

这是关于如何使用强化学习训练AI玩贪吃蛇游戏的简单指南。文章逐步展示了如何设置自定义游戏环境并使用python标准化Stable-Baselines3算法库训练AI玩贪吃蛇。
在本项目中,我们使用的是Stable-Baselines3,这是一个标准化的库,它提供了易于使用的基于PyTorch的强化学习(RL)算法实现。
首先,设置环境。Stable-Baselines库内有很多内置的游戏环境,这里我们使用经典贪吃蛇的修改版本,并在中间额外设置十字交叉的墙。
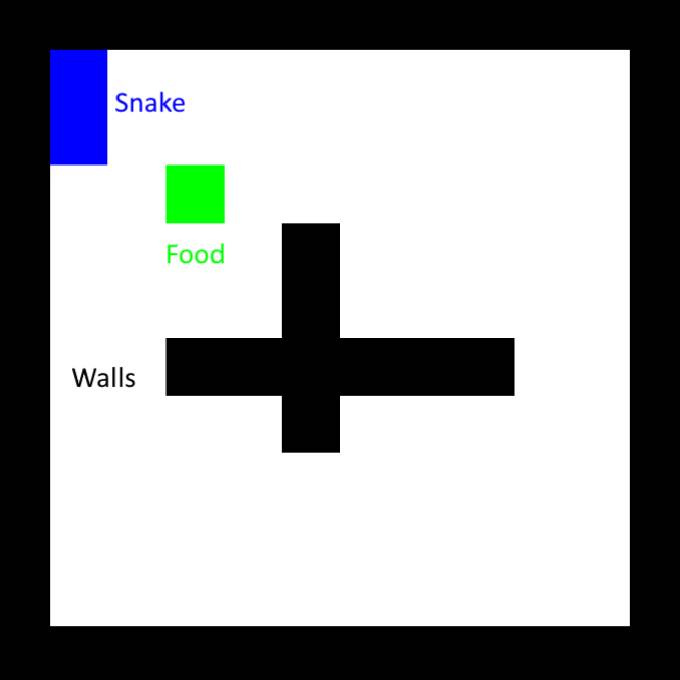
一个更好的奖励计划是只奖励更接近食物的步骤。在这里必须小心,因为贪吃蛇仍然只能学会绕圈走动,在接近食物时获得奖励,然后转身又回来。为了避免这种情况,我们还必须对远离食物给予等效的惩罚,换句话说,我们需要确保闭环上的净奖励为零。我们还需要引入对撞墙的惩罚,因为在某些情况下,贪吃蛇会选择撞墙来接近食物。
大多数机器学习算法都相当复杂且难以实现。幸运的是,Stable-Baselines3已经实现了几种我们可以使用的最先进的算法。在示例中,我们将使用Proximal Policy Optimization(PPO)。虽然我们不需要知道算法如何工作的细节(如果有兴趣,请看这个解释视频),但我们需要对它的超参数是什么以及它们的作用有一个基本的了解。幸运的是,PPO只有其中一些,我们将使用以下内容:
learning_rate:设置策略更新的步骤有多大,与其他机器学习方案相同。将其设置得太高会阻止算法找到正确的解决方案,甚至将算法推向一个永远无法恢复的方向。将其设置得太低会使训练花费更长的时间。一个常见的技巧是在训练期间使用调度器函数来调整它。
gamma:未来奖励的折扣系数,介于0(仅即时奖励重要)和1(未来奖励与即时奖励价值相同)之间。为了保持训练效果,最好将其保持在0.9以上。
clip_range1+-clip_range:PPO的一个重要特性,它的存在是为了确保模型不会在训练时发生显着改变。减少它有助于在后期训练阶段微调模型。
ent_coef:从本质上讲,它的值越高,就越鼓励算法探索不同的非最优动作,这可以帮助该方案摆脱局部奖励最大值。
一般来说,从默认的超参数开始即可。
接下来的步骤是针对一些预先确定的步骤进行训练,然后亲自查看算法的运行情况,然后使用性能最佳的可能的新参数重新开始。在这里,我们绘制了不同训练时间的奖励。
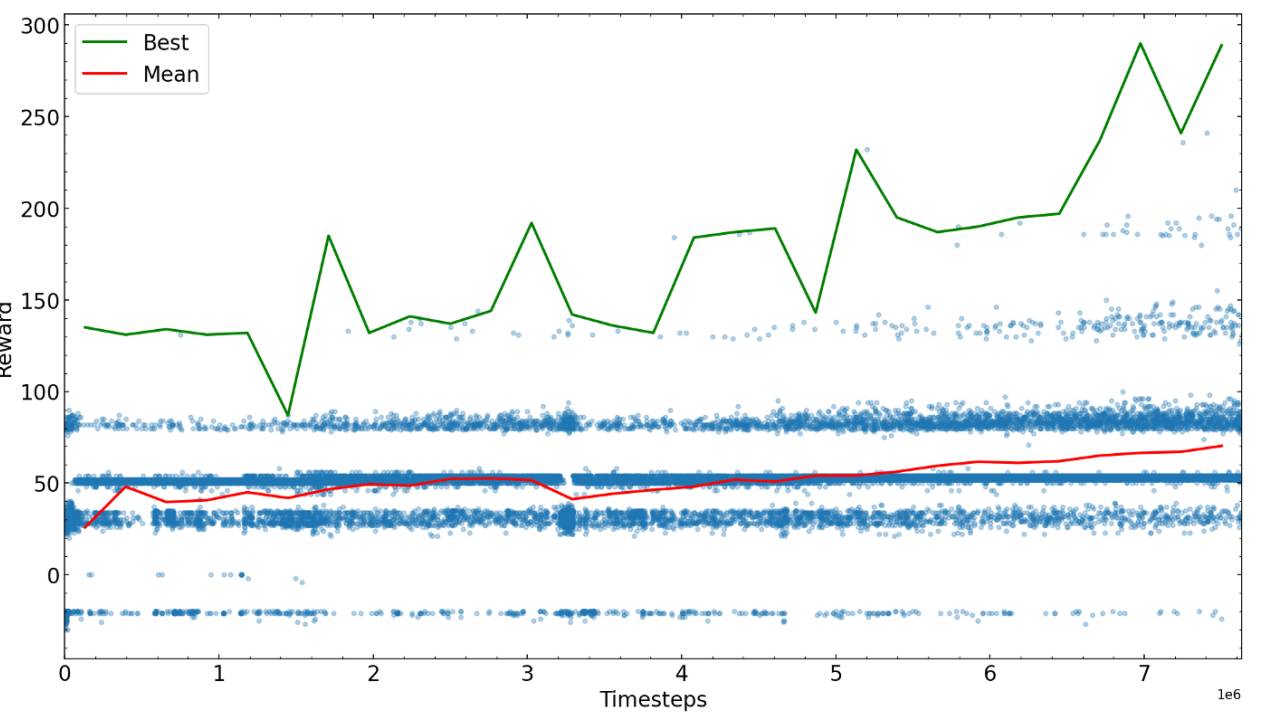
经过足够多的步骤后,训练贪吃蛇的算法收敛到某个奖励值,就可以完成训练或尝试微调参数并继续训练。
达到最大可能奖励所需的训练步骤很大程度上取决于问题、奖励方案和超参数,因此建议在训练算法前先优化一下。在训练AI玩贪吃蛇游戏示例的最后,我们发现AI已经能做到在迷宫中找到食物并避免与尾巴相撞了。
以上是用Python训练AI玩贪吃蛇游戏的方法的详细内容。更多信息请关注PHP中文网其他相关文章!





















