

最近,来自LMSYS Org(UC伯克利主导)的研究人员又搞了个大新闻——大语言模型版排位赛!
顾名思义,「LLM排位赛」就是让一群大语言模型随机进行battle,并根据它们的Elo得分进行排名。
然后,我们就能一眼看出,某个聊天机器人到底是「嘴强王者」还是「最强王者」。
划重点:团队还计划把国内和国外的这些「闭源」模型都搞进来,是骡子是马溜溜就知道了!(GPT-3.5现在就已经在匿名竞技场里了)

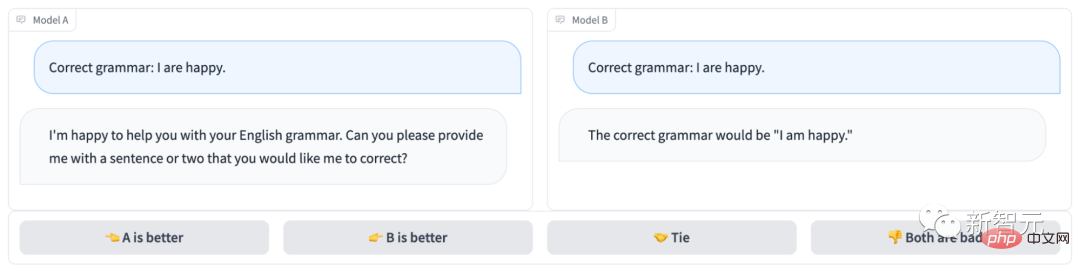
匿名聊天机器人竞技场长下面这样:
很明显,模型B回答正确,拿下这局;而模型A连题都没读懂……
项目地址:https://arena.lmsys.org/
在当前的排行榜中,130亿参数的Vicuna以1169分稳居第一,同样130亿参数的Koala位列第二,LAION的Open Assistant排在第三。
清华提出的ChatGLM,虽然只有60亿参数,但依然冲进了前五,只比130亿参数的Alpaca落后了23分。
相比之下,Meta原版的LLaMa只排到了第八(倒数第二),而Stability AI的StableLM则获得了唯一的800+分,排名倒数第一。
团队表示,之后不仅会定期更新排位赛榜单,而且还会优化算法和机制,并根据不同的任务类型提供更加细化的排名。

目前,所有的评估代码以及数据分析均已公布。
在这次的评估中,团队选择了目前比较出名的9个开源聊天机器人。
每次1v1对战,系统都会随机拉两个上场PK。用户则需要同时和这两个机器人聊天,然后决定哪个聊天机器人聊的更好。
