

Requests 是一个 Python 模块,可用于发送各种 HTTP 请求。它是一个易于使用的库,具有许多功能,从在 URL 中传递参数到发送自定义标头和 SSL 验证。在本教程中,您将学习如何使用该库在 Python 中发送简单的 HTTP 请求。
您可以在 Python 版本 2.6–2.7 和 3.3–3.6 中使用请求。在继续之前,您应该知道 Requests 是一个外部模块,因此在尝试本教程中的示例之前必须先安装它。您可以通过在终端中运行以下命令来安装它:
pip install requests
安装模块后,您可以使用以下命令导入模块来验证是否已成功安装:
import requests
如果安装成功,您将不会看到任何错误消息。
使用 Requests 发送 HTTP 请求非常容易。您首先导入模块,然后发出请求。这是一个例子:
import requests
req = requests.get('https://tutsplus.com/')
有关我们请求的所有信息现在都存储在名为 req 的响应对象中。例如,您可以使用 req.encoding 属性获取网页的编码。您还可以使用 req.status_code 属性获取请求的状态代码。
req.encoding # returns 'utf-8' req.status_code # returns 200
您可以使用 req.cookies 访问服务器发回的 cookie。同样,您可以使用 req.headers 获取响应标头。 req.headers 属性返回响应标头的不区分大小写的字典。这意味着 req.headers['Content-Length']、req.headers['content-length'] 和 req。 headers['CONTENT-LENGTH'] 都会返回 'Content-Length' 响应头的值。
您可以检查响应是否是格式良好的 HTTP 重定向,可以使用 req.is_redirect 属性自动处理。它将根据响应返回 True 或 False 。您还可以使用 req.elapsed 属性获取发送请求和获取响应之间经过的时间。
由于多种原因(包括重定向),您最初传递给 get() 函数的 URL 可能与响应的最终 URL 不同。要查看最终的响应 URL,您可以使用 req.url 属性。
import requests
req = requests.get('https://www.tutsplus.com/')
req.encoding # returns 'utf-8'
req.status_code # returns 200
req.elapsed # returns datetime.timedelta(0, 1, 666890)
req.url # returns 'https://tutsplus.com/'
req.history
# returns [<Response [301]>, <Response [301]>]
req.headers['Content-Type']
# returns 'text/html; charset=utf-8'
获取有关您正在访问的网页的所有这些信息固然很好,但您很可能想要访问实际内容。如果您访问的内容是文本,则可以使用 req.text 属性来访问它。然后内容被解析为 unicode。您可以使用 req.encoding 属性传递用于解码文本的编码。
对于非文本响应,您可以使用 req.content 以二进制形式访问它们。该模块将自动解码 gzip 和 deflate 传输编码。当您处理媒体文件时,这会很有帮助。同样,您可以使用 req.json() 访问响应的 json 编码内容(如果存在)。
您还可以使用 req.raw 从服务器获取原始响应。请记住,您必须在请求中传递 stream=True 才能获取原始响应。
您使用请求模块从 Internet 下载的某些文件可能会很大。在这种情况下,立即将整个响应或文件加载到内存中是不明智的。您可以使用 iter_content(chunk_size = 1,decode_unicode=False) 方法分块或块下载文件。
此方法一次迭代 chunk_size 字节数中的响应数据。当请求上设置了 stream=True 时,此方法将避免一次将整个文件读入内存以获得大量响应。 chunk_size 参数可以是整数,也可以是 None。当设置为整数值时,chunk_size 确定应读入内存的字节数。
当 chunk_size 设置为 None 且 stream 设置为 True 时,数据将被读取为无论收到的块大小如何,它都会到达。当 chunk_size 设置为 None 且 stream 设置为 False 时,所有数据将作为单个返回块。
让我们使用请求模块下载一些蘑菇的图像。这是实际图像:

这是您需要的代码:
import requests
req = requests.get('path/to/mushrooms.jpg', stream=True)
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
for chunk in req.iter_content(chunk_size=50000):
print('Received a Chunk')
fd.write(chunk)
'path/to/mushrooms.jpg' 是实际的图像 URL。您可以将任何其他图像的 URL 放在这里来下载其他内容。给定的图像文件大小为 162kb,并且您已将 chunk_size 设置为 50,000 字节。这意味着“Received a Chunk”消息应在终端中打印四次。最后一个块的大小将仅为 32350 字节,因为前三次迭代后仍待接收的文件部分为 32350 字节。
