

大型预训练语言模型其中一个重要的特点就是上下文学习(In-Context Learning,ICL)能力,即通过一些示范性的输入-标签对,就可以在不更新参数的情况下对新输入的标签进行预测。
性能虽然上去了,但大模型的ICL能力到底从何而来仍然是一个开放的问题。
为了更好地理解ICL的工作原理,清华大学、北京大学和微软的研究人员共同发表了一篇论文,将语言模型解释为元优化器(meta-optimizer),并将ICL理解为一种隐性的(implicit)微调。

论文链接:https://arxiv.org/abs/2212.10559
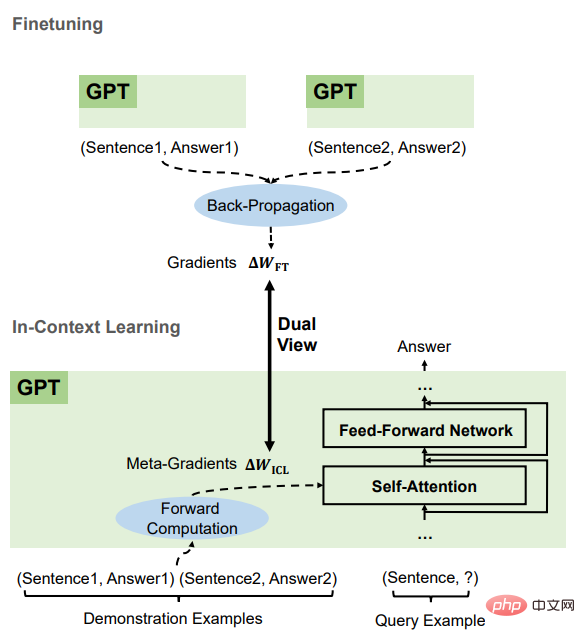
从理论上讲,这篇文章弄清楚了Transformer注意力中存在一个基于梯度下降优化的对偶形式(dual form),并在此基础上,对ICL的理解如下。GPT首先根据示范实例产生元梯度,然后将这些元梯度应用于原始的GPT,建立ICL模型。
在实验中,研究人员综合比较了ICL和基于真实任务的显式微调的行为,以提供支持该理解的经验证据。
结果证明,ICL在预测层面、表征层面和注意行为层面的表现与显式微调类似。
此外,受到元优化理解的启发,通过与基于动量的梯度下降算法的类比,文中还设计了一个基于动量的注意力,比普通的注意力有更好的表现,从另一个方面再次支持了该理解的正确性,也展现了利用该理解对模型做进一步设计的潜力。
研究人员首先对Transformer中的线性注意力机制进行了定性分析,以找出它与基于梯度下降的优化之间的对偶形式。然后将ICL与显式微调进行比较,并在这两种优化形式之间建立联系。
Transformer注意力就是元优化
设X是整个query的输入表征,X'是示例的表征,q是查询向量,则在ICL设置下,模型中一个head的注意力结果如下:
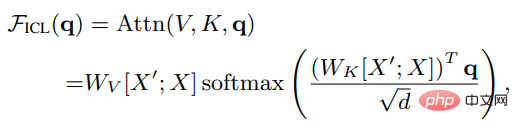
可以看到,去除缩放因子根号d和softmax后,标准的注意力机制可以近似为:
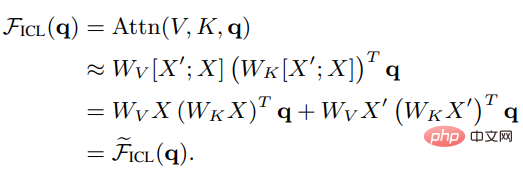
将Wzsl设为Zero-Shot Learning(ZSL)的初始参数后,Transformer注意力可以转为下面的对偶形式:
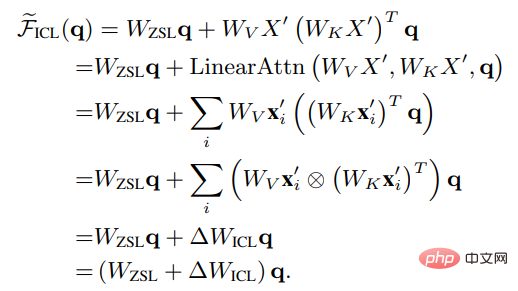
可以看到,ICL可以被解释为一个元优化(meta-optimization)的过程:
1. 将基于Transformer的预训练语言模型作为一个元优化器;
