

最近,大型语言模型(LLM)以及它们的高级提示策略的出现,意味着语言模型的研究取得了重大进展,尤其是在经典的自然语言处理(NLP)任务中。其中一个重要的创新是思维链(CoT)提示技术,这种技术因其在多步骤问题解决中的能力而受到赞誉。CoT技术遵循了人类的顺序推理方式,在各种挑战中展现出了卓越的性能,包括跨领域、长期泛化和跨语言任务。CoT以其富有逻辑的、逐步推理的方法,在复杂问题解决场景中提供了至关重要的可解释性。
尽管 CoT 已取得长足进展,但研究界对于其具体机制和有效原因尚未达成共识。这种知识差距意味着提高 CoT 性能仍是一片未知的领域。目前,试错法是探索 CoT 改进的主要途径,因为缺乏系统性方法论,研究人员只能依赖猜测和实验。然而,这也意味着该领域存在着重要的研究机遇:深入、结构化地理解 CoT 的内部运作。实现这一目标不仅能揭开当前 CoT 过程的神秘面纱,还能为各种复杂的 NLP 任务中更可靠、高效地应用这种技术铺平道路。
来自美国西北大学、利物浦大学和新泽西理工大学等研究者的研究进一步探讨了推理步骤的长度与结论准确性之间的关系,以帮助人们更好地理解如何有效解决自然语言处理(NLP)问题。该研究探索了推理步骤是否是促使连续开放式文本(CoT)发挥作用的提示中最关键的部分。 在实验中,研究者严格控制了变量,特别是在引入新的推理步骤时,确保不引入额外的知识。在零样本实验中,研究者将初始提示从“请逐步思考”调整为“请逐步思考,并尽可能思考出更多的步骤”。对于小样本问题,研究者设计了一个实验,在保持其他所有因素不变的情况下,扩展了基础推理步骤。 通过这些实验,研究者发现推理步骤的长度与结论准确性之间存在一定的关联。更具体地说,当提示中要求思考更多步骤时,参与者往往能够提供更准确的结论。这表明在解决NLP问题时,通过扩展推理步骤可以提高问题解决的准确性。 这项研究对于深入理解NLP问题的解决方式具有重要意义,为进一步优化和改进NLP技术提供了有益的指导。