可以看到,页面下面有4个选项,左边(A)更好,右边(B)更好,一样好,或者都很差。
当用户提交投票之后,系统就会显示模型的名称。这时,用户可以继续聊天,或者选择新的模型重新开启一轮对战。
不过,团队在分析时,只会采用模型是匿名时的投票结果。在经过差不多一周的数据收集之后,团队共收获了4.7k个有效的匿名投票。
在开始之前,团队先根据基准测试的结果,掌握了各个模型可能的排名。
根据这个排名,团队会让模型去优先选择更合适的对手。
然后,再通过均匀采样,来获得对排名的更好总体覆盖。
在排位赛结束时,团队又引入了一种新模型fastchat-t5-3b。
以上这些操作最终导致了非均匀的模型频率。
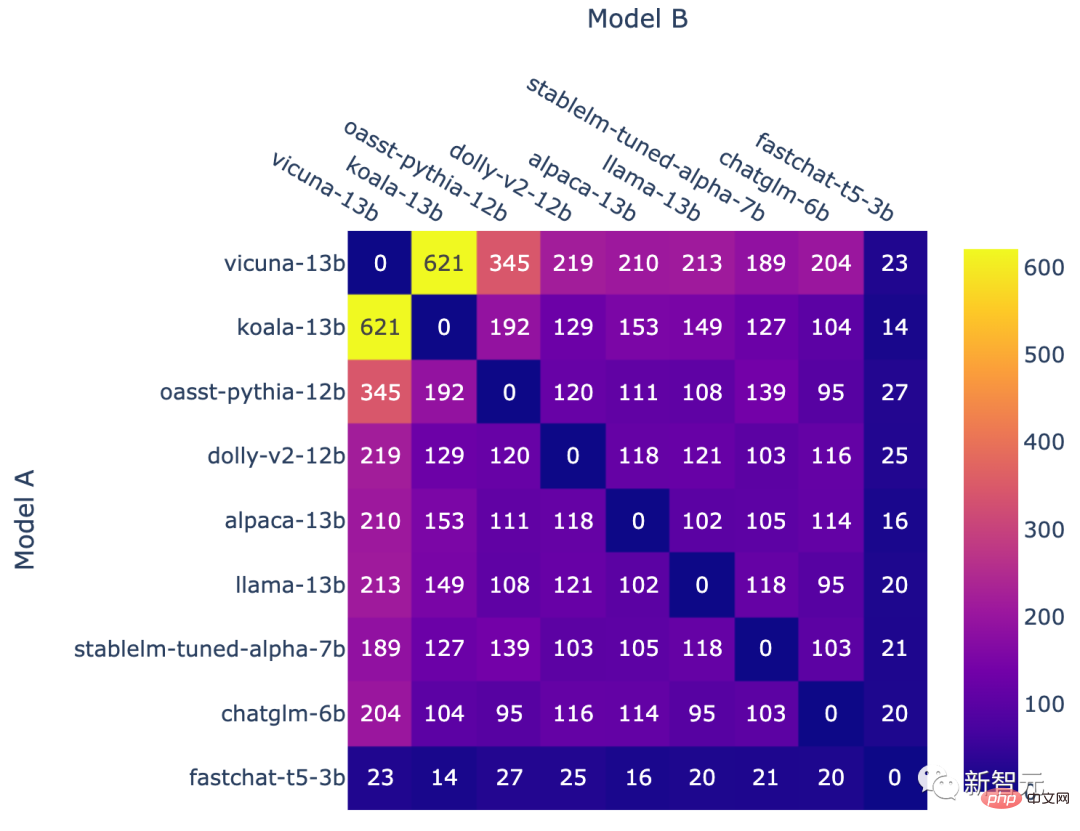
每个模型组合的对战次数
从统计数据来看,大多数用户所用的都是英语,中文排在第二位。
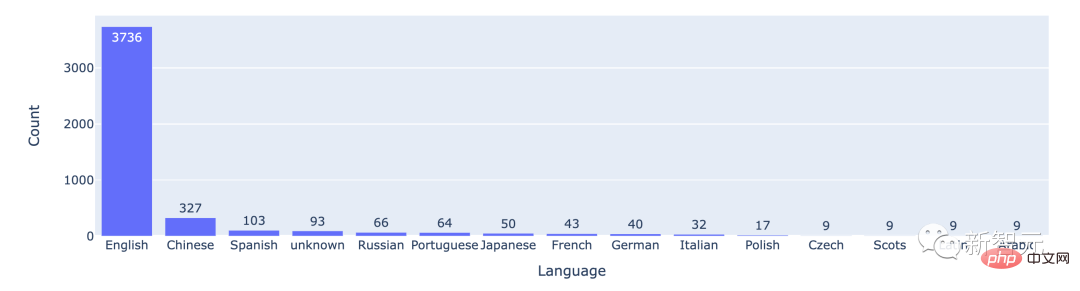
排名前15的语言的对战次数
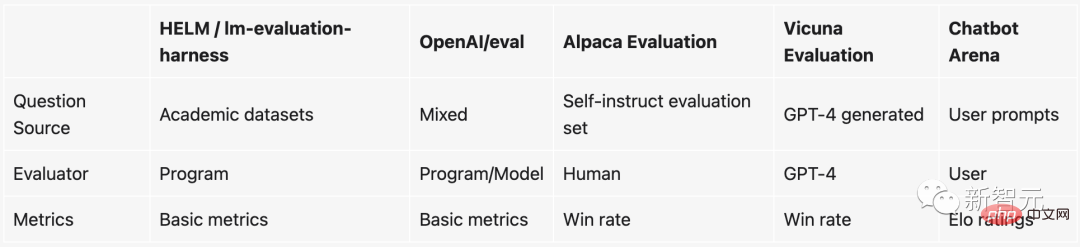
自从ChatGPT爆火之后,经过指令跟随微调的开源大语言模型如雨后春笋一般大量涌现。可以说,几乎每周都有新的开源LLM在发布。
但问题是,评估这些大语言模型非常难。
具体来说,目前用来衡量一个模型好不好的东西基本都是基于一些学术的benchmark,比如在一个某个NLP任务上构建一个测试数据集,然后看测试数据集上准确率多少。
然而,这些学术benchmark(如HELM)在大模型和聊天机器人上就不好用了。其原因在于:
1. 由于评判聊天机器人聊得好不好这件事是非常主观的,因此现有的方法很难对其进行衡量。
