

在推动基于视觉的感知方法落地时,提高模型的泛化能力是一个重要的基础。测试段训练和适应(Test-Time Training/Adaptation)是通过在测试阶段调整模型参数权重,使模型能够适应未知的目标域数据分布。现有的TTT/TTA方法通常侧重于提高在封闭环境中的目标域数据下的测试段训练性能
然而,在许多应用场景中,目标领域很容易受到强域外数据(Strong OOD)的污染,例如与语义无关的数据类别。在这种情况下,也被称为开放世界测试段训练(OWTTT),现有的TTT/TTA通常会将强域外数据强行分类为已知类别,最终干扰对弱域外数据(Weak OOD)如受到噪声干扰的图像的识别能力
最近,华南理工大学和A*STAR团队首次提出了开放世界测试段训练的设定,并且推出了相应的训练方法

论文:https://arxiv.org/abs/2308.09942
需要重写的内容是:代码链接:https://github.com/Yushu-Li/OWTTT
本文首先提出了一种自适应阈值的强域外数据样本过滤方法,提高了自训练 TTT 方法的在开放世界的鲁棒性。该方法进一步提出了一种基于动态扩展原型来表征强域外样本的方法,以改进弱 / 强域外数据分离效果。最后,通过分布对齐来约束自训练。
本文的方法在 5 个不同的 OWTTT 基准上实现了最优的性能表现,并为 TTT 的后续研究探索面向更加鲁棒 TTT 方法的提供了新方向。研究已作为 Oral 论文被 ICCV 2023 接收。
引言
测试段训练(TTT)可以仅在推理阶段访问目标域数据,并对分布偏移的测试数据进行即时推理。TTT 的成功已经在许多人工选择的合成损坏目标域数据上得到证明。然而,现有的 TTT 方法的能力边界尚未得到充分探索。
为促进开放场景下的 TTT 应用,研究的重点已转移到调查 TTT 方法可能失败的场景。人们在更现实的开放世界环境下开发稳定和强大的 TTT 方法已经做出了许多努力。而在本文工作中,我们深入研究了一个很常见但被忽略的开放世界场景,其中目标域可能包含从显著不同的环境中提取的测试数据分布,例如与源域不同的语义类别,或者只是随机噪声。
我们将上述测试数据称为强分布外数据(strong OOD)。而在本工作中被称为弱 OOD 数据则是分布偏移的测试数据,例如常见的合成损坏。因此,现有工作缺乏对这种现实环境的研究促使我们探索提高开放世界测试段训练(OWTTT)的鲁棒性,其中测试数据被强 OOD 样本污染
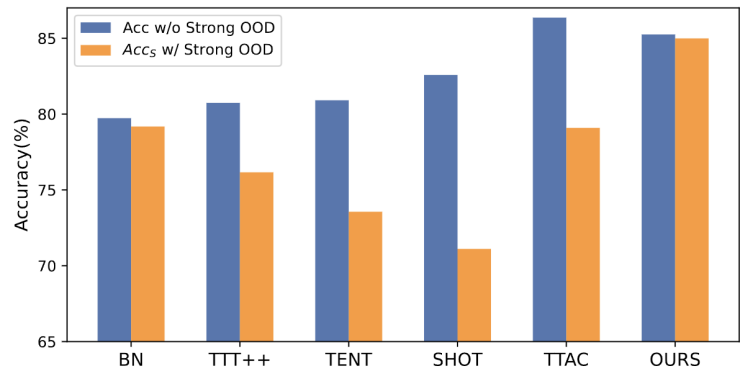
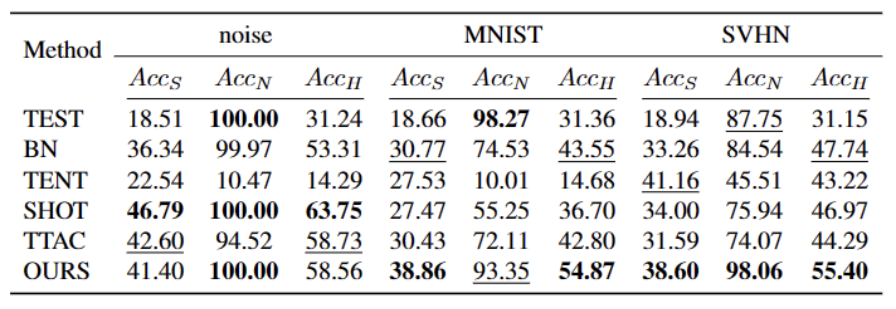
需要重写的内容是:图1:在OWTTT设定下,对现有的TTT方法进行评估的结果
