

近日,Meta发布了Voicebox AI模型,它在音频模拟方面有着显著优势。
据悉,Voicebox只需要一段2秒钟的音频样本,即可准确辨别出音频细节、音色,并基于文字结果转换为语音输出。

Voicebox 是一种生成式 AI 模型,可以帮助进行音频编辑、采样和造型。
这种技术在未来可以用来帮助创作者轻松编辑音轨,同时,它也能够为声带受损的人群提供协助,帮助TA们重新“发声”。使视障人士能够通过声音听到他们朋友的书面信息,同时使人们能够用自己的声音说任何外语。
同时,它还可以基于语音片段的前后内容,自动补齐中间缺失的内容。
根据Meta的介绍,Voicebox能够为AI助手,或是未来元宇宙的NPC提供自然且真实的语音效果,大大提升用户使用时的沉浸感。
Voicebox 的多功能性支持各种任务,包括:
上下文文本到语音合成:使用短至两秒的音频样本,Voicebox 可以匹配音频风格并将其用于文本到语音生成。
语音编辑和降噪:Voicebox 可以重新创建被噪音打断的部分语音或替换说错的词,而无需重新录制整个语音。例如,您可以识别被狗叫声打断的一段语音,将其裁剪,然后指示 Voicebox 重新生成该段——就像用于音频编辑的橡皮擦一样。
跨语言转换:当给定某人演讲样本和一段英语、法语、德语、西班牙语、波兰语或葡萄牙语的文本时,Voicebox 可以生成任何这些语言的文本阅读,即使样本语音和文本是不同的语言。将来,即使人们不懂这些语言,他们也可以使用此功能以一种更为自然、真实的方式进行交流。
流匹配是 Voicebox 使用的一种方法,已被证明可以提高扩散模型的性能。Voicebox 在可懂度(5.9% 对 1.9% 的单词错误率)和音频相似性(0.580 对 0.681)方面优于当前最先进的英语模型 VALL-E,同时快 20 倍。对于跨语言风格迁移,Voicebox 优于 YourTTS,将平均单词错误率从 10.9% 降低到 5.2%,并将音频相似度从 0.335 提高到 0.481。
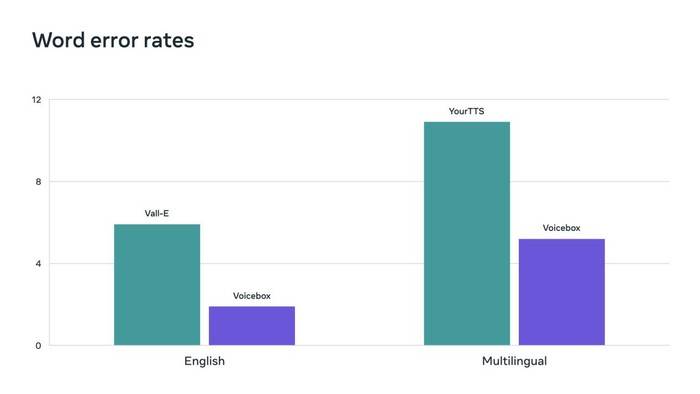
Voicebox 取得了新的最先进的结果,在单词错误率方面优于 Vall-E 和 YourTTS。
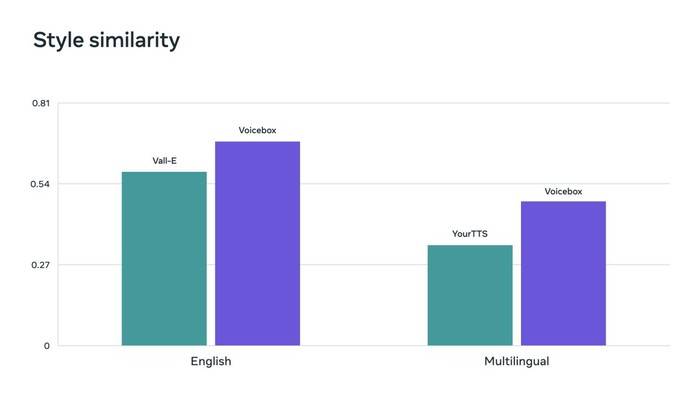
Voicebox 还分别在英语和多语言基准测试中的音频风格相似性指标上取得了最新的最新成果。
值得一提的是,Meta目前已经意识到了Voicebox被应用在造假领域时,存在的潜在危害,因此他们正在寻找一种区分真实语音和Voicebox生成语音的方法。
在找到解决方法前,Meta将不会向公众公开Voicebox AI模型,以避免不必要的危害。
编辑点评:AI如今已经被应用在各个领域,作为第一个成功执行任务泛化的多功能、高效模型,相信 Voicebox 可以开创语音生成 AI 的新时代。如果Meta无法有效应对音频造假问题,那么Voicebox技术可能会被禁用。
以上是Meta发布音频AI模型,仅需2秒片段模拟真人语音的详细内容。更多信息请关注PHP中文网其他相关文章!





