2. 通过正向计算,根据示范样例计算元梯度;
3. 通过注意力机制,将元梯度应用于原始语言模型上,建立一个ICL模型。
为了比较ICL的元优化和显式优化,研究人员设计了一个具体的微调设置作为比较的基线:考虑到ICL只直接作用于注意力的key和value,所以微调也只更新key和value投影的参数。
同样在非严谨形式下的线性注意力中,微调后的head注意力结果可以被表述为:
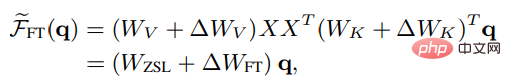
为了与ICL进行更公平的比较,实验中进一步将微调设置限制如下:
1. 将训练例子指定为ICL的示范样例;
2. 只对每个例子进行一步训练,其顺序与ICL的示范顺序相同;
3. 用ICL所用的模板对每个训练样例进行格式化,并使用因果语言建模目标进行微调。
比较后可以发现,ICL与微调有许多共同的属性,主要包括四个方面。
都是梯度下降
可以发现ICL和微调都对Wzsl进行了更新,即梯度下降,唯一的区别是,ICL通过正向计算产生元梯度,而finetuning通过反向传播获得真正的梯度。
相同的训练信息
ICL的元梯度是根据示范样例获得的,微调的梯度也是从相同的训练样本中得到的,也就是说,ICL和微调共享相同的训练信息来源。
训练样例的因果顺序相同
ICL和微调共享训练样例的因果顺序,ICL用的是decoder-only Transformers,因此示例中的后续token不会影响到前面的token;而对于微调,由于训练示例的顺序相同,并且只训练一个epoch,所以也可以保证后面的样本对前面的样本没有影响。
都作用于注意力
与zero-shot学习相比,ICL和微调的直接影响都仅限于注意力中key和value的计算。对于ICL来说,模型参数是不变的,它将示例信息编码为额外的key和value以改变注意力行为;对于微调中引入的限制,训练信息也只能作用到注意力key和value的投影矩阵中。
基于ICL和微调之间的这些共同特性,研究人员认为将ICL理解为一种隐性微调是合理的。
任务和数据集
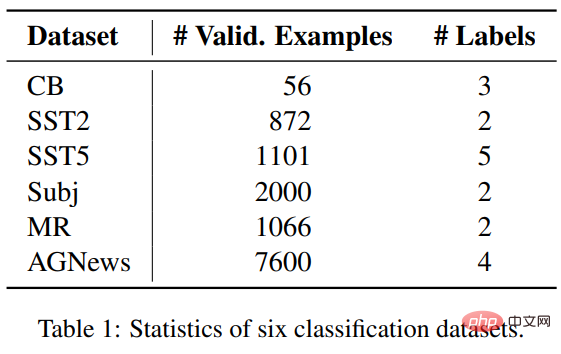
研究人员选择了横跨三个分类任务的六个数据集来对比ICL和微调,包括SST2、SST-5、MR和Subj四个用于情感分类的数据集;AGNews是一个话题分类数据集;CB用于自然语言推理。
实验设置
模型部分使用了两个类似于GPT的预训练语言模型,由fairseq发布,其参数量分别为1.3B和2.7B.
