


通过采访和约稿的方式,请运维领域老炮输出深刻洞见,共同碰撞,以期形成一些先进的共识,推动行业更好得前进。
这一期我们邀请到的是又拍云科技的邵海杨,一个25年的Linux老炮,邵总醉心技术,一步一步往上走,是普通运维人员的典型成长路径,希望今天的采访可以对你有那么一些启发。
这里是接地气、有高度的《运维百家讲坛》第 4 期,开讲!
我是来自又拍云科技的邵海杨,从1998年开始使用Linux至今快25年了,资深(老鸟)Linux系统运维/架构师,DevOps八荣八耻倡导者,业余撰稿人;精通(心虚)系统优化及网络服务管理,Linux系统定制,CDN加速和安全防御; 擅长互联网高性能网络及架构设计、虚拟化KVM及OpenStack云平台, K8S容器云和Ceph分布式存储等新技术;喜欢交流分享,活跃于社区,一直积极投身于开源活动的组织和传播。
又拍云是一家提供云存储,云分发,云处理服务的公司,也是国内首创可编程CDN 服务的专业云服务提供商,特点就是7x24全年不间断服务,所以云运维也有一些律条或原则,比如:
先保障稳定,然后再优化
过度设计或过早优化很可能会带来更多的故障停机时间,要先集中精力提高系统的可扩展性和高可用性。坚持 “先完成,再完善,后完美”,项目也是“先能用,再好用,后用好”的实施策略。
提供可靠的测试依据和时间验证
引入新技术到架构之前,要确保新技术的稳定性和足够时间久的考验,更要有运维工程化中开发出来的工具链的完整。一旦线上返工或变更造成的措手不及可能已经是故障的导火索。
使用可控的自动化手段提升效率
自动部署、自动编排、自动巡检、自动升级等自动化手段越来越多应用于云运维。这是适应云计算时代的趋势,但能力越强,责任越大,要谨慎自动化的雪崩和惊群效应,做好灰度/蓝绿部署和各种测试。
保持简单,监控一切
保持简单,别把事搞的太复杂。除了常见的异常问题报警外,面向业务指标,市场指标和销售数据,成本等都可以用来做趋势分析信息。定期的轮询查看各个趋势数据的峰值峰谷有助于见微知著。
面向预算的运维
运维团队通常是最大的花费者,因为预算不足,没有钱的运维是很难兼顾到日益增长的公司业务规模,除非公司业务已经停滞或不再有爆炸式的增长,面对这样的挑战,运维要学会降本增益,开源节流,利用新技术实现能效比的提升。
面向场景的智能运维
各种各样的负载场景,从高并发处理到视频转码,从高性能并行计算到海量的网络请求。这些不同的负载场景,对网络带宽,各种处理和IO的要求也各不相同。智能运维就是需要深入理解业务,合理配置资源和架构来满足不同业务场景的需求。
持续集成和发布系统
持续发布包括灰度发布、测试发布、滚动发布、回滚发布等多种场景,并且确保每种场景都应该是可以可控的。
确保任何人都可以被替换
铁打的营盘流水的兵,人挪活是常态,做好员工的共享文档管理和知识传递和分享,理论上所有人都可以被替换,任何人也不应该成为公司的天花板。
公司一直是积极鼓励员工的技能自我提高和促进成长:
又拍云运维团队内的培养包括:
对于刚步入管理岗的运维来说,我的建议是及时梳理遗留的技术债和人才技能的盘点和培养,先打好基础,后面才能有更大的空间进步,具体可以参考我的《DevOps的八荣八耻》的分享。
人才上技能树的盘点,主要是配合人事做好人才九宫格的划分(如果是开发或运维,把左侧的绩效换成潜力,绩效针对销售而言),考查的是管理者对员工的全方面的辨析能力,知人善用。
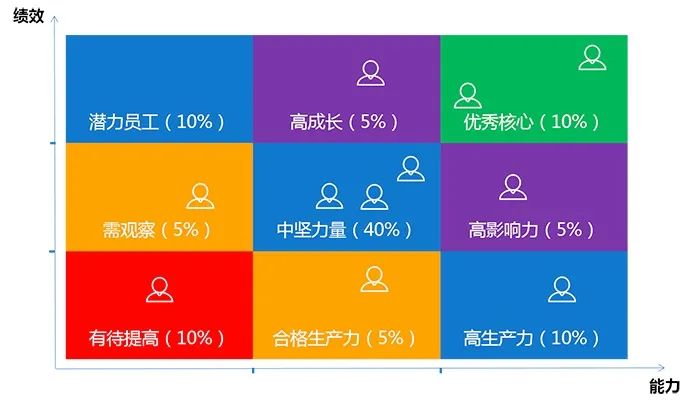
再结合公司的OKR目标管理来激励员工,它的优点在于聚集目标的同时,还能:
虽然Kubernetes代表着目前为止的devops的最佳工程应用实践(真香),但也不是所有场合都能应用,如又拍云的CDN边缘服务器,数据中心的日志分析平台,Ceph分布式存储就以物理机为主。所以,我建议找一些合适的场景先试用起来,如:
运维工程师 = 冲锋陷阵的将军
软件工程师 = 坐阵帐中的军师