根据图1所示,我们首先对现有的OWTTT设定下的TTT方法进行了评估,发现通过自训练和分布对齐的TTT方法都会受到强OOD样本的影响。这些结果表明,在开放世界中应用现有的TTT技术无法实现安全的测试训练。我们将它们的失败归因于以下两个原因
基于自训练的 TTT 很难处理强 OOD 样本,因为它必须将测试样本分配给已知的类别。尽管可以通过应用半监督学习中采用的阈值来过滤掉一些低置信度样本,但仍然不能保证滤除所有强 OOD 样本。
当计算强 OOD 样本来估计目标域分布时,基于分布对齐的方法将会受到影响。全局分布对齐 [1] 和类别分布对齐 [2] 都可能受到影响,并导致特征分布对齐不准确。
为了提高自训练框架下开放世界 TTT 的鲁棒性,我们考虑了现有 TTT 方法失败的潜在原因,并提出了两种技术相结合的解决方案
首先,我们将在自训练的变体上建立TTT的基线,即在目标域中使用源域原型作为聚类中心进行聚类。为了减轻自训练受到错误伪标签的强OOD影响,我们提出了一种无超参数的方法来拒绝强OOD样本
为了进一步分离弱 OOD 样本和强 OOD 样本的特征,我们允许原型池通过选择孤立的强 OOD 样本扩展。因此,自训练将允许强 OOD 样本围绕新扩展的强 OOD 原型形成紧密的聚类。这将有利于源域和目标域之间的分布对齐。我们进一步提出通过全局分布对齐来规范自我训练,以降低确认偏差的风险
最后,为了综合开放世界的 TTT 场景,我们采用 CIFAR10-C、CIFAR100-C、ImageNet-C、VisDA-C、ImageNet-R、Tiny-ImageNet、MNIST 和 SVHN 数据集,并通过利用一个数据集为弱 OOD,其他为强 OOD 建立基准数据集。我们将此基准称为开放世界测试段训练基准,并希望这能鼓励未来更多的工作关注更现实场景中测试段训练的稳健性。
方法
论文分了四个部分来介绍所提出的方法。
1)概述开放世界下测试段训练任务的设定。
2)介绍了如何通过原型聚类是一种无监督学习算法,用于将数据集中的样本聚类成不同的类别。在原型聚类中,每个类别由一个或多个原型表示,这些原型可以是数据集中的样本或者是根据某种规则生成的。原型聚类的目标是通过最小化样本与其所属类别原型之间的距离来实现聚类。常见的原型聚类算法包括K均值聚类和高斯混合模型。这些算法在数据挖掘、模式识别和图像处理等领域得到广泛应用实现 TTT 以及如何扩展原型以进行开放世界测试时训练。
3)介绍了如何利用目标域数据进行需要进行重写的内容是:动态原型扩展。