您还可以用类似的方式下载视频。我们可以简单地将其值设置为 None,而不是指定固定的 chunk_size,然后视频将以提供的任何块大小下载。以下代码片段将从 Mixkit 下载高速公路的视频:
import requests
req = requests.get('path/to/highway/video.mp4', stream=True)
req.raise_for_status()
with open('highway.mp4', 'wb') as fd:
for chunk in req.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
尝试运行代码,您将看到视频作为单个块下载。
如果您决定使用 stream 参数,则应记住以下几点。响应正文的下载会被推迟,直到您使用 content 属性实际访问其值。这样,如果某些标头值之一看起来不正确,您就可以避免下载文件。
另请记住,在将流的值设置为 True 时启动的任何连接都不会关闭,除非您消耗所有数据或使用 close() 方法。确保连接始终关闭的更好方法是在 with 语句中发出请求,即使您部分读取了响应,如下所示:
import requests
with requests.get('path/to/highway/video.mp4', stream=True) as rq:
with open('highway.mp4', 'wb') as fd:
for chunk in rq.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
由于我们之前下载的图片文件比较小,您也可以使用以下代码一次性下载:
import requests
req = requests.get('path/to/mushrooms.jpg')
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
fd.write(req.content)
我们跳过了设置 stream 参数的值,因此默认设置为 False。这意味着所有响应内容将立即下载。借助 content 属性,将响应内容捕获为二进制数据。
请求还允许您在 URL 中传递参数。当您在网页上搜索某些结果(例如特定图像或教程)时,这会很有帮助。您可以使用 GET 请求中的 params 关键字将这些查询字符串作为字符串字典提供。这是一个例子:
import requests
query = {'q': 'Forest', 'order': 'popular', 'min_width': '800', 'min_height': '600'}
req = requests.get('https://pixabay.com/en/photos/', params=query)
req.url
# returns 'https://pixabay.com/en/photos/?order=popular&min_height=600&q=Forest&min_width=800'
发出 POST 请求与发出 GET 请求一样简单。您只需使用 post() 方法而不是 get() 即可。当您自动提交表单时,这会很有用。例如,以下代码将向 httpbin.org 域发送 post 请求,并将响应 JSON 作为文本输出。
import requests
req = requests.post('https://httpbin.org/post', data = {'username': 'monty', 'password': 'something_complicated'})
req.raise_for_status()
print(req.text)
'''
{
"args": {},
"data": "",
"files": {},
"form": {
"password": "something_complicated",
"username": "monty"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "45",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-63ad437e-67f5db6a161314861484f2eb"
},
"json": null,
"origin": "YOUR.IP.ADDRESS",
"url": "https://httpbin.org/post"
}
'''
您可以将这些 POST 请求发送到任何可以处理它们的 URL。举个例子,我的一位朋友创建了一个网页,用户可以在其中输入单词并使用 API 获取其含义以及发音和其他信息。我们可以用我们查询的单词向URL发出POST请求,然后将结果保存为HTML页面,如下所示:
import requests
word = 'Pulchritudinous'
filename = word.lower() + '.html'
req = requests.post('https://tutorialio.com/tools/dictionary.php', data = {'query': word})
req.raise_for_status()
with open(filename, 'wb') as fd:
fd.write(req.content)
执行上面的代码,它会返回一个包含该单词信息的页面,如下图所示。
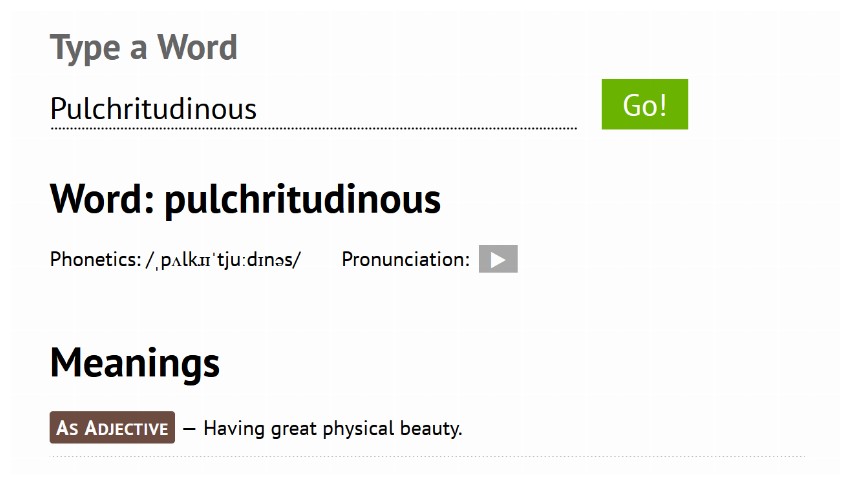
如前所述,您可以使用 req.cookies 和 req.headers 访问服务器发回给您的 cookie 和标头。请求还允许您通过请求发送您自己的自定义 cookie 和标头。当您想要为您的请求设置自定义用户代理时,这会很有帮助。