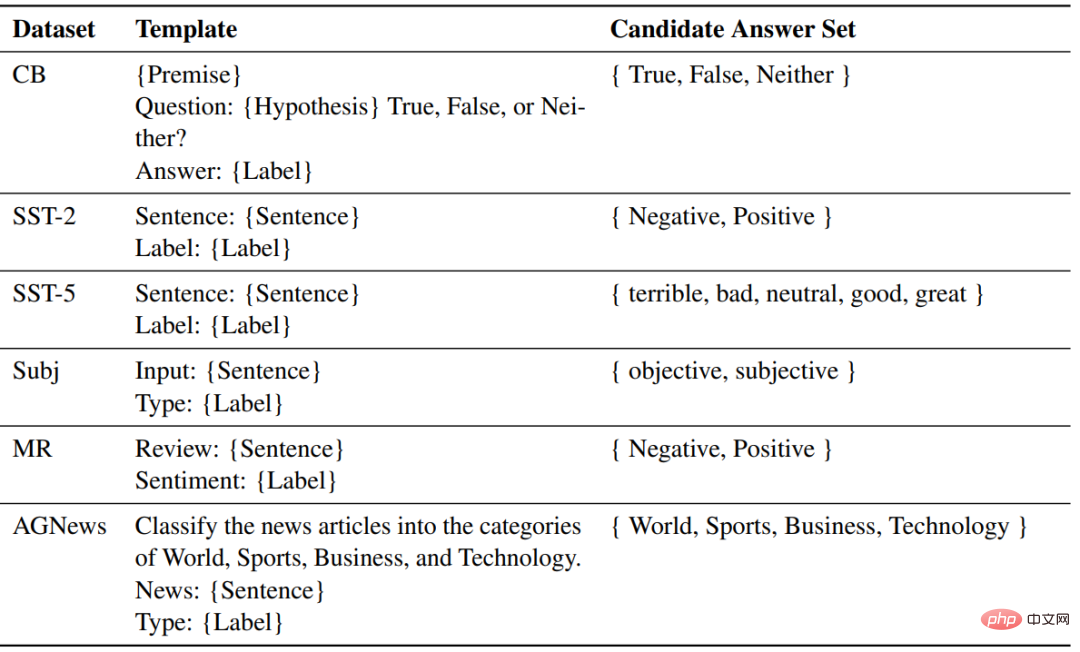
对于每个任务,使用相同的模板来对ZSL、ICL和微调的样本进行格式化。
结果
准确率
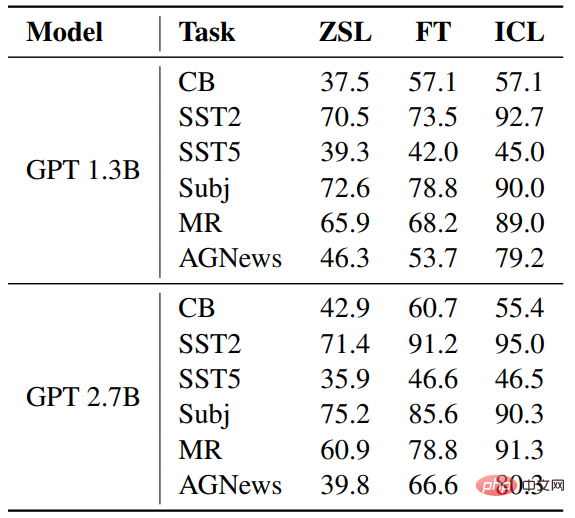
与ZSL相比,ICL和微调都取得了相当大的改进,这意味着它们的优化,对这些下游任务都有帮助。此外,ICL在少数情况下比微调更好。
Rec2FTP(Recall to Finetuning Predictions)
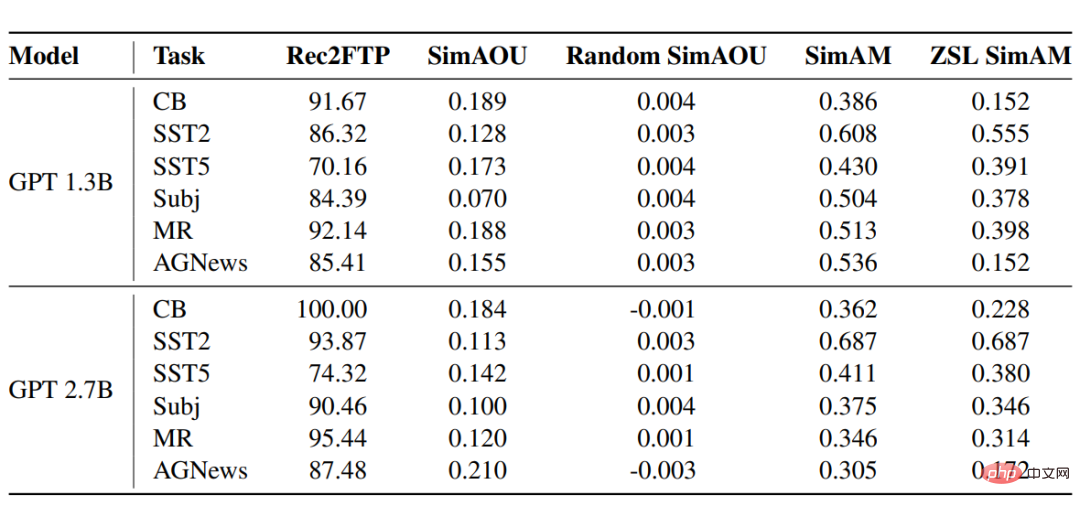
GPT模型在六个数据集上的得分结果显示,平均而言,ICL可以正确预测 87.64%的例子,而微调可以纠正ZSL。在预测层面,ICL可以覆盖大部分正确的的行为进行微调。
SimAOU(Similarity of Attention Output Updates)
