作量、MyISAM不支持事务是否能满足系统要求。
2、建立冗余表或字段,把需要汇总的数据在变更时重新计算,需要考虑大量的更新操作是否加大系统的负载。
3、如果对查询结果不要求时完全精确的,可以定时计算结果并保存起来,查询的时候不在直接查询原表。
这种情况下可以按照月或者季度等分为多个统计表,比如你800万数据,新建一张表,每一行代表一个月的总记录。这样再统计就会快得多得多。