要将 HTTP 标头添加到请求中,您只需将它们通过 dict 传递到 headers 参数即可。同样,您还可以使用传递给 cookies 参数的 dict 将自己的 cookie 发送到服务器。
import requests
url = 'http://some-domain.com/set/cookies/headers'
headers = {'user-agent': 'your-own-user-agent/0.0.1'}
cookies = {'visit-month': 'February'}
req = requests.get(url, headers=headers, cookies=cookies)
Cookie 也可以在 Cookie Jar 中传递。它们提供了更完整的界面,允许您通过多个路径使用这些 cookie。这是一个例子:
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('first_cookie', 'first', domain='httpbin.org', path='/cookies')
jar.set('second_cookie', 'second', domain='httpbin.org', path='/extra')
jar.set('third_cookie', 'third', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
req = requests.get(url, cookies=jar)
req.text
# returns '{ "cookies": { "first_cookie": "first", "third_cookie": "third" }}'
有时,在多个请求中保留某些参数很有用。 Session 对象正是这样做的。例如,它将在使用同一会话发出的所有请求中保留 cookie 数据。 Session 对象使用 urllib3 的连接池。这意味着底层 TCP 连接将被重复用于向同一主机发出的所有请求。这可以显着提高性能。您还可以将 Requests 对象的方法与 Session 对象一起使用。
以下是使用和不使用会话发送的多个请求的示例:
import requests
reqOne = requests.get('https://tutsplus.com/')
reqOne.cookies['_tuts_session']
#returns 'cc118d94a84f0ea37c64f14dd868a175'
reqTwo = requests.get('https://code.tutsplus.com/tutorials')
reqTwo.cookies['_tuts_session']
#returns '3775e1f1d7f3448e25881dfc35b8a69a'
ssnOne = requests.Session()
ssnOne.get('https://tutsplus.com/')
ssnOne.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
reqThree = ssnOne.get('https://code.tutsplus.com/tutorials')
reqThree.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
正如您所看到的,会话cookie在第一个和第二个请求中具有不同的值,但当我们使用Session对象时它具有相同的值。当您尝试此代码时,您将获得不同的值,但在您的情况下,使用会话对象发出的请求的 cookie 将具有相同的值。
当您想要在所有请求中发送相同的数据时,会话也很有用。例如,如果您决定将 cookie 或用户代理标头与所有请求一起发送到给定域,则可以使用 Session 对象。这是一个例子:
import requests
ssn = requests.Session()
ssn.cookies.update({'visit-month': 'February'})
reqOne = ssn.get('http://httpbin.org/cookies')
print(reqOne.text)
# prints information about "visit-month" cookie
reqTwo = ssn.get('http://httpbin.org/cookies', cookies={'visit-year': '2017'})
print(reqTwo.text)
# prints information about "visit-month" and "visit-year" cookie
reqThree = ssn.get('http://httpbin.org/cookies')
print(reqThree.text)
# prints information about "visit-month" cookie
如您所见,"visit-month" 会话 cookie 随所有三个请求一起发送。但是, "visit-year" cookie 仅在第二次请求期间发送。第三个请求中也没有提及 "vist-year" cookie。这证实了单个请求上设置的 cookie 或其他数据不会与其他会话请求一起发送。
本教程中讨论的概念应该可以帮助您通过传递特定标头、cookie 或查询字符串来向服务器发出基本请求。当您尝试抓取网页以获取信息时,这将非常方便。现在,一旦您找出 URL 中的模式,您还应该能够自动从不同的网站下载音乐文件和壁纸。
无论您是刚刚入门还是希望学习新技能的经验丰富的程序员,都可以通过我们完整的 Python 教程指南学习 Python。
以上是Python中使用Requests模块的详细内容。更多信息请关注PHP中文网其他相关文章!





