4)引入分布对齐与原型聚类是一种无监督学习算法,用于将数据集中的样本聚类成不同的类别。在原型聚类中,每个类别由一个或多个原型表示,这些原型可以是数据集中的样本或者是根据某种规则生成的。原型聚类的目标是通过最小化样本与其所属类别原型之间的距离来实现聚类。常见的原型聚类算法包括K均值聚类和高斯混合模型。这些算法在数据挖掘、模式识别和图像处理等领域得到广泛应用相结合,以实现强大的开放世界测试时训练。
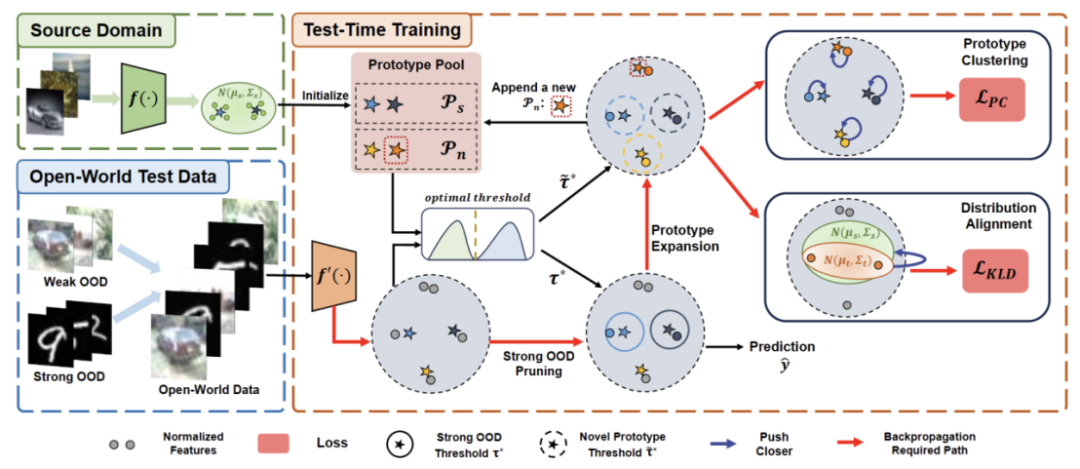
需要重新写作的内容是:图2:方法概览图
任务设定
TTT的目标是使源域预训练模型适应目标域,其中目标域可能相对于源域存在分布迁移。在标准的封闭世界TTT中,源域和目标域的标签空间是相同的。然而,在开放世界TTT中,目标域的标签空间包含源域的目标空间,也就是说目标域具有未见过的新语义类别
为了避免 TTT 定义之间的混淆,我们采用 TTAC [2] 中提出的顺序测试时间训练(sTTT)协议进行评估。在 sTTT 协议下,测试样本被顺序测试,并在观察到小批量测试样本后进行模型更新。对到达时间戳 t 的任何测试样本的预测不会受到到达 t+k(其 k 大于 0)的任何测试样本的影响。
原型聚类是一种无监督学习算法,用于将数据集中的样本聚类成不同的类别。在原型聚类中,每个类别由一个或多个原型表示,这些原型可以是数据集中的样本或者是根据某种规则生成的。原型聚类的目标是通过最小化样本与其所属类别原型之间的距离来实现聚类。常见的原型聚类算法包括K均值聚类和高斯混合模型。这些算法在数据挖掘、模式识别和图像处理等领域得到广泛应用
受到域适应任务中使用聚类的工作启发 [3,4],我们将测试段训练视为发现目标域数据中的簇结构。通过将代表性原型识别为聚类中心,在目标域中识别聚类结构,并鼓励测试样本嵌入到其中一个原型附近。原型聚类是一种无监督学习算法,用于将数据集中的样本聚类成不同的类别。在原型聚类中,每个类别由一个或多个原型表示,这些原型可以是数据集中的样本或者是根据某种规则生成的。原型聚类的目标是通过最小化样本与其所属类别原型之间的距离来实现聚类。常见的原型聚类算法包括K均值聚类和高斯混合模型。这些算法在数据挖掘、模式识别和图像处理等领域得到广泛应用的目标定义为最小化样本与聚类中心余弦相似度的负对数似然损失,如下式所示。
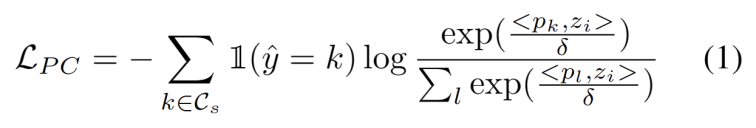
我们开发了一种无超参数的方法来滤除强 OOD 样本,以避免调整模型权重的负面影响。具体来说,我们为每个测试样本定义一个强 OOD 分数 os 作为与源域原型的最高相似度,如下式所示。
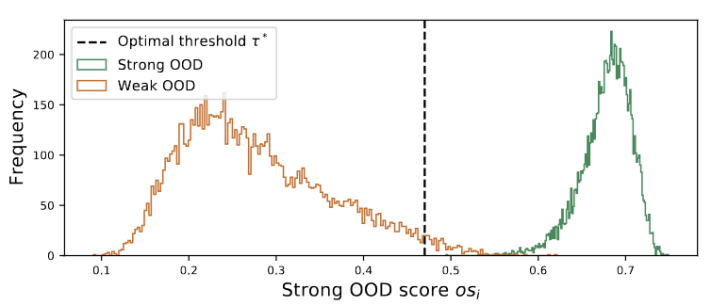
图 3 离群值呈双峰分布
我们观察到离群值服从双峰分布,如图 3 所示。因此,我们没有指定固定阈值,而是将最佳阈值定义为分离两种分布的的最佳值。具体来说,问题可以表述为将离群值分为两个簇,最佳阈值将最小化中的簇内方差。优化下式可以通过以 0.01 的步长穷举搜索从 0 到 1 的所有可能阈值来有效实现。