本文的第一组实验旨在评估在上述策略下使用Auto-CoT技术对零样本和小样本任务推理性能的提高情况。接着,对不同方法在不同推理步数下的准确性进行了评估。随后,研究者扩大了调研对象,比较了本文提出的策略在不同LLM(如GPT-3.5和GPT-4)上的有效性。研究结果显示,在一定范围内,推理链的长度与LLM的能力之间存在明显的相关性。值得思考的是,当研究者在推理链中引入误导信息时,性能仍然得到提高。这提示我们一个重要结论:影响性能的关键因素似乎是思维链的长度,而不是其准确性。
本文的主要发现如下所示:
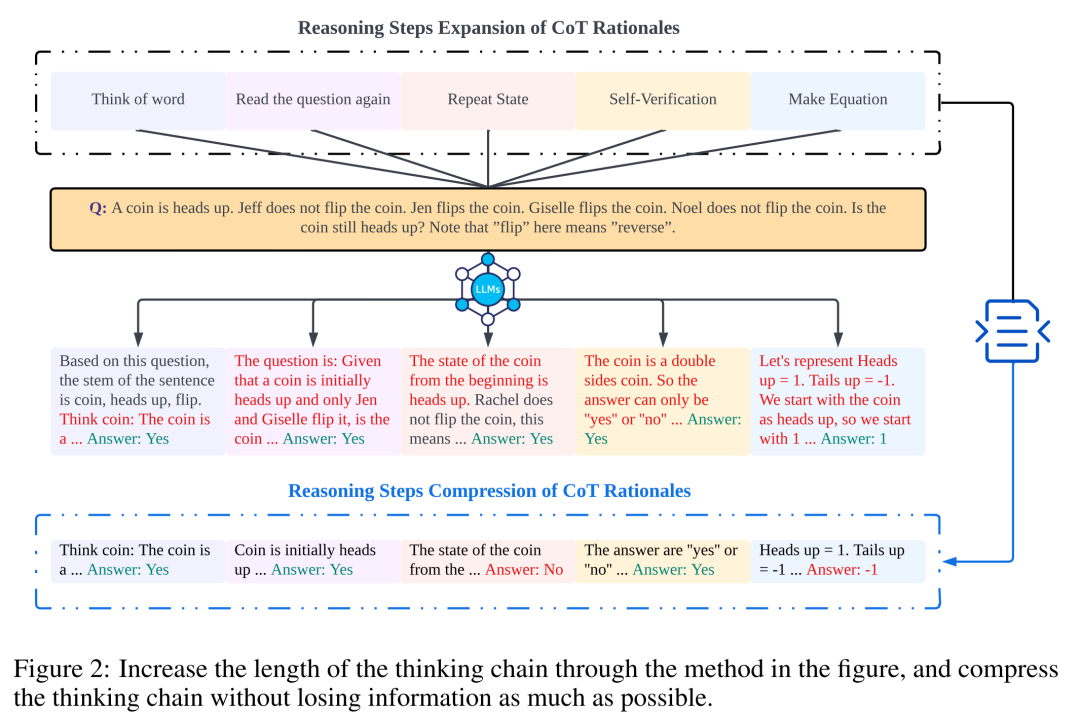
研究者通过分析来检验推理步骤与 CoT 提示性能之间的关系。他们的方法的核心假设是,在推理过程中,序列化步骤是 CoT 提示中最关键的组成部分。这些步骤能够使语言模型在生成回复内容时应用更多的逻辑进行推理。为了测试这一观点,研究者设计了一个实验,通过先后扩展和压缩基础推理步骤,来改变 CoT 的推理过程。同时,他们保持了所有其他因素不变。具体而言,研究者只系统地改变推理步骤的数量,而没有引入新的推理内容或删除已有的推理内容。他们在下文中评估了零样本和少样本的 CoT 提示。整个实验过程如图 2 所示。通过这种控制变量分析的方法,研究者阐明了 CoT 如何影响 LLM 生成逻辑健全的应答能力。
零样本CoT 分析
在零样本场景中,研究者将最初的prompt 从「请逐步思考」修改为「请逐步思考,并且尽可能思考出更多的步骤」。之所以做出这一改变,是因为与少样本 CoT 环境不同,使用者不能在使用过程中引入额外的推理步骤。通过改变初始 prompt,研究者引导 LLM 进行了更广泛的思考。这种方法的重要性在于能够提高模型的准确性,而且不需要少样本场景中的典型方案:增量训练或额外的示例驱动优化方法。这种精细化策略确保了更全面、更详细的推理过程,显着提高了模型在零样本条件下的性能。