2. 这些大模型在训练的时候就几乎把整个互联网的数据都扫了一个遍,因此很难保证测试用的数据集没有被看到过。甚至更进一步,用测试集直接对模型进行「特训」,如此一来表现必然更好。
3. 理论上我们可以和聊天机器人聊任何事情,但很多话题或者任务在现存的benchmark里面根本就不存在。
那如果不想采用这些benchmark的话,其实还有一条路可以走——花钱请人来给模型打分。
实际上,OpenAI就是这么搞的。但是这个方法明显很慢,而且更重要的是,太贵了……
为了解决这个棘手的问题,来自UC伯克利、UCSD、CMU的团队发明了一种既好玩又实用的全新机制——聊天机器人竞技场(Chatbot Arena)。
相比而言,基于对战的基准系统具有以下优势:
当不能为所有潜在的模型对收集足够的数据时,系统应能扩展到尽可能多的模型。
系统应能够使用相对较少的试验次数评估新模型。
系统应为所有模型提供唯一顺序。给定任意两个模型,我们应该能够判断哪个排名更高或它们是否并列。
Elo等级分制度(Elo rating system)是一种计算玩家相对技能水平的方法,广泛应用在竞技游戏和各类运动当中。其中,Elo评分越高,那么就说明这个玩家越厉害。
比如英雄联盟、Dota 2以及吃鸡等等,系统给玩家进行排名的就是这个机制。
举个例子,当你在英雄联盟里面打了很多场排位赛后,就会出现一个隐藏分。这个隐藏分不仅决定了你的段位,也决定了你打排位时碰到的对手基本也是类似水平的。
而且,这个Elo评分的数值是绝对的。也就是说,当未来加入新的聊天机器人时,我们依然可以直接通过Elo的评分来判断哪个聊天机器人更厉害。