理论上,优秀的软件工程师是可以把部分(甚至全部)运维工程师的工作做掉,比如说业务软件性能的监控,如果程序员在程序中插入很多的钩子或探针,就可以统计出数据来,不需要运维劳心劳力的监控;比如说程序员在设计程序的时候,考虑到了分库分表,考虑到了大并发和分布式的设计,那运维就可以水平扩展机器就行;如果软件没有那么多bug,还有很多如果......但是,现实是残酷的,这种高水平的程序员太少了,尤其在中国,大家都忙于实现业务功能,连个文档甚至注释都不愿意写,更别提能够考虑这么周全了;同理,运维接触的很多是开源很优秀很成熟的软件,从中是可以借鉴知晓优秀软件是怎么设计的,比如优秀的程序,日志信息会非常详尽,我们可以通过标准的syslog或者日志去监控它,所以,资深的运维会:
当然,要达到上述能力的运维管理,肯定需要潜心研究,承上启下,协调团队,任劳任怨的修行多年,到那个时候,运维就不再是对事情的结果负责,而是转变角色,主导和协调整个过程。当然,这里指的能力不仅仅是技能,还包括对业务的理解能力,站在公司管理层面对整个项目和资源的分配和把握。 因此,运维工程师其实是现实中的软件工程师的互补,因为大家的能力侧重点不同,所以大家更要团结一体,要能够打胜仗,离开谁都是不行的,这是一个共同修炼进步的过程。
最后,我的个人观点:架构师它可能不是一个人的角色,而是一个团队的统称,它可以:
其实沟通不顺畅的原因大部分在于对后果的不可预见性,你说冗余他说预算,你说架构他说工期,各有立场又各有苦衷,但就是没人对结果负责。我在工作中发现,当故障发生时,各部门的配合是空前团结,战斗力也是最强的,所以,沟通协作的关键在于:既要团队协作,也要责任分明
比如说提供在线10W并发的能力,需要冗余带宽冗余服务器数量x2,因为预算不足减半所导致的后果及责任人;再比如软件设计不好,通过性能监控,发现指标异常的后果及责任人;当然,报警处理不及时,人为操作故障也会算到运维亦无可厚非;故障文化就是要关注问题和关注事情本身,对事不对人。大家都在故障中成长,在复盘中变强。
运维自动化;
监控常态化;
日志可视化!
这个篇幅太多了,不展开讲,可以参考《云运维的启示和架构设计》
又拍云通常不会重复造轮子,但一定会先用好轮子,或者把轮子改造得更加称手,选择自研往往具备了一定的开发能力,再加上某些必要原因,如:
公有云做为IaaS基座,容器云作为CaaS中间层,云原生做为SaaS应用层,整个云生态日新月异,SRE团队的核心职能会更加注重顶层系统性的容量规划,指标监控,高可用性和分布式的弹性设计,所以跨平台跨部门的职能互补、团队协作、持续精进、勇于承担包括:
团队的价值就在于是否总是能够接受新事物,新的挑战,各施所长,不做井底之蛙,也不是温水煮青蛙,在创新或者颠覆来临的时候,也能保持不被时代脱钩。
技术领域
非技术领域
首先不是工作选择人,而是人选择工作,一个人若对某方面有了兴趣,真正用心学习了近10000个小时,其实做什么都是可以的。比如说我毕业那个时候,都是强调复合型人才,根本没有运维这个职业,我们不光自己攒(DIY)机器,自学Linux操作系统,还学习编程,折腾网络,自己动手写论坛聊天室等程序;Linux给我们带来的是每天都有创新的,好玩的,优秀的开源软件让我们保持激情去尽情的折腾和学习,当互联网兴起的机会来临时,做个运维总监其实也是顺理成章的事; 其实,除此之外,我还转型做过售前,技术支持,跑过市场,经常做演讲培训,所以真正的高手是什么不会学什么,技多不压身,做个懂业务、会开发的运维工程师。
我认为最重要的能力是表达沟通能力,但不排除运维本身所需的技术储备、实践动手能力、编程能力和学习能力。考虑到运维大部分还是一个成本支出的岗位,如何把深奥隐晦的性能及瓶颈指标,用直观的图表展示来获取上层持续的投入是需要技巧的;然后面对你的同事,你的兄弟部门,也需要你的影响力去协调推进工作,如果能够做到这些,说明你已经具备了领导的才能,这样以后做什么事都会站在更高的水平,用全局观的格局去统筹规划整个项目的目标,人员,工期和资源的合理分配和把握。
以上是又拍云邵海杨:25年Linux老兵聊DevOps八荣八耻的详细内容。更多信息请关注PHP中文网其他相关文章!





