小样本 CoT 分析
本节将通过增加或压缩推理步骤来修改 CoT 中的推理链。其目的是研究推理结构的变化如何影响 LLM 决策。在推理步骤的扩展过程中,研究者需要避免引入任何新的任务相关信息。这样,推理步骤就成了唯一的研究变量。
为此,研究者设计了以下研究策略,以扩展不同 LLM 应用程序的推理步骤。人们思考问题的方式通常有固定的模式,例如,一遍又一遍地重复问题以获得更深入的理解、创建数学方程以减轻记忆负担、分析问题中单词的含义以帮助理解主题、总结当前状态以简化对主题的描述。基于零样本 CoT 和 Auto-CoT 的启发,研究者期望 CoT 的过程成为一种标准化的模式,并通过在 prompt 部分限制 CoT 思维的方向来获得正确的结果。本文方法的核心是模拟人类思维的过程,重塑思维链。表 6 中给出了五种通用的 prompt 策略。

总体而言,本文的即时策略都在模型有所体现。表 1 展示的内容是其中一个例子,其他四种策略的示例可以在原论文中查看。

推理步骤与准确性的关系
表 2 比较了使用 GPT-3.5-turbo-1106 在三类推理任务的八个数据集上的准确性。
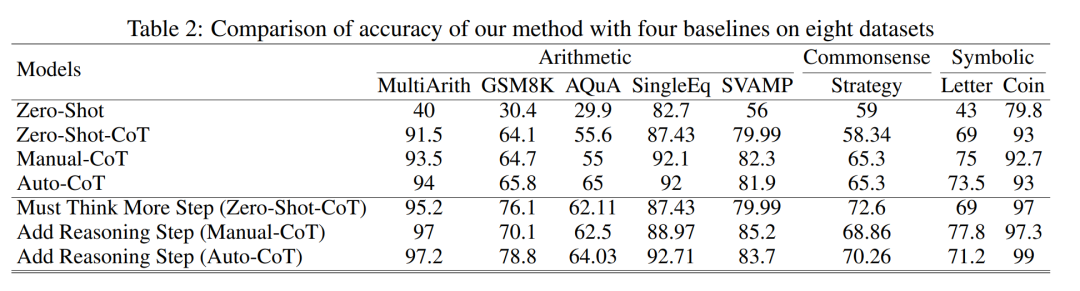
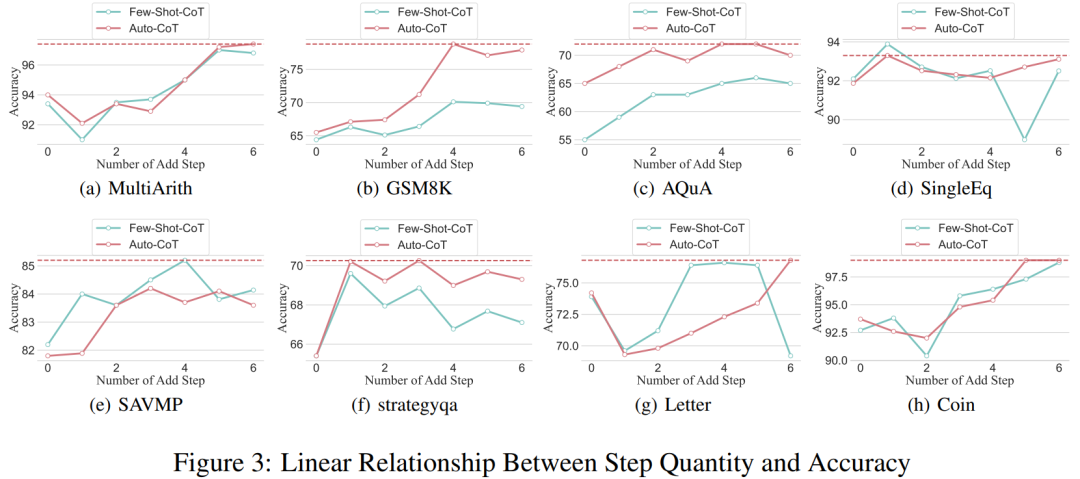
