

MySQL是项目中常用的数据库,其中in查询也是很常用。最近项目调试过程中,遇到一个出乎意料的select查询,竟然用了33秒!
1. userinfo 表

2. article 表
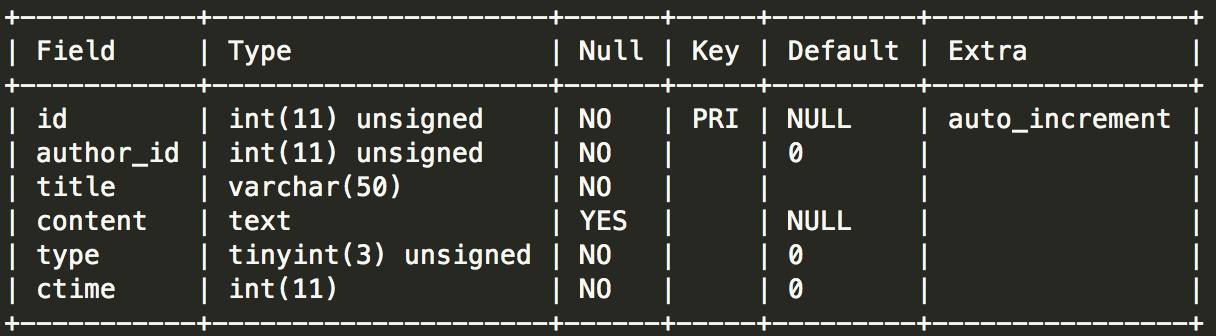
select*fromuserinfowhereidin(selectauthor_idfromartilcewheretype=1);
大家第一眼看到上面的SQL时,可能都会觉得这是一个很简单的子查询。先把author_id查出来,再用in查询一下。
如果有相关索引会非常快的,拆解来讲就是以下这样的:
1.selectauthor_idfromartilcewheretype=1; 2.select*fromuserinfowhereidin(1,2,3);
但是事实是这样的:
mysql> select count(*) from userinfo;
mysql> select count(*) from article;

mysql> select id,username from userinfo where id in (select author_id from article where type = 1);

33 秒!为什么会这么慢呢?
官方文档解释:in 子句在查询的时候有时会被转换为 exists 的方式来执行,变成逐条记录进行遍历(版本 5.5 中存在,5.6 中已做优化)。

参考:
https://dev.mysql.com/doc/refman/5.5/en/subquery-optimization.html
1. 使用临时表
select id,username from userinfo where id in (select author_id from (select author_id from article where type = 1) as tb);
2. 使用 join
select a.id,a.username from userinfo a, article b where a.id = b.author_id and b.type = 1;
版本 5.6 已针对子查询做了优化,方式跟【四】中的临时表方式一样,参考官方文档:
If materialization is not used, the optimizer sometimes rewrites a noncorrelated subquery as a correlated subquery.
For example, the following IN subquery is noncorrelated ( where_condition involves only columns from t2 and not t1 ):
select * from t1
where t1.a in (select t2.b from t2 where where_condition);
The optimizer might rewrite this as an EXISTS correlated subquery:
select * from t1
where exists (select t2.b from t2 where where_condition and t1.a=t2.b);
Subquery materialization using a temporary table avoids such rewrites and makes it possible to execute the subquery only once rather than once per row of the outer query.
https://dev.mysql.com/doc/refman/5.6/en/subquery-materialization.html
文章来自微信公众号:HULK一线技术杂谈
以上是记踩到 MySQL in 子查询的'坑”的详细内容。更多信息请关注PHP中文网其他相关文章!





















