


Java分布式之Kafka消息队列实例分析

介绍
Apache Kafka 是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
注意:Kafka并没有遵循JMS规范(),它只提供了发布和订阅通讯方式。
Kafka核心相关名称
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群
Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发
massage: Kafka中最基本的传递对象。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。Kafka里面实现分区,一个broker就是表示一个区域。
Segment:partition物理上由多个segment组成,每个Segment存着message信息
Producer : 生产者,生产message发送到topic
Consumer : 消费者,订阅topic并消费message, consumer作为一个线程来消费
Consumer Group:消费者组,一个Consumer Group包含多个consumer
Offset:偏移量,理解为消息 partition 中消息的索引位置
主题和队列的区别:
队列是一个数据结构,遵循先进先出原则
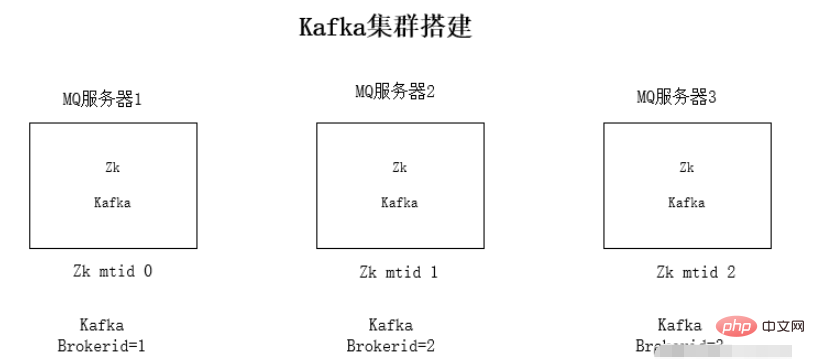
kafka集群安装
每台服务器上安装jdk1.8环境
安装Zookeeper集群环境
安装kafka集群环境
运行环境测试
安装jdk环境和zookeeper这里不详述了。
kafka为什么依赖于zookeeper:kafka会将mq信息存放到zookeeper上,为了使整个集群能够方便扩展,采用zookeeper的事件通知相互感知。
kafka集群安装步骤:
1、下载kafka的压缩包
2、解压安装包
tar -zxvf kafka_2.11-1.0.0.tgz
3、修改kafka的配置文件 config/server.properties
配置文件修改内容:
zookeeper连接地址:
zookeeper.connect=192.168.1.19:2181监听的ip,修改为本机的ip
listeners=PLAINTEXT://192.168.1.19:9092kafka的brokerid,每台broker的id都不一样
broker.id=0
4、依次启动kafka
./kafka-server-start.sh -daemon config/server.properties
kafka使用
kafka文件存储
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生成的数据。Producer生成的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。
例如:执行命令新建一个主题,分三个区存放放在三个broker中:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kaico
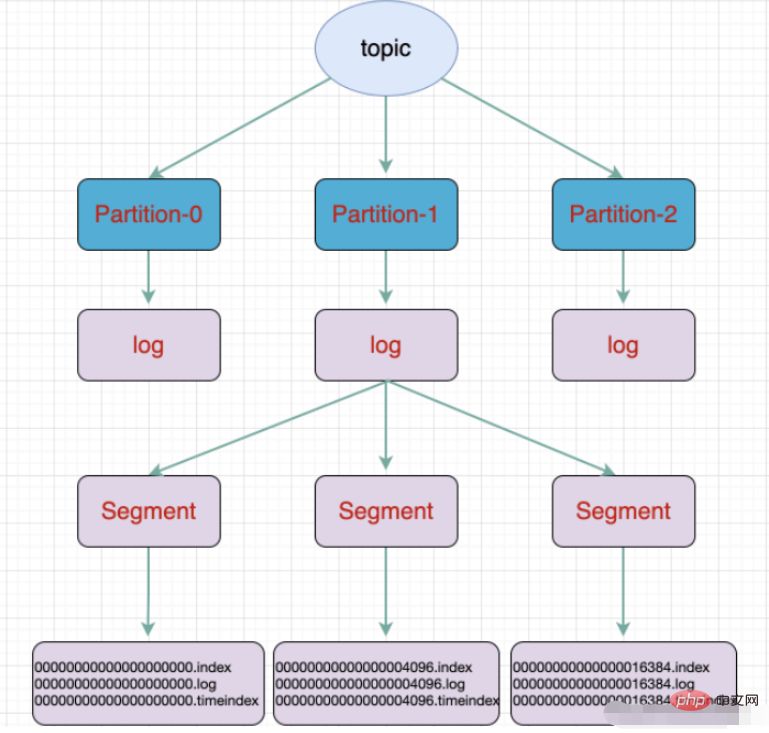
一个partition分为多个segment
.log 日志文件
.index 偏移量索引文件
.timeindex 时间戳索引文件
其他文件(partition.metadata,leader-epoch-checkpoint)
Springboot整合kafka
maven依赖
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>yml配置
# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094生产者
@RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}消费者
@Component
public class TopicKaicoConsumer {
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topics = "kaico") //监听的主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
//输出key对应的value的值
System.out.println(consumer.value());
}
}以上是Java分布式之Kafka消息队列实例分析的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undress AI Tool
免费脱衣服图片

