

对于这种图片的获取,其实本质上就是就是文件的下载(HttpClient)。但是因为不只是获取一张图片,所以还会有一个页面解析的处理过程(Jsoup)。
Jsoup:解析html页面,获取图片的链接。
HttpClient:请求图片的链接,保存图片到本地。
首先进入首页分析,主要有以下几个分类(这里不是全部分类,但是这几个也足够了,这只是学习技术而已。),我们的目标就是获取每个分类下的图片。
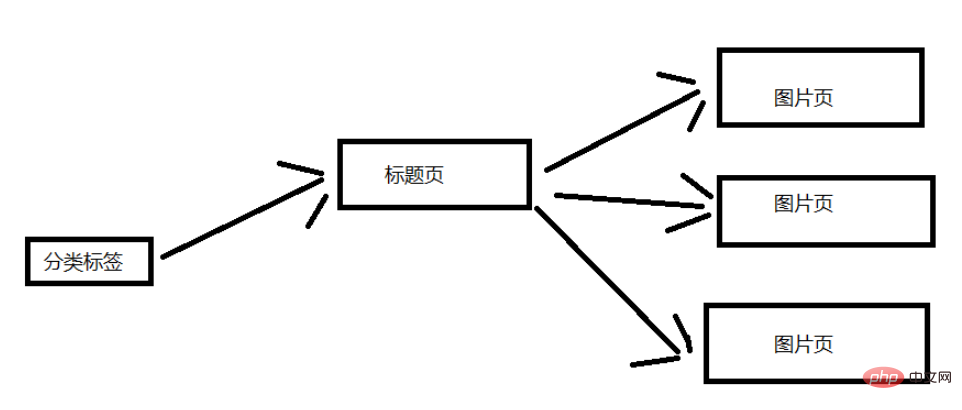
这里来分析一下网站的结构,我这里就简单一点吧。 下面这张图片是大致的结构,这里选取一个分类标签进行说明。 一个分类标签页含有多个标题页,然后每个标题页含有多个图片页。(对应标题页的几十张图片)
导入项目依赖jar包坐标或者直接下载对应的jar包,导入项目也可。
1 2 3 4 5 6 7 8 9 10 11 |
|
实体类:把属性封装成一个对象,这样调用方便一点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
工具类:不断变换 UA(我也不知道有没有用,不过我是使用自己的ip,估计用处不大了)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
多线程实在是太快了,再加上我只有一个ip,没有代理ip可以用(我也不太了解),使用多线程被封ip是很快的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
|
这是获取 HttpClient 连接的工具类,避免频繁创建连接的性能消耗。(但是因为我这里是使用单线程来爬取,所以用处就不大了。我就是可以只使用一个HttpClient连接来爬取,这是因为我刚开始是使用多线程来爬取的,但是基本获取几张图片就被禁掉了,所以改成单线程爬虫。所以这个连接池也就留下来了。)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 |
|
这里有一个爬虫队列,但是我最终连第一个都没有爬取完,这是因为我计算失误了,少算了两个数量级。但是,程序的功能是正确的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|

这里有一个计算失误,代码如下:
1 2 3 |
|
这个 i 的取值过大了,因为我计算的时候失误了。如果按照这个情况下载的话,总共会下载:4 * 10 * (30-5) * 60 = 64800 张。(每一页是含有30个标题页,大概5个是广告。) 我一开始以为只有几百张图片! 这是一个估计值,但是真实的下载量和这个不会差太多的(没有数量级的差距)。所以我下载了一会发现只下载了第一个队列里面的图片。当然了,作为一个爬虫学习的程序,它还是很合格的。
这个程序只是用来学习的,我设置每张图片的下载间隔时间是1.5秒,而且是单线程的程序,所以速度上会显得很慢。但是那样也没有关系,只要程序的功能正确就行了,应该没有人会真的等到图片下载完吧。
那估计要好久了:64800*1.5s = 97200s = 27h,这也只是一个粗略的估计值,没有考虑程序的其他运行时间,不过其他时间可以基本忽略了。
以上是怎么使用Java爬虫批量爬取图片的详细内容。更多信息请关注PHP中文网其他相关文章!





