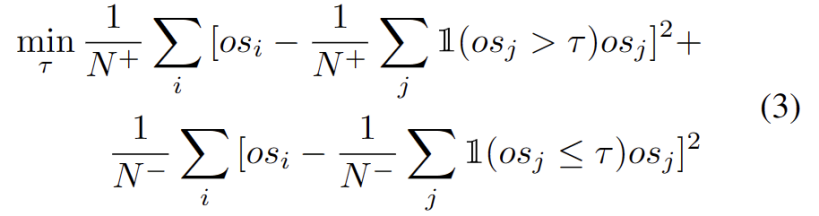
需要进行重写的内容是:动态原型扩展
扩展强 OOD 原型池需要同时考虑源域和强 OOD 原型来评估测试样本。为了从数据中动态估计簇的数量,之前的研究了类似的问题。确定性硬聚类算法 DP-means [5] 是通过测量数据点到已知聚类中心的距离而开发的,当距离高于阈值时将初始化一个新聚类。DP-means 被证明相当于优化 K-means 目标,但对簇的数量有额外的惩罚,为需要进行重写的内容是:动态原型扩展提供了一个可行的解决方案。
为了减轻估计额外超参数的难度,我们首先定义一个测试样本,其具有扩展的强 OOD 分数作为与现有源域原型和强 OOD 原型的最近距离,如下式。因此,测试高于此阈值的样本将建立一个新的原型。为了避免添加附近的测试样本,我们增量地重复此原型扩展过程。
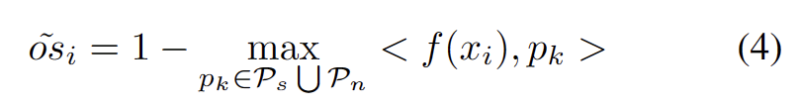
随着其他强 OOD 原型的确定,我们定义了用于测试样本的原型聚类是一种无监督学习算法,用于将数据集中的样本聚类成不同的类别。在原型聚类中,每个类别由一个或多个原型表示,这些原型可以是数据集中的样本或者是根据某种规则生成的。原型聚类的目标是通过最小化样本与其所属类别原型之间的距离来实现聚类。常见的原型聚类算法包括K均值聚类和高斯混合模型。这些算法在数据挖掘、模式识别和图像处理等领域得到广泛应用损失,并考虑了两个因素。首先,分类为已知类的测试样本应该嵌入到更靠近原型的位置并远离其他原型,这定义了 K 类分类任务。其次,被分类为强 OOD 原型的测试样本应该远离任何源域原型,这定义了 K+1 类分类任务。考虑到这些目标,我们将原型聚类是一种无监督学习算法,用于将数据集中的样本聚类成不同的类别。在原型聚类中,每个类别由一个或多个原型表示,这些原型可以是数据集中的样本或者是根据某种规则生成的。原型聚类的目标是通过最小化样本与其所属类别原型之间的距离来实现聚类。常见的原型聚类算法包括K均值聚类和高斯混合模型。这些算法在数据挖掘、模式识别和图像处理等领域得到广泛应用损失定义为下式。
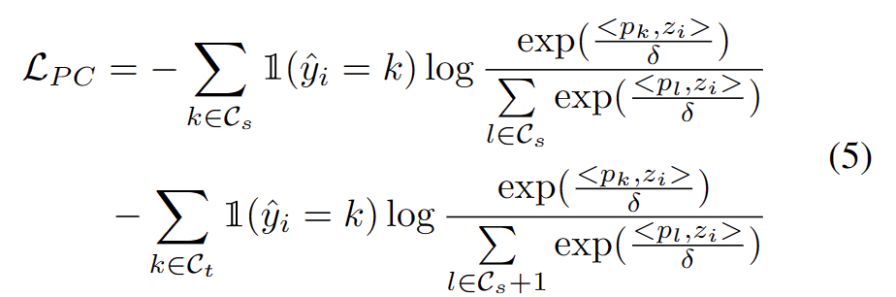
分布对齐约束
众所周知,自训练容易受到错误伪标签的影响。目标域由 OOD 样本组成时,情况会更加恶化。为了降低失败的风险,我们进一步将分布对齐 [1] 作为自我训练的正则化,如下式。
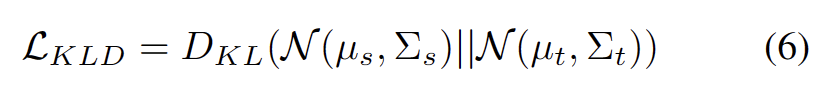