具体来说,如果玩家A的评分为Ra,玩家B的评分为Rb,玩家A获胜概率的精确公式(使用以10为底的logistic曲线)为:

然后,玩家的评分会在每场对战后线性更新。
假设玩家A(评分为Ra)预计获得Ea分,但实际获得Sa分。更新该玩家评分的公式为:
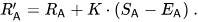
此外,作者还展示了排位赛中每个模型的对战胜率以及使用Elo评分估算的预测对战胜率。
结果显示,Elo评分确实可以相对准确地进行预测
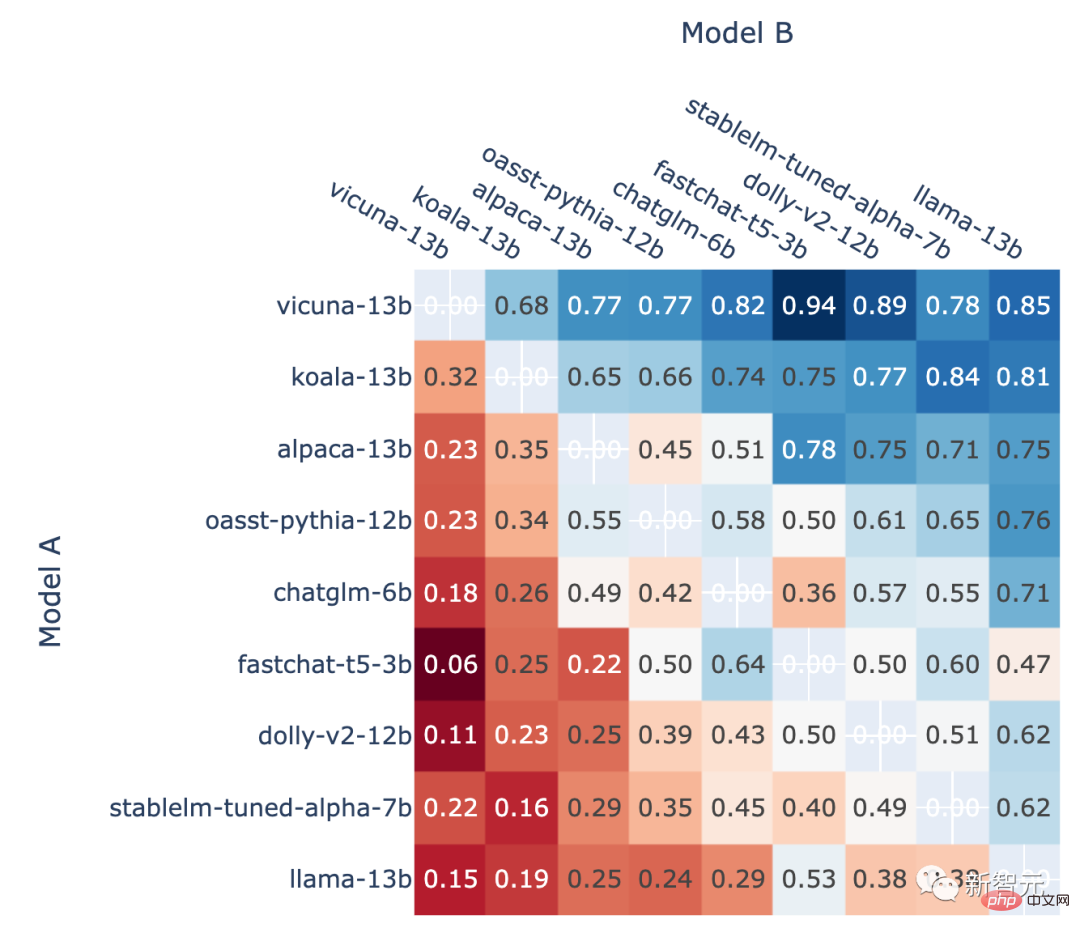
所有非平局A对B战斗中模型A胜利的比例
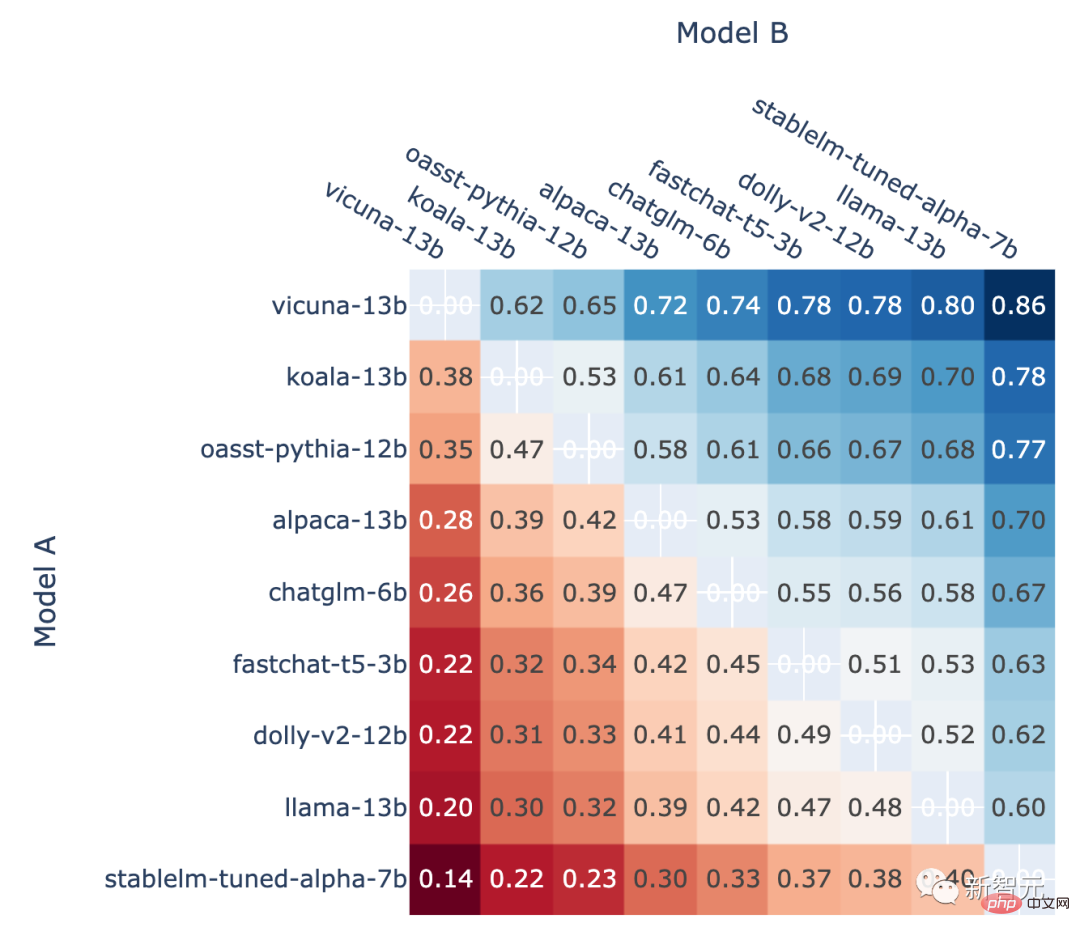
在A对B战斗中,使用Elo评分预测的模型A的胜率
「聊天机器人竞技场」由前小羊驼作者机构LMSYS Org发布。
该机构由UC伯克利博士Lianmin Zheng和UCSD准教授Hao Zhang创立,目标是通过共同开发开放的数据集、模型、系统和评估工具,使每个人都能获得大型模型。
Lianmin Zheng是加州大学伯克利分校EECS系的博士生,他的研究兴趣包括机器学习系统、编译器和分布式系统。
Hao Zhang目前是加州大学伯克利分校的博士后研究员。他将于2023年秋季开始在加州大学圣地亚哥分校Halıcıoğlu数据科学研究所和计算机系担任助理教授。
以上是UC伯克利发布大语言模型排行榜!Vicuna夺冠,清华ChatGLM进前5的详细内容。更多信息请关注PHP中文网其他相关文章!





