得益于研究者能够将思维链过程标准化,接下来就可以量化在 CoT 的基本流程中增加步骤而对准确性的提高程度。本实验的结果可以回答之前提出的问题:推理步骤与 CoT 性能之间的关系是什么?该实验基于 GPT-3.5-turbo-1106 模型。研究者发现,有效的 CoT 过程,例如在 CoT 过程中增加多达六个步骤的额外思维过程,会让大型语言模型推理能力都会得到提高,并且是在所有的数据集上都有体现。换句话说,研究者发现准确性和 CoT 复杂性之间存在一定的线性关系。
错误答案的影响
推理步骤是影响 LLM 性能的唯一因素吗?研究者做了以下尝试。将 prompt 中的一个步骤更改为不正确的描述,看看它是否会影响思维链。对于这个实验,本文研究者在所有 prompt 中添加一个错误。有关具体示例,请看表 3。

对于算术类型的问题,即使其中一个 prompt 结果出现偏差,对推理过程中思维链的影响也是微乎其微的,因此研究者认为在解决算术类型的问题时,大语言模型对提示中思维模式链的学习要多于单一计算。对于类似硬币数据的逻辑问题,prompt 结果中的一个偏差往往会带来整个思维链的支离破碎。研究者同样使用 GPT-3.5-turbo-1106 完成这项实验,并根据之前实验得出的每个数据集的最佳步数保证了性能。结果如图 4 所示。
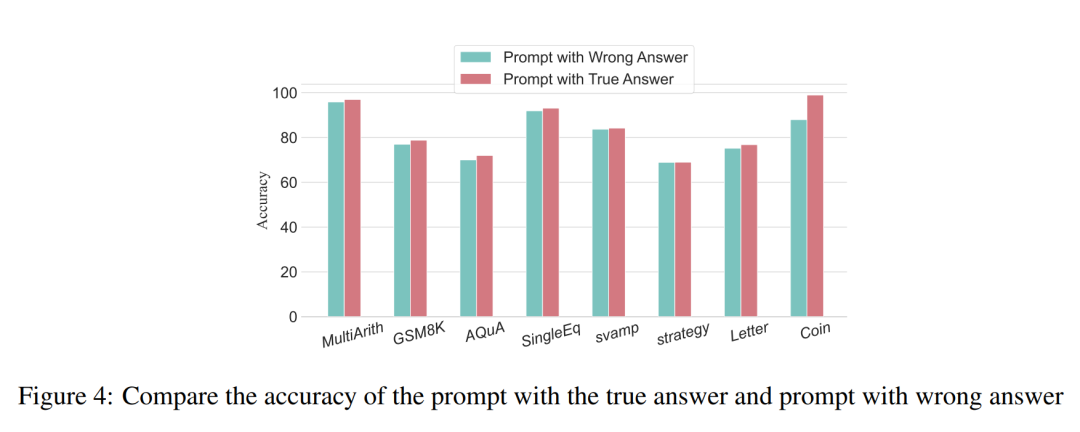
压缩推理步骤
先前的实验已经证明了增加推理步骤可以提高 LLM 推理的准确性。那么在小样本问题中压缩基础推理步骤会损害 LLM 的性能吗?为此,研究者进行了推理步骤压缩实验,并采用实验设置中概述的技术,将推理过程浓缩成 Auto CoT 和 Few-Shot-CoT,减少推理步骤数。结果如图 5 所示。
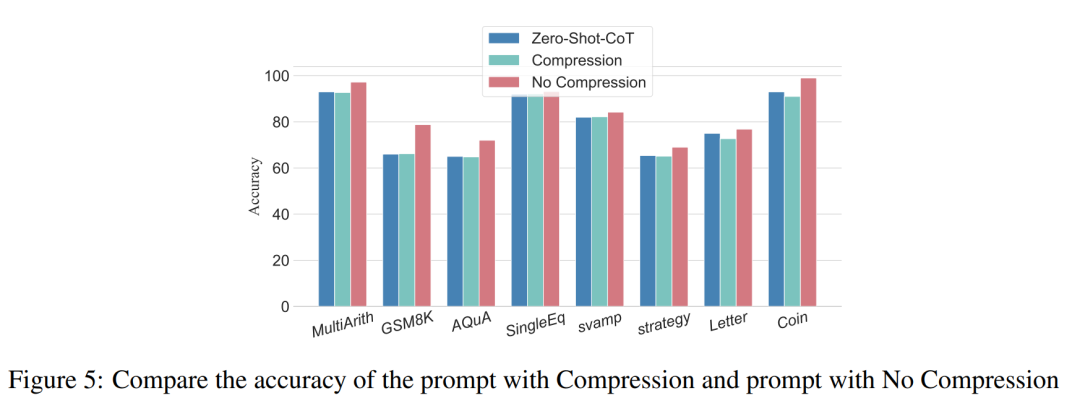
结果显示,模型的性能显着下降,回归到与零样本方法基本相当的水平。这个结果进一步表明,增加 CoT 推理步骤可以提高 CoT 性能,反之亦然。
不同规格模型的性能对比