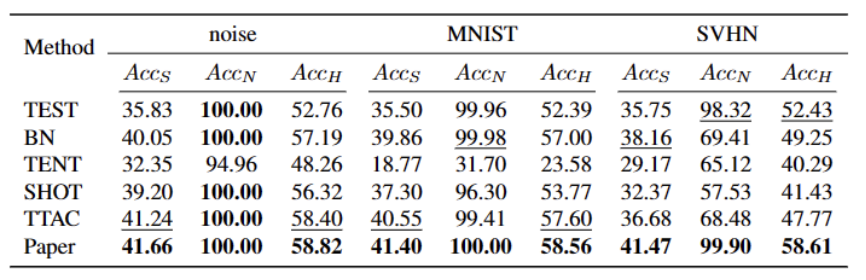
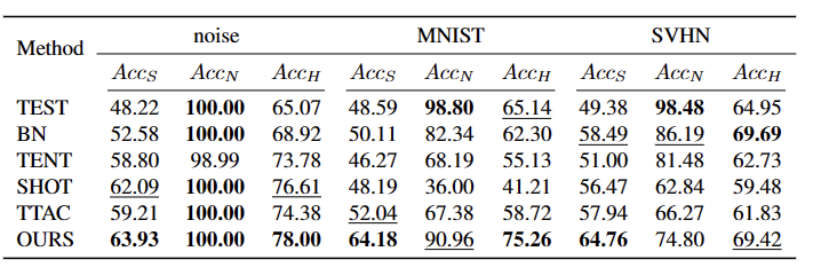
总结内容时,需要保持原意不变,将语言改写为中文
本文首次提出了开放世界测试段训练(OWTTT)的问题和设定,指出现有的方法在处理含有和源域样本有语义偏移的强 OOD 样本的目标域数据时时会遇到困难,并提出一个基于需要进行重写的内容是:动态原型扩展的自训练的方法解决上述问题。我们希望这项工作能够为 TTT 的后续研究探索面向更加鲁棒的 TTT 方法提供新方向。
参考文献:
[1] Yuejiang Liu, Parth Kothari, Bastien van Delft, Baptiste Bellot-Gurlet, Taylor Mordan, and Alexandre Alahi. Ttt++: When does self-supervised test-time training fail or thrive? In Advances in Neural Information Processing Systems, 2021.
[2] Yongyi Su, Xun Xu, and Kui Jia. Revisiting realistic test-time training: Sequential inference and adaptation by anchored clustering. In Advances in Neural Information Processing Systems, 2022.
[3] 唐辉和贾奎。区分性对抗域适应。在人工智能AAAI会议论文集中,卷34,页5940-5947,2020年
[4] Kuniaki Saito, Shohei Yamamoto, Yoshitaka Ushiku, and Tatsuya Harada. Open set domain adaptation by backpropagation. In European Conference on Computer Vision, 2018.
[5] Brian Kulis和Michael I Jordan。重新审视k-means:通过贝叶斯非参数方法的新算法。在机器学习国际会议上,2012年
以上是ICCV 2023 Oral | 如何在开放世界进行测试段训练?基于动态原型扩展的自训练方法的详细内容。更多信息请关注PHP中文网其他相关文章!


![PHP实战开发极速入门: PHP快速创建[小型商业论坛]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)



