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。


Stock Market GPT
人工智能驱动投资研究,做出更明智的决策

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何在Java中的类Path中添加JAR文件?
Sep 21, 2025 am 05:09 AM
如何在Java中的类Path中添加JAR文件?
Sep 21, 2025 am 05:09 AM
使用-cp参数可将JAR加入类路径,使JVM能加载其内类与资源,如java-cplibrary.jarcom.example.Main,支持多JAR用分号或冒号分隔,也可通过CLASSPATH环境变量或MANIFEST.MF配置。
 文件夹在哪里找
Sep 20, 2025 am 07:57 AM
文件夹在哪里找
Sep 20, 2025 am 07:57 AM
最直接的方法是回忆保存位置,通常在桌面、文档、下载等文件夹;若找不到,可使用系统搜索功能。文件“失踪”多因保存路径未留意、名称记忆偏差、文件被隐藏或云同步问题。高效管理建议:按项目、时间、类型分类,善用快速访问,定期清理归档,并规范命名。Windows通过文件资源管理器和任务栏搜索查找,macOS则依赖访达和聚焦搜索(Spotlight),后者更智能高效。掌握工具并养成良好习惯是关键。
 如何在Java中创建文件
Sep 21, 2025 am 03:54 AM
如何在Java中创建文件
Sep 21, 2025 am 03:54 AM
UseFile.createNewFile()tocreateafileonlyifitdoesn’texist,avoidingoverwriting;2.PreferFiles.createFile()fromNIO.2formodern,safefilecreationthatfailsifthefileexists;3.UseFileWriterorPrintWriterwhencreatingandimmediatelywritingcontent,withFileWriterover
 了解Java仿制药和通配符
Sep 20, 2025 am 01:58 AM
了解Java仿制药和通配符
Sep 20, 2025 am 01:58 AM
Javagenericsprovidecompile-timetypesafetyandeliminatecastingbyallowingtypeparametersonclasses,interfaces,andmethods;wildcards(?,?extendsType,?superType)handleunknowntypeswithflexibility.1.UseunboundedwildcardwhentypeisirrelevantandonlyreadingasObject
 Google Chrome无法加载此页面
Sep 20, 2025 am 03:51 AM
Google Chrome无法加载此页面
Sep 20, 2025 am 03:51 AM
首先检查网络连接是否正常,若其他网站也无法打开则问题在网络;1.清除浏览器缓存和Cookies,进入Chrome设置选择清除浏览数据;2.关闭扩展程序,可通过无痕模式测试是否因插件冲突导致;3.检查并关闭代理或VPN设置,避免网络连接被拦截;4.重置Chrome网络设置,恢复默认配置;5.更新或重装Chrome至最新版本以解决兼容性问题;6.使用其他浏览器对比测试,确认问题是否仅限Chrome;根据错误提示如ERR_CONNECTION_TIMED_OUT或ERR_SSL_PROTOCOL_ER
 UC浏览器如何强制缩放网页_UC浏览器网页强制缩放功能使用技巧
Sep 24, 2025 pm 04:54 PM
UC浏览器如何强制缩放网页_UC浏览器网页强制缩放功能使用技巧
Sep 24, 2025 pm 04:54 PM
首先启用UC浏览器内置缩放功能,进入设置→浏览设置→字体与排版或页面缩放,选择预设比例或自定义百分比;其次可通过双指张开或捏合手势强制调整页面显示大小;对于限制缩放的网页,可请求桌面版网站以解除限制;高级用户还可通过在地址栏执行JavaScript代码修改viewport属性,实现更灵活的强制缩放效果。
 为什么实时系统需要确定性响应保障?
Sep 22, 2025 pm 04:03 PM
为什么实时系统需要确定性响应保障?
Sep 22, 2025 pm 04:03 PM
实时系统需确定性响应,因正确性依赖结果交付时间;硬实时系统要求严格截止期限,错过将致灾难,软实时则允许偶尔延迟;非确定性因素如调度、中断、缓存、内存管理等影响时序;构建方案包括选用RTOS、WCET分析、资源管理、硬件优化及严格测试。
 如何在Java中获取通话方法的名称?
Sep 24, 2025 am 06:41 AM
如何在Java中获取通话方法的名称?
Sep 24, 2025 am 06:41 AM
答案是使用Thread.currentThread().getStackTrace()获取调用方法名,通过索引2得到调用anotherMethod的someMethod名称,因索引0为getStackTrace、1为当前方法、2为调用者,示例输出“Calledbymethod:someMethod”,也可用Throwable实现,但需注意性能、混淆、安全及内联影响。