研究者还提出疑问,我们能否观察到缩放现象,即所需的推理步骤与 LLM 的大小有关?研究者研究了各种模型(包括 text-davinci-002、GPT-3.5-turbo-1106 和 GPT-4)中使用的平均推理步骤数。通过在 GSM8K 上的实验计算出了每个模型达到峰值性能所需的平均推理步骤。在 8 个数据集中,该数据集与 text-davinci-002、GPT-3.5-turbo-1106 和 GPT-4 的性能差异最大。可以看出,在初始性能最差的 text-davinci-002 模型中,本文提出的策略具有最高的提升效果。结果如图 6 所示。
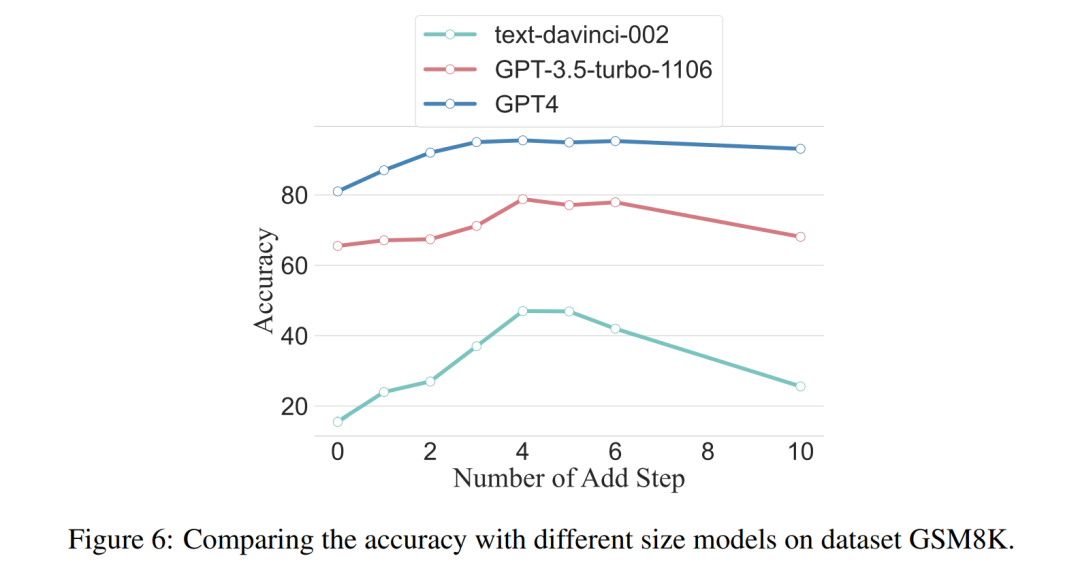
协同工作实例中问题的影响
问题对 LLM 推理能力的影响是什么?研究者想探讨改变 CoT 的推理是否会影响 CoT 的性能。由于本文主要研究推理步骤对性能的影响,所以研究者需要确认问题本身对性能没有影响。因此,研究者选择了数据集 MultiArith 和 GSM8K 和两种 CoT 方法(auto-CoT 和 few-shot-CoT)在 GPT-3.5-turbo-1106 中进行实验。本文的实验方法包括对这些数学数据集中的样本问题进行有意的修改,例如改变表 4 中问题的内容。

值得注意的是,初步观察表明,这些对于问题本身的修改对性能的影响是几个要素里最小的,如表 5 所示。
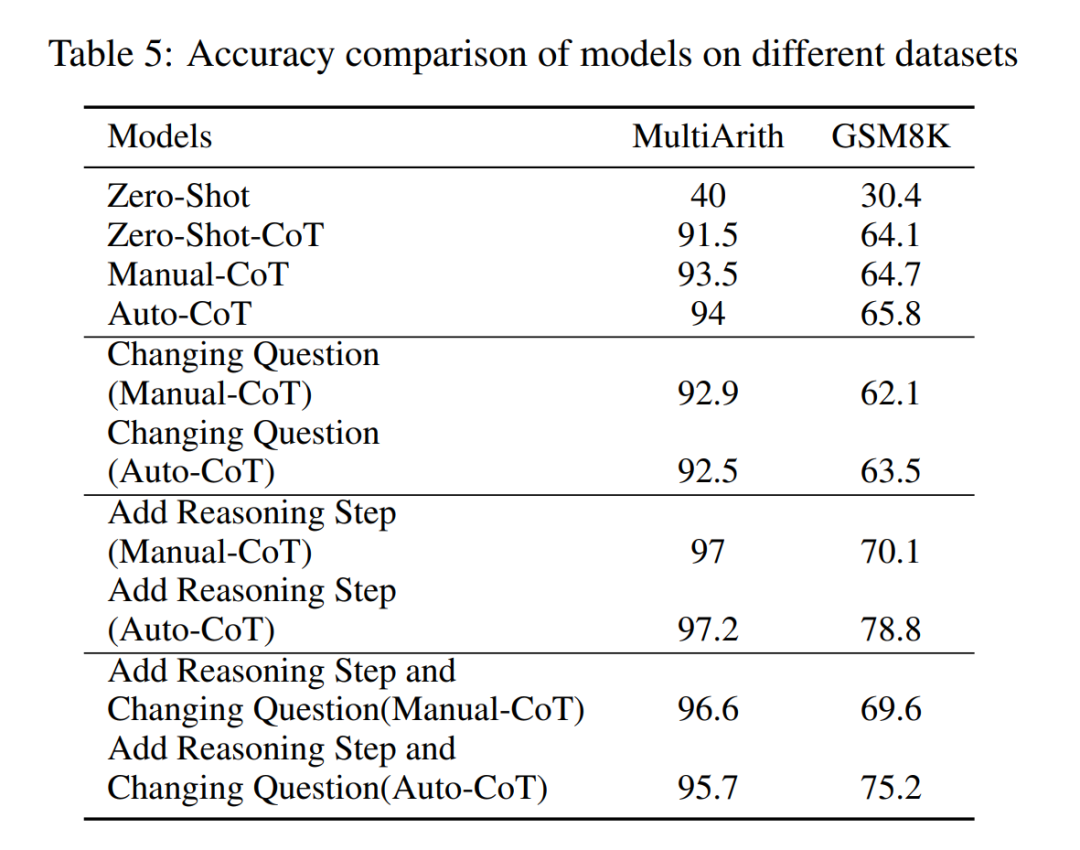
这一初步发现表明,推理过程中步骤的长度是大模型的推理能力最主要的影响因素,问题本身的影响并不是最大的。
更多详细内容,请阅读原论文。
以上是更有用的模型需要更深入地「逐步思考」,而不仅仅是「逐步思考」不够的详细内容。更多信息请关注PHP中文网其他相关文章!





