从结果中可以发现,ICL更新与微调更新的相似度远高于随机更新,也意味着在表示层面上,ICL倾向于以与微调变化相同的方向改变注意力结果。
SimAM(Similarity of Attention Map)
作为SimAM的基线指标,ZSL SimAM计算了ICL注意力权重和ZSL注意力权重之间的相似度。通过比较这两个指标,可以观察到,与ZSL相比,ICL更倾向于产生与微调相似的注意力权重。
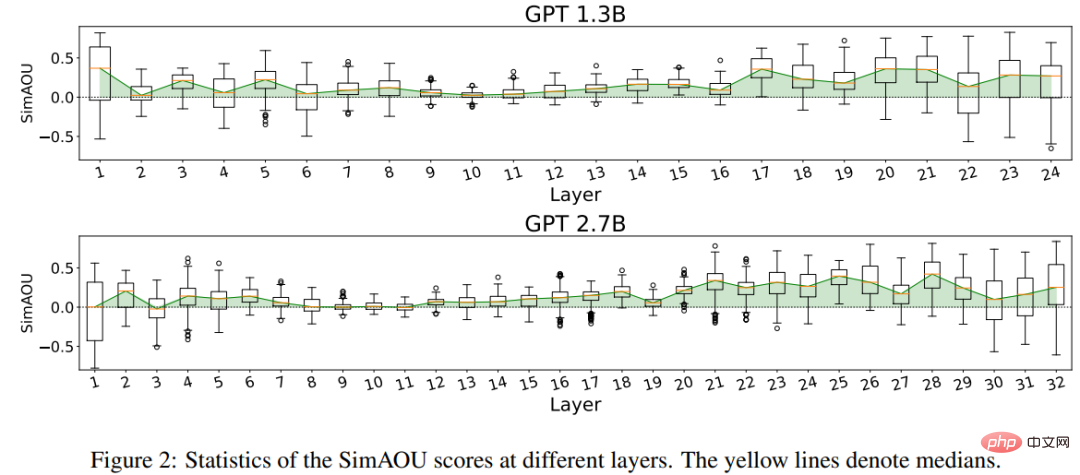
同样,在注意力行为层面,实验结果证明了ICL的行为与微调相似。
以上是清北微软深挖GPT,把上下文学习整明白了!和微调基本一致,只是参数没变而已的详细内容。更多信息请关注PHP中文网其他相关文章!





